

If you’re choosing a database to build your next system, you’ve likely heard terms like transactional, relational, and non-relational thrown around. They sound similar. But they solve very different problems.
- Transactional databases ensure every operation, like a payment or update, either fully happens or doesn’t happen at all.
- Relational databases structure data into rows and columns.
- Non-relational databases handle unstructured data with more flexibility, but less rigidity.
In this article, we will understand the core differences, show where each model suits, and help you choose based on scale, structure, and safety.
TL;DR: Choose your database based on structure, scale, and consistency
-
Transactional databases ensure all-or-nothing operations and can be found in both relational and non-relational systems
-
Relational databases are ideal for structured data, defined schemas, and strict consistency
-
Non-relational databases offer flexibility and horizontal scale, perfect for unstructured or fast-changing data
-
The right choice depends on your system’s behavior, how much you expect it to grow, and how critical data accuracy is to your business
What Is a Transactional Database?
A transactional database is built for one thing: guaranteeing that every change to your data is all-or-nothing. Either the full operation succeeds or nothing is saved at all.
That might sound simple, but it’s critical for systems that can’t afford errors, such as banking apps, e-commerce sites, or airline booking platforms. These systems rely on transactions (bundled sets of operations) that must succeed or fail together.
Let’s say a customer places an order online. You need to charge their card, reduce inventory, and create a receipt—all at once.
If any of those steps fail, you don’t want mismatched records or disappearing inventory. A transactional database ensures everything either completes together or rolls back entirely so data remains consistent.
Transactional databases give you safety.
That safety comes from a set of principles called ACID:
- Atomicity: The whole transaction succeeds—or none of it does
- Consistency: Data must meet all rules before being saved
- Isolation: Transactions don’t interfere with each other
- Durability: Once saved, data won’t be lost even if the system crashes
(We’ll discuss these further in the article.)
Most transactional databases are relational, like PostgreSQL, MySQL (InnoDB), or Oracle. But being relational isn’t a requirement. Some modern non-relational databases, such as MongoDB or Couchbase, now support ACID-compliant transactions as well.
What Is a Relational Database?
A relational database stores data in tables like a spreadsheet. Each table contains rows (records) and columns (fields). The name “relational” comes from the way these tables connect to each other.
Here’s how it works:
| Rows | Columns | Primary Keys (PK) | Foreign Keys (FK) |
|---|---|---|---|
| Each row represents a single record (like a customer or an order) | Define the type of data in each field (like name, date, or amount) | Uniquely identify each row | link related data across tables |
Let’s say you have one table for customers and another for orders. The customer ID appears in both. That link helps you track which customer placed which order, without storing the same customer info over and over.
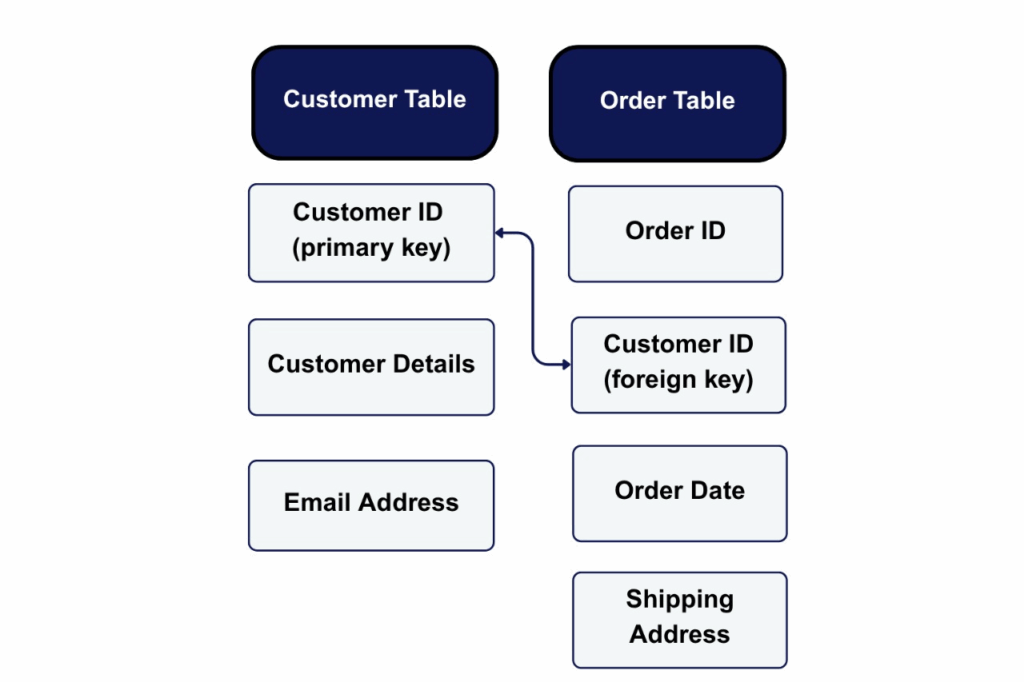
To manage all of this, relational databases use Structured Query Language (SQL). If you’ve ever heard about “CRUD” operations (create, read, update, delete), that’s SQL in action.
Since they work so well with structured data, relational databases are ideal for finance systems, CRMs, and inventory tools.
Why?
Because these systems need clear rules, repeatable transactions, and accurate relationships between records, exactly what relational models are designed to handle.
Advantages of Relational Databases
Relational databases link related data across tables using primary and foreign keys to reduce duplication and ensure each data point only lives in one place. This makes large datasets easier to manage and less prone to error.
They also use Structured Query Language (SQL), a universal standard that’s widely supported across tools and platforms. Most engineers already know SQL, which keeps onboarding time and learning curves low.
Another benefit? Maturity.
Relational databases have been around for decades. That means there’s no shortage of:
- community support
- well-documented best practices
- robust frameworks and integrations
If your data has a clear structure and doesn’t change formats often, relational databases offer a stable solution for storing and retrieving information.
Disadvantages of Relational Databases
The flip side of structure is rigidity.
Relational databases rely on a fixed schema. This means the structure of your tables like which columns exist and what data types they hold, must be defined in advance and stay consistent over time.
So, if you want to add new fields or restructure relationships in your data model, you may have to update the schema manually. And that may require complex migrations.
They’re also not built for easy scaling.
Why?
Because vertical scaling (adding CPU or RAM to a single server) can only go so far. Horizontal scaling (distributing the load across multiple machines) is possible but tricky.
In fact, as your data warehouse grows, query performance can suffer. This means large joins across multiple tables can slow operations.
So, if you’re working with unstructured data, like JSON logs, social media messages, or IoT sensor outputs, relational databases aren’t usually the best fit.
What Is a Non-Relational Database?
Non-relational databases don’t use the traditional table-and-column format. Instead of forcing data into a fixed structure, they let you store information in a way that fits your application’s needs (no predefined schema required).
This makes them ideal for handling unstructured (chat logs, images, or social media posts) or semi-structured (like JSON files or XML documents) data.
Why?
Because these formats don’t follow consistent rows and columns. So trying to force them into a rigid table would slow your work and limit what you can do with the data.
Unlike relational databases, which require predefined relationships and data types, non-relational databases are either schema-less or schema-flexible. This means you can store new fields or formats without needing to redesign the whole structure every time something changes.
That flexibility is why you’ll find non-relational databases at the backend of:
- real-time applications
- big data pipelines
- cloud-native and distributed systems
Note: Non-relational ≠ anti-structure. These databases still organize data but they let you define the structure as you go.
Advantages of Non-Relational Database
Non-relational databases are built for flexibility and scale: two must-haves in cloud-native and modern application environments.
They support a wide variety of data types, from structured records to unstructured sensor data and semi-structured SaaS logs. Because there’s no fixed schema, developers can adjust the data model on the fly, without rewriting or migrating the entire system.
Scalability is another major strength.
These databases are designed for horizontal scaling, which means they can grow across multiple machines. That’s ideal for distributed systems that handle large or unpredictable data loads such as analytics pipelines or real-time recommendation engines.
And when paired with the right query tools or BI platforms, non-relational databases can return insights faster. Because they skip the rigid joins and constraints that slow down relational systems.
Disadvantages of Non-Relational Database
The flexibility comes at a cost: data reliability.
Non-relational databases typically lack full ACID compliance (atomicity, consistency, isolation, durability). That means they don’t always guarantee that every transaction is complete and correct, especially when multiple systems are writing to the same dataset. Partial writes or inconsistent states can occur.
In addition, developers often need to build their own safeguards to maintain data integrity, which adds engineering overhead.
Other tradeoffs include:
- a smaller ecosystem (compared to decades-old relational databases)
- less built-in support and community resources
- potential for steeper learning curves with newer or niche database types
For teams that need tight control over data consistency, these tradeoffs may require extra planning or even a hybrid approach that combines both relational and non-relational models.
Are All Relational Databases Transactional?
Not always. And that’s a common point of confusion.
Many relational databases support transactions, but not all do by default. That support depends on the storage engine, not just the database type.
Take MySQL as an example.
It includes multiple storage engines, and they don’t all handle transactions the same way.
- InnoDB, MySQL’s default engine, supports full ACID compliance. It can safely commit or roll back multi-step operations.
- MyISAM, on the other hand, does not support transactions. If something goes wrong mid-write, there’s no rollback; you only have partially saved data.
That’s a big issue in systems where data accuracy matters.
So if you’re configuring a relational database, especially in open-source environments like MySQL, make sure to verify which engine you’re using.
Most modern relational databases like PostgreSQL, Oracle, and SQL Server are transactional by default. But relational does not mean transactional.
Transactional doesn’t mean relational, and not all relational databases support transactions.
So while “relational” and “transactional” often go together, they’re not the same thing.
ACID vs BASE Explained
When it comes to data reliability, databases typically follow one of two models: ACID or BASE.
- ACID (used in most transactional databases) prioritizes strict data integrity.
- BASE (common in many non-relational systems) trades strict consistency for greater flexibility and scale.
ACID is like a bank transaction. Every step must be verified and completed before the money moves. If something fails, nothing happens at all. It’s strict, structured, and reliable so there’s no room for uncertainty.
BASE, on the other hand, is like tracking a package delivery. At any given moment, the system might not show the full picture; your tracking status could be behind or temporarily inconsistent. But eventually, all updates catch up, and the final state is correct.
Here’s how the two compare:
| ACID (Transactional) | BASE (Eventually Consistent) |
|---|---|
| All parts of a transaction succeed or none do. | The system is available even if parts are inconsistent. |
| Transactions bring the database from one valid state to another. | The state of the system may change over time, even without input. |
| Transactions don’t interfere with each other. | Data will become consistent over time. |
| Once committed, data won’t be lost. | May not guarantee permanent durability without extra configuration. |
ACID is common in relational databases like PostgreSQL, Oracle, or MySQL with InnoDB. BASE is more typical of non-relational databases like Cassandra, DynamoDB, or older versions of MongoDB (though many NoSQL systems now offer optional ACID-like features).
Quick Comparison: Transactional Database vs Relational Database vs Non-Relational Database
Here’s a quick comparison between the three types of databases: transactional, relational and non-relational.
| Feature | Transactional Database | Relational Database | Non-Relational Database |
|---|---|---|---|
| Data Structure | Varies – applies to both relational and some non-relational DBs | Structured (tables, rows, columns) | Flexible (JSON, key-value, documents, etc.) |
| Query Method | SQL or NoSQL depending on the DB engine | SQL | Varies (API calls, query languages like MongoQL, CQL, etc.) |
| Schema Flexibility | Depends on underlying DB – not a schema model | Rigid – requires predefined schema | Flexible or schema-less |
| Scalability | Depends on DB type – many are horizontally scalable | Vertically scalable (harder to scale across servers) | Horizontally scalable (easier to distribute across nodes) |
| Reliability | ACID-compliant (transaction safety is the defining trait) | Strong ACID compliance by default | Often BASE, though some offer ACID features |
| Best Use Cases | E-commerce orders, payments, anything requiring rollback safety | Financial systems, CRMs, inventory, ERP | Social media, IoT, logs, product catalogs |
| Cloud-Readiness | Both types can be cloud-ready if ACID is supported | Cloud-compatible, often needs tuning for distributed scale | Built for cloud-native and distributed environments |
Use Case Scenarios: Choosing the Right Fit
Still unsure which type of database to use?
Let’s look at some common real-world scenarios and see where each database type suits.
1. E-Commerce Checkout System
Best fit: Transactional relational database (e.g., PostgreSQL, MySQL with InnoDB)
During checkout, when a customer clicks “Place Order,” multiple things need to happen at once: charging a payment, updating inventory, and creating a shipping label. All of it must succeed together or fail together.
That’s a perfect case for an ACID-compliant transactional database as it guarantees complete, reliable operations.
2. Internal CRM for a Sales Team
Best fit: Relational database
A CRM stores customer records, sales pipelines, contact histories, and reports. All of this relies on clear relationships and predictable structure.
A relational database is ideal to handle this.
Why?
Because it allows you to run complex queries and generate dashboards where accuracy and relational logic matter.
3. Content Management System for a Media Site
Best fit: Document-based non-relational database (e.g., MongoDB)
In a CMS, articles, author bios, tags, comments, and media files are all stored together but they don’t fit neatly into a table.
In such a case, use a document database to store all this data in flexible JSON-like structures. This way, you can adapt as your content model evolves.
Make Your Choice and Optimize for Performance
Choosing between transactional, relational, and non-relational databases starts with one question: what kind of consistency, structure, and scale does your data need?
Once you’ve chosen the right type, don’t stop there.
A well-chosen database is only as good as its uptime, speed, and observability. So, test it and make sure your database performs as expected, whether you’re supporting millions of real-time sensor writes or ensuring rock-solid transactional integrity.



