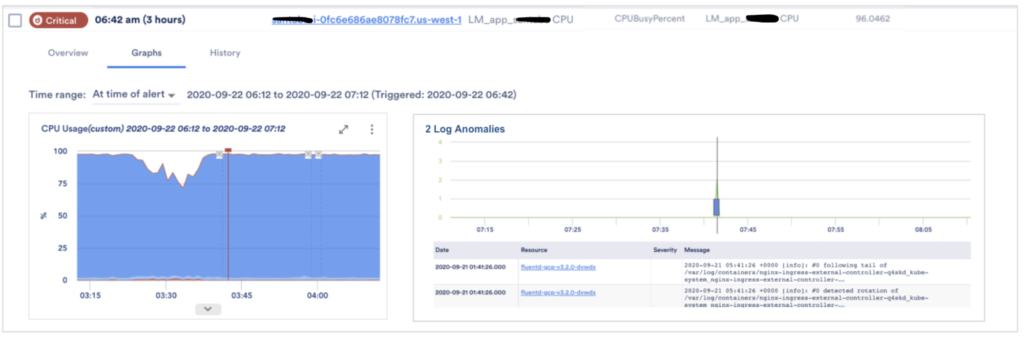
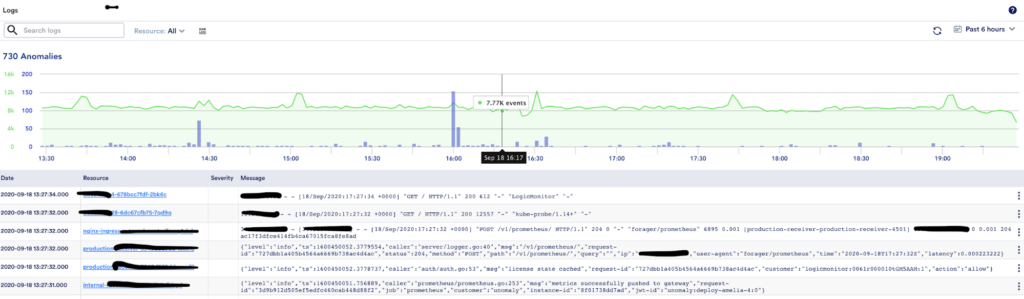
Observability is made up of metrics, logs, and traces. These pillars help us understand the behavior of applications under normal execution, which further accelerates identifying anomalies in case of application failure or deviation from normal execution.
Logging is not about tracing each and every operation, it is about sensible, consistent, and machine-readable log messages that expose the application behavior. Logging each function provides insight into the functional flow, however, there is an exuberant cost of managing applications and transaction tracing.
Logging with the right intention and end goal in mind, where the monitoring systems can identify normal behavior and deviation from normal behavior, helps to accurately detect anomalies.
In this blog we will cover:
The importance of logging in understanding application behavior
How to start finding a pattern to improve the logging
Simple logging strategies to improve the logging leading to high ROI
Bringing logs and metrics together
The Importance of Logging in Understanding Application Behavior
Ironically, logging will not mimic the application behavior if the logging is not done right. Developers may add a variety of log messages while developing the application, but if the logging is inconsistent the behavior of the application isn’t captured correctly.
Excessive and non-intended logging will make troubleshooting applications difficult and further, searching and mining context from an inconsistent large volume of logs will increase troubleshooting time.
Logging with the intention of understanding application behavior reduces the problem search space due to the clear context provided by logging. Machine learning algorithms will proactively identify anomalies since the generated machine learning models are more accurate.
The observability of an application starts with effective logging. Engineering has to start with an end goal in mind in terms of what an application will log to show it’s a normal behavior in production. Logging for observability is different from logging for troubleshooting as the healthy application logs become a signature required for analysis and finding anomalies. It becomes easy to correlate alerts and anomalies because of the context mined from logs.
Understanding Logging Patterns
From a simple grep command to sophisticated tools for log management and analysis, there are a variety of ways to provide capabilities for log analysis. Logging captures “before the fact” and “after the fact” behavior and there are hidden patterns in these messages.
In order to find logging patterns during analysis, you need to ask yourself these questions:
What log lines are produced highest in number?
What is the frequency of unique log lines?
Do log lines have enough context?
Is logging a reflection of a metric?
Are log messages structured and machine-readable?
You can pre-determine the signatures that need to appear in log messages when a certain problem occurs. These tools work on the presence or absence of signatures.
Understanding both patterns and anti-patterns is important when identifying the correct logging strategy so that the cost is under control and applications are observable. Dumping log messages with just a runtime trace of code will increase the logging footprint and make the application less observable.
Simple Logging Strategies Help in Contextual Analysis
Logging too much or too little will suppress important application behavior and introduce false-positive anomalies. It is important to understand that “what is happening in an application” is observability and “why is it happening” is troubleshooting.
Applications can follow guidelines to make application logging cost-effective and expose the application behavior via logs.
Let us looks at various strategies for logging:
Log each message with a context
Clearly add the intended log level
Use a consistent standard timestamp
Log Message Length should be limited to a certain size
Each log message should have a “key=value” structure
Convert logs into metrics for deep insights
Log messages should be controlled via log category
Control repeated log messages via throttling
Consider using JSON format
Applications coded with the mindset of exposing the behavior of an application reduce the time for problem identification. Developers should adopt effective logging strategies, as mentioned above, to expose application meaningful behavior. Doing so keeps the cost manageable and accelerates anomaly detection.
Benefits of Effective Application Logging
Effective logging reduces the phenomena of “garbage in, garbage out” for monitoring tools. You can reduce MTTR by bringing metrics and logs together for early identification of operational issues. Additionally, the cost of storing and handling log messages is under control due to the required and in context logging.
Anomaly detection using logs messages is a complex and interesting field. LogicMonitor is gearing up to add business value to your already monitored infrastructure with LM Logs. Learn more about our LM Logs platform here.
Disclaimer: The views expressed on this blog are those of the author and do not necessarily reflect the views of LogicMonitor or its affiliates.