MTTR reduzieren
MTTR reduzieren mit KI-korrelierten Protokollen und Metriken plus automatisierter Behebung
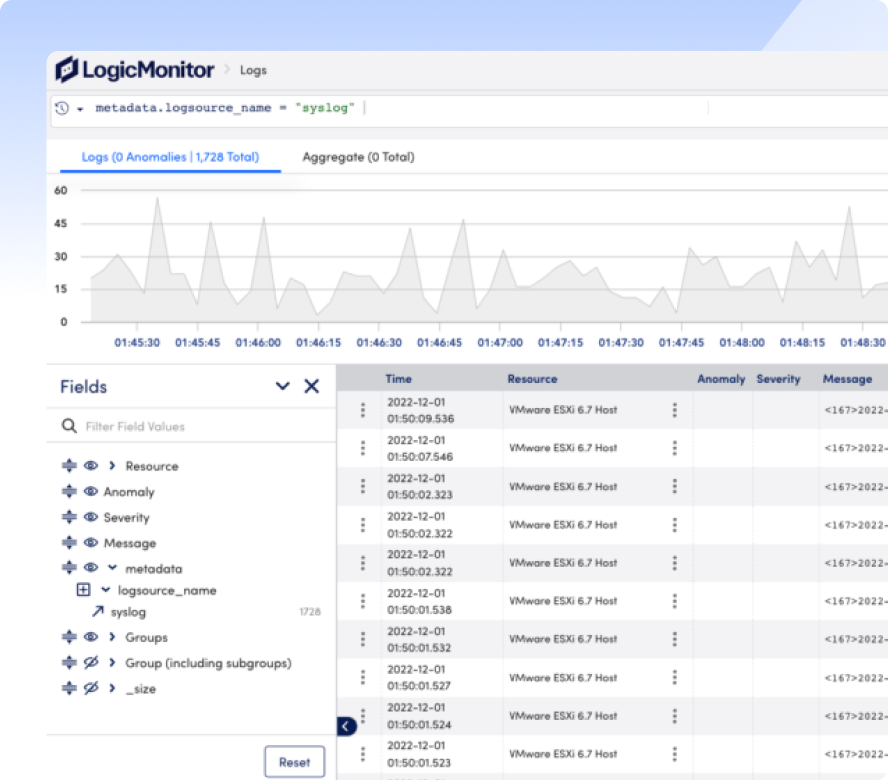
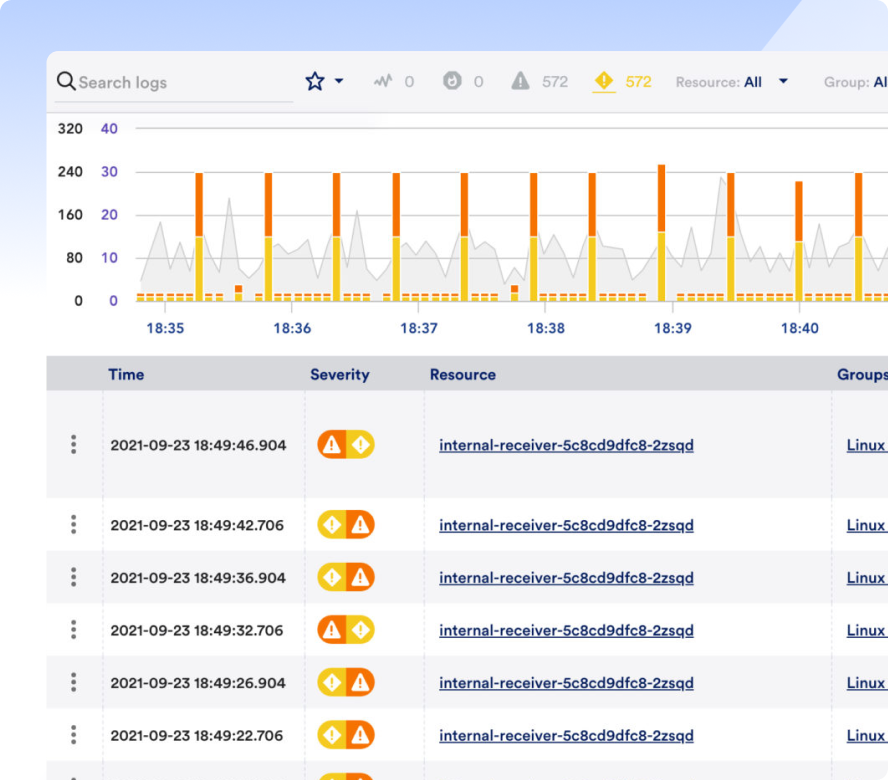
