This week I’ve been off visiting customers in Atlanta – which means a lot of time on planes and in airports (especially today, when my flight was cancelled so I have a 6 hour delay…) So that means a lot of reading. One book I read on this trip was UX for Lean Startups, by Laura Klein. A good read, advocating good common sense strategies, which I will roughly paraphrase:
- you will be wrong in some of your assumptions about how customers will use, and be able to use, your UX; therefore
- start with an MVP of your UX
- show your UX to test groups of customers as early as possible (before implementing); see where they have issues and what they like/don’t like
- iterate on the UX with your customers
- release it in your product; measure usage and business impact
- rinse and repeat.
This is, to some degree, a similar message that you will hear from proponents of Agile methodologies like Scrum; from DevOps, and the Lean enterprise movement in general: work collaboratively; release frequently; measure the results.
How does this relate to monitoring?
- you will be wrong in some of your assumptions about how your code will perform under production load; therefore
- start with the MVP of your feature
- run the feature in limited load: in the lab, or with a small set of live traffic. See where the performance issues are.
- iterate on the feature and performance bottlenecks with your developers
- release it in your product, measuring performance and capacity impact
- rinse and repeat
Like modifying a UX, it’s easier to change code for performance and capacity reasons earlier, rather than later. If your plan to use flat files to store all your customer’s transaction history works fine for 5 customers, but not for 5000 – it’s much better to find that out when you have 5 customers. (Even better to find it out before you’ve released it to any customers.) Finding that out may require simulating the load of 5000 customers – but if you have in depth monitoring, it is more likely to be evident in advance of the load. In the case of flat files, it would be easy to see a spike in linux disk request latency – even if you only have a few users. If you have a less-anachronistic architect whose decided to use MySQL, you may see no issues in disk latency, but you may see a spike in table scans. No actual problem now, but an indicator of where you may run into growing pains. If you run Redis/Memcached/Cassandra/MongoDB (hopefully not all at once), you may not see performance issues in the transactions, but you may have less memory to run the application, so it may start swapping – so now you need to split your systems.
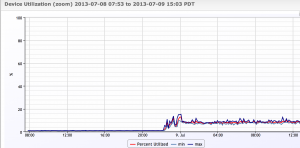
If your disk load jumps like this with 5 users – dont put 5000 on this system…
In Lean UX, the initial steps are qualitative observations of a small subset of users to identify the worst issues that are then addressed and iterated on. With Lean monitoring, thorough monitoring should be deployed even initially, and it will require someone with experience to identify changes in behavior that, while not a problem now, could indicate one under greater load, and how to address them. (Change from Mysql to NoSQL? Add indexes? Add hardware resources? Scale horizontally?) The more thorough your monitoring is, with good graphical presentation of trends, the more likely you are to be able to find issues early, and thus scale and release without issues.
If you run infrastructure, and don’t work directly with developers, the same principles apply. You don’t move all functions from one datacenter to another at once (if you have a choice). You run a small set of applications in the new datacenter, monitoring everything you can in the new datacenter, fix the errors you find, then move some more load. Rinse, repeat. Deploying new ESX infrastructure? Move some non-critical VMs first. New Exchange cluster? Dont move all users at once without testing.
Nothing revolutionary, and nothing people don’t know, but it’s good to have reminders sometimes. The key to all changes is to keep them small, and measure the crap out of them.
© LogicMonitor 2026 | All rights reserved. | All trademarks, trade names, service marks, and logos referenced herein belong to their respective companies.