
The photoelectric effect is the observation that many metals emit electrons when light shines upon them. While not a law of physics, large applications tend to behave like metals when observed and exposed to light. Tiny particles, frequently referred to as Service Oriented Architecture (SOA) components or Micro Services, are emitted from monolithic software as a response to observation.
Enough of the tenuous physics metaphor! The technology world is moving away from monolithic applications towards micro services. Like everything, micro service architectures entail some trade-offs. The benefits of increased modularity, ease of deployment, and increased application level robustness, come at the cost of operational complexity. One of the most difficult questions to answer when moving to a service oriented architecture is the most important: “Is this new service working properly?”
Unless the critical metrics are communicated carefully and explicitly during the handoff from Dev to Operations, an intimate knowledge of the new component is required to configure monitoring. We have gotten numerous chances to work through this handoff, so here are some of the recommendations that we have to make sure that your electron (SOA service) starts its life with the right energy:
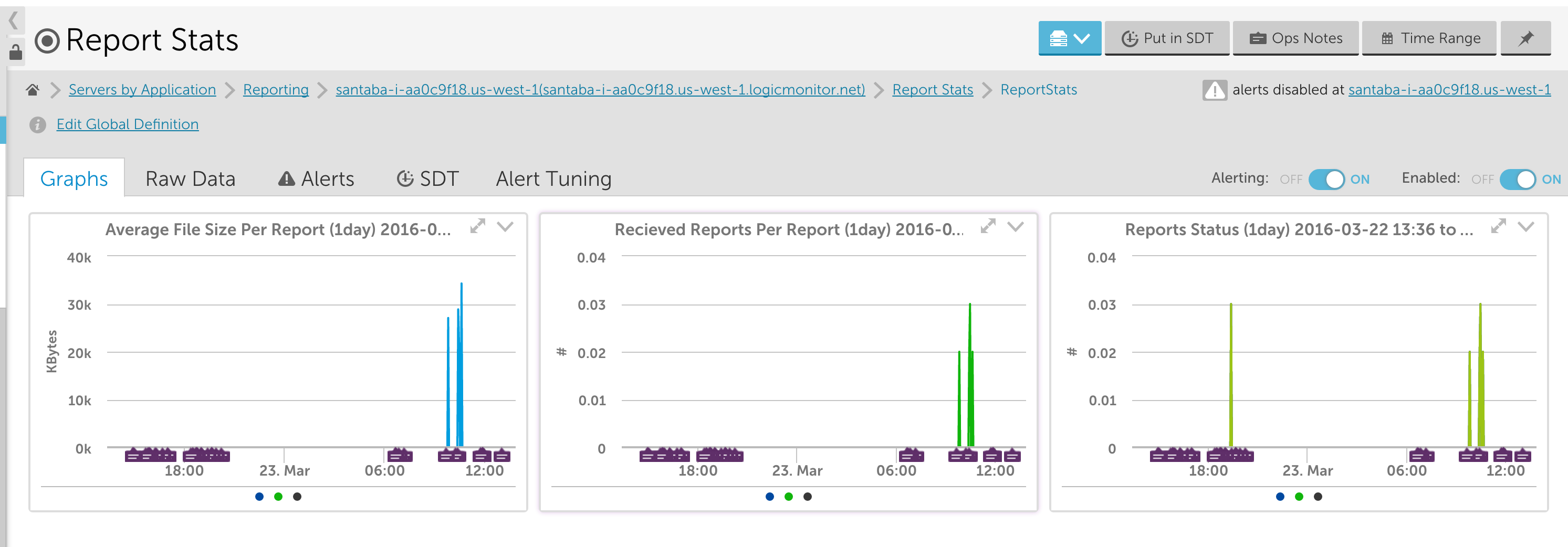
1) All new components must be monitored – in LogicMonitor terminology, they should have associated datasources. These datasources must include critical metrics and thresholds configured by Development. Generally speaking, the only group with visibility into the application specific health metrics will be Development. They should make sure that if anything happens, the on-call team will be notified appropriately.
2) New component datasources should be presented in dashboards (in an overview dashboard at least). These dashboards should be a collaborative effort between Development and Operations. Having a good overview of the application health is important, and can be used for preventative maintenance instead of break-fix maintenance like alerting. Also, it looks good on a NOC screen.
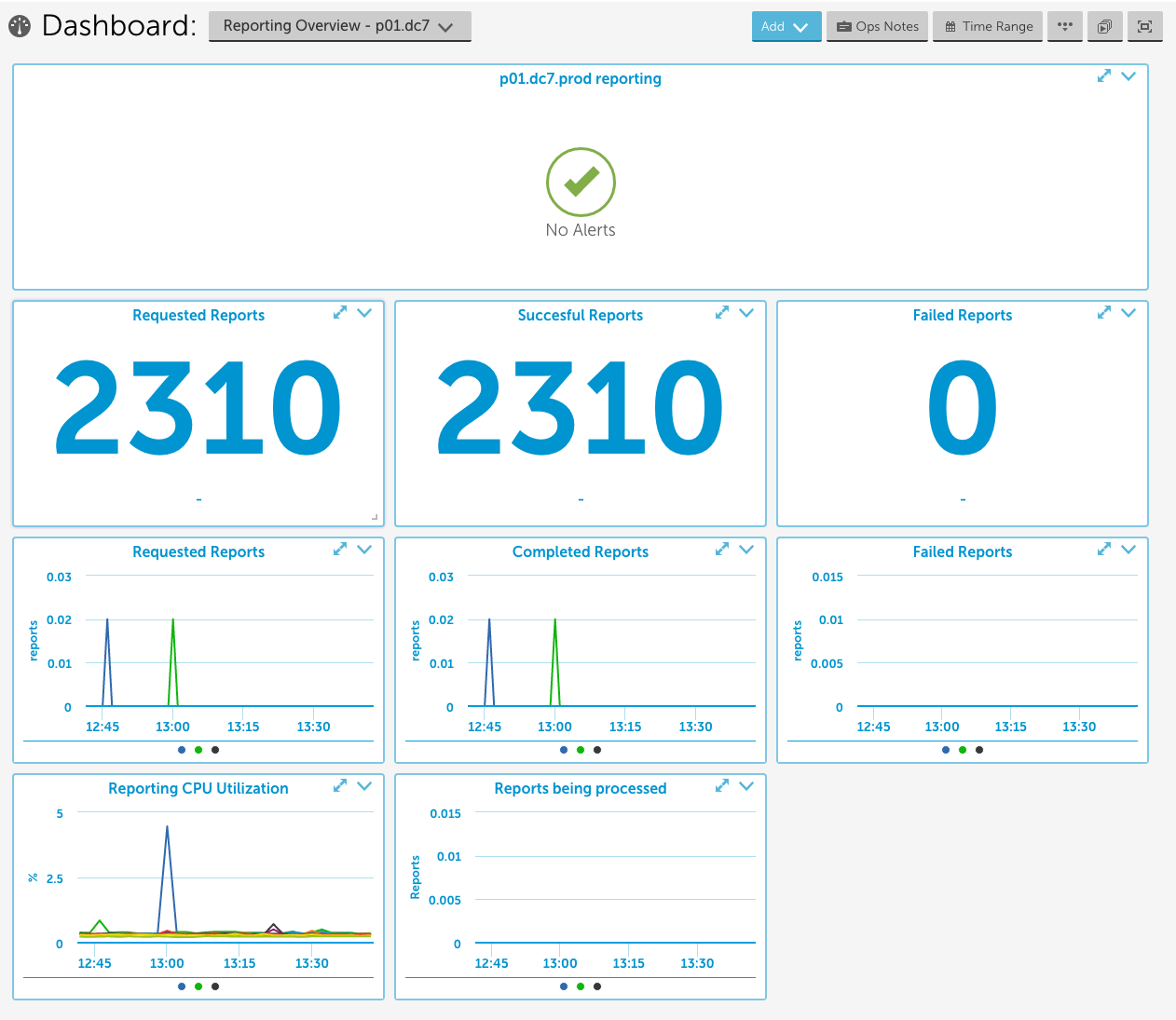
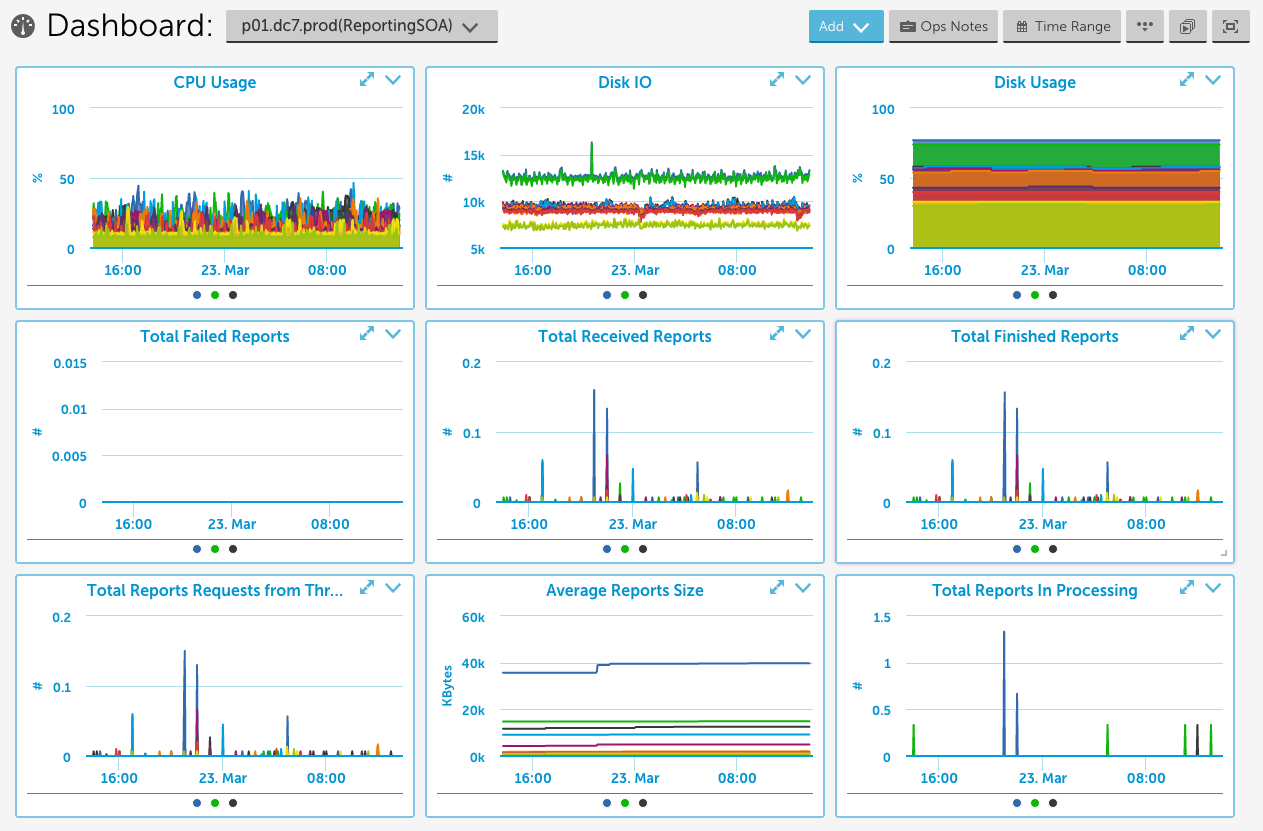
3) All actions available to Operations when the component is in an unhealthy state (which you should be able to determine from Step 1) should be clearly documented. If you get alerted in the wee-hours of the morning, reverse engineering the appropriate action from the alert is nearly out of the question. However, the Operations teams taking sporadic “throw spaghetti at the wall” actions (i.e. “Let’s restart the service. How about the server? How about the service it’s talking to?”) is more likely to hurt than to help. You want a clear and easily accessible document with troubleshooting steps, recommended actions, etc.
4) Ideally, the people that know the application and are responsible for how it performs (i.e. the developers) will also be the ones responding to the alerts for the application. The Operations team can certainly be an escalation point, as some issues may not be directly app related. This is where the value of DevOps (or OpsDev) comes to the fore.
Operational complexity is inevitable when dealing with micro services. Despite the risks, we aren’t afraid of deploying SOA, as the benefits are significant, and the risks manageable. How do you feel about them?

