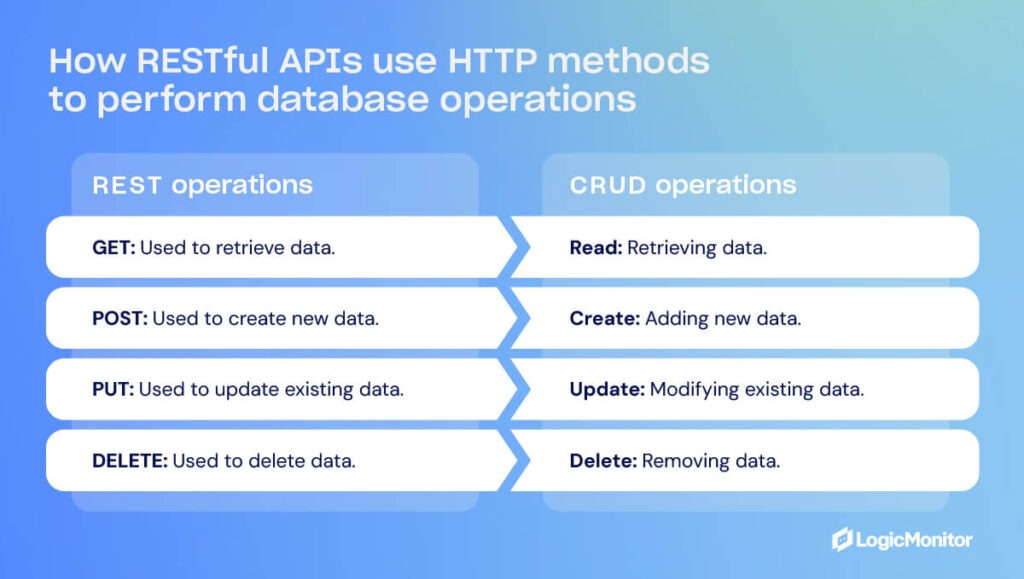
CRUD refers to the four basic operations you perform on data — Create, Read, Update, and Delete — usually at the database or application logic level. REST, on the other hand, is an API design style that uses HTTP methods to expose those operations over the web, such as POST (create), GET (read), PUT/PATCH (update), and DELETE (delete).
CRUD operations meaning is focused on data persistence—Create, Read, Update, Delete—typically handled at the database or backend logic layer.
REST defines how APIs expose resources over HTTP, using consistent endpoints and stateless requests.
In CRUD vs REST, the key difference is scope: CRUD handles data operations, while REST defines how those operations are accessed and executed through an API.
Monitor both REST API behavior and CRUD data operations to troubleshoot issues faster with LogicMonitor.
CRUD and REST are two of the most popular concepts in the Application Program Interface (API) industry:
CRUD stands for Create, Read, Update, and Delete, focusing on managing data.
REST, or Representational State Transfer, is a way to design web services that focuses on how clients and servers interact and communicate.
While both are involved in handling data, REST defines how systems expose and access resources, while CRUD focuses on how that data is actually created and managed.
This blog will discuss what REST and CRUD are, the basic principles that govern them, and REST vs. CRUD similarities and differences.
What Is REST?
REST is an abbreviation for Representational State Transfer. It’s an architectural style that defines how systems communicate over the web.
Roy Fielding, the founder of the REST protocol, defines it as “an abstraction of the architectural elements within a distributed hypermedia system.”
How Did REST Originate?
Before REST launched in 2000, there was no standard way to build or use a web API. Existing protocols were complicated and inconsistent.
Roy Fielding and his colleagues developed REST to fix this, creating a standard that lets servers exchange data anywhere on the web
REST-compliant systems are called RESTful systems. These systems are characterized by their statelessness and the separation of client and server concerns. Since its launch in 2000, many companies such as eBay and Amazon have used the REST-based APIs.
What is a RESTful API? (RESTful API Meaning Explained)
A REST API (or RESTful API) is an API that follows REST principles. It allows applications to communicate over the web using standard HTTP methods such as GET, POST, PUT, and DELETE.
REST API full form is Representational State Transfer Application Programming Interface.
