Last night, our server monitoring sent me a text alert about the CPU load of a server in our infrastructure I had never seen before. (I’m not normally on the NOC escalation – but of the usual NOC team, one guy is taking advantage of our unlimited vacation policy to recharge in Europe, and two others were travelling en route to Boston to speak at AnsibleFest.) So I got woken up; saw the errant CPU; checked the server briefly via LogicMonitor on my phone; replied to the text with “SDT 6” to put this alert into Scheduled Downtime for 6 hours, and went back to sleep with the CPU still running over 90%.
How, you may ask, did I know it was safe to just SDT this alert, when I had never come across this server before? What if it was a critical piece of our infrastructure, and its high CPU was causing Bad Things? Its name told me.
This particular text alert referred to the CPU load on a server called idm1.dc7. So, this told me two things:
- it was a machine responsible for identity management: not directly customer affecting, our identity management system is used internally. It’s replicated across different datacenters, and worst case, if all the nodes fail, it just locks out ssh access, leaving only console. (And at 2:00 am, even if that was occurring, I doubt any of our team cared much.)
- it was for a machine located in a new datacenter, DC7, which was not yet live with customers.
Had this server been called Gandalf, or Asgard, or some other whimsical name that conveyed no meaning – I would have had to get out of bed to figure out what the server did, and what it’s high load may have been affecting.
Name your hosts to convey meaning. Use a host name scheme that is unambiguous and that conveys location, and function of the server. If the server has many roles (if, say, you run DB, server, and cache on each of many servers in your fleet) you can’t just call them db1, db2 – but you can denote whether they are production, or staging, or QA, and their location, and, if you run a mix, whether they are physical or virtual servers. (vqa2.dc7, for example – a virtual qa server, number 2 of that class, located in the dc7 datacenter. Or vqadb2.dc7, if its purely a database.)
So does this matter for other than not having to get out of bed? Yes – it can save you a ton of work in setting up your monitoring. Using LogicMonitor’s dynamic groups, you can specify that all hosts whose hostname contains the string “DC7” are members of the “DC Datacenter” group. And another group called “QA Systems” may contain all hosts whose name matches “qa” (which may include some hosts already in the DC7 group – no reason you can’t group hosts by location, production stage, and function, simultaneously). This makes it super easy to change alert routing, so you are never woken up by hosts in the QA group – so long as you name them consistently. You can also use dynamic groups to manage thresholds (so QA systems have different thresholds than staging or production systems); or even delegate ownership for monitoring purposes. Hard to do if the QA systems are called Batman, SuperMan, and Hulk, while production systems are IronMan and Thor. (Wait – would SuperMan beat IronMan in a fight? Does that mean SuperMan is production? Not what you want to be thinking at 2:00 am…)
Consistency in naming conventions extends beyond hostnames – all logical objects are better off having a logically constructed name. For example, storage arrays are often expensive systems, and thus may be shared amongst departments. If there are many storage arrays, and each has many volumes – it’s easy to create an aggregate graph showing space usage for a business unit if the volumes are consistently named. Configuring monitoring to graph the sum of the space used for all volumes matching “/vol/*retail*” is easy. Figuring out that the retail unit owns the volumes “sales01”, “retmail”, “backup.orig”, and “sales03”, but not “salesmain” – is impossible. Or a single graph showing all space used on the database SSDs is easy, even if you are adding and removing servers – so long as the mount points are consistent.
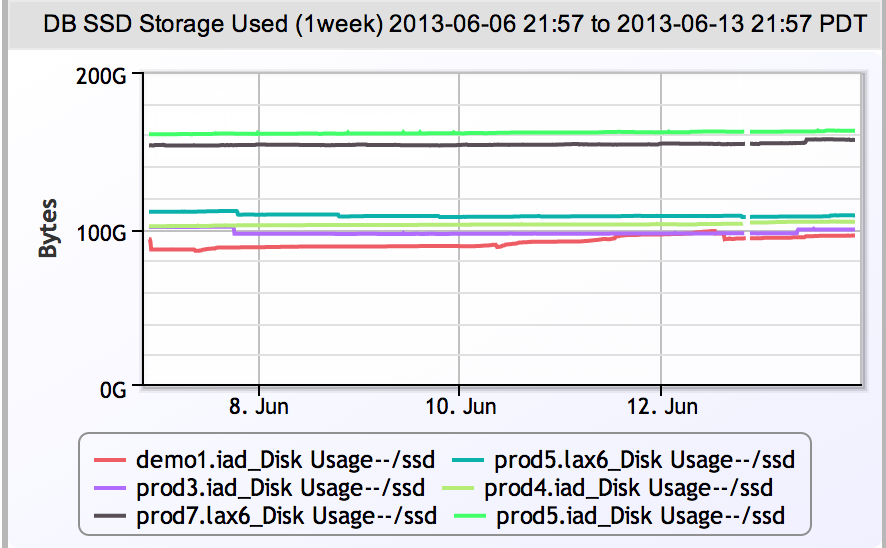
So give up the Gandalf, and adopt a logical scheme for hosts and logical objects. You’ll thank yourself at 2:00 am.
© LogicMonitor 2026 | All rights reserved. | All trademarks, trade names, service marks, and logos referenced herein belong to their respective companies.