

One question we sometimes get is why LogicMonitor relies so little on SNMP traps. When we are writing the monitoring for a new device, we look at the traps in the MIB for the device to see the things the vendor thinks are important to notify about – but we will try to determine the state of the device by polling for those things, not relying on the traps. “Why not rely on traps?” you may ask. Good question.
Firstly, consider what a trap is – a single UDP datagram, sent from a device to notify you that something is going wrong with that device. Now, UDP (User Datagram Protocol) packets are, unlike TCP, not acknowledged, and so not retransmitted if they get lost on the network and do not arrive (as the sender has no way of knowing if it arrived or not.) So, a trap is a single, unreliable notification, being sent from a device at the exact time that a UDP packet is least likely to make it to the management station – as, by definition, something is going wrong. The thing going wrong may be causing spanning tree to re-compute, or routing protocols to reconverge, or interface buffers to reset due to a switchover to redundant power supply. Not the time to rely on a single packet to tell you about critical events…
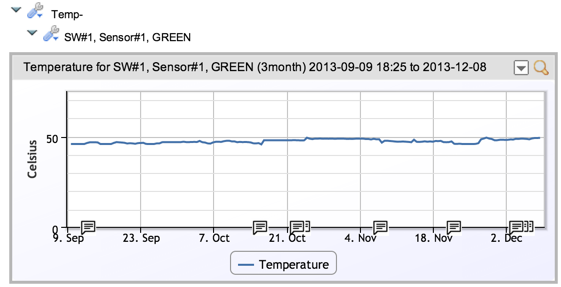
Traps are not a reliable means to tell you of things that can critically affect your infrastructure. That’s one reason to avoid them if possible. Another reason we prefer polling to traps is trending and context. Some devices send traps when CPU utilization becomes too high, or temperature exceeds a threshold. If you happened to upgrade software on a switch, and then receive a temperature-too-high trap shortly thereafter – you have limited data. Has the temperature been slowly climbing over the last 3 months, or was this a sudden increase since the upgrade? A trap cannot tell you that, but polling data that is shown as a temperature graph over the last months will – while also allowing you set easily set thresholds of different severity at different levels.
Yet another reason is manageability. In order for a trap to be sent and arrive at the management station, you have to configure the trap destination – the monitoring station’s IP address – into every device. On every switch, every router, every server…. But, you may ask, don’t you have to do this to set up the SNMP community on the devices anyway, to enable polling? Yes – but usually when SNMP communities are defined, polling is enabled for entire specific subnets. You can move your monitoring system to another IP on the same subnet, and not have to change any configuration. But if you rely on traps, you now have to touch every device and reconfigure it to send traps to the new destination. And perhaps more significantly, how can you test that you have things set up correctly? With polling it’s easy to see (and be alerted on) data not returning due to a misconfigured community, firewall or access list. But it is much harder to be confident that a system is set up to trap to the right place, and that access-lists are set correctly to allow the traps. (And of course, traps use a different port than regular SNMP queries, so the fact polling works tells you nothing about whether traps will work.)
By definition, polls are tested every minute or so. A trap is usually tested only when a critical event occurs, with no notification or feedback if it fails. Which would you rather depend on for the health of your infrastructure and applications?