


l’observabilité IA dans une plateforme unique
Unifiez chaque signal de votre environnement IA pour passer d’une gestion réactive des incidents à des décisions stratégiques, pilotées par la donnée.
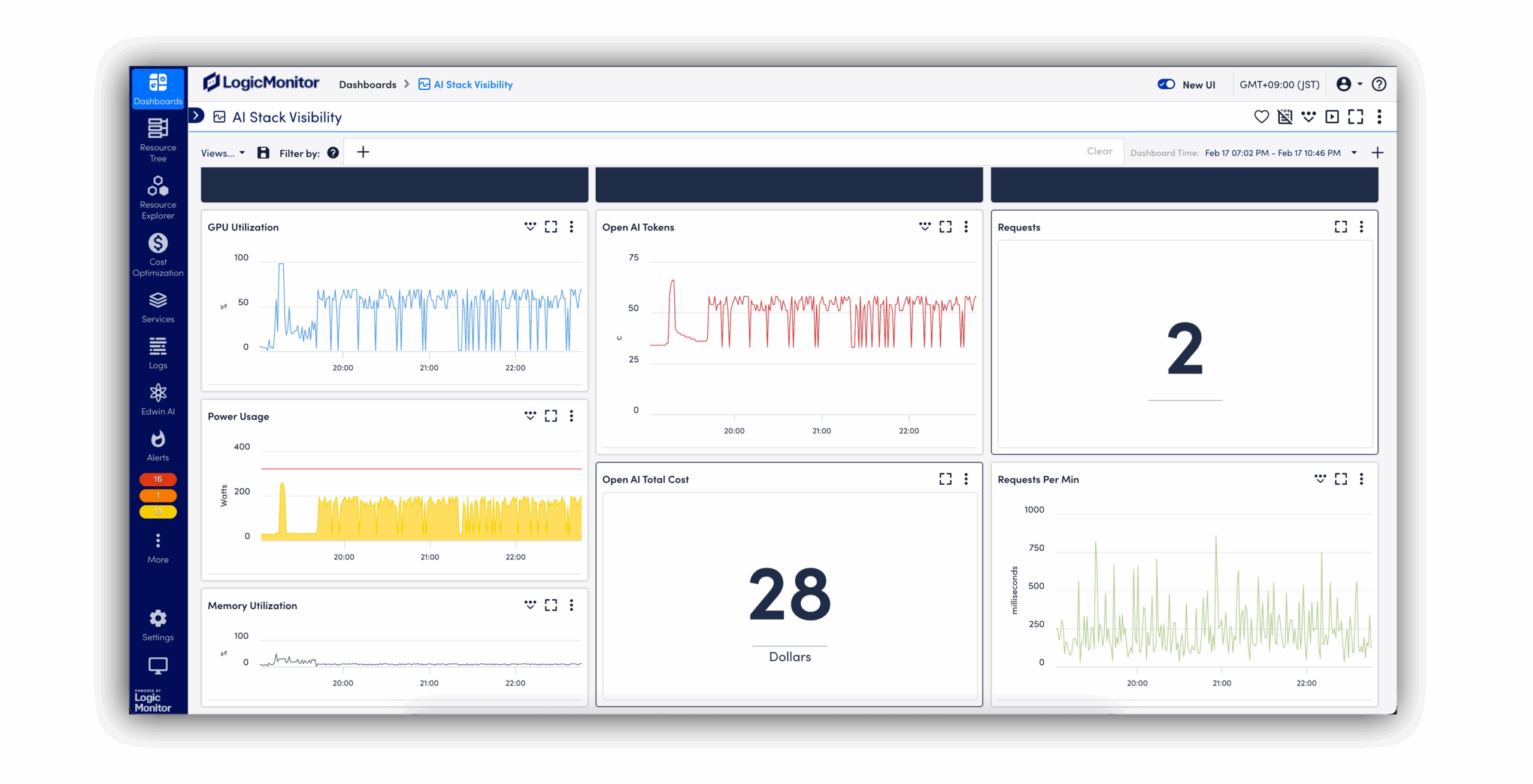
Plateforme d’AI Observability
Visibilité unifiée et Contrôle total de tous vos systèmes IA
LogicMonitor Envision rassemble métriques, événements, logs et traces issus de vos systèmes IA, de votre infrastructure on-prem et de vos services cloud dans une vue unique. Cette observabilité IA vous aide à détecter les problèmes avant qu’ils ne s’aggravent, à optimiser la gestion des coûts et à garantir la fiabilité de vos services.
CHIFFRES CLÉS
Une supervision réseau qui fait la différence
Obtenez une visibilité full-stack sur l’ensemble de votre environnement IA et IT
Des LLM et des GPU aux réseaux et aux bases de données, tout est visible dans une vue unifiée, pour mettre fin au changement permanent de contexte et se concentrer sur la résolution des incidents.
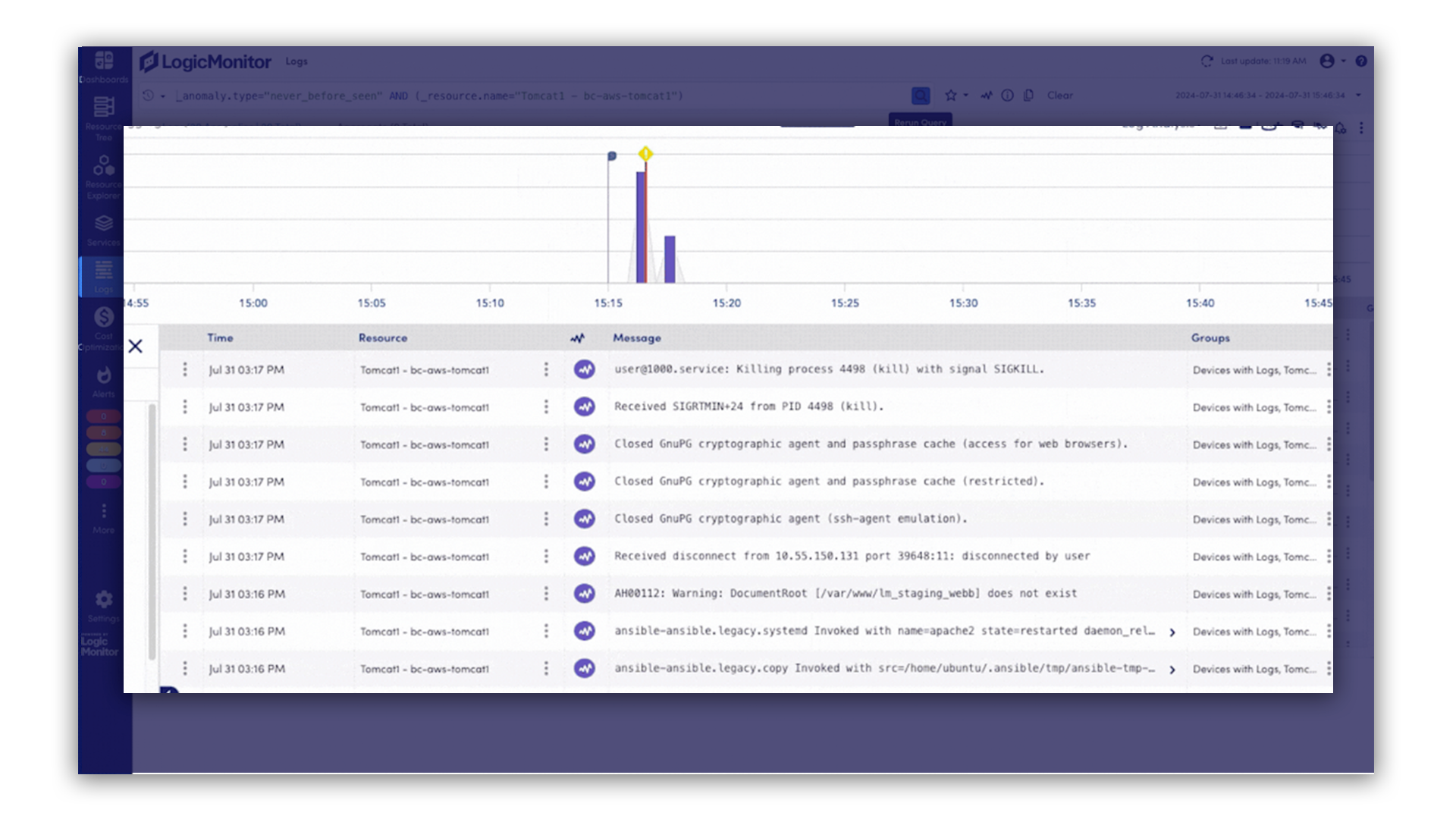
Détectez les problèmes et corrigez-les avant qu’ils n’impactent vos clients
Quand un incident survient, vous savez immédiatement où chercher et comment le corriger rapidement. LM Envision détecte les incidents en amont, et Edwin AI vous aide à identifier la cause racine sans les habituelles approximations, ni les bascules incessantes entre outils.
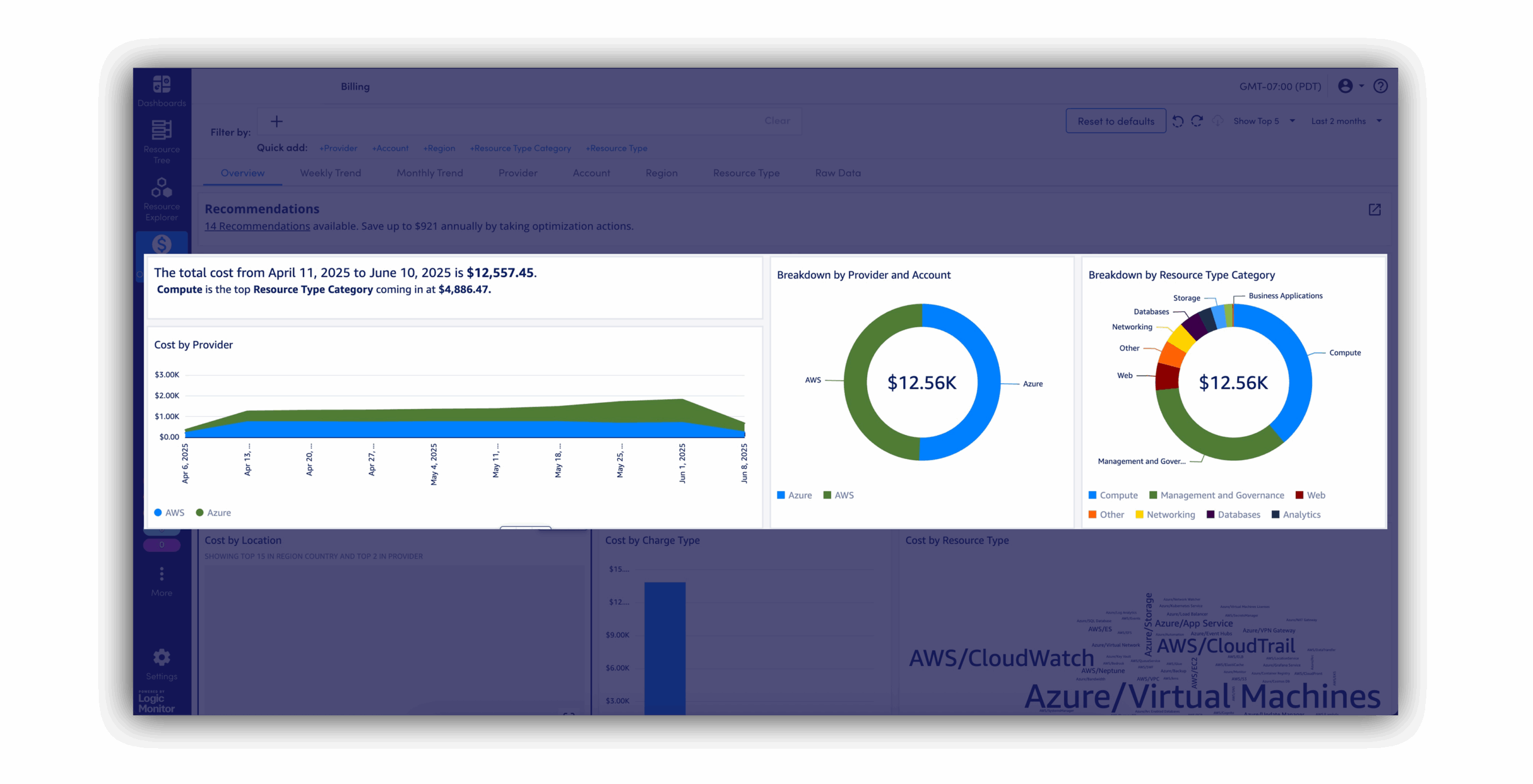
Maîtrisez votre budget IA sans lever le petit doigt
Réduisez les coûts et respectez vos budgets en identifiant automatiquement les ressources inactives et la puissance de calcul gaspillée avant qu’elles ne fassent grimper vos dépenses.
Faites évoluer votre environnement IA sans multiplier les outils ni les complications
De nouveaux systèmes sont déployés, et LM Envision les détecte automatiquement, vous offrant une visibilité instantanée sans licences supplémentaires ni configuration manuelle.
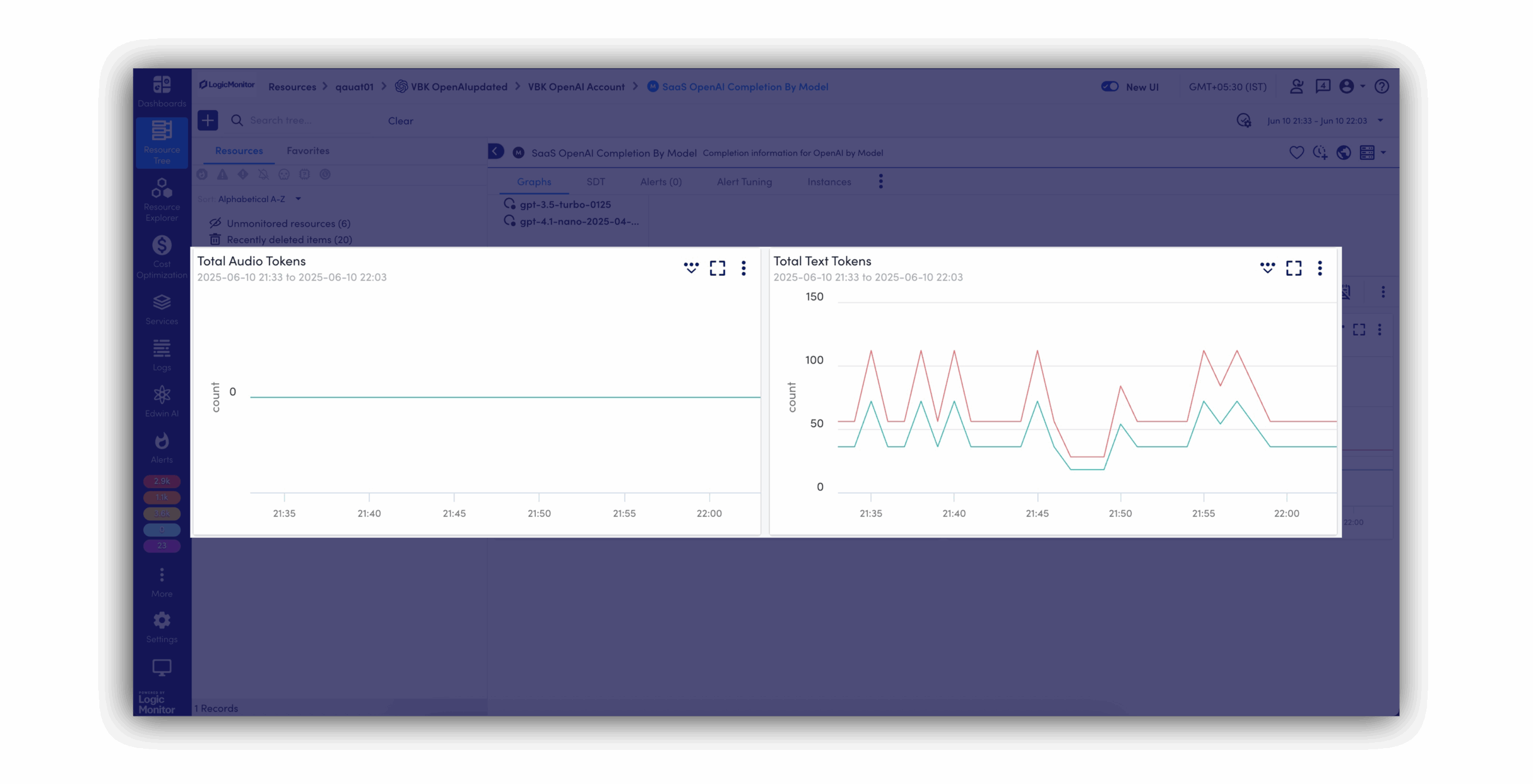
Protégez votre stack IA de bout en bout
Gardez le contrôle sur qui accède à quoi, et depuis où. Au moindre écart, vous le détectez avant qu’il ne devienne un problème.
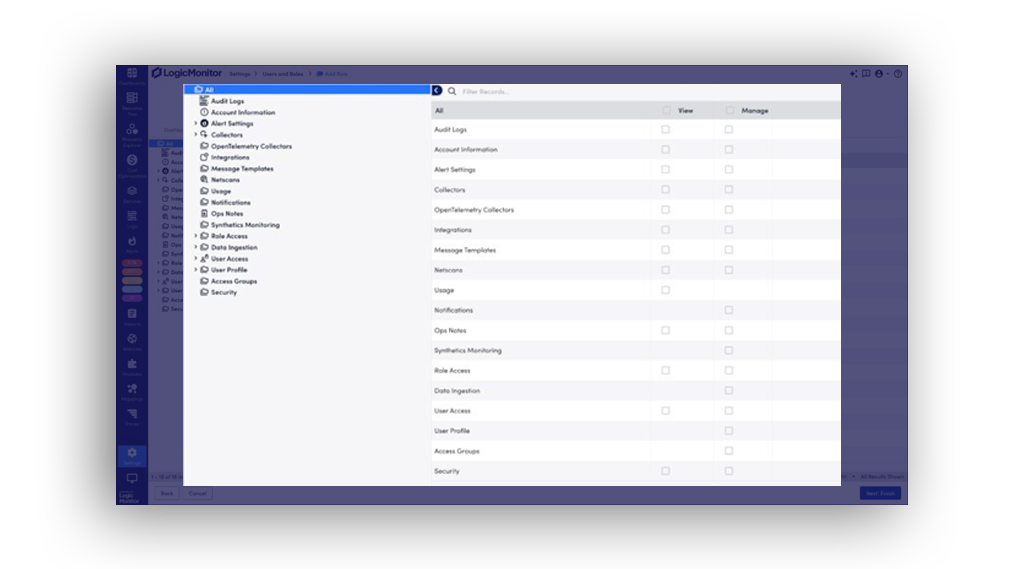
Générez en quelques minutes des rapports prêts pour les comités de direction
Transformez rapidement des métriques complexes, comme les dépenses IA, la disponibilité et la posture de sécurité, en tableaux de bord clairs, prêts pour les dirigeants, qui favorisent l’alignement et l’action.
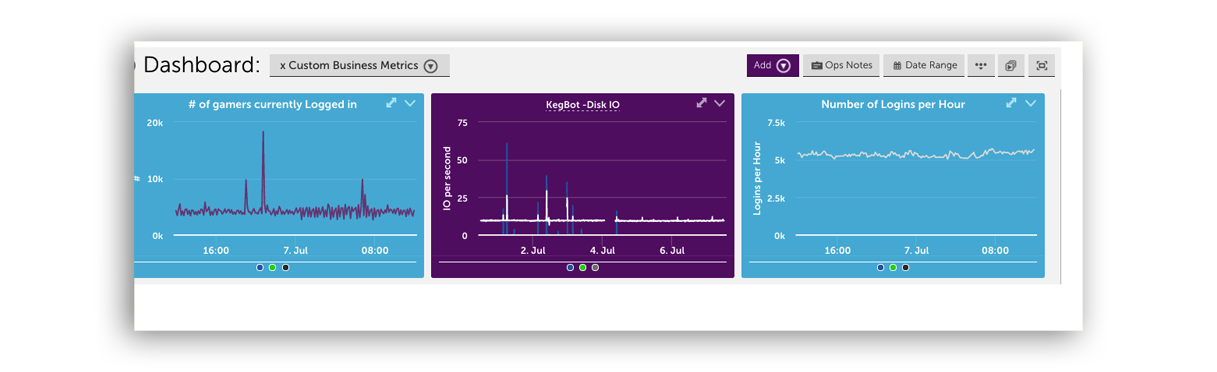
Rendez votre ITOps encore plus intelligent
Edwin AI : l’AIOps agentique pour la gestion des incidents
Edwin AI vous aide à détecter les problèmes plus tôt, à réduire le bruit et à résoudre les incidents rapidement. Grâce à l’IA générative intégrée, il corrèle automatiquement les alertes, met en évidence la cause racine et fournit des instructions étape par étape pour corriger les problèmes avant même que les clients ne s’en aperçoivent.
Conçu pour les charges de travail IA
Tout ce dont vous avez besoin pour superviser, piloter et optimiser l’IA
Unifiez l’ensemble de vos télémétries liées à l’IA pour éliminer les angles morts.
-
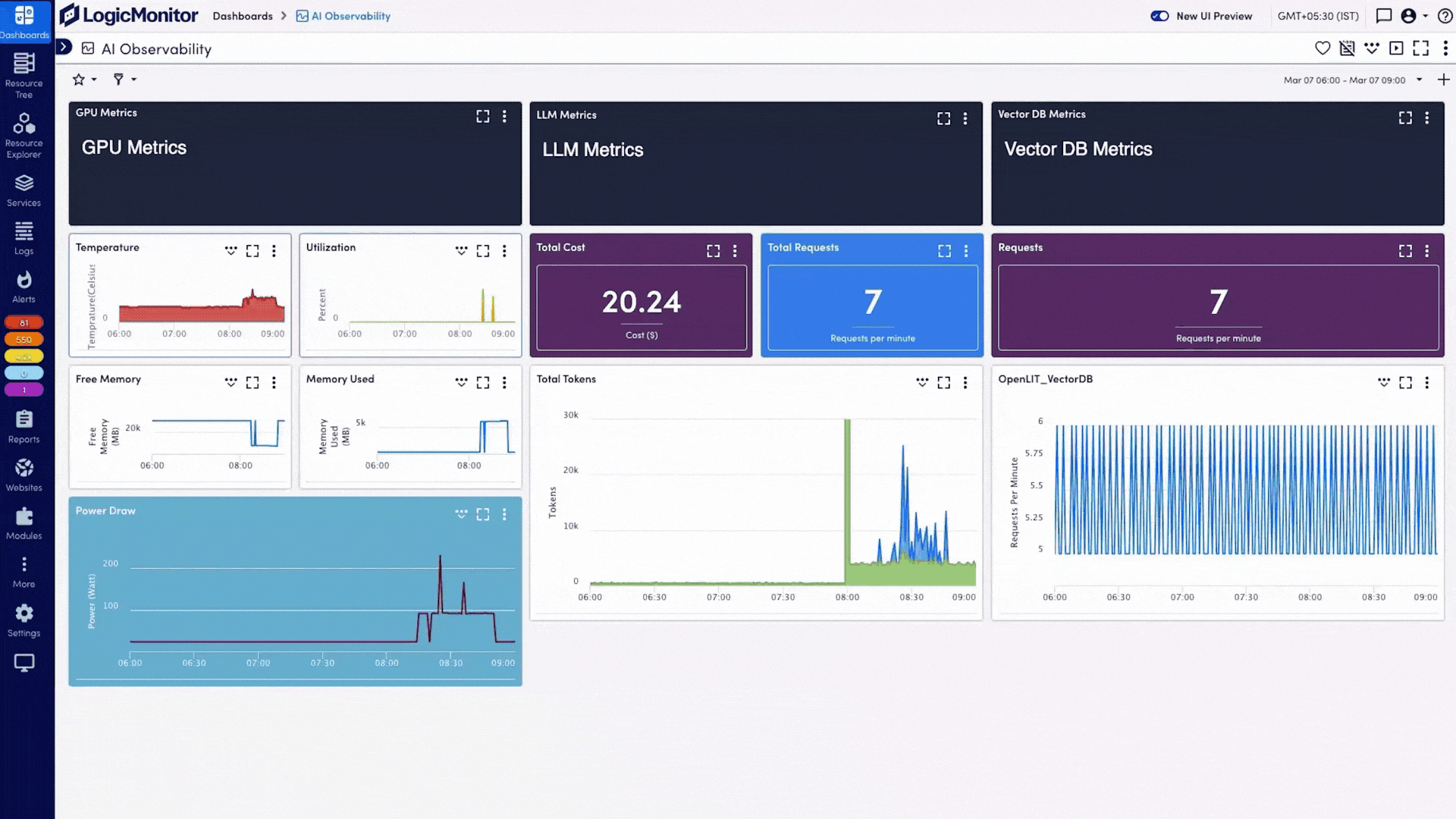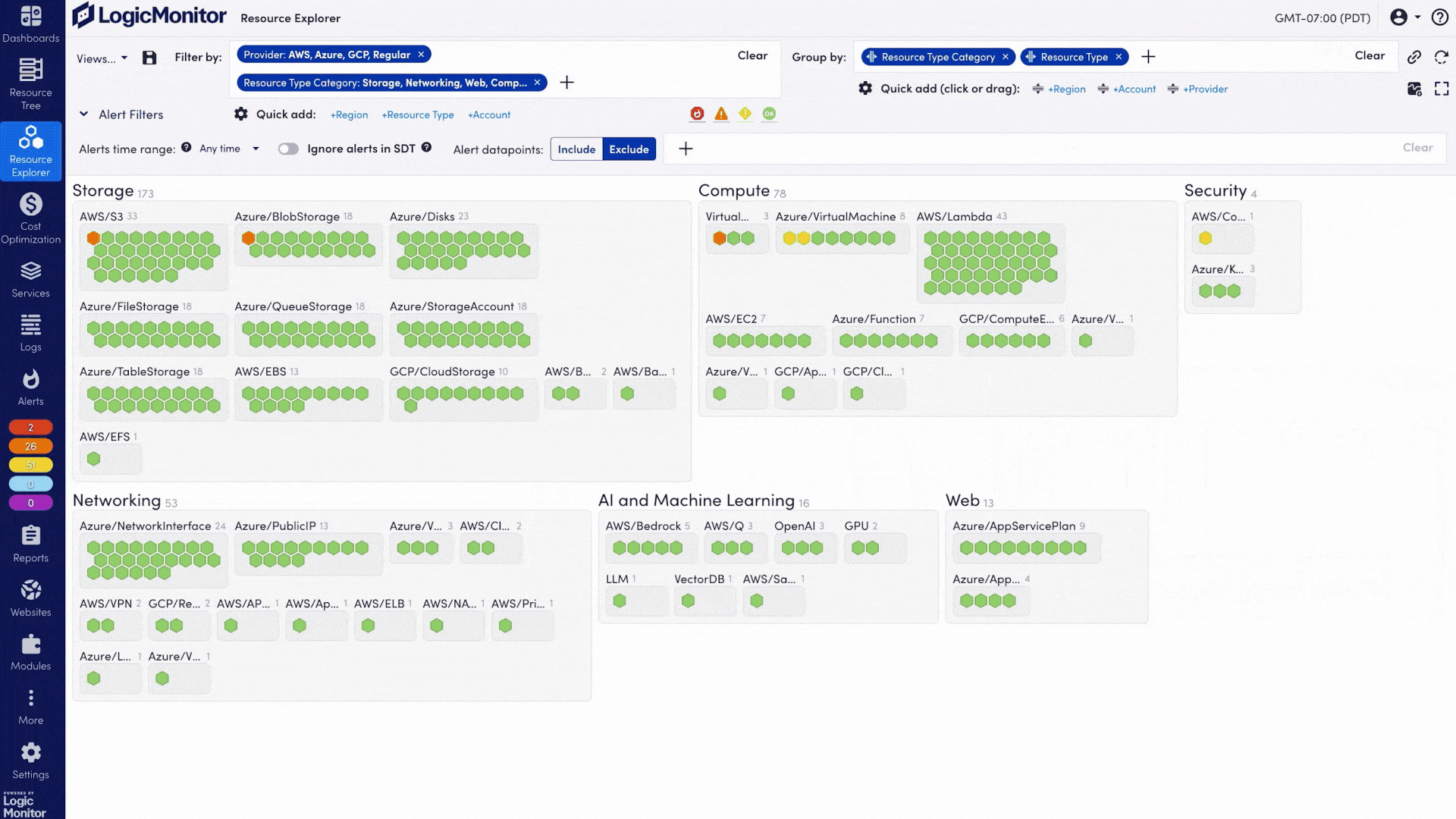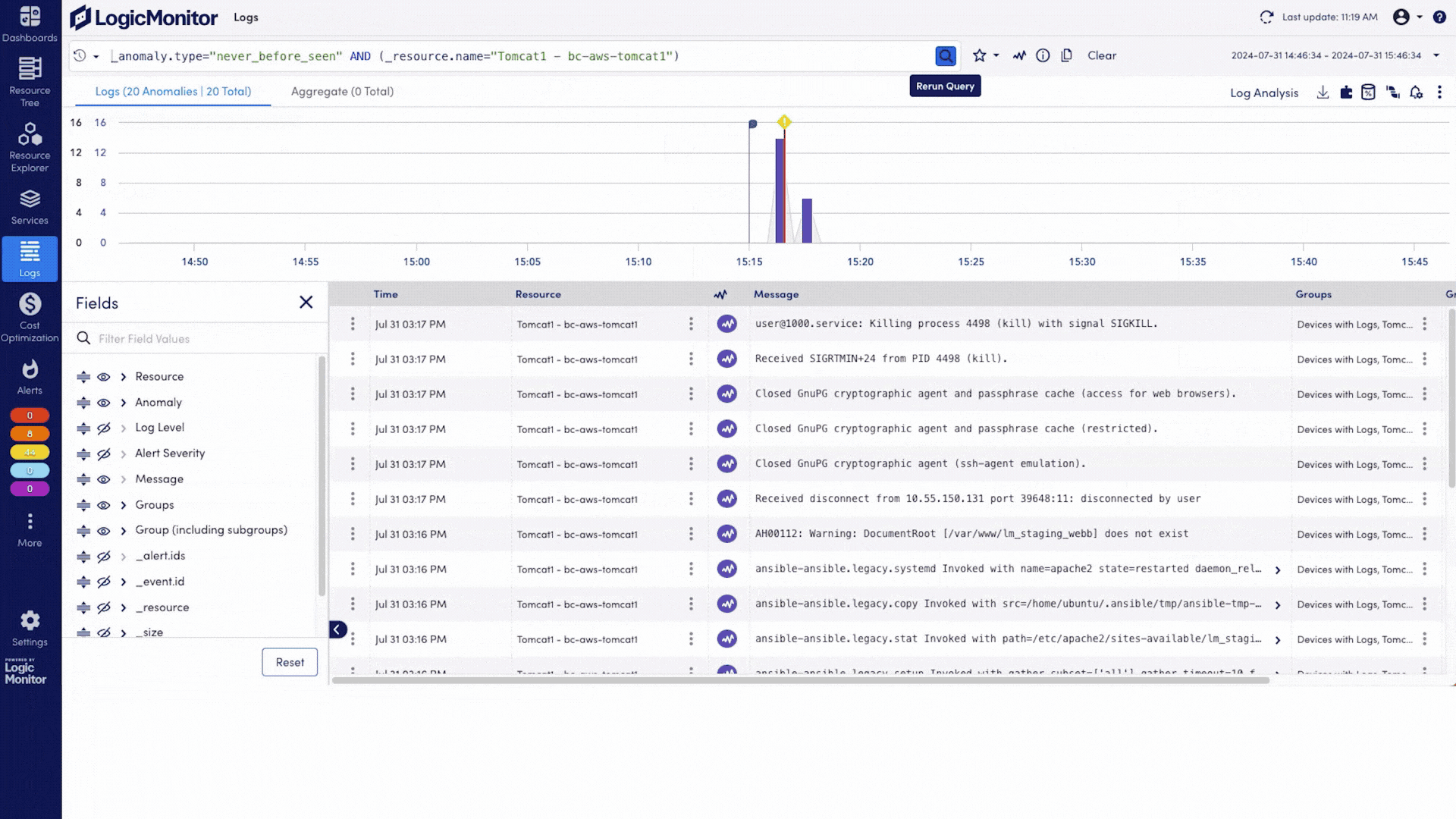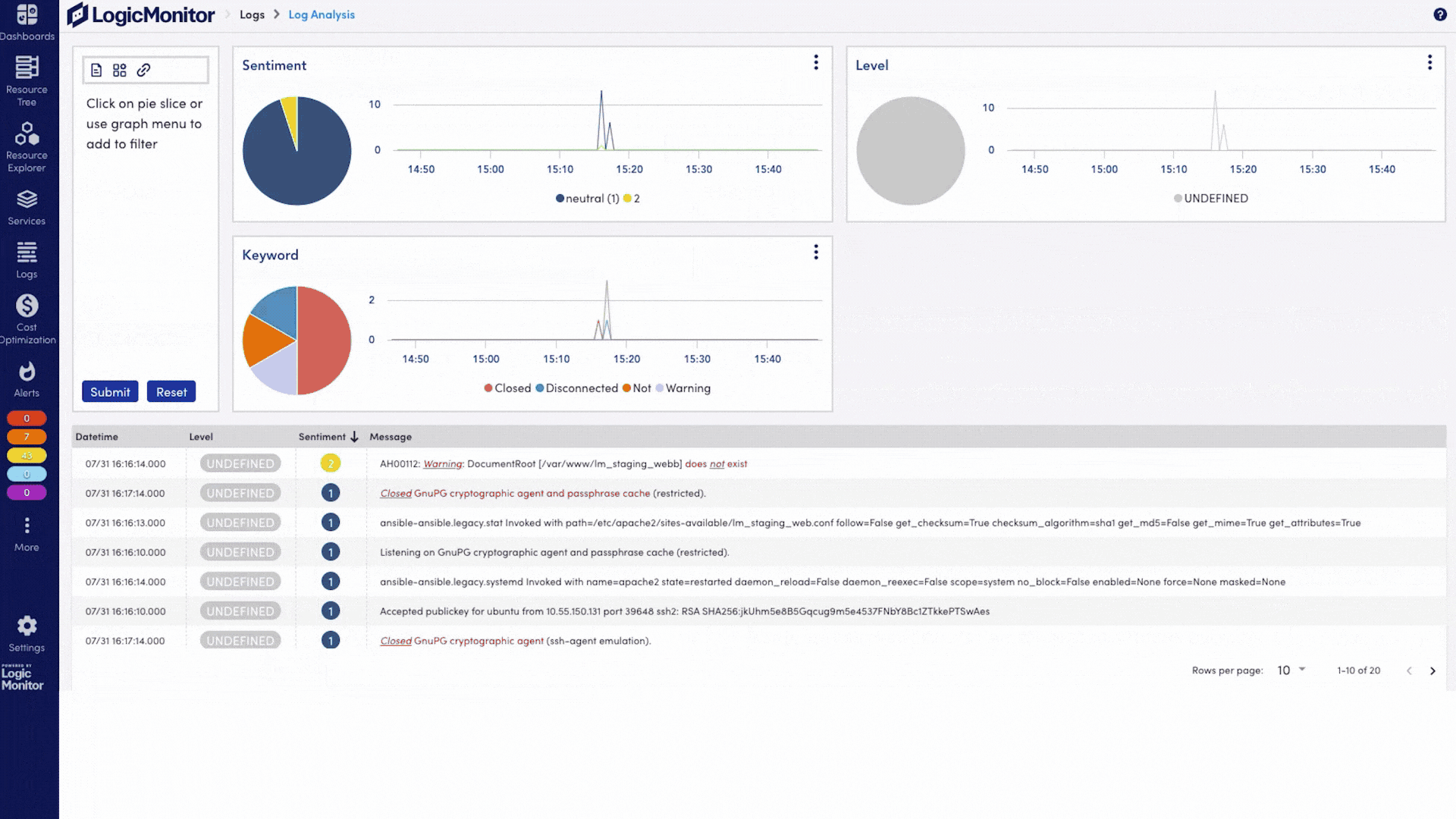
Métriques GPU et calcul Collectez l’utilisation, la mémoire, la température et la consommation énergétique des GPU NVIDIA, on-premise et cloud, avec la découverte automatique de nouveaux clusters.
-
Télémétrie LLM et API Intégrez les volumes de tokens, la latence des appels API, les taux d’erreur et le coût par requête depuis OpenAI, AWS Bedrock, Azure OpenAI et GCP Vertex AI.
-
Visibilité des bases de données vectorielles Collectez le volume de requêtes, la latence en lecture/écriture et la taille des index depuis les clusters Pinecone et ChromaDB nativement.
Visualisez toutes les métriques IA et infrastructure dans une seule vue unifiée.
-
Vue unifiée Affichez les métriques des LLM, GPU et bases vectorielles aux côtés des données serveurs et réseau existantes, dans une vue unique et défilante.
-
Modèles prêts à l’emploi Accédez à des tableaux de bord dédiés à l’IA, livrés par défaut avec LM Envision.
-
Tableaux de bord personnalisés Créez et organisez vos widgets par glisser-déposer pour adapter les vues à chaque équipe ou rôle.
Edwin AI comprend le comportement normal de votre environnement et ne fait ressortir que les signaux réellement importants.
-
Moteur de détection d’anomalies Identifie automatiquement les comportements anormaux sur les LLM, GPU, API et pipelines, sans nécessiter de seuils manuels.
-
Alertes basées sur des seuils Définissez des seuils personnalisés pour chaque métrique et recevez des notifications lorsque les valeurs dépassent ou passent sous les limites définies.
-
Suppression du bruit Éliminez automatiquement les alertes redondantes ou de faible priorité afin que seules les alertes réellement critiques déclenchent des notifications.
Tracez chaque requête pour identifier les causes racines en quelques secondes.
-
Traçage de bout en bout Instrumentez les pipelines d’inférence (appel API → framework LLM → exécution GPU → réponse) pour suivre le chemin des requêtes et identifier les goulets d’étranglement.
-
Insights sur les chaînes de services Collectez et corrélez les métriques provenant d’Amazon SageMaker, d’AWS Q Business, des pods Kubernetes, des agents LangChain et d’autres composants middleware.
-
Cartographie de la topologie hybride Découvrez et cartographiez automatiquement les relations entre hôtes on-premise, VM cloud et clusters de conteneurs, avec une mise à jour continue à mesure que de nouvelles ressources apparaissent.
Anticipez vos coûts grâce à la prévision des dépenses IA et à des recommandations budgétaires.
-
Répartition des coûts des tokens Ventilez les dépenses IA par modèle, application ou équipe via des tableaux de bord de coûts intégrés.
-
Détection des ressources inactives Identifiez les GPU et shards de bases vectorielles sous-utilisés afin de révéler des opportunités de consolidation.
-
Prévisions et alertes budgétaires Exploitez les métriques historiques pour prévoir les dépenses en tokens ou l’utilisation GPU du mois suivant et définir des alertes de seuil budgétaire.
Combinez les événements de service et les journaux de sécurité pour détecter les activités non autorisées et exporter instantanément des logs prêts pour audit.
-
Événements de sécurité unifiés Centralisez les logs et alertes de sécurité (pare-feu, VPN, endpoints) en parallèle des événements des services IA, afin d’identifier les appels API non autorisés, les lancements de conteneurs suspects et les anomalies d’accès aux données.
-
Journalisation d’audit Conservez et exportez les logs et instantanés de métriques à tout moment pour répondre aux exigences de conformité (p. ex., HIPAA, SOC 2) et faciliter les audits.
Nous n’avions pas une vision complète. Depuis le déploiement de LogicMonitor, nous disposons d’un outil unique et d’un point d’accès centralisé pour observer l’ensemble de notre infrastructure. Les gains de temps sont considérables. Je ne peux même pas les chiffrer précisément, mais je dirais des centaines d’heures.
Intégrations
Exploitez les plus de 3 000 intégrations existantes de LM Envision (serveurs, réseaux, stockage, APM, CMDB) pour alimenter les télémétries d’infrastructure et d’applications, aux côtés des données IA. Explorez les intégrations
Transmettez des détails d’incident enrichis, incluant le contexte GPU, LLM et bases de données, vers ServiceNow, Jira et Zendesk, avec une synchronisation bidirectionnelle pour les mises à jour de statut.
Activez des plugins pour OpenAI, AWS Bedrock, Azure OpenAI, GCP Vertex AI, Pinecone, ChromaDB, NVIDIA DCGM et OpenLIT ; chaque connecteur ingère automatiquement les métriques requises.
Découvrez ce que l’observabilité IA peut apporter à votre stack
Découvrez comment LogicMonitor vous aide à superviser vos systèmes IA depuis un point unique. Votre équipe gagne en rapidité, avec moins de surprises.
DES RÉPONSES À VOS QUESTIONS
FAQ
Les réponses aux questions les plus fréquentes sur la supervision réseau.
Qu’est-ce que l’observabilité IA ?
L’observabilité IA est la capacité à surveiller et comprendre le comportement des systèmes d’IA en production. Elle aide les équipes à détecter la dérive des modèles, identifier les latences et repérer les défaillances silencieuses en réunissant les signaux de l’infrastructure, des modèles et des applications dans une vue unique.
En quoi l’observabilité IA diffère-t-elle de la supervision traditionnelle ?
La supervision traditionnelle surveille le CPU, la mémoire et la disponibilité. L’observabilité IA relie ces signaux au comportement des modèles, comme les variations de sorties, les ralentissements de performance et les comportements inhabituels des agents.
Quand faut-il mettre en place l’observabilité IA ?
Idéalement avant la mise en production. Il est bien plus simple de suivre vos systèmes IA dès le premier jour que de corriger des angles morts plus tard.
LogicMonitor peut-il détecter des problèmes comme la dérive ou la latence ?
Oui. LogicMonitor surveille les schémas inhabituels dans le comportement des systèmes et des modèles, comme des réponses lentes, des pics de sortie inattendus ou des changements d’usage indiquant des problèmes IA plus profonds.
Faut-il des agents ou une instrumentation personnalisée pour démarrer ?
Non. LogicMonitor repose sur un modèle sans agent avec des intégrations natives. Vous pouvez commencer à superviser votre stack IA rapidement, sans configuration complexe.
