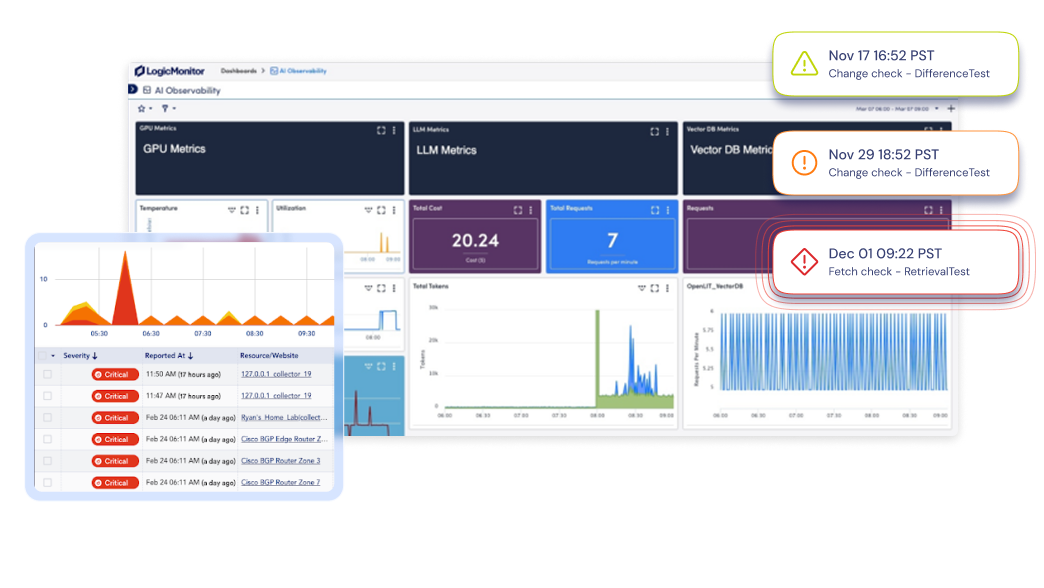
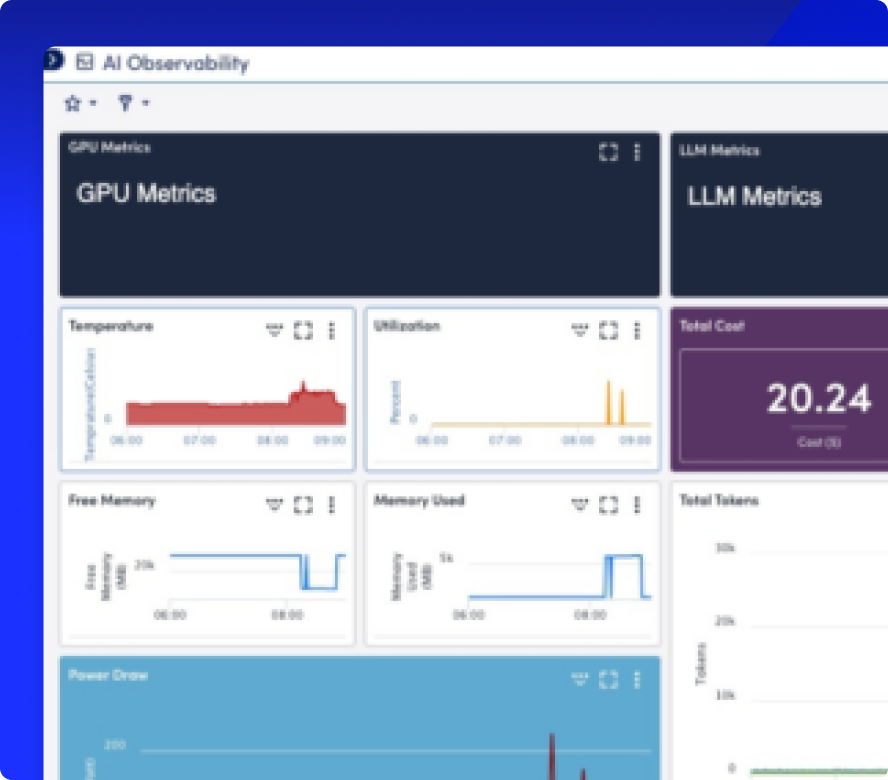
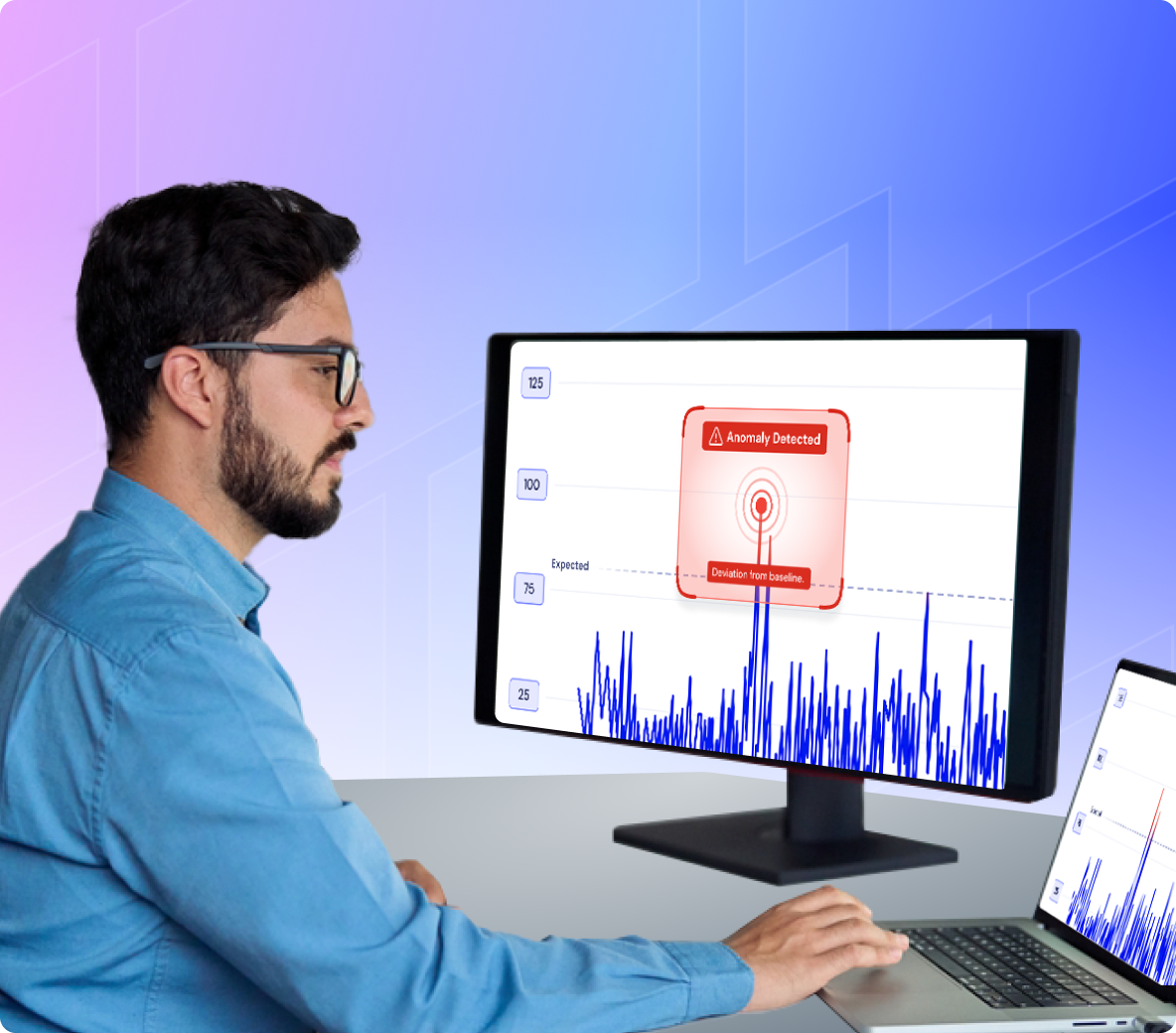
