Reduce MTTR
Reduce MTTR with AI-Correlated Logs and Metrics plus Automated Remediation
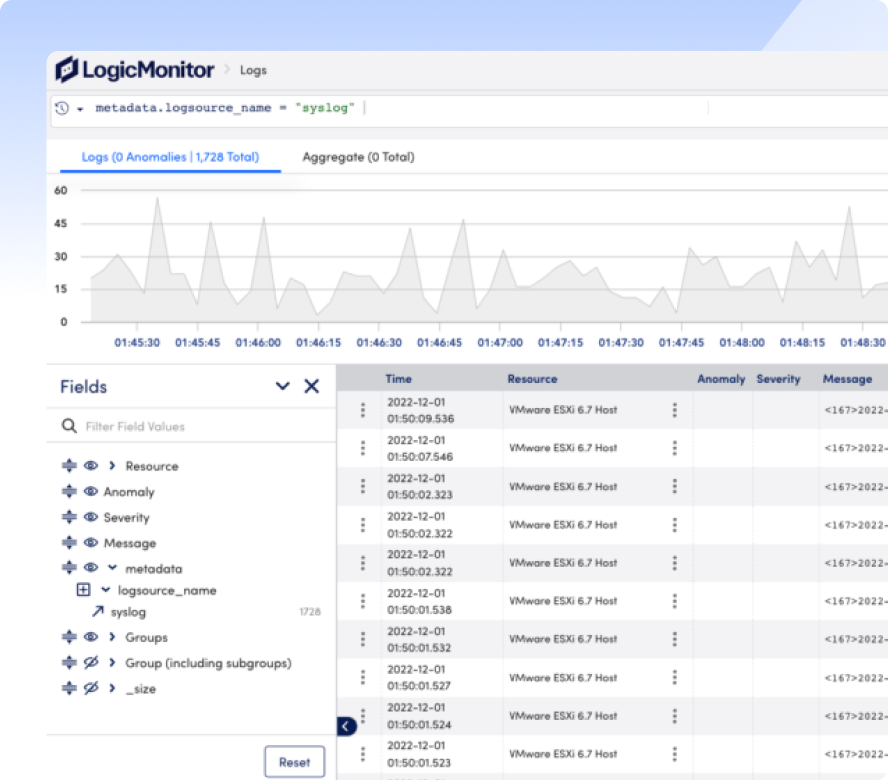
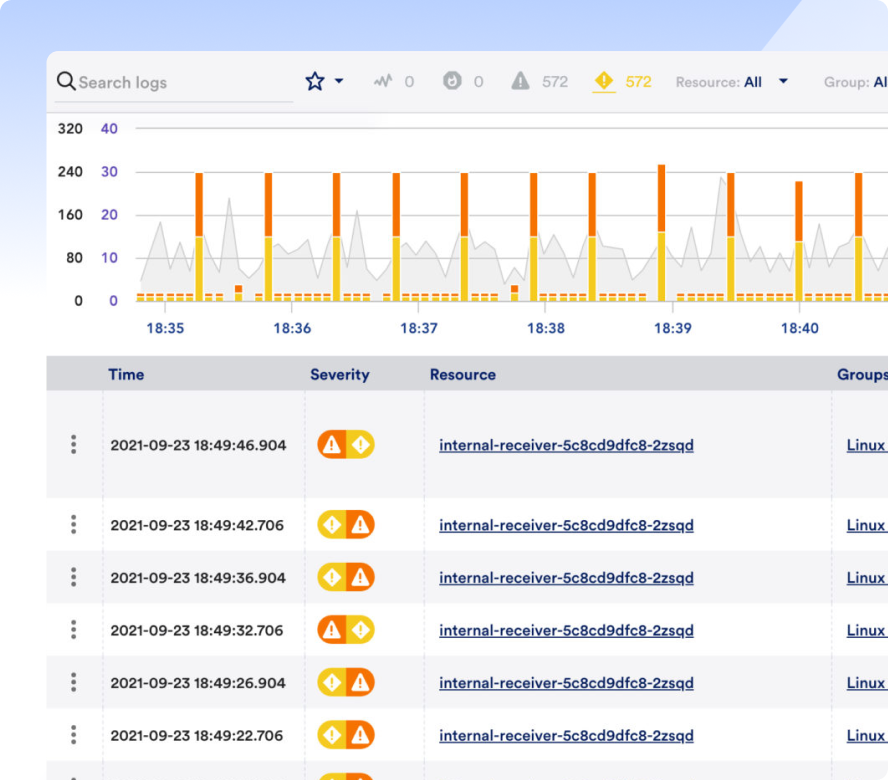
