
Troubleshooting Kubernetes Monitoring
Last updated on 02 August, 2023If you were not able to successfully install LogicMonitor’s Kubernetes Monitoring Integration, use the following steps to troubleshoot:
If the Helm install commands were not successful:
- Make sure that the Kubernetes RBAC enabled option was correctly selected during install. This controls the ‘enableRBAC’ Helm chart values, which must match the RBAC in your cluster (i.e. if RBAC is not enabled for your cluster, this value must be false).
- Confirm that your LogicMonitor API Tokens are valid, and have sufficient permission.
- Check the logs for the Argus & Collectorset-Controller pods
If Helm install commands were successful, but your cluster hasn’t been added to monitoring successfully:
- Check whether the Collector Group added. If it wasn’t, there may be an issue with the LogicMonitor API Tokens provided. You can use the LogicMonitor Audit Log to identify if the request was denied.
- Check whether Collectors were successfully installed. If the Collector Group was added, but Collectors weren’t successfully installed, it’s not likely to be an issue with your API Tokens. It may be that Collector installation memory requirements were not met – confirm that this is not the case. If the Collectors aren’t properly installed, it’s also a good idea to look at the logs for the Argus, Collectorset-Controller, and Collector pods.
- If you are using OpenShift, you may need to elevate the permissions of the serviceaccount for the Collector to enable install. You can do this via the following command (assumes the default namespace is used):
oc adm policy add-scc-to-user anyuid system:serviceaccount:default:collector
If Helm install commands were successful, and your cluster was added into monitoring, but data collection isn’t working:
- Ensure you’re using the latest version of the DataSources. We regularly release new versions of our DataSources to include bug fixes and improvements. To import newer versions, please see this article
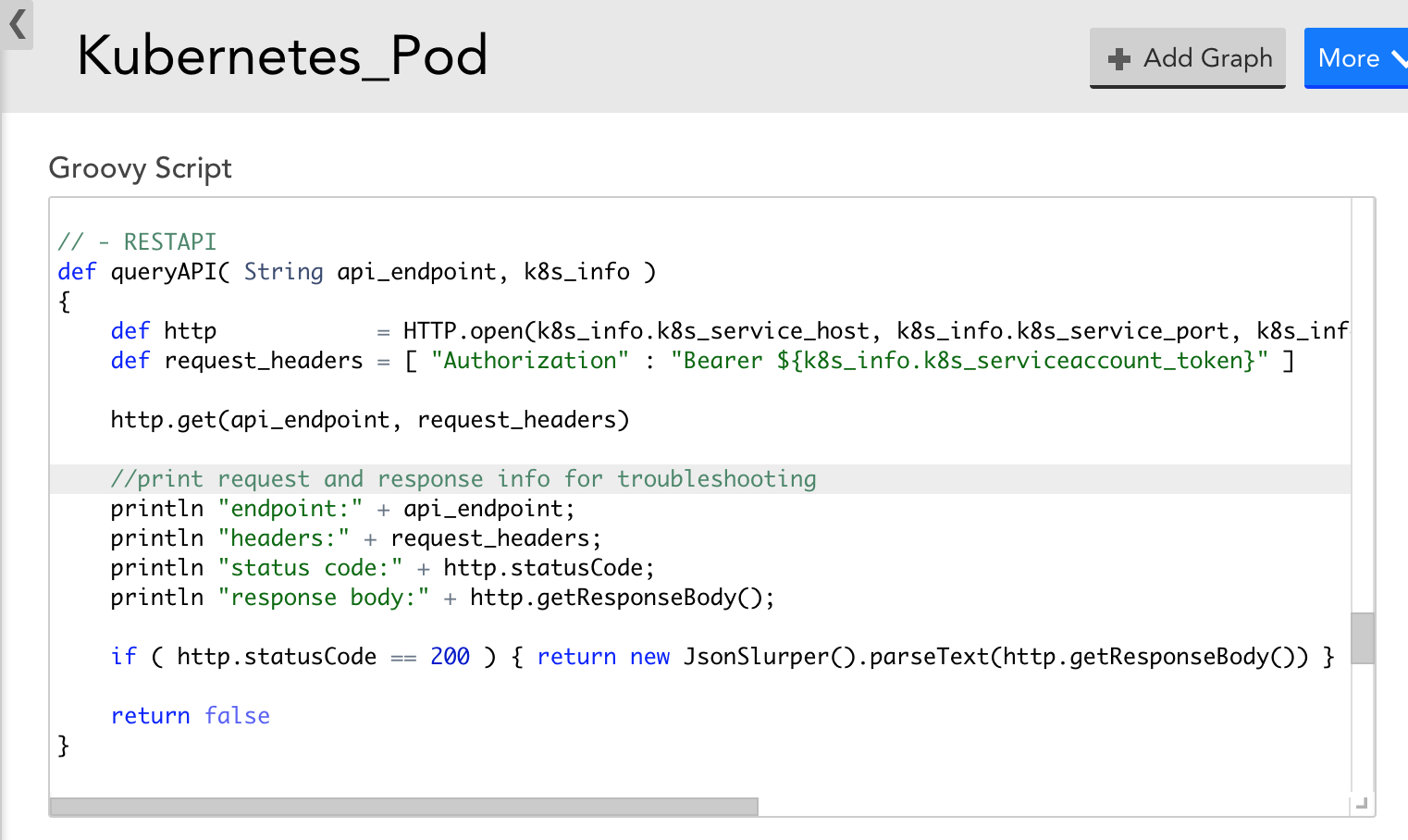
- If, with the latest version of the DataSources, data collection still doesn’t work – you can modify the DataSource to display the Kubernetes API response and status code to get more information. For example, the Pod DataSource could be modified to print out request and response information to narrow down what error the Kubernetes API is returning during data collection attempts, as in the following screenshot. This may help you identify why data collection isn’t working.