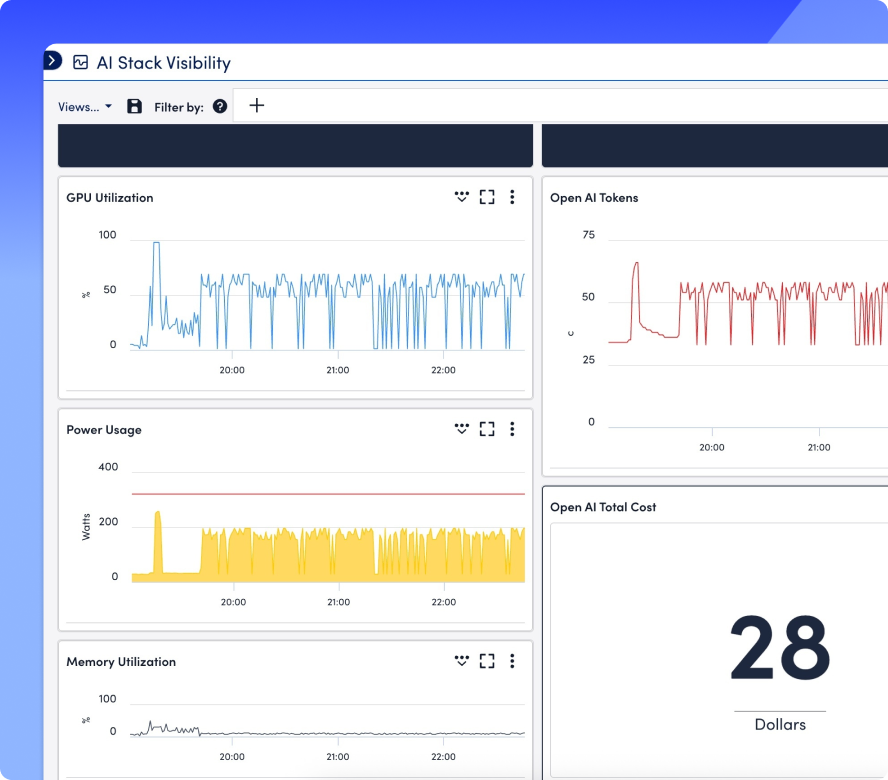
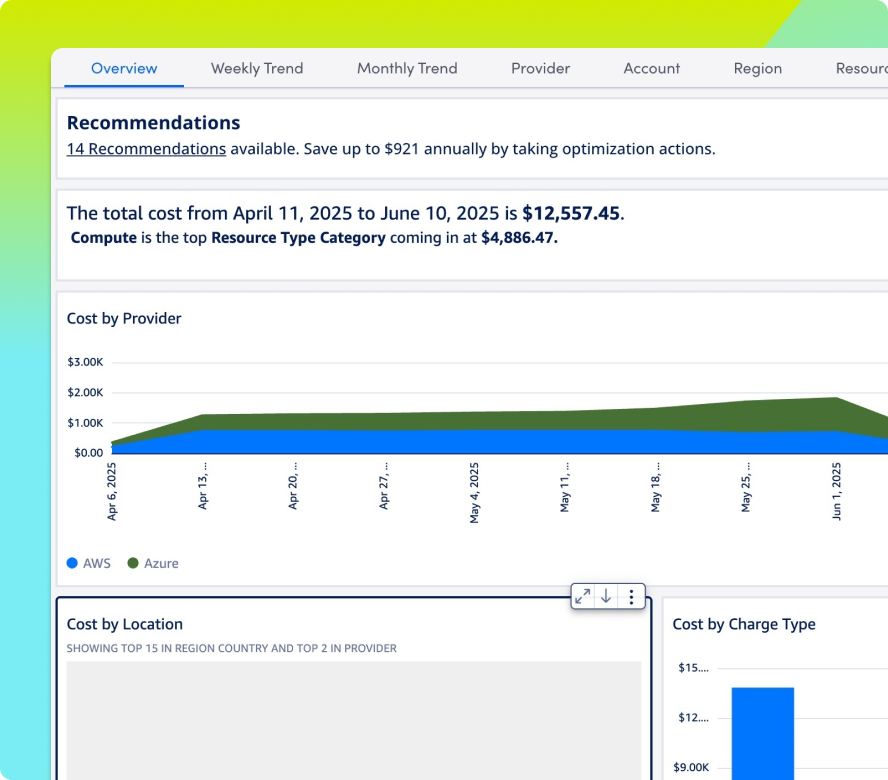
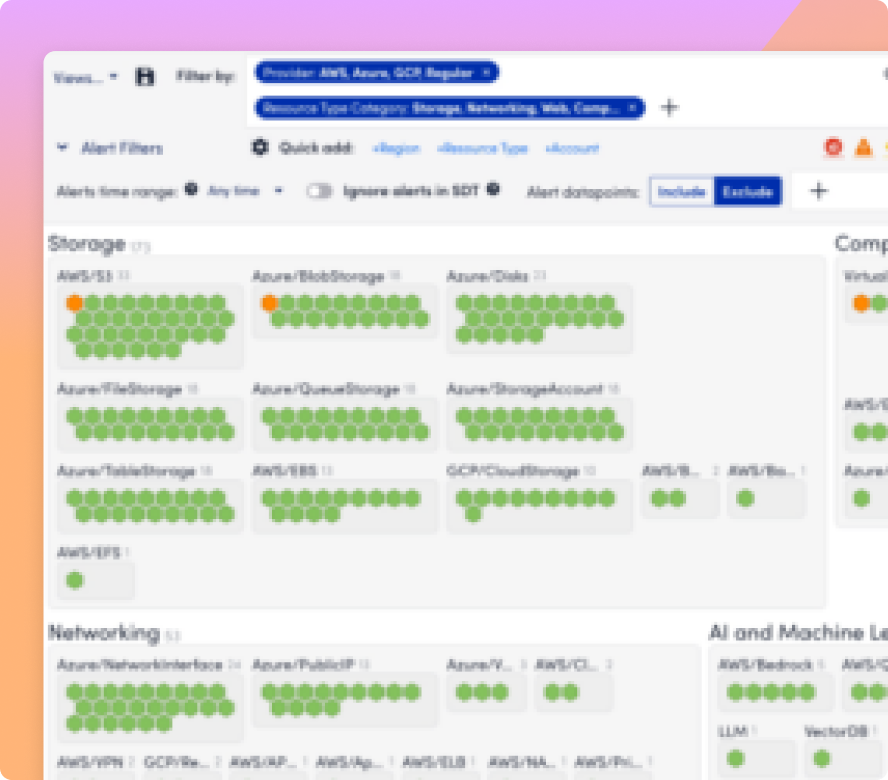
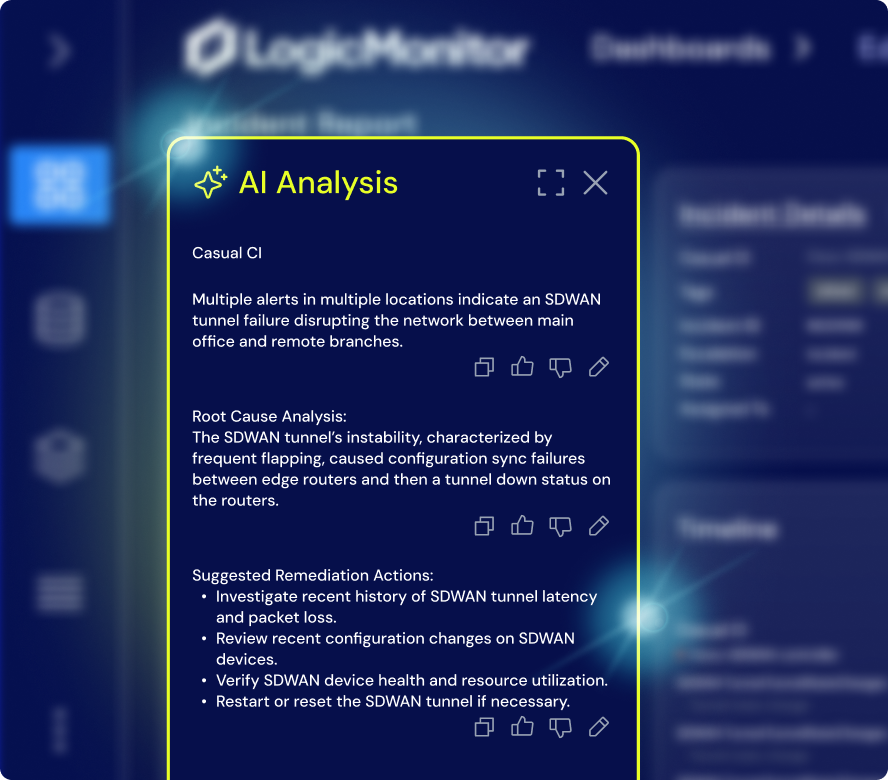
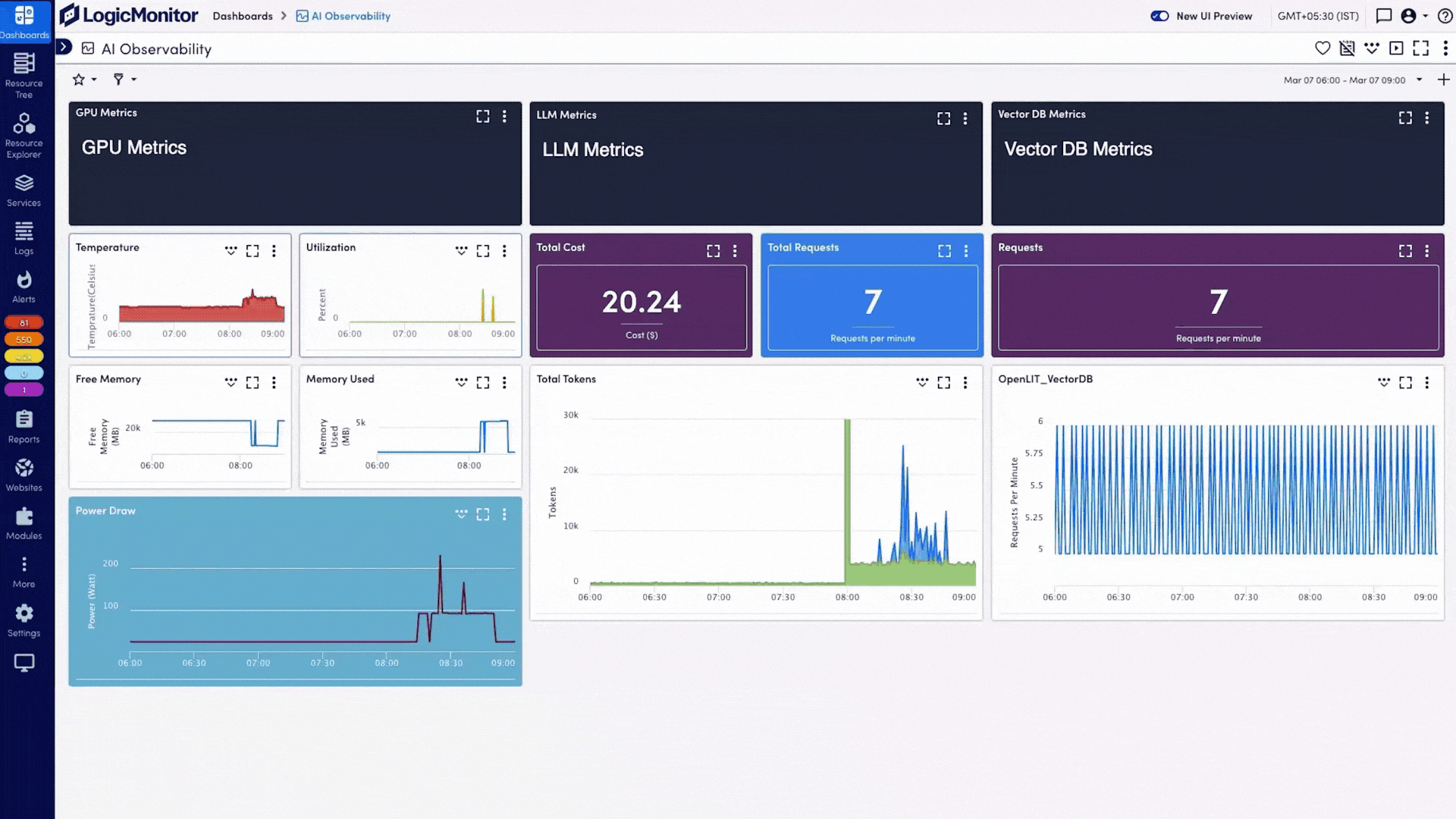