Developers are increasingly using Kubernetes’ open-source platform to manage containerized workloads and services. Kubernetes containers became popular because it was impossible to define a resource boundary for multiple applications in a traditional CPU environment, and resource misuse created an inefficient environment.
Kubernetes solves the problem by allowing applications to work as isolated containers inside a single operating system. These lightweight containers have their own filesystem, CPU share, memory, storage space, etc. You can move the container across clouds and OS distributions, which makes them a powerful resource. Currently, there are three different Kubernetes certifications that you can take to develop your knowledge and skills even further. Keep reading to see which one is right for you.
Why should I get Kubernetes certifications?
Kubernetes certifications create new opportunities for career growth. A recent survey by Cloud Native Computing Foundation suggests that Kubernetes is the go-to choice for more than 78% of organizations, and nearly 84% of companies run containers in production. Such trends are also visible in the 2021 Red Hat OpenShift report, which states that more than half of IT companies intend to increase the use of containers in the future.
Many organizations shortlist employment candidates who hold the Kubernetes certification, so getting certified helps you stand out and often means less competition when you’re looking for a new job. Companies are also willing to pay more to K8s engineers because hiring managers realize that very few individuals are skilled in this emerging field.
Kubernetes certifications paths
The Linux Foundation manages Kubernetes certification. There are currently five certifications. These are:
- Certified Kubernetes Application Developer (CKAD)
- Certified Kubernetes Administrator (CKA)
- Certified Kubernetes Security Specialist (CKS)
- Kubernetes and Cloud Native Security Associate (KCSA)
- Kubernetes and Cloud Native Associate (KCNA)
Developer path: As the name suggests, a developer builds and manages Kubernetes applications. You will design, build, and configure apps. Developers can define the resources that applications will use and troubleshoot relevant issues.
Administrative path: The administrative path focuses on managing the Kubernetes environment. Administrators may install, manage, and configure production-grade Kubernetes clusters. They’re the people behind the Kubernetes operations.
The administrative path also leads to certification as a Kubernetes Security Specialist. The CKS certification ensures best practices and covers the necessary skills to secure container-based apps and platforms from threats. It is important to note that you must hold a Certified Kubernetes Administrator license before pursuing a Kubernetes Security Specialist license.
Foundational cloud-native path: This path is designed for beginners and professionals seeking to understand cloud-native ecosystems. The KCNA certification validates knowledge of Kubernetes fundamentals, while the KCSA certification focuses on cloud-native security principles, making them excellent starting points for a cloud-native career.
Certified Kubernetes Application Developer (CKAD)
The Certified Kubernetes Application Developer exam is developed by Linux Foundation and the Cloud Native Computing Foundation. It’s a two-hour online exam that tests the candidate’s ability to perform the responsibilities of a Kubernetes developer. The two-hour exam is the first step for many new individuals.
Prerequisites
There is no prerequisite to take CKAD; however, prior experience in an IT field will help candidates easily grasp the concepts. The exam will not test candidates on material related to container runtimes and microservice architecture, but it assumes that you should know these contents.
To pass the exam, you should be comfortable with the following:
- An OCI-Compliant container Runtime.
- Concepts and architectures related to Cloud Native application.
- Knowledge of programming languages such as Java, Python, and Node.js.
Content
The course content consists of seven domains and competencies. These include core concepts, configuration, multi-container pods, observability, pod design, service and networking, and state persistence.
The exam
For the CKAD exam, candidates must score 66% or above to become certified. The exam consists of performance-based tasks that candidates must solve in a command line. Each test is proctored online using audio, video, and screen-sharing feeds, allowing the examiner to view candidates’ desktops.
It will cost you $300 to take the Certified Kubernetes Application Developer exam, but you may be eligible for a bundled discount when opting for training and the exam. The certification is valid for three years.
Certified Kubernetes Administrator (CKA)
Certified Kubernetes Administrator certificate ensures you can install, configure, and manage production-grade Kubernetes clusters. After passing the exam, you also become eligible to take the CKS exam.
Prerequisites
Although this certificate does not have prerequisites, candidates should preferably have prior experience in the IT field. The exam is designed for Kubernetes administrators, IT professionals, and cloud administrators.
To pass the exam, candidates should be comfortable in:
- Understanding the key concepts of Kubernetes networking, storage, security, and maintenance.
- Establishing basic use cases for end-users.
- Knowledge of application lifecycle, troubleshooting, and API object primitives.
Content
The exam question tests candidates’ knowledge of five key subjects. Nearly 40% of the content covers storage and troubleshooting. Another 15% is dedicated to workloads and scheduling. Cluster architecture, installation, and configuration comprise almost 25% of the exam’s questions. The remaining 20% tests your knowledge of services and networking.
The exam
You must score at least 66% to pass the CKA exam. The exam is proctored online, and you can review documents installed by the distribution. Candidates can also review the exam content instructions presented in the command line terminal. The Procter will allow you to open one additional tab on the Chrome browser to access particular online assets.
The cost of the exam is $300, which includes a free retake. The certification is valid for three years. You will receive the result within 36 hours after the completion of the exam.
Certified Kubernetes Security Specialist (CKS)
The two-hour exam for Certified Kubernetes Security Specialist evaluates candidates based on the best practices required to secure the Kubernetes environment. To pass the exam, candidates must demonstrate knowledge of securing container-based applications and the Kubernetes platform during build, deployment, and runtime.
Prerequisites
To sit in the exam, you need to pass the Certified Kubernetes Administrator exam first. You may purchase the CKS certification before the actual exam, but you can only take the exam after completing the prerequisite.
Here are some of the important points to grasp before the exam:
- Understand a broad range of best practices required to secure a Kubernetes environment.
- Basic knowledge of dealing with Kubernetes and cloud security issues in a real-world environment.
- Ability to set up clusters, run security audits, detect threats, and do static analysis.
Content
The exam is divided into six modules. The cluster setup comprises 10% of the overall content, while cluster hardening and system hardening make up 30%. The remaining 60% evaluates supply chain security, microservice vulnerability, and managing runtime security.
The exam
The exam, which consists of 15 to 20 performance-based tasks, costs $300 to register for. During the exam, you can access Kubernetes documentation, tools, and app armor. Unlike the two other certifications, CKS certification is valid for two years.
Certified Kubernetes and Cloud Native Security Associate (KCSA)
The Kubernetes and Cloud Native Security Associate (KCSA) exam is designed by the Linux Foundation to validate foundational cloud-native security skills. It serves as a starting point for those new to Kubernetes security or cloud-native technologies. The exam evaluates a candidate’s understanding of Kubernetes security concepts, cloud-native infrastructure, and industry best practices.
Prerequisites
There are no formal prerequisites for the KCSA exam. However, having a basic understanding of Kubernetes and IT security concepts can be helpful.
To pass the exam, candidates should be comfortable in:
- Understanding Kubernetes cluster components and their security features.
- Applying security fundamentals for cloud-native environments.
- Managing container security using best practices.
Content
The exam is divided into six modules. The overview of cloud-native security accounts for 14% of the content, while Kubernetes cluster component security and Kubernetes security fundamentals each comprise 22%. The Kubernetes threat model and platform security cover 16% each, and compliance and security frameworks comprise the remaining 10%.
The exam
The KCSA exam costs $250 and is an online, proctored, multiple-choice test. Candidates have 12 months from the purchase date to schedule and complete the exam. Two exam attempts are included. The certification is valid for three years.
Certified Kubernetes and Cloud Native Associate (KCNA)
The Kubernetes and Cloud Native Associate (KCNA) exam is designed by the Linux Foundation to validate foundational knowledge of Kubernetes and the wider cloud-native ecosystem. It is an entry-level certification for those new to cloud-native technologies, providing a strong starting point for IT professionals and developers.
Prerequisites
The KCNA exam has no prerequisites, making it accessible to beginners and IT professionals who want to develop cloud-native skills.
To pass the exam, candidates should be comfortable in:
- Understanding Kubernetes fundamentals and container orchestration.
- Recognizing cloud-native architecture principles.
- Applying cloud-native observability and application delivery practices.
Content
The exam is divided into five modules. Kubernetes fundamentals account for 46% of the content, container orchestration makes up 22%, and cloud-native architecture covers 16%. Cloud-native observability and application delivery account for 8% of the total.
The exam
The KCNA exam costs $250 and is an online, proctored, multiple-choice test. Candidates have 12 months from the purchase date to schedule and complete the exam, with one free retake included. Like the CKS certification, the KCNA certification is only valid for two years.
Kubernetes certifications comparison table
| Criteria | CKAD | CKA | CKS | KCSA | KCNA |
| Prerequisites | None, but IT experience recommended | None, but IT experience recommended | Must pass CKA first | None | None |
| Exam Format | Performance-based tasks | Performance-based tasks | Performance-based tasks | Multiple-choice | Multiple-choice |
| Exam Length | 2 hours | 2 hours | 2 hours | Online, proctored | 90 minutes |
| Exam Cost | $300 (with possible bundled discount) | $300 (includes free retake) | $300 | $250 (two attempts included) | $250 (one free retake included) |
| Certification Validity | 3 years | 3 years | 2 years | 3 years | 2 years |
Certified Kubernetes Administrator (CKA) vs. Certified Kubernetes Application Developer (CKAD)
Many people need clarification about the two certifications. Because of their relevancy and similarities, they can’t decide which certification to pursue. Here’s our take on the subject.
If you have basic app development experience or are new to Kubernetes, starting as a Certified Kubernetes Application Developer may be better. The certