
Have you ever been the guy in charge of storage and the dev guy and database guy come over to your desk waaaaay too early in the morning before you’ve had your caffeine and start telling you that the storage is too slow and you need to do something about it? I have. In my opinion it’s even worse when the Virtualization guy comes over and makes similar accusations, but that’s another story.
Now that I work for LogicMonitor I see this all the time. People come to us because “the NetApps are slow”. All too often we come to find that it’s actually the ESX host itself, or the SQL server having problems because of poorly designed queries. I’ve experienced this first hand before I worked for LogicMonitor,so it’s no surprise to me that this is a regular issue. When I experienced this problem myself I found it was vital to monitor all systems involved so I could really figure out where the bottleneck was.
Let’s break it down….
Dev guy says: “The disk is killing my app. We need to add more disks to speed it up, or we need to get a better storage system”.
What do you do when the dev guy makes such accusations? You could certainly drop $100k on a new disk system, but who’s to say that will really fix the problem? The dev guy? Do you trust the dev guy to make that call? You’re the ops guy, even more specifically you’re the storage guy. You should be the one making this call. As the storage guy I would immediately go to the volume statistics from where the app or application’s database was being served and see what the performance looks like just to see if the initial allegation holds true.
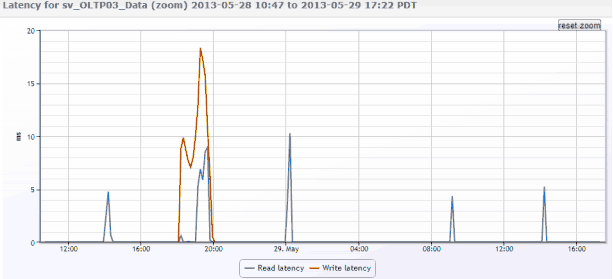
After viewing the data, here’s what you say to the dev guy: “It doesn’t look like it’s the NetApp to me. Let’s check the database”.
And so you go check the database metrics, and you find this interesting graph….
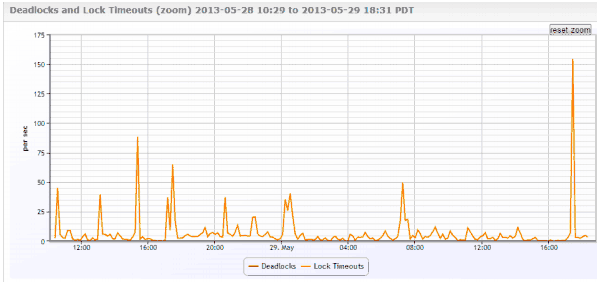
So you might say “These lock timeouts seem interesting to me”.
And you both wander over to the database guy. If one of you happens to be the database guy, even better. If you happen to have a specialist it’s still ok, because you have a reference point for him. You guys have decided that disk latency is not the issue thanks to your thorough monitoring, and you’ve noticed something funny happening with the database server.
Now in this particular example we happened to get lucky and were able to track it down to a query that was causing the problems. It turned out that the dev guy that came over in the first place was the guy who was in charge of the problem and he was able to fix it.
In this scenario I (and my team) were fortunate to have both the storage platform and the database application in the same monitoring platform, which made it much easier for us to find the problem and implement a solution. My advice: Make sure you have all relevant platforms in the same monitoring solution (physical and virtual servers, network, storage, applications). Give all parties access to the data. Collaborate with each other rather than finger point. I bet you’ll find your organization solving problems quicker and ultimately being more successful in delivering your IT needs.