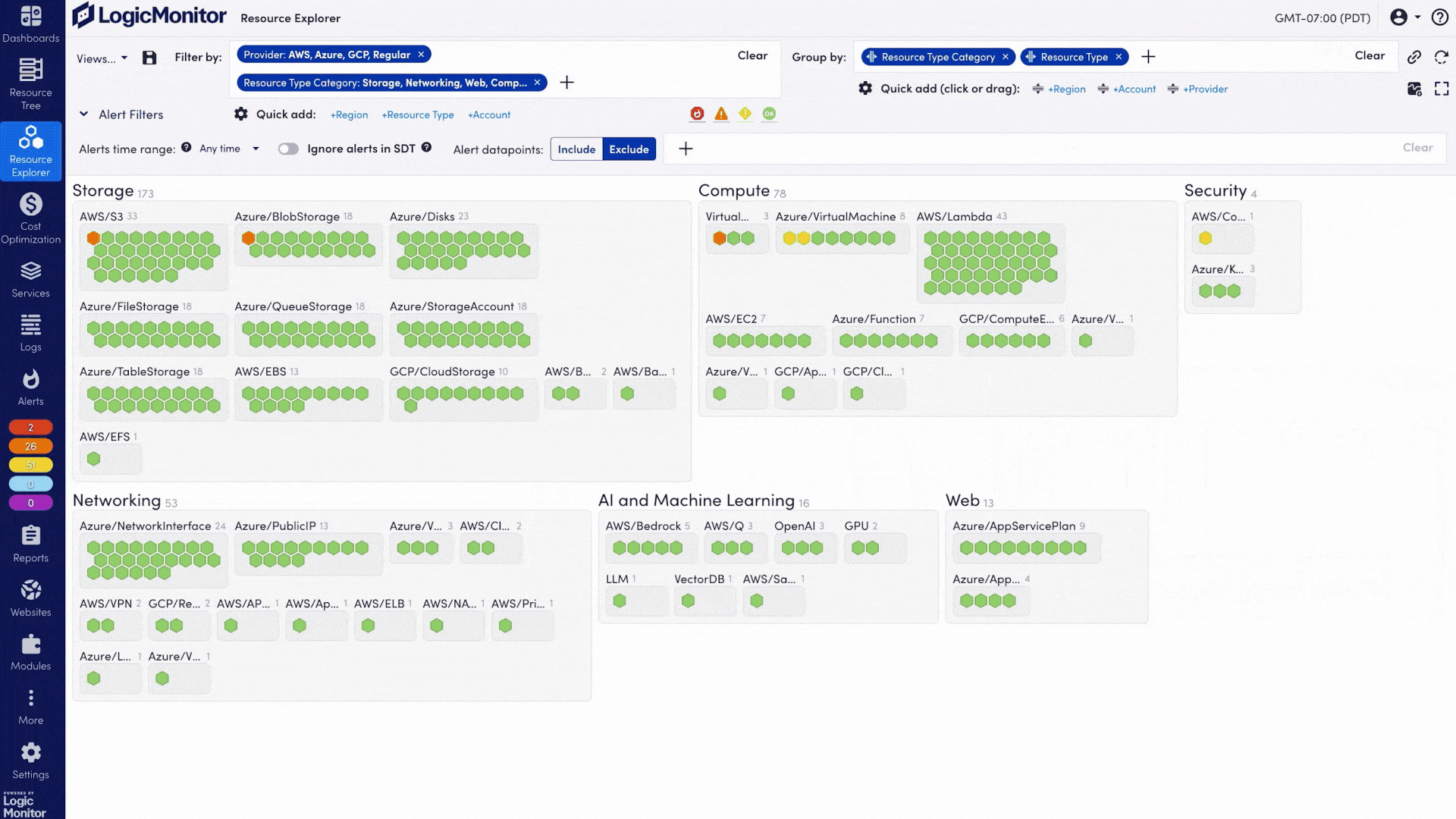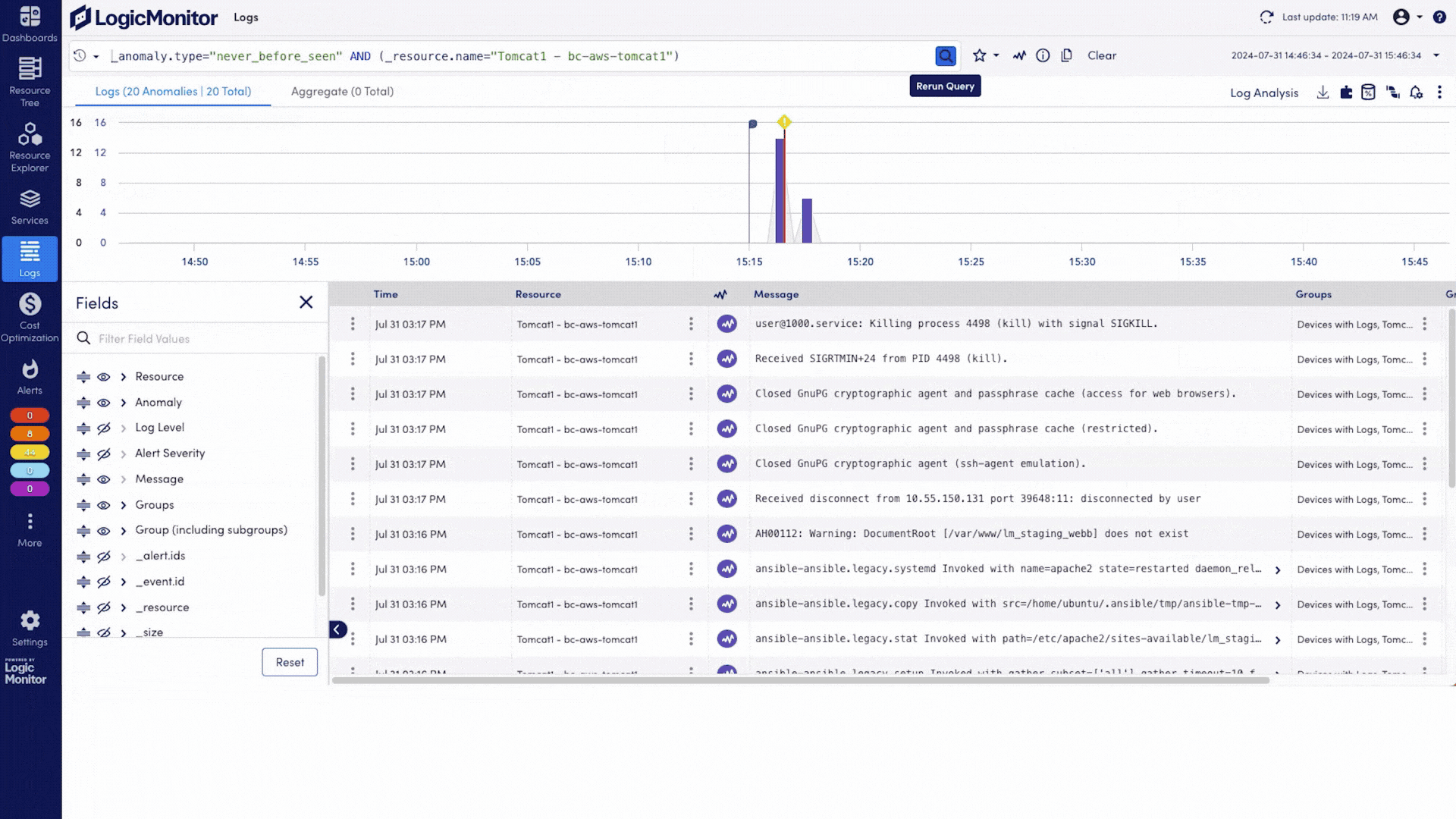