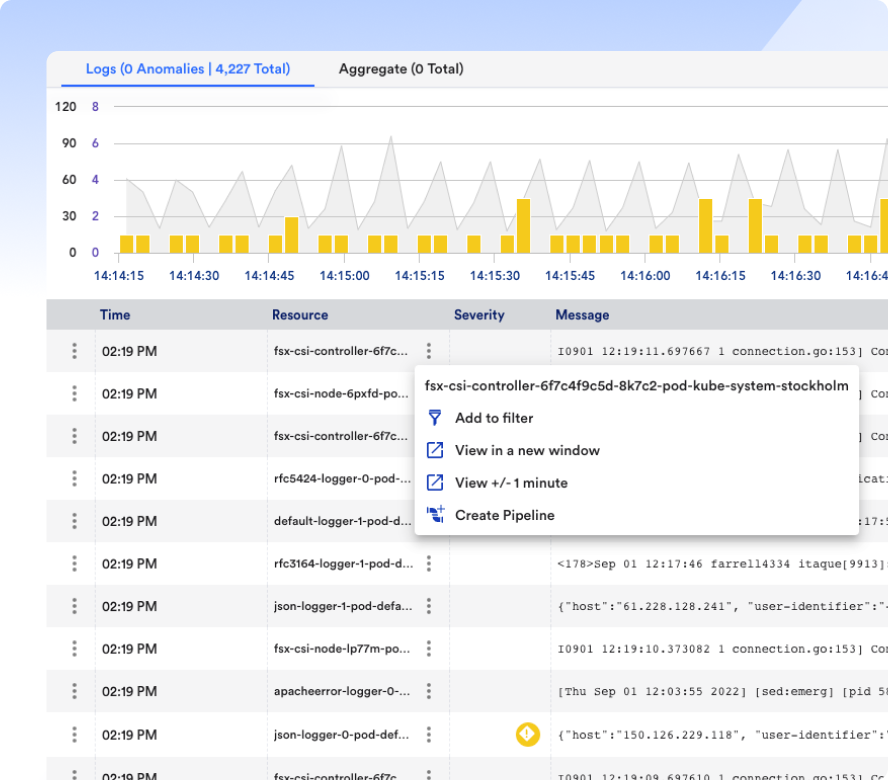
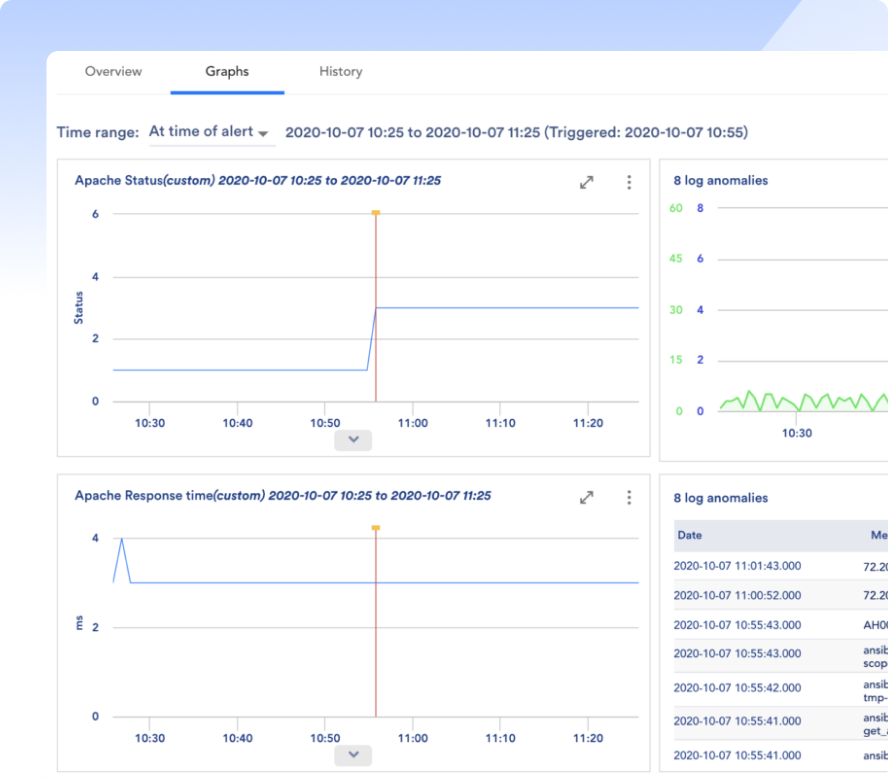
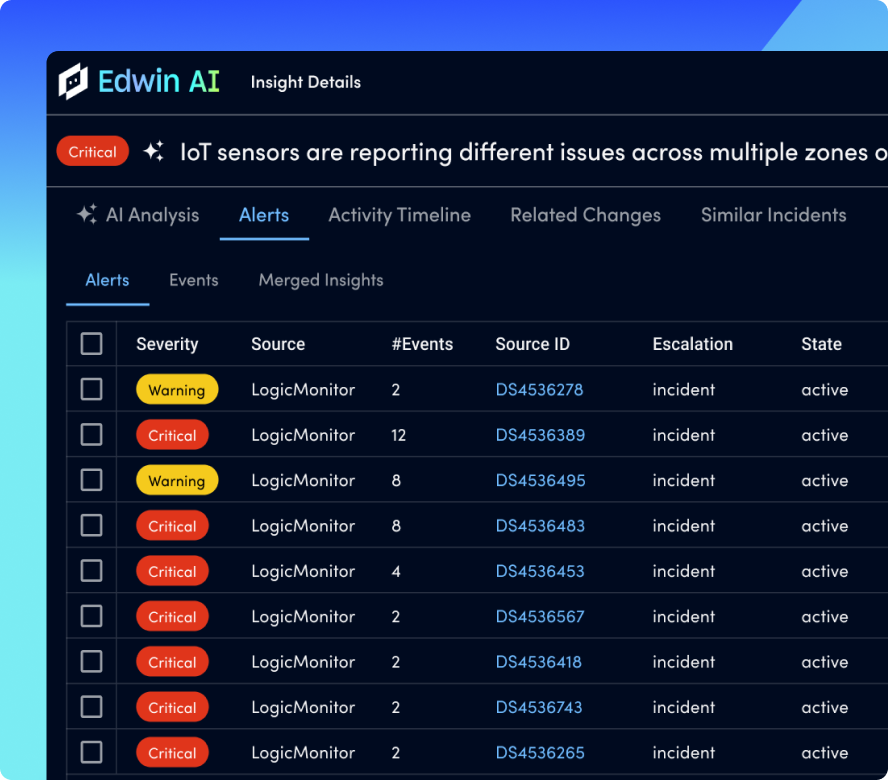
Everyone defines MTTR a little differently, but it all comes down to fixing problems and freeing up time to innovate. Whatever it is, fix it fast with LM Envision, AI-powered correlation, and automated remediation.