KI-Observability für Infrastruktur, Workloads und Pipelines in einer Plattform
Vereinheitlichen Sie alle Signale Ihrer KI-Umgebung, um von reaktivem Firefighting zu strategischen, datenbasierten Entscheidungen zu gelangen.
Entdecken Sie unsere Ressourcenbibliothek für IT-Profis. Erhalten Sie Expertenleitfäden, Observability-Strategien und praxisnahe Einblicke für intelligentere, KI-gestützte IT-Operations.
Ressourcen entdecken


Vereinheitlichen Sie alle Signale Ihrer KI-Umgebung, um von reaktivem Firefighting zu strategischen, datenbasierten Entscheidungen zu gelangen.
Beenden Sie die mühsame Datensuche über verschiedene Tools hinweg. Mit Full-Stack-Transparenz über Ihre KI- und IT-Umgebungen kann Ihr Team schneller agieren, intelligenter Fehler beheben und sich auf das Wesentliche konzentrieren.
Erkennen Sie Anomalien proaktiv, bevor sie Services beeinträchtigen. Dank frühzeitiger Erkennung und fundierter Ursachenanalysen reduzieren Sie Ausfallzeiten und eliminieren Rätselraten.
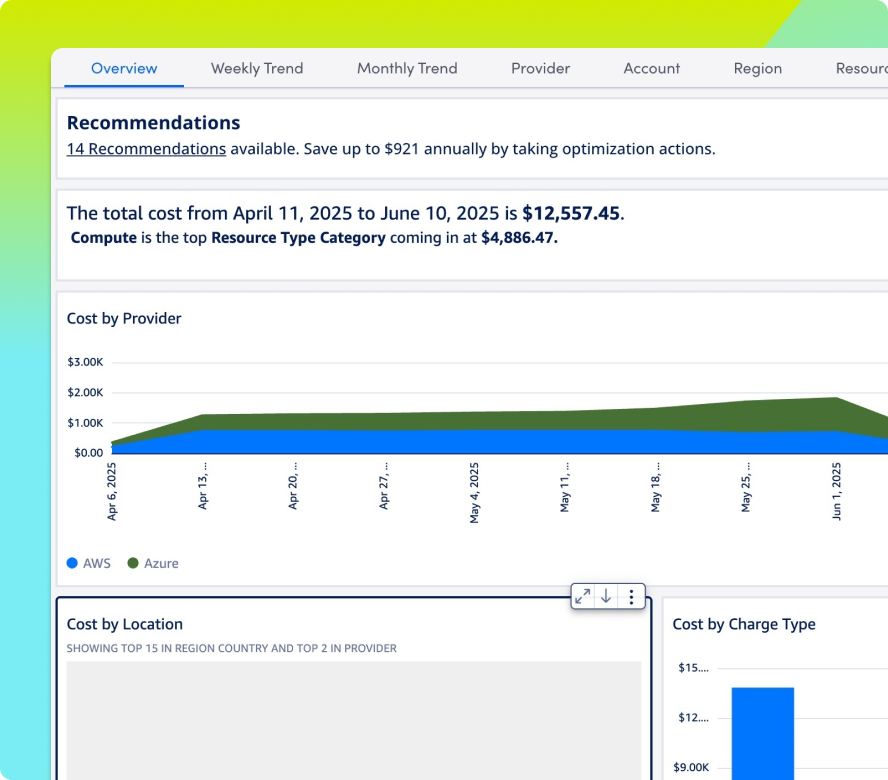
Vermeiden Sie Budgetüberraschungen durch integrierte Transparenz über ungenutzte Ressourcen, unterausgelastete GPUs und ausufernde Compute-Kosten – bevor sie Ihr Budget belasten.
Wenn sich Ihr Stack weiterentwickelt, bleibt LogicMonitor Schritt. Neue Systeme werden automatisch erkannt – ohne manuellen Aufwand und ohne Überwachungslücken.
Überwachen Sie Zugriffe, Nutzung und Systemverhalten über Ihre gesamte KI-Landschaft hinweg. Erkennen Sie ungewöhnliche Aktivitäten frühzeitig, bevor sie zu Sicherheitsvorfällen oder Serviceunterbrechungen werden.
Übersetzen Sie komplexe Kennzahlen wie KI-Kosten, Verfügbarkeit und Systemperformance in verständliche, handlungsorientierte Dashboards – für bessere Abstimmung, gezielte Investitionen und fundierte Entscheidungen.
Volle Observability mit LogicMonitor Envision und Edwin AI
Mit Echtzeit-Transparenz, automatischer Erkennung und KI-gestützter Korrelation hilft LM Envision, jede Ebene Ihrer KI-Infrastruktur zu überwachen – damit Sie Ausfallzeiten verhindern, Kosten steuern und schnell handeln können.
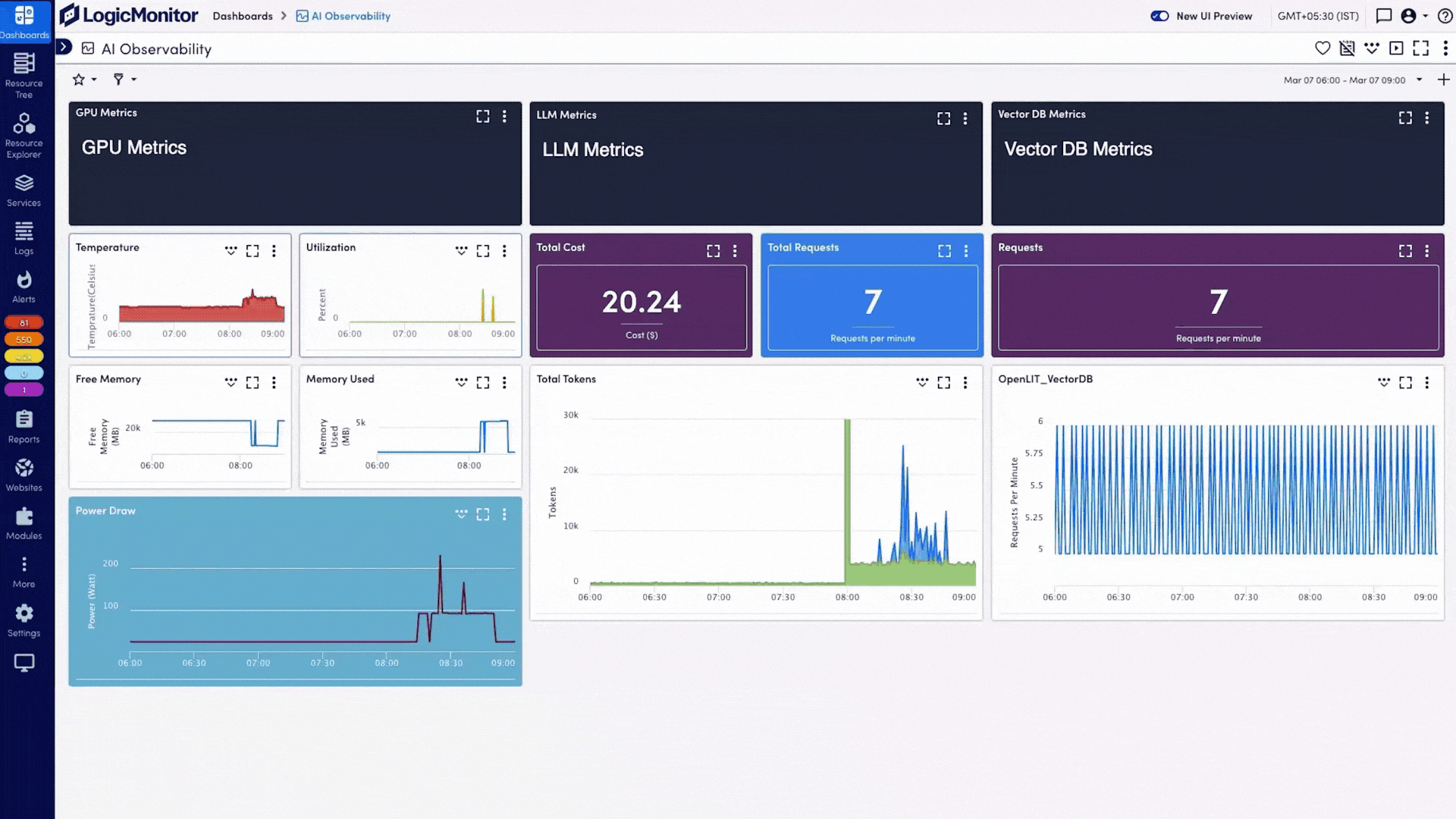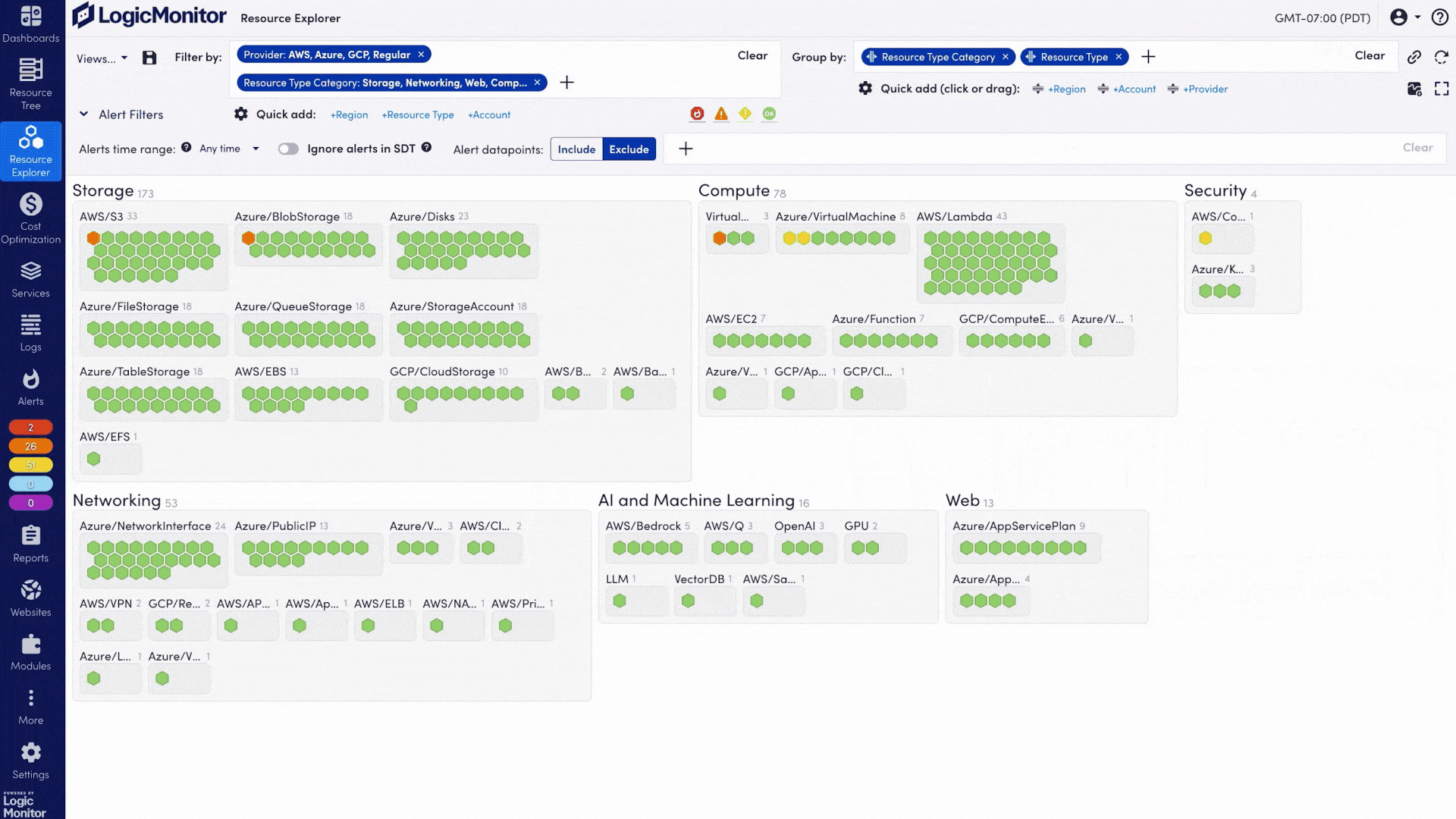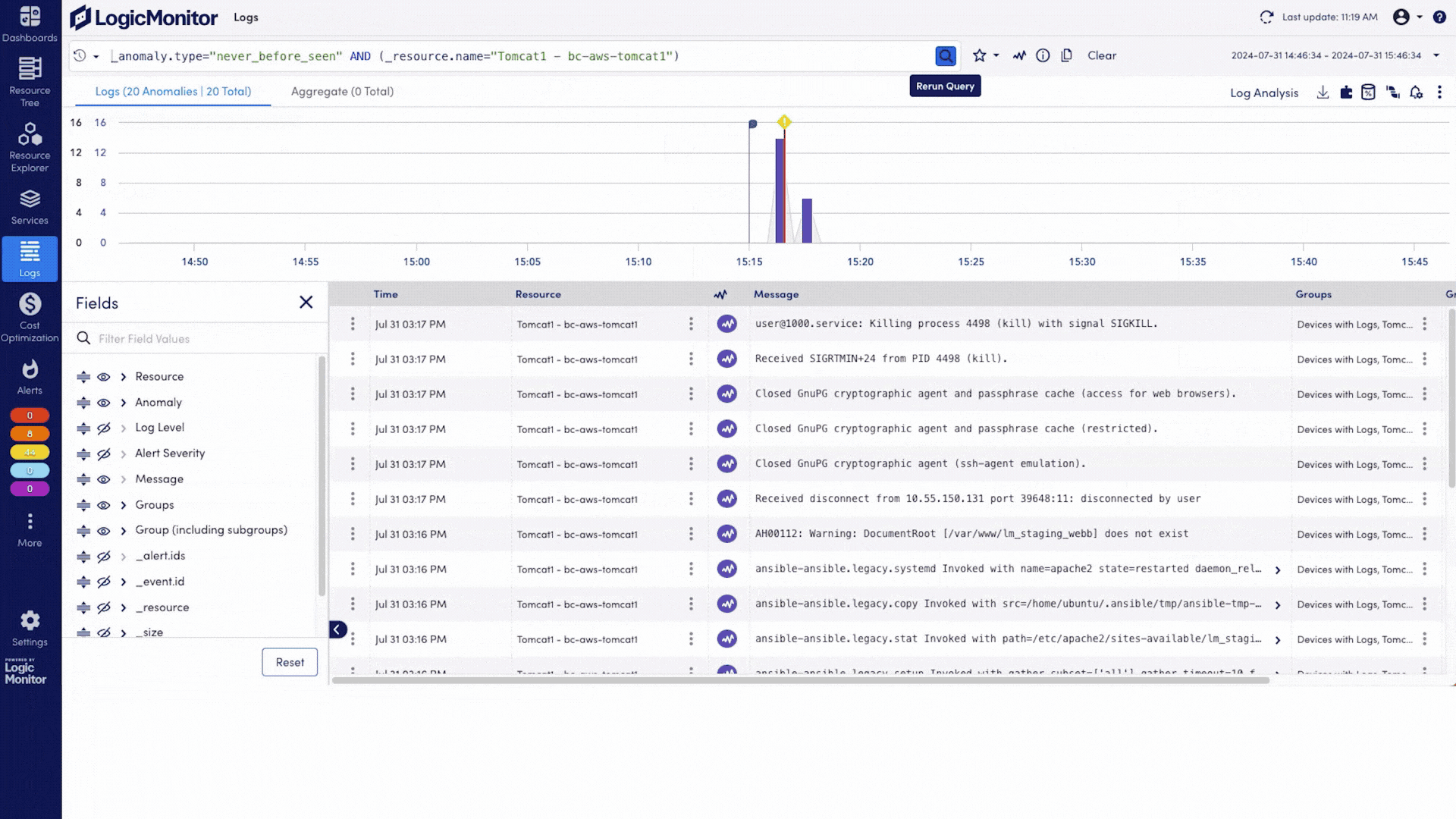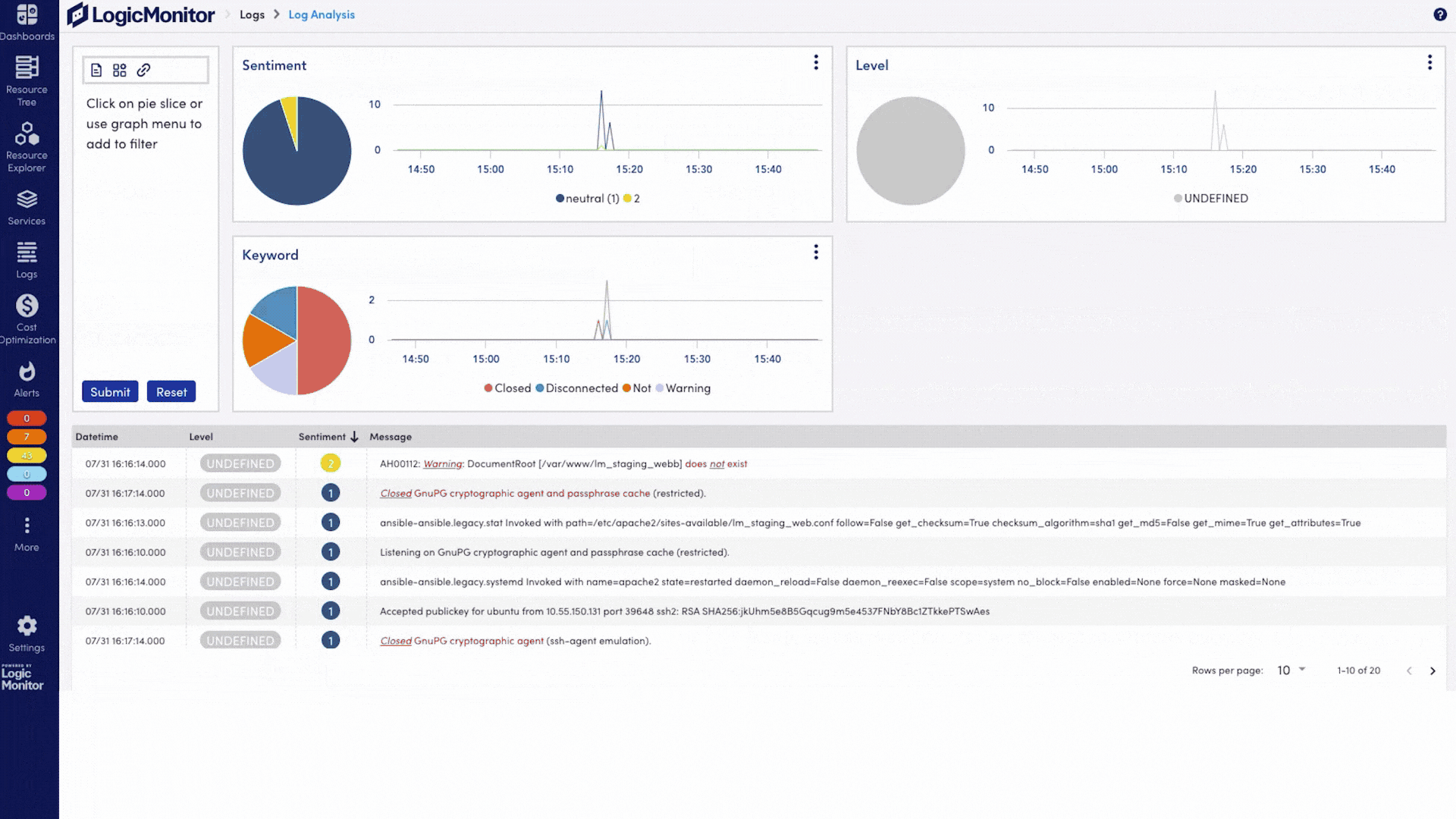
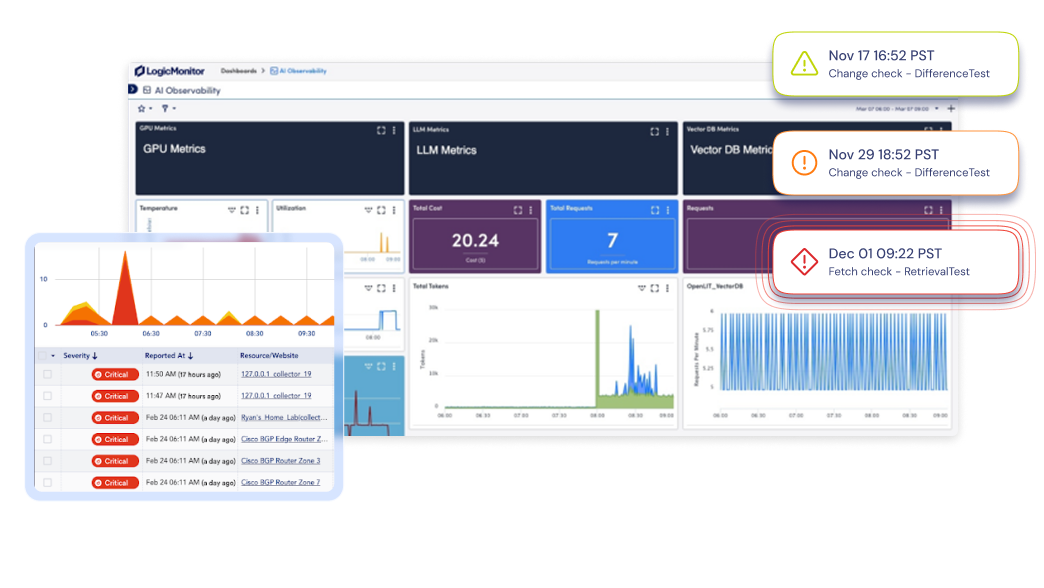