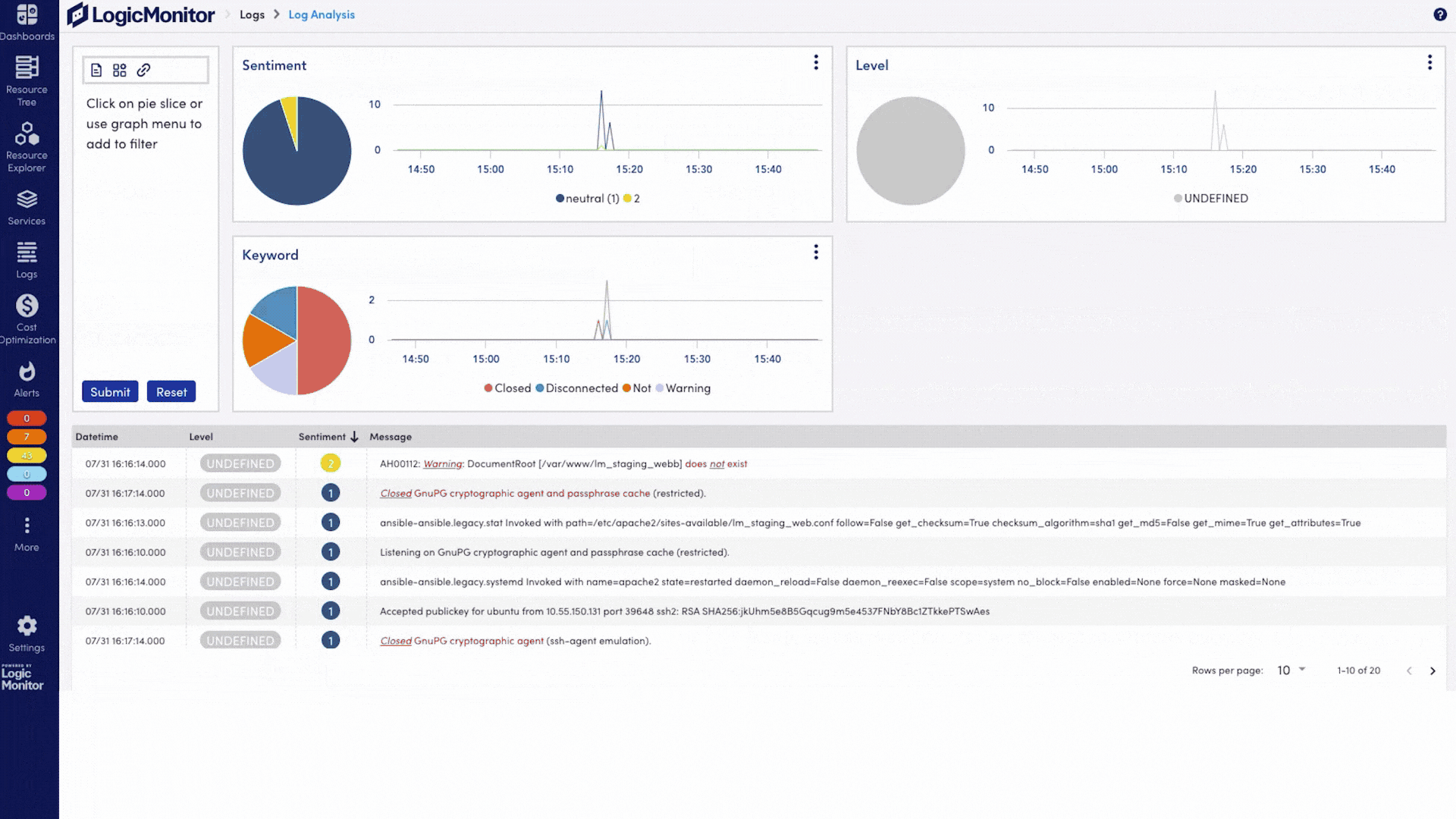
Observabilité de l'IA pour les GPU, LLM, Infrastructure et Expérience Numérique
Voyez comment chaque couche de votre pile de services d'IA fonctionne, des GPU, des LLM et de l'infrastructure aux performances Internet et à l'expérience numérique, afin que les équipes puissent résoudre les problèmes plus rapidement, contrôler les coûts et fournir des services d'IA plus fiables.