IT Operational Efficiency
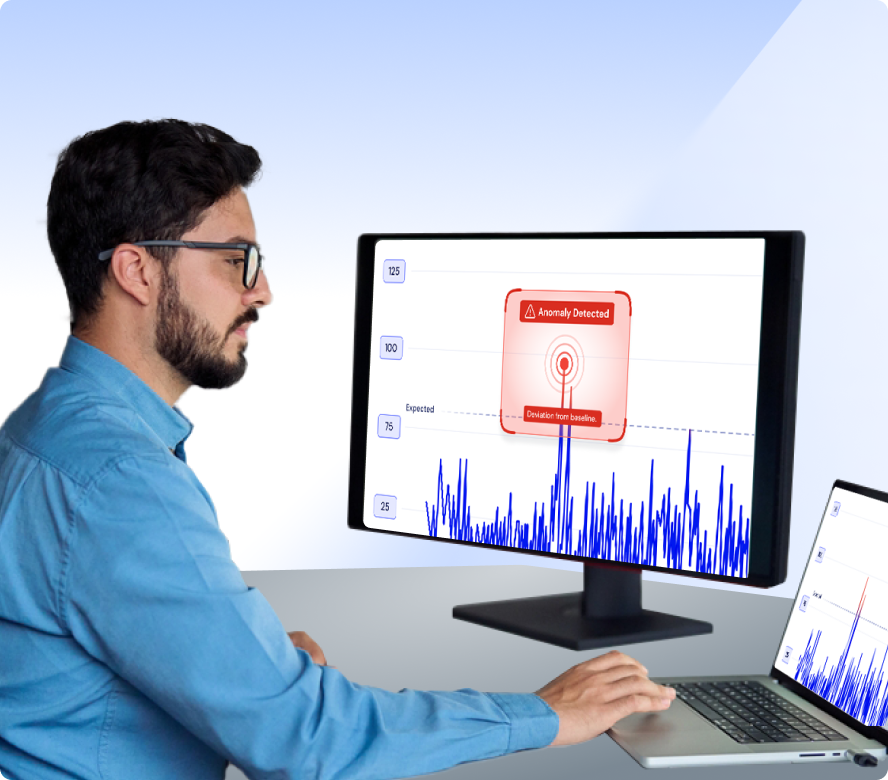
Improve ITOps Efficiency with AI-Powered Observability
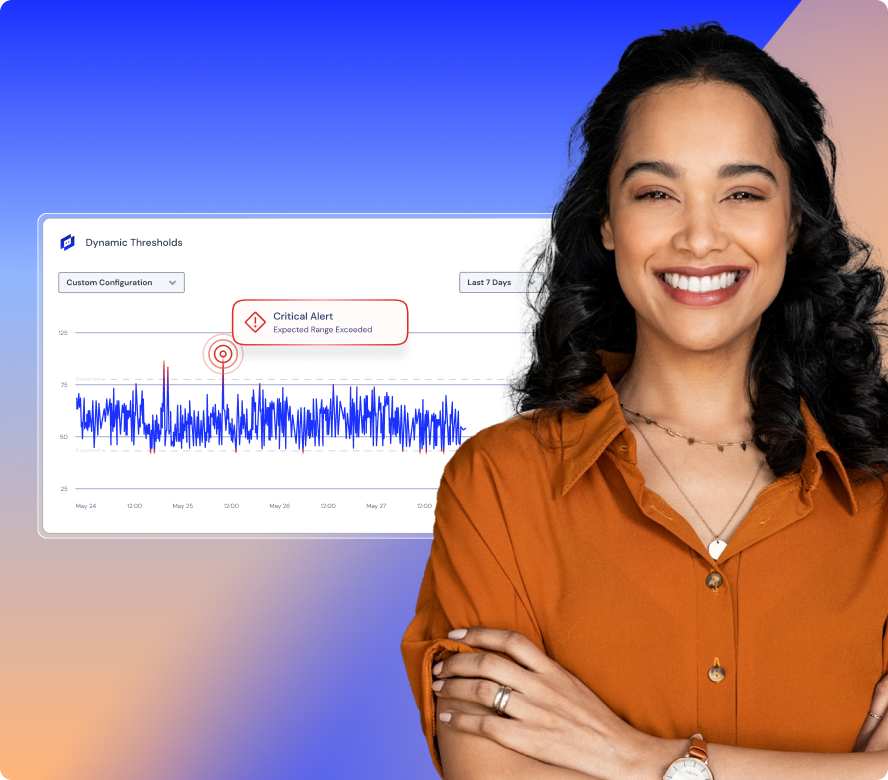
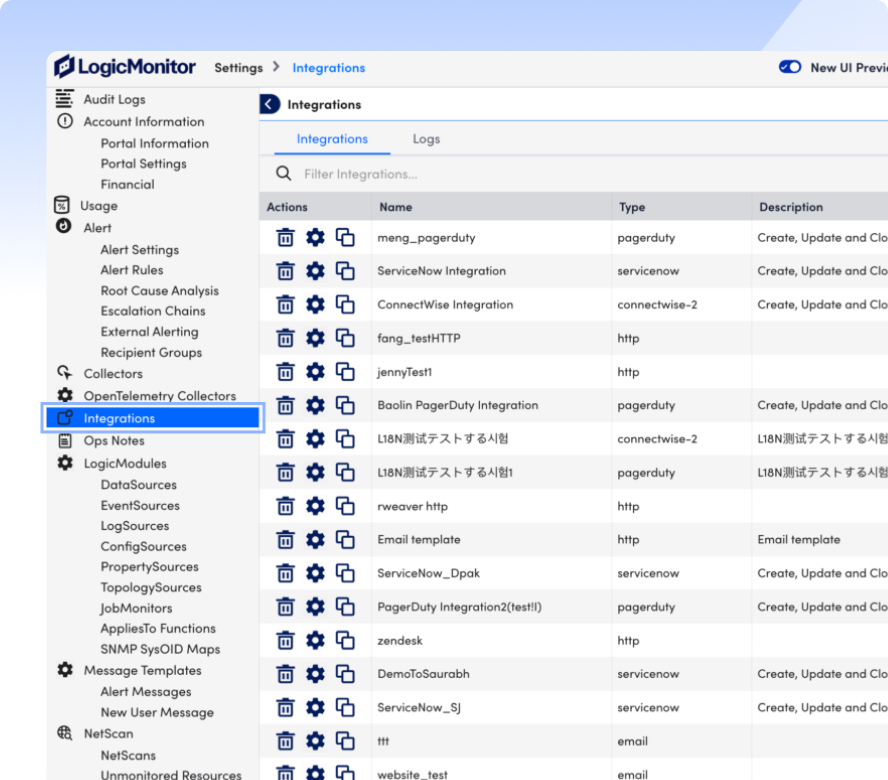
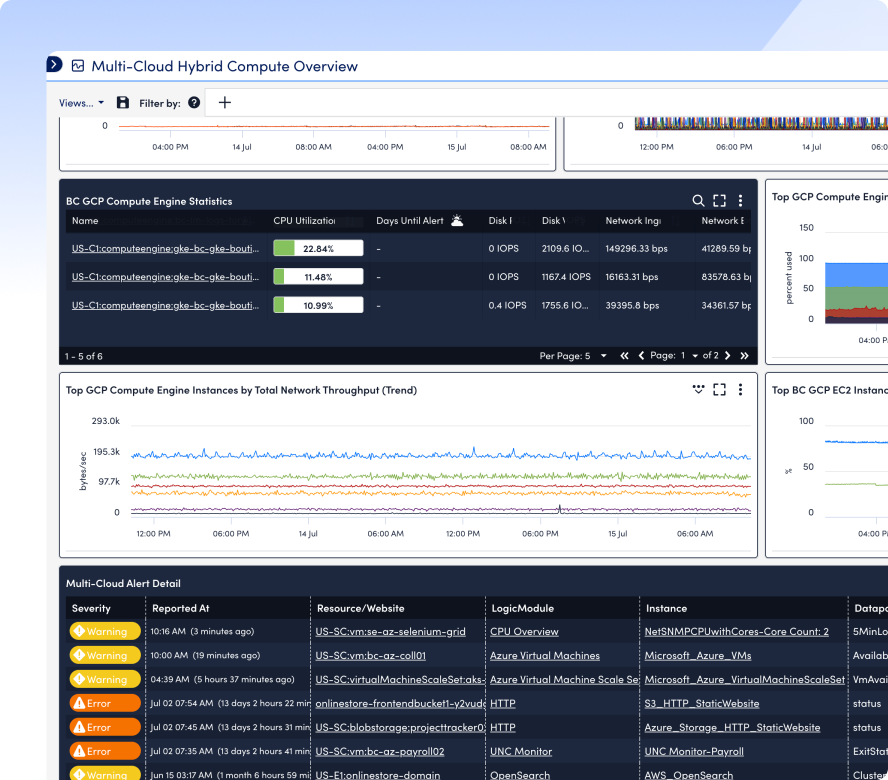
