Clarity for AWS Monitoring in Hybrid Environments
Extend the value of Amazon CloudWatch with deeper visibility, faster insights, and full context across AWS and hybrid infrastructure in one platform.
Extend the value of Amazon CloudWatch with deeper visibility, faster insights, and full context across AWS and hybrid infrastructure in one platform.
When you go beyond Amazon CloudWatch, you get deeper insights into infrastructure health and service availability, so your critical business services remain always-on
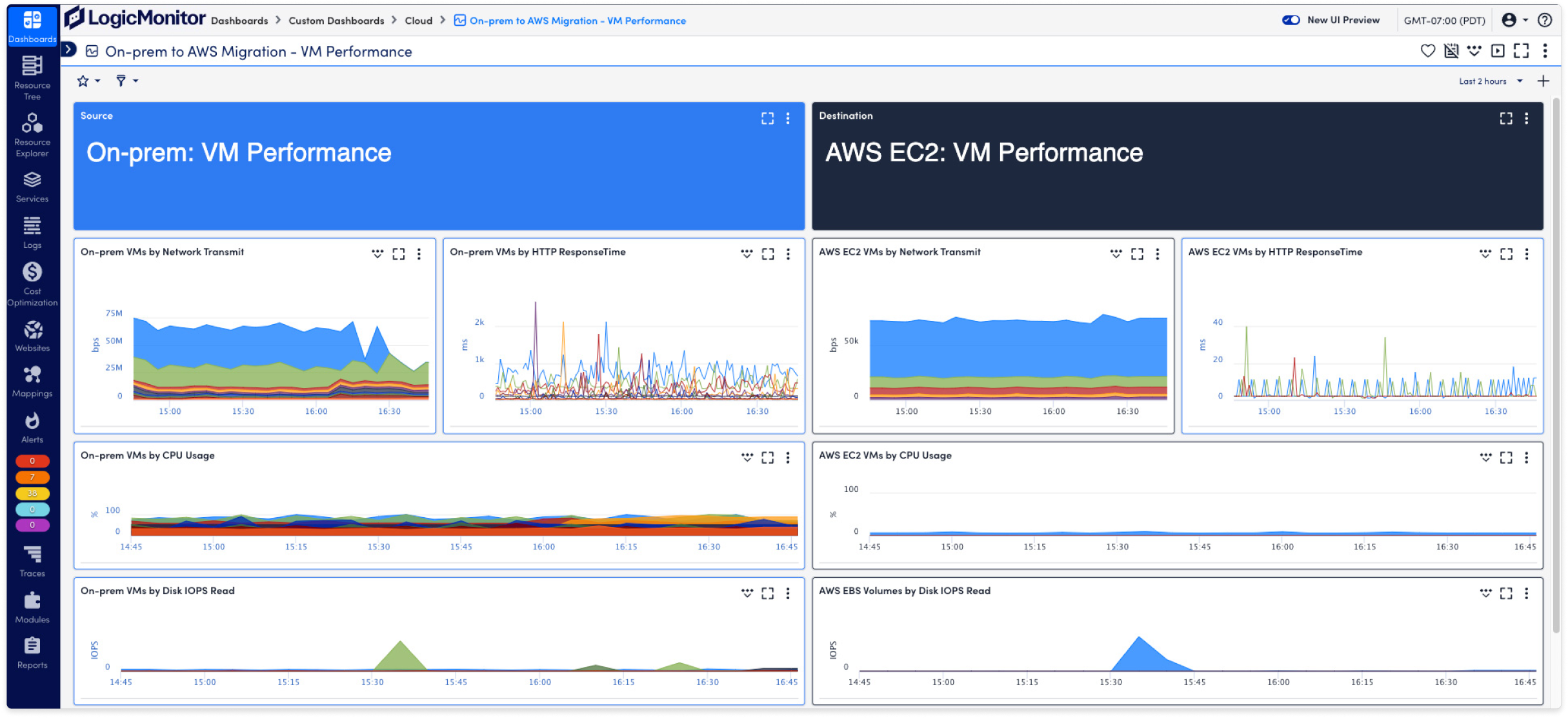
See what’s working—and what’s not—during and after AWS migrations, so you can fix issues early and move forward with confidence.
Monitor AWS, hybrid, and data center infrastructure side by side, so your teams can troubleshoot issues faster.
Correlate cost data with usage and performance trends to optimize cloud spend, reduce waste, and make smarter tradeoffs.
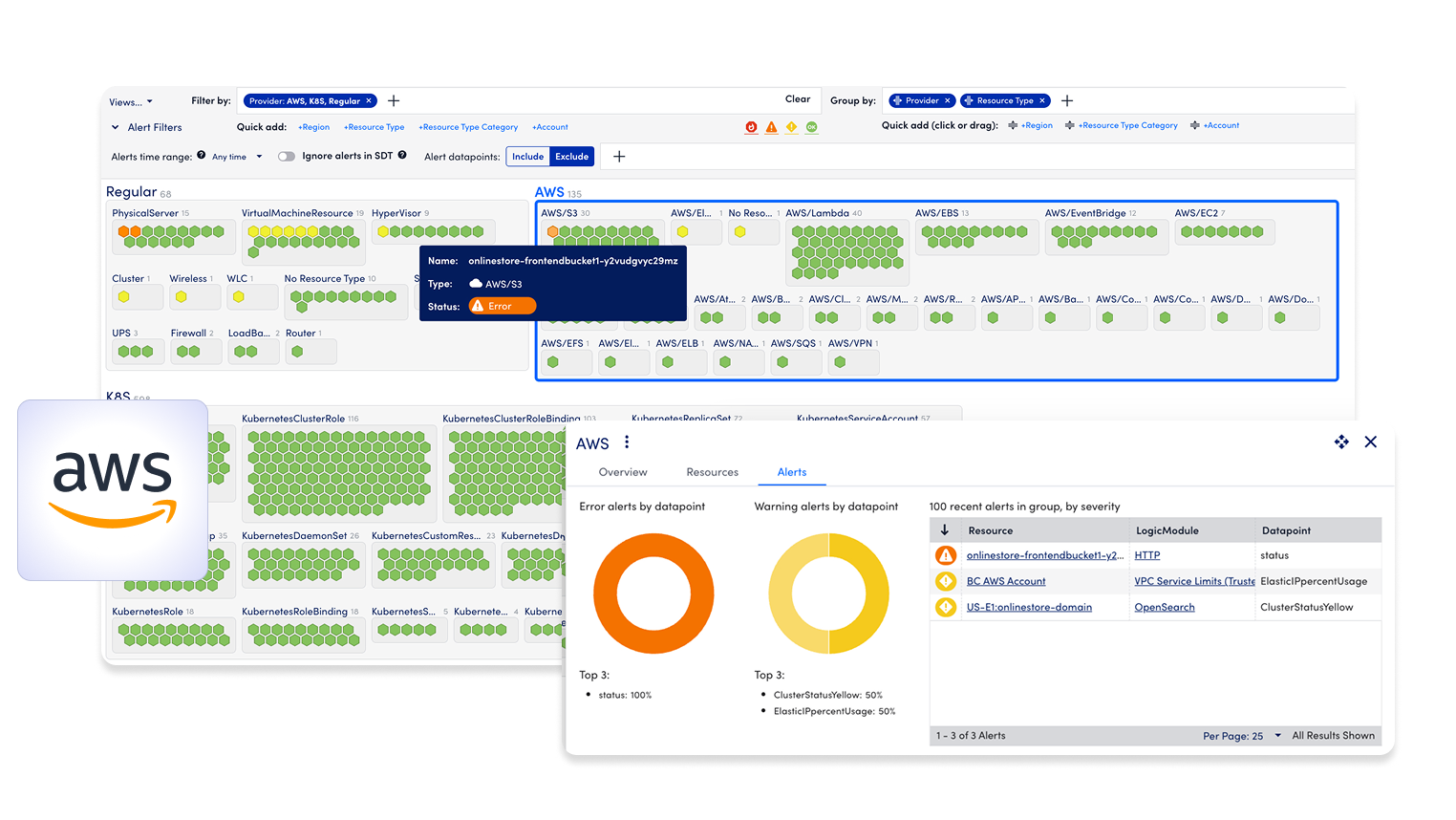
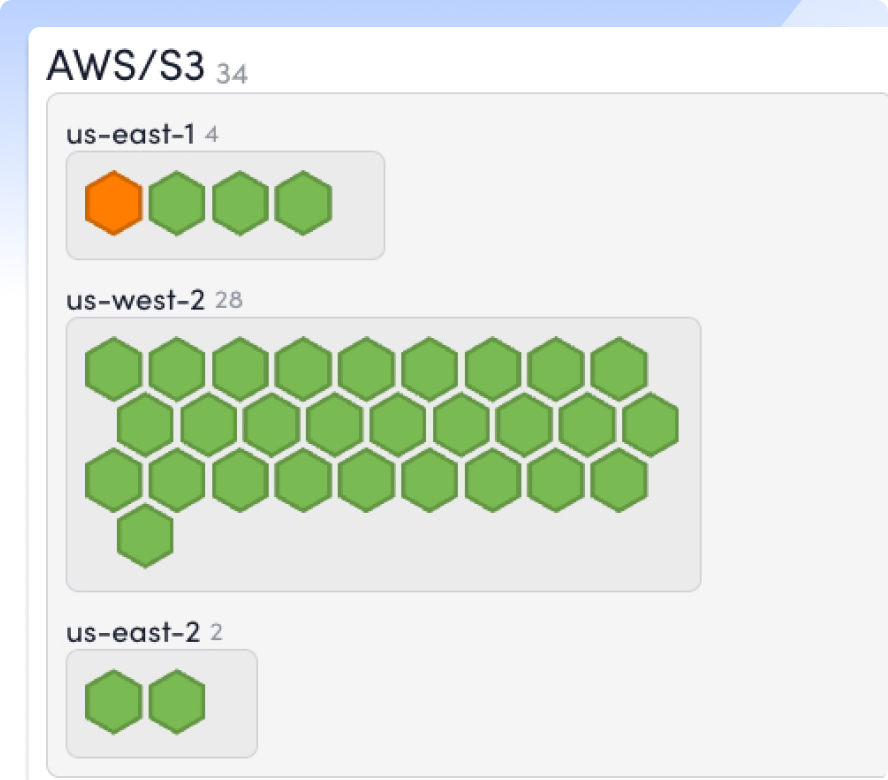
Auto-discover new AWS resources and services as they’re deployed, so your coverage keeps pace with your cloud.
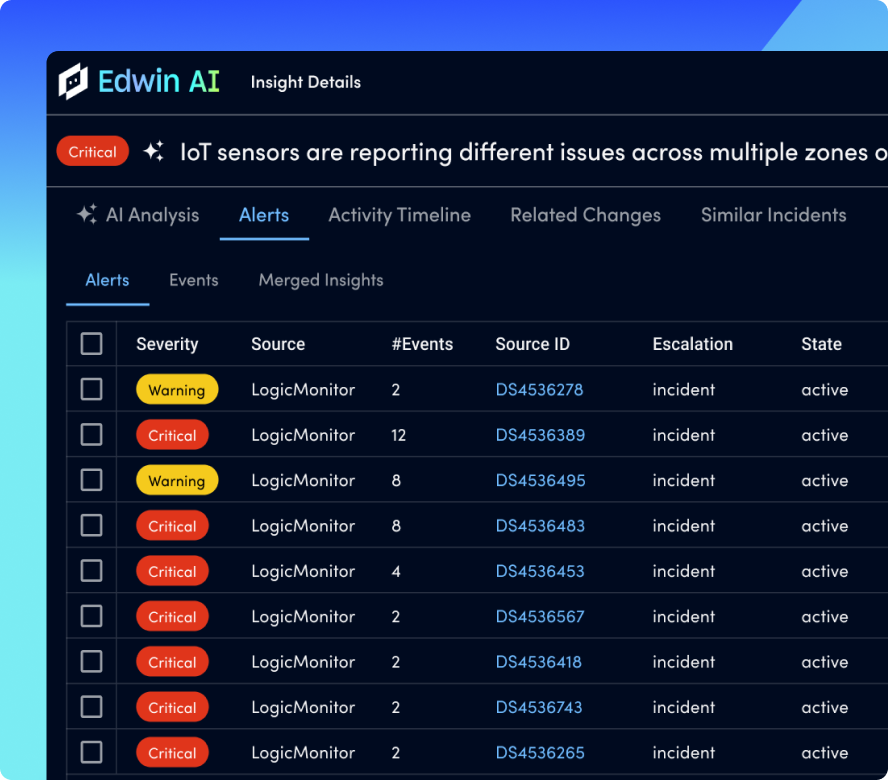
Group related alerts and filter out noise, so your teams are notified when serious issues need action.
Give ITOps, CloudOps, and SREs one shared view of AWS health, performance, and context, so everyone acts faster with less friction.
AWS CLOUDWATCH + LOGICMONITOR ENVISION = BETTER TOGETHER
From EC2 to EKS, LM Envision connects to Amazon CloudWatch and auto-discovers AWS resources. Monitor performance, detect anomalies, and surface meaningful alerts—across every service, region, and environment.