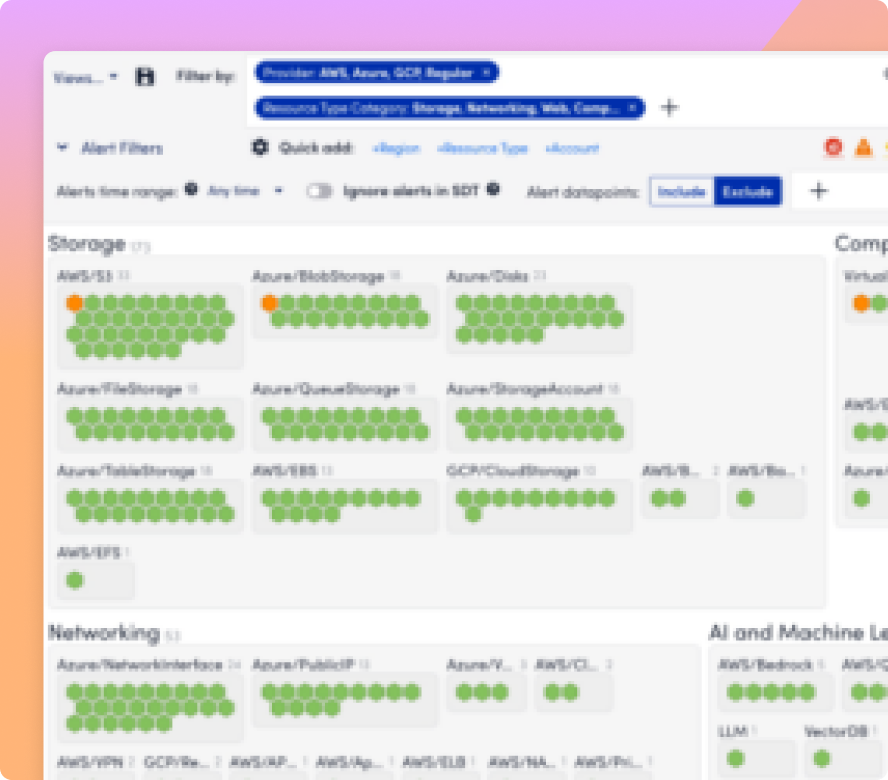
Führen Sie GPU-Metriken, LLM-Performance und Vektor-Datenbank-Kennzahlen in einer zentralen Ansicht zusammen. So vermeiden Sie blinde Flecken und überwachen jede Ebene Ihres KI-Stacks.