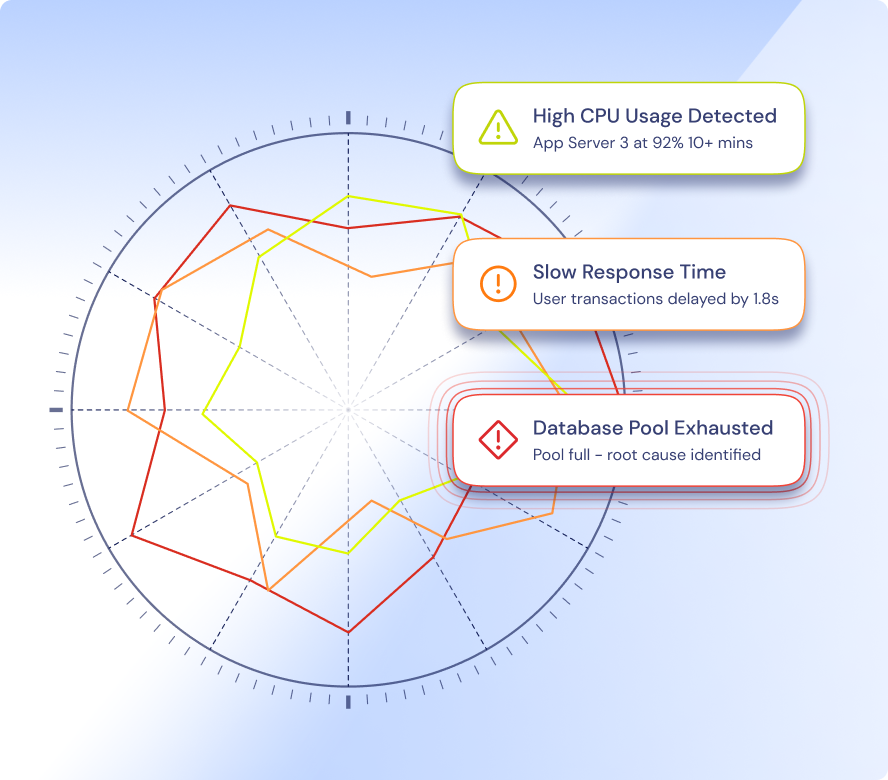
Maximize efficiency, reduce costs, and free up your IT team to focus on innovation. Streamline operations with automation, intelligent monitoring, and proactive issue resolution—so you can do more with less.