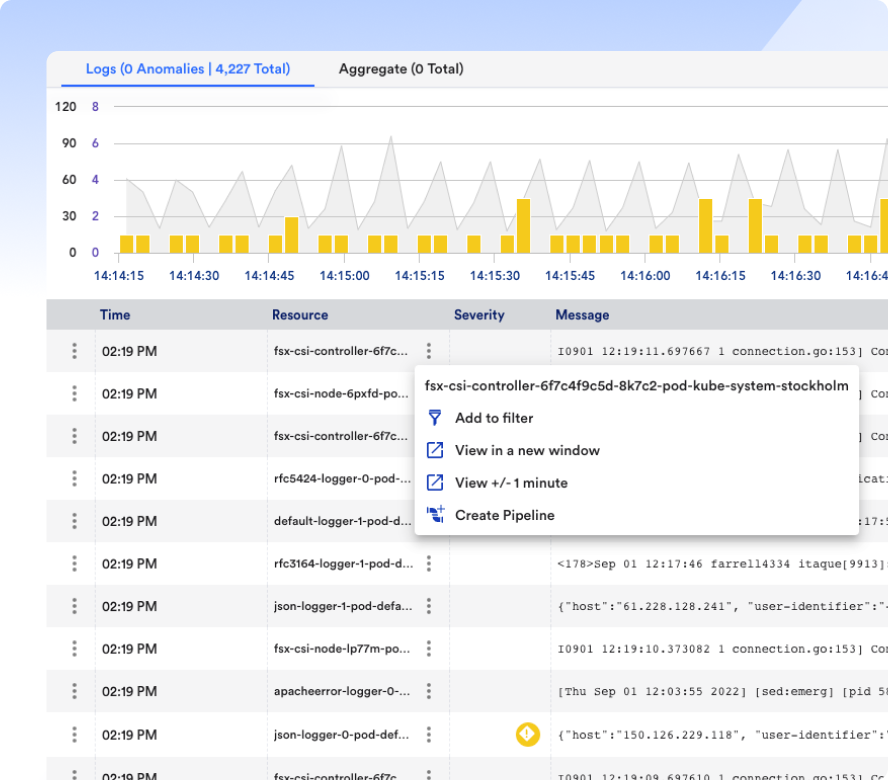
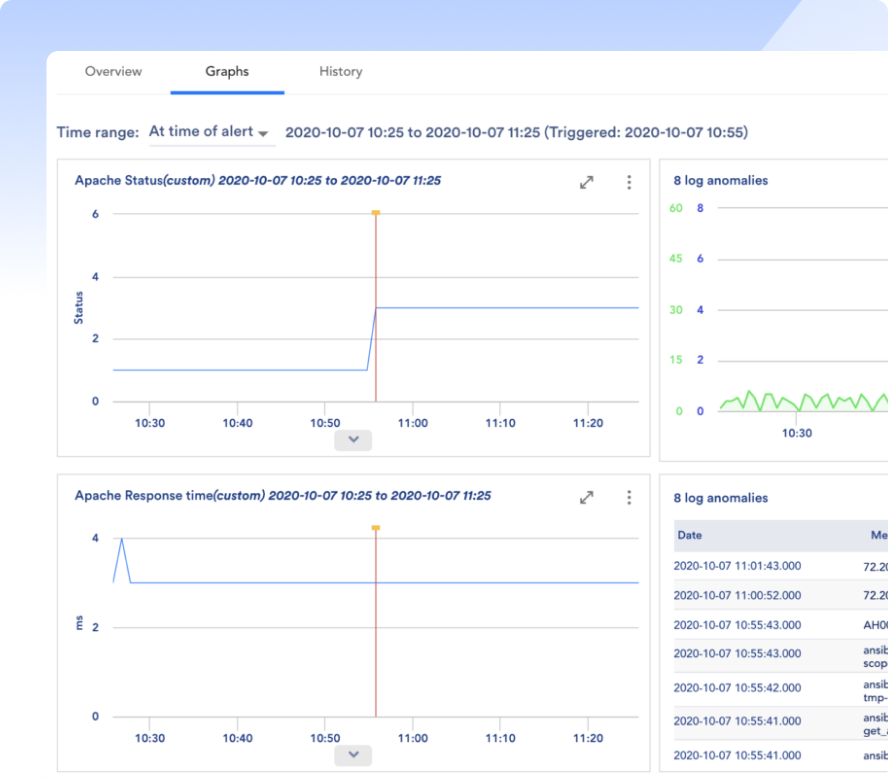
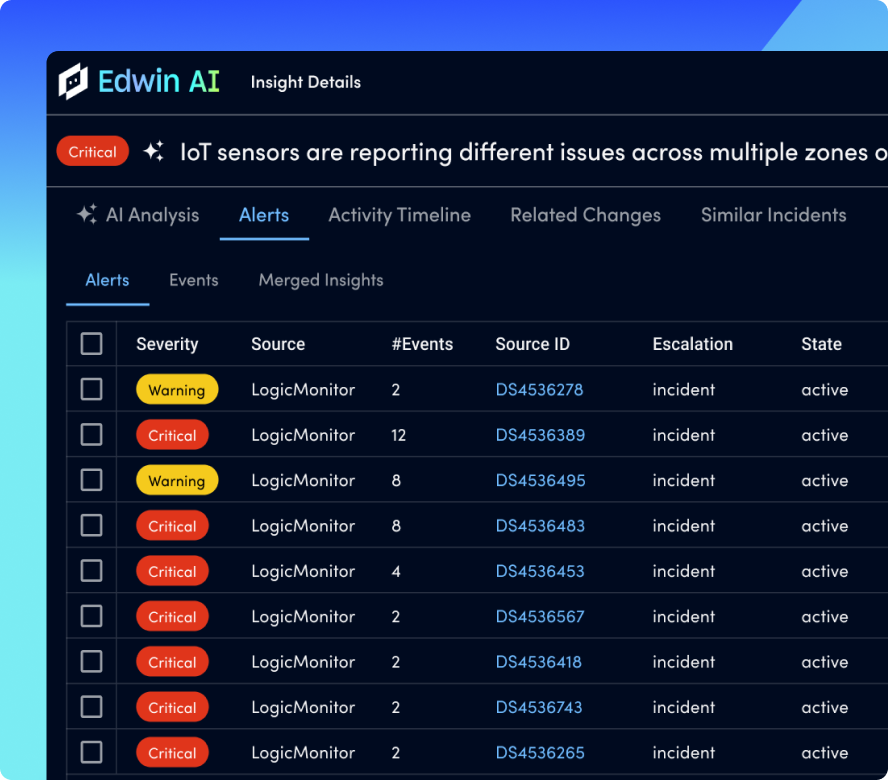
Jeder definiert MTTR ein wenig anders, aber letztendlich geht es darum, Probleme zu beheben und Zeit für Innovationen freizusetzen. Was auch immer es ist, lösen Sie es schnell mit LM Envision, KI-gestützter Korrelation und automatisierter Fehlerbehebung.