For example:
GET /users/123
POST /users
PUT /users/123
DELETE /users/123
Each endpoint represents a resource (like a user), and the HTTP method defines what action to perform. Each URL in a REST API is called a REST endpoint; it represents a specific resource and defines how clients interact with it.
REST APIs often map to CRUD operations, but they’re not the same thing. CRUD manages data; REST exposes it.
A REST resource is not the same as a database record. A single resource can combine multiple data sources or represent actions, not just stored data.
Not all REST endpoints map directly to CRUD operations. For example, an endpoint like /servers/123/restart performs an action that doesn’t fit neatly into Create, Read, Update, or Delete.
CRUD Operation
Typical REST Method
Example
Create
POST
POST /users
Read
GET
GET /users/123
Update
PUT / PATCH
PUT /users/123
Delete
DELETE
DELETE /users/123
What Are The 6 Core Principles of REST (The 6 REST Constraints)
Let’s break them down here.
1. Independent Client-Server Interaction
REST lets the client and server be built and updated independently. Neither needs to know how the other works internally.
A server provides services (data, files, processing). A client consumes them. REST keeps the two loosely coupled, so either side can work independently without affecting the result. As long as the client and the server know what format to use when sending messages, different clients eventually reach the same REST endpoints. The client and server interface separation also allows both systems to evolve independently.
2. Stateless Communication in REST APIs
REST servers don’t store client session state. Each request is treated as new. The client must send everything the server needs — including auth — with every request.
3. Enhancing Efficiency With Caching
Requests on a server go through different pathways or caches. These caches can either be a local cache, proxy cache, or reverse proxy, and a RESTful API’s server can mark information as either cacheable or non-cacheable. When a client requests their end, this request goes through a series of caches. If any caches along that path have a fresh copy of the representation, it uses that cache to generate a result. When none of the caches can fulfill the request, it returns to the origin server. A RESTful API’s servers determine whether the information is cacheable or non-cacheable.
Caching has several benefits, some of which are:
Reduces bandwidth
Decrease latency by decreasing the number of trips to and from the server to fetch data from memory
Reduces server load
Decreases network failures
4. Predictable Interactions via a Uniform Interface
In a REST system, the client and server interact in predictable ways. A resource in the system follows only one logical Uniform Resource Identifier (URI). This uniformity is what separates REST from other API styles. Resources on a REST API use Hypermedia as the Engine of Application State (HATEOAS) to fetch related information whenever applicable. All resources on RESTful APIs follow specific guidelines with naming conventions and link formats. A uniform interface follows four guiding principles:
Resource-based: Each resource uses URI as a resource identifier.
Actions on Resources Through Representations: A resource associated with metadata contains information on the server that you can modify or delete.
Self-descriptive Messages: Each message has all the information to describe how it is processed.
Hypermedia as the Engine of Application State (HATEOAS): Clients provide states by body content, request headers, and URI, and the service provides customers with the state by response codes, response headers, and body content. This is called Hypermedia.
5. Layered Architecture for Scalability
A RESTful API relies on a layered system to deliver results. This approach allows developers to modularize their systems. For example, see how you can write a custom Terraform provider with OpenAPI to simplify API management. This layered system provides a hierarchy that constrains a layer from seeing beyond its assigned layer and allows the developer to deploy various functions to different servers. Each layer works independently, and each layer does not know the functionality of other layers besides its own. On the user end, a layered system does not allow users to ordinarily differentiate whether they are connected to a primary or intermediary server. The importance of intermediary servers is their ability to provide load-balancing cache sharing.
“Mastering both CRUD and REST is essential for building scalable and efficient web services.”
6. Code on Demand (Optional)
In some REST systems, the server can send executable code to the client. This is optional and less common, which is why some REST explainers leave it out—but it is part of the standard six-constraint model.
What Is CRUD?
CRUD stands for CRUD acronym CREATE, READ, UPDATE, and DELETE.
CRUD started as a database concept. It describes a cycle of data operations, not an architecture.
Different languages and frameworks implement CRUD with their own naming conventions.
A good example is SQL (structured query language), which uses Insert, Select, Update, and Delete. Also, there are CRUD cycles in a dynamic website, such as a buyer on any eCommerce site (Amazon, Mango, etc.). Users can create an account, update information and delete things from their shopping cart. Other programming languages that use the CRUD frameworks are Java (JOOQ, iBAtis), Python (Django), PHP (Propel, Doctrine), and .NET (NHibernate, LLBLGEN Pro), to name a few.
CRUD was designed for persistent storage — data that outlives the process that created it. Today, CRUD principles show up across SQL, REST APIs, and other systems.
The Four Fundamental Operations of CRUD
As discussed above, the four fundamental operations of the CRUD cycle are: CREATE, READ, UPDATE and DELETE. In API design, these operations are often exposed through endpoints; sometimes informally referred to as “CRUD endpoints” or “CRUD API”.
CREATE: Adds one or more entries and is the equivalent of the Insert function in SQL.
READ: Retrieves data based on different criteria and is equivalent to the Select function in SQL.
UPDATE: Change procedures and modify records without overwriting.
DELETE: Removes one or more specified entries.
L and S: Additions to CRUD
CRUD is sometimes extended to CRUDL (adding List) to handle paginated results, or SCRUD (adding Search) for queries.
Security Considerations for REST And CRUD
APIs enable applications to connect and communicate across networks and the Internet. Both REST and CRUD systems need security controls. The basics apply regardless of which approach you use:
Authentication and Authorization: Require authentication so only approved users can access data. The OAuth 2.0 framework works well for applications and services utilizing REST principles, while role-based access controls work best for CRUD interactions.
Data Validation: Validate inputs (file type, format, size) and strip anything malicious before processing.
Encryption: Use HTTPS for data in transit. Encrypt data at rest.
Rate Limiting: Cap the number of requests per client. This prevents overload and helps block DoS attacks.
Implementation Examples for REST and CRUD
Here’s how each one looks in code:
CRUD Example Using SQL
-- Insert a new user into the 'users' table
INSERT INTO users (name, email) VALUES ('John Doe', '[email protected]');
-- Select a user from the 'users' table where the ID is 1
SELECT * FROM users WHERE id = 1;
-- Update the email of the user where the ID is 1
UPDATE users SET email = '[email protected]' WHERE id = 1;
-- Delete a user from the 'users' table where the name is 'John Doe' and the email is '[email protected]'
DELETE FROM users WHERE name = 'John Doe' AND email = '[email protected]';
Using the example graphic above, the CRUD steps outlined in the graphic perform the following functions using SQL.
Create: In this step, the command inserts a new record into the users table of the database named John Doe with an email address of [email protected].
Read: This command retrieves the record for viewing from the users table with the value of 1 in the id column of the SQL table.
Update: This line overwrites the information in the ’email’ column of the record with an ‘id’ value of 1 with the email address [email protected].
Delete: This command deletes an erroneous record from the database in which the name was entered as ‘John Doo’ with the same email address.
REST Example Using HTTP Methods
# Create a new user (POST request)
POST /users
{
"name": "John Doe",
"email": "[email protected]"
}
# Retrieve user information by ID (GET request)
GET /users/1
# Update user information (PUT request)
PUT /users/1
{
"email": "[email protected]"
}
# Delete a user by ID (DELETE request)
DELETE /users/1
In the example graphic above, these REST commands perform the following tasks:
POST: Creates a user record with name ‘John Doe’ and the email value “[email protected].”
PUT: Updates the email for the user with ID 1 to “[email protected].” This example assumes the John Doe record has the ID of 1.
Practical REST API Use Cases and CRUD Use Cases
REST and CRUD often work together, but each has its own strengths:
REST works well for public-facing APIs such as social platforms, streaming services, and banking apps. It also fits microservices and IoT systems where many components need to communicate.
On the contrary, CRUD is perfect for data-management tools such as CMS editors, calendars, admin dashboards, and inventory systems — anywhere users directly manipulate records.
A simple admin dashboard is a good example of a CRUD-heavy design, while a public SaaS API or an internal service action endpoint is a better example of where REST adds value beyond basic data operations.
“CRUD focuses on data operations, while REST defines how web services communicate.”
What Are the Similarities Between CRUD vs. REST?
REST and CRUD share overlapping commands.
REST Commands
POST: This creates a new record in the database.
GET: This request reads information sourced from a database.
PUT/PATCH: This updates an object.
DELETE: This removes a record from the database.
CRUD Commands
CREATE: This creates a new record through INSERT statements. In REST, this is a POST command.
READ/RETRIEVE: These procedures grab data based on input parameters. In REST, this is equivalent to a GET command.
UPDATE: This updates data without overwriting it. In REST, this is a PUT request.
DELETE: This removes data from the database. REST uses the same request to delete data.
What Are the Differences Between CRUD vs. REST?
The similarities make it easy to confuse the two. Here’s where they differ:
Aspect
REST
CRUD
What it is
An architectural style for APIs
A set of data operations
Layer
API and communication layer
Data layer (database/backend logic)
Purpose
Defines how systems expose and exchange resources
Defines how records are created and managed
Protocol
Uses HTTP (GET, POST, PUT, PATCH, DELETE)
Uses database commands (INSERT, SELECT, UPDATE, DELETE in SQL)
Scope
Can include non-data actions (e.g., /servers/123/restart)
Limited to four data operations
State
Stateless — each request is independent
Stateful — operates on persistent records
Resource model
A resource can combine multiple data sources or represent actions
A record maps directly to a row or document in storage
Update behavior
PUT replaces a full resource; PATCH updates part of it
UPDATE modifies fields in a record
Independence
Can exist without CRUD operations
Can exist without REST (used in many non-API contexts)
Best for
Public APIs, microservices, IoT, distributed systems
Admin panels, CMS editors, internal tools, direct data management
Example
GET /users/123
SELECT * FROM users WHERE id = 123
The simplest way to remember it: REST is an architecture, and CRUD is a function. A REST API can use CRUD operations underneath, but REST can also do things that CRUD can’t, like trigger actions, return computed resources, or expose hypermedia links. CRUD on its own can’t replace a REST API.
Note: CRUD focuses on data operations, while REST defines the architecture for web services, shaping how clients and servers interact.
REST and CRUD Work Together, but They Are Not the Same
REST and CRUD work together but aren’t the same. REST is an architecture. CRUD is a set of operations. One defines how systems talk; the other defines what happens to the data.
Monitor REST APIs and CRUD Workflows With Full-Stack Visibility
Track API requests, backend performance, and related logs in LogicMonitor to spot issues faster, trace failures across services, and improve the reliability of your REST and CRUD-driven applications.
In programming, CRUD refers to the core set of operations used to interact with stored data. It’s typically implemented in backend logic or database queries, not at the API design level.
2. What Does CRUD Stand for and What Are CRUD Operations?
CRUD operations are the actions that allow systems to create new data, retrieve existing data, update records, and delete them—forming the foundation of most data-driven applications.
3. What does REST API Stand For?
A REST API stands for Representational State Transfer Application Programming Interface. It’s an API designed using REST principles to expose resources and handle requests over HTTP. In practice, what does REST API mean comes down to this: it’s a consistent way for systems to request and exchange data using standard methods and predictable endpoints.
4. What Is a REST Endpoint?
A REST endpoint is a specific URL in a REST API that represents a resource and defines how clients can interact with it. For example, /users/123 is an endpoint that allows you to retrieve or update a specific user. Each endpoint is paired with an HTTP method (like GET or POST) to perform an action.
5. What Is the Difference Between API vs REST API?
An API is a general interface that allows systems to communicate, while a REST API is a specific type of API that follows REST principles like statelessness, resource-based endpoints, and standard HTTP methods.
6. REST API vs RESTful API: Is There a Difference?
In most cases, REST API vs RESTful API means the same thing. Both refer to APIs designed using REST principles, though “RESTful” emphasizes that the API correctly follows those guidelines.
7. What Are Common REST API Use Cases?
REST API use cases include web and mobile apps, microservices communication, public APIs (like payment or mapping services), and internal tools that need to exchange data reliably.
8. REST vs HTTP: How Are They Different?
REST vs HTTP comes down to role: HTTP is the protocol used to send data, while REST is a design style that uses HTTP to structure API interactions.