If you are unable to set up Argus and Collectorset-Controller pods in GKE due to memory, CPU, and ephemeral storage, use the following configuration:
- Ensure to set the resource limits and requests (memory, CPU, ephemeral storage) for the collector using the Argus configuration file.
Sample file:
statefulsetspec:
template:
spec:
containers:
- name: collector
resources:
requests:
cpu: 1000m
ephemeral-storage: 5Gi
memory: 2GiIf the following gRPC connection failed error occurs while installing Argus, do the following:
level=warning msg=”Error while creating gRPC connection. Error: context deadline exceeded” argus_pod_id=<pod-id> debug_id=<id> goroutine=1 method=pkg/connection.createGRPCConnection watch=init
Complete the following steps to resolve the issue:
- Run the following command to log in to the Argus Pod shell:
kubectl exec -it <argus_Pod_name> /bin/sh
- Check the communication between Argus and Collectorset-Controller Pods by entering the following command:
curl http://collectorset-controller:50000
- If the communication fails and an error occurs, you must check the parameters of the restrictions set in the internal network policies.
If the collector pods are frequently restarting on OpenShift Cluster v4.x and are causing monitoring gaps, do the following:
The Docker collector runs all the collection jobs; however, the limit is insufficient for the large-scale clusters as OpenShift has a default container PID limit of 1024 that limits the number of processes to 1024.
You can modify the settings by using a ContainerRuntimeConfig custom resource.
For example, you have labeled a Pod as machineconfigpool on which you want to increase the PID limit with key as custom-crio and value as custom-pidslimit, then modify the configuration file as follows:
apiVersion: machineconfiguration.openshift.io/v1
kind: ContainerRuntimeConfig
metadata:
name: custom-pidslimit
spec:
machineConfigPoolSelector:
matchLabels:
custom-crio: custom-pidslimit
containerRuntimeConfig:
pidsLimit: 4096Note: The appropriate PID limit may vary based on the collector size and the number of Kubernetes resources that are monitored. However, the default PID limit set for the small-size collector is a minimum of 4096.
You can also verify if the PID limit is effective by entering the following command in the pod shell:cat /sys/fs/cgroup/pids/pids.current