Stellen Sie GPU-, LLM-, Vektor-DB- und Infrastrukturmetriken nebeneinander dar – mit vorkonfigurierten Dashboards oder individuell gestalteten Ansichten.
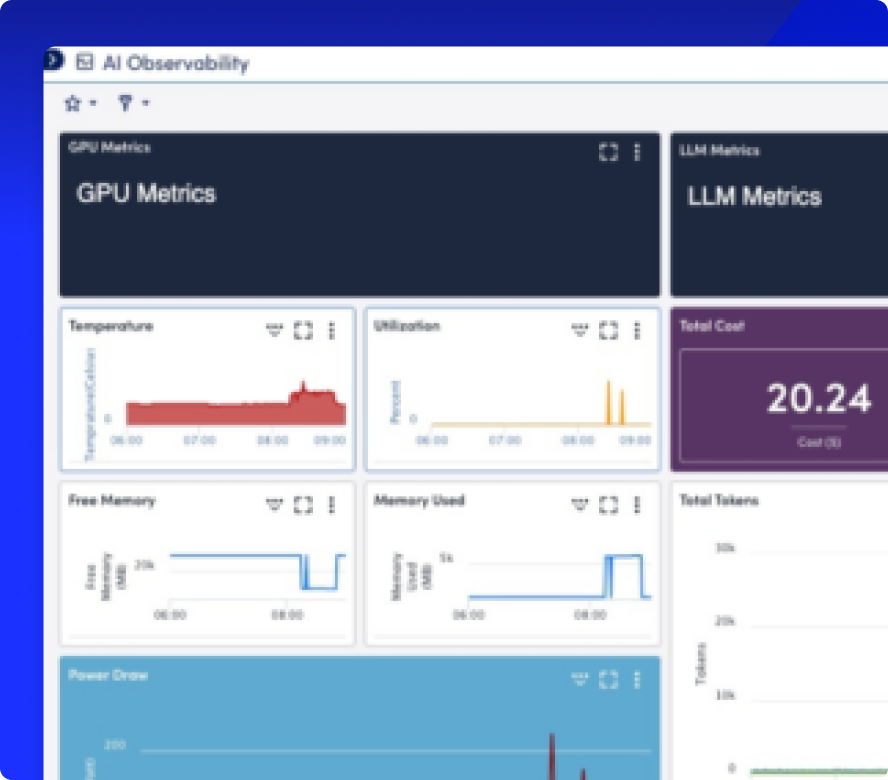
Erkennen Sie ungewöhnliches Verhalten frühzeitig mit Anomalieerkennung, setzen Sie metrikenbasierte Schwellenwerte und unterdrücken Sie unwichtige Alarme – damit sich Teams auf relevante Incidents konzentrieren können.
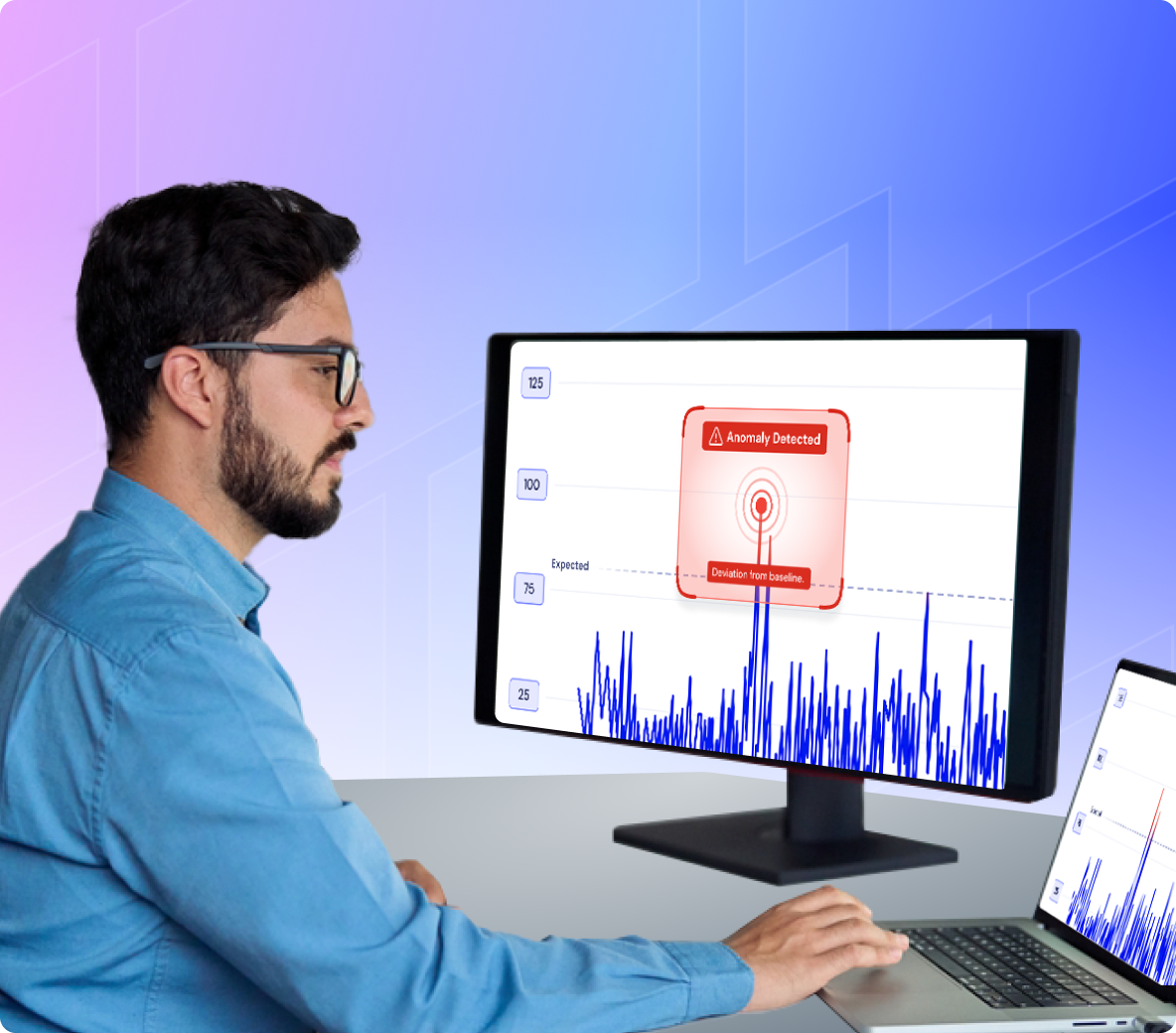
Visualisieren Sie Inferenz-Pipelines, Service-Abhängigkeiten und hybride Topologien, um Latenzen gezielt zu identifizieren und Probleme schneller zu beheben.
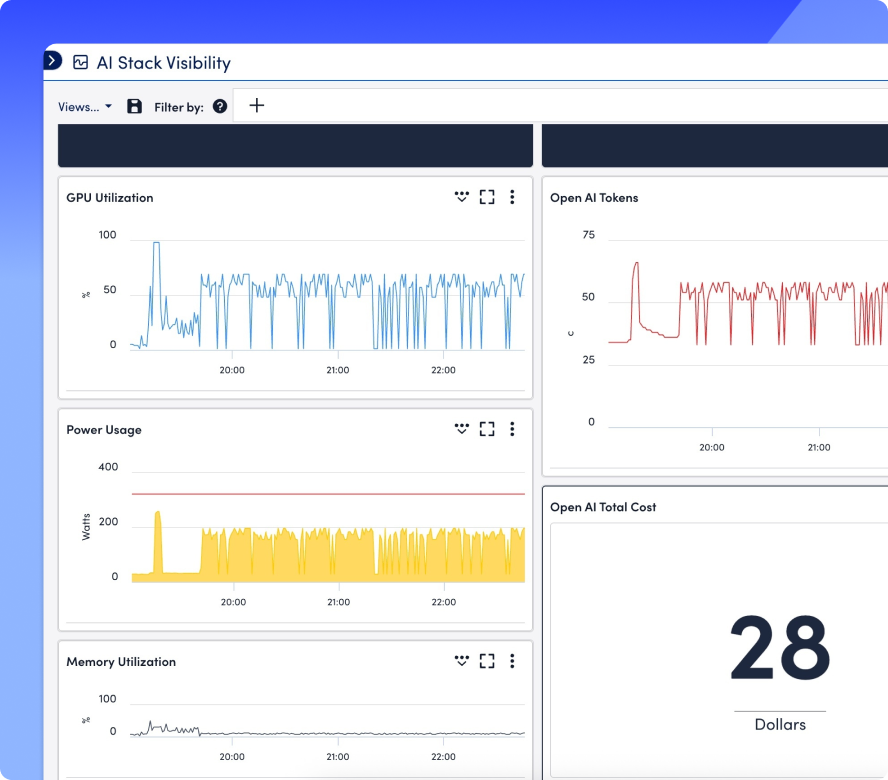
Analysieren Sie Token-Verbrauch und GPU-Kosten, erkennen Sie ungenutzte Ressourcen und setzen Sie Budgetwarnungen mit integrierten Prognosefunktionen – speziell für KI-Workloads entwickelt.
Ingestieren Sie KI-spezifische und infrastrukturelle Logs, erkennen Sie Anomalien, überwachen Sie Zugriffsmuster und exportieren Sie auditfähige Logs für Compliance-Anforderungen wie HIPAA und SOC 2.
INTEGRATIONEN
LM Envision integriert sich mit über 3.000 Technologien – von Infrastruktur- und ITSM-Tools bis hin zu KI-Plattformen und Modell-Frameworks. Erfassen Sie Metriken aus GPUs, LLMs, Vektor-Datenbanken und Cloud-KI-Services und synchronisieren Sie automatisch angereicherte Incident-Kontexte mit Tools wie ServiceNow, Jira und Zendesk.
100%
Collector-basiert und API-freundlich
3,000+
Integrationen, stetig wachsend
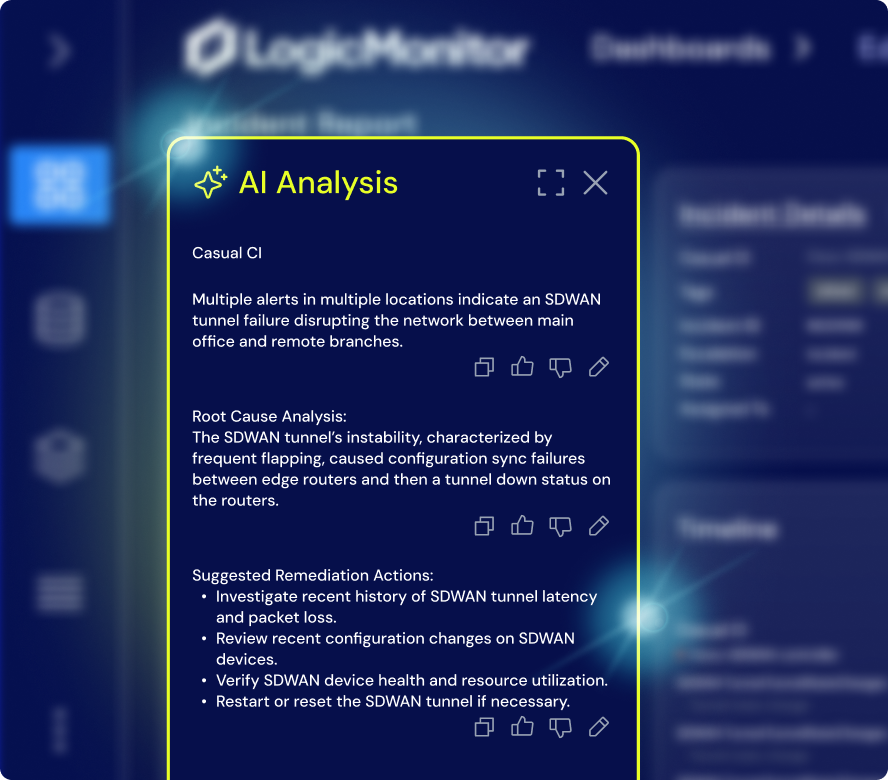
KI-Agent für ITOps
Edwin AI nutzt agentische AIOps, um ITOps zu optimieren: Alarmflutn wird reduziert, die Triage automatisiert und die Problemlösung selbst in komplexesten Umgebungen beschleunigt. Kein manuelles Zusammenführen. Kein Tool-Hopping.
67%
weniger ITSM Incidents
88%
weniger Alarmflut
Zahlen & Fakten
Antworten erhalten
Erhalten Sie Antworten auf die wichtigsten Fragen zum KI-Monitoring.
KI Observability beschreibt die Fähigkeit, das Verhalten von KI-Systemen im Produktivbetrieb zu überwachen und zu verstehen. Sie hilft Teams, Model Drift zu erkennen, Latenzen zu identifizieren und stille Fehler aufzudecken, indem Daten aus Infrastruktur, Modellen und Anwendungen in einer zentralen Sicht zusammengeführt werden.
Klassisches Monitoring überwacht Kennzahlen wie CPU, Speicher und Verfügbarkeit. KI Observability geht einen Schritt weiter und verknüpft diese Daten mit dem Verhalten von Modellen – etwa Änderungen in Outputs, Performance-Einbußen oder ungewöhnliches Verhalten von Agents.
Idealerweise vor dem Produktivstart. Es ist deutlich einfacher, KI-Systeme von Anfang an zu überwachen, als später fehlende Transparenz nachträglich zu schließen.
Ja. LogicMonitor erkennt auffällige Muster im System- und Modellverhalten, wie z. B. verlangsamte Antworten, ungewöhnliche Output-Spitzen oder veränderte Nutzungsmuster, die auf tieferliegende Probleme hinweisen können.
Nein. LogicMonitor arbeitet mit einem Collector-basierten Ansatz und bietet integrierte Integrationen. So können Sie Ihre KI-Umgebung schnell überwachen – ohne aufwendige Konfiguration.
Übernehmen Sie die Kontrolle über Ihre KI-Performance mit
mit LM Envision