Executive Summary
The Infrastructure Visibility Gap is No Longer Acceptable
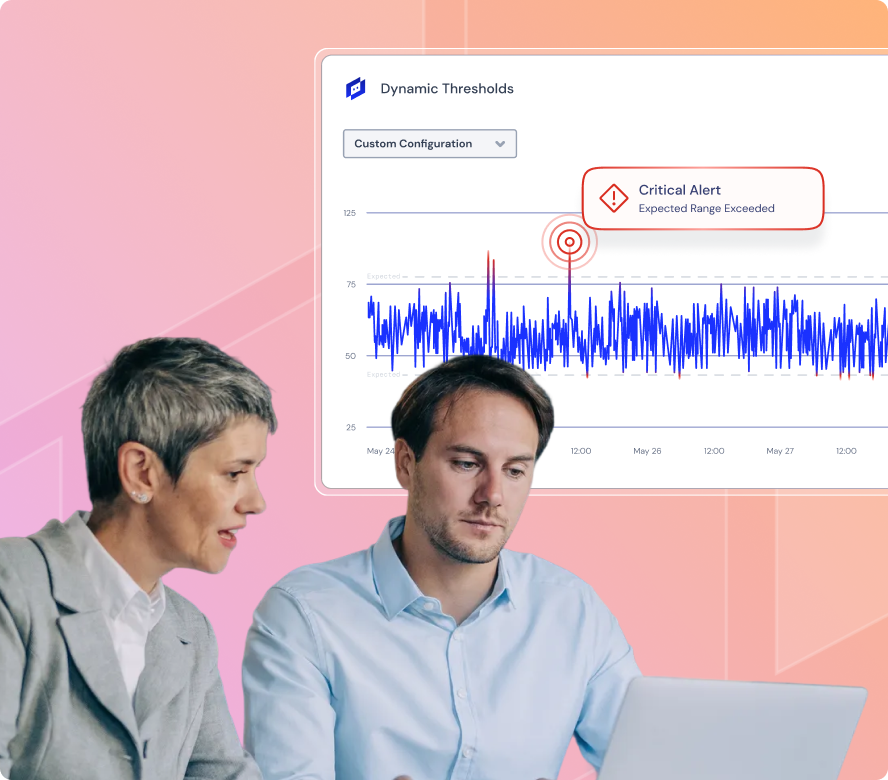
IT operations have outgrown the model they were built on. Enterprises now monitor tens of thousands of metrics, ingest terabytes of logs, and generate thousands of alerts daily, all while managing increasingly complex infrastructures that span on-prem data centers, multiple cloud environments, and emerging AI workloads. Yet despite all this telemetry, too many teams still learn about outages from customers before they see them in their tools.
Recent high-profile outages at CrowdStrike, Cloudflare, and others have demonstrated just how quickly a small issue can ripple across industries, interrupt daily life, and cost companies billions.