Out-of-the-box integrations for 70+ AWS services, including EC2, S3, Lambda, EKS, ELB, and AI services like Amazon SageMaker and Amazon Bedrock.
Automatically group related alerts and surface meaningful events using AWS-aware logic.
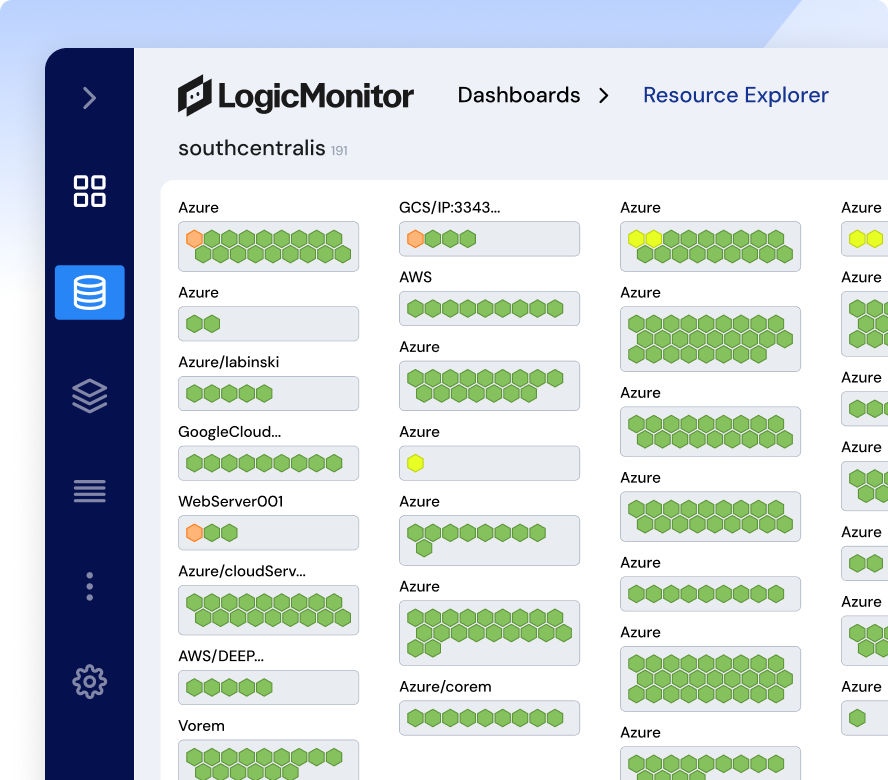
Bring together metrics, logs, traces, and contextual events from across your AWS environment—plus hybrid and on-prem systems—in a single, real-time view.
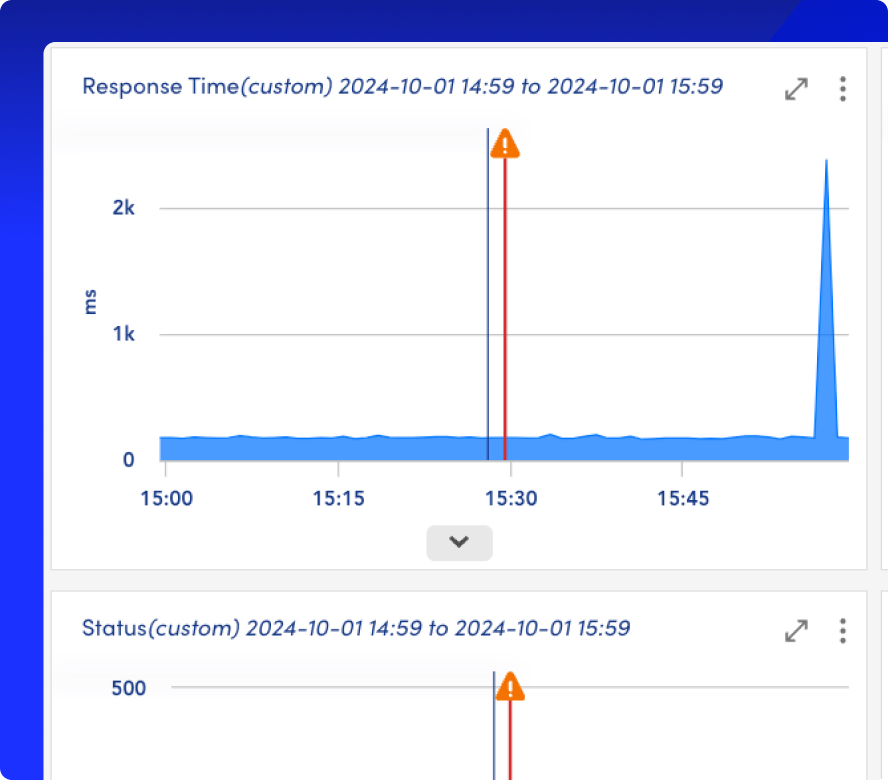
Detect and surface abnormal behavior in AWS resources without complex manual thresholds.

Tailor visualizations and data delivery for different teams, tools, or stakeholders.
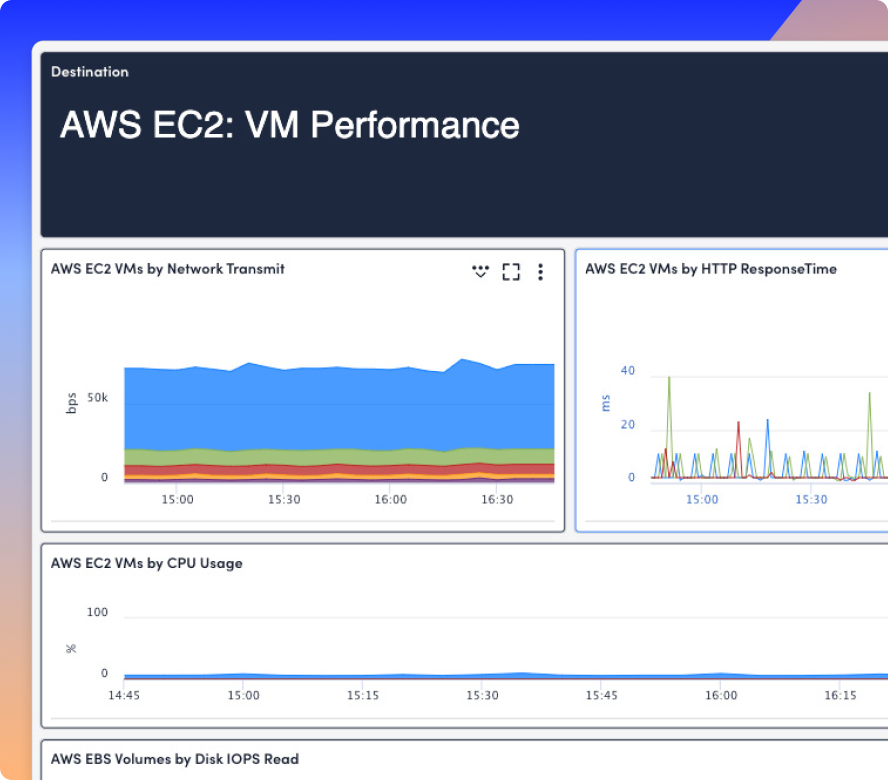
INTEGRATIONS
LM Envision integrates with CloudWatch, Azure, GCP, ServiceNow, PagerDuty, and more, giving you full visibility without switching tools or losing context.
100%
collector-based and API-friendly
3,000+
integrations and counting
AI AGENT FOR Cloud-Native Ops
Edwin connects the dots across your AWS metrics, events, logs, and traces to surface root causes, not just symptoms. Just ask, and Edwin delivers real-time insights in plain language so anyone can act fast.
67%
ITSM incident reduction
88%
noise reduction
BY THE NUMBERS
GET ANSWERS
Get the answers to the top AWS Monitoring questions.
LM Envision natively supports 70+ AWS services out of the box—including EC2, RDS, Lambda, S3, ELB, ECS, and more. Dynamic discovery ensures that new services are monitored automatically, with no manual configuration required.
LM Envision integrates directly with AWS CloudWatch via an API to ingest telemetry, but goes beyond it by applying visibility into AWS availability, OS, and application-level metrics for deeper insights into underlying infrastructure health and service availability.
No agents are required for AWS monitoring. LM Envision collects data via AWS APIs and credentials with least-privilege IAM roles, keeping setup lightweight and secure.
Yes. LM Envision automatically correlates related alerts, enriches them with context, and filters out false positives, helping teams cut alert noise by up to 80%.
Most teams connect their AWS environment to LM Envision in under an hour. Out-of-the-box dashboards and autodiscovery accelerate time to value, with no need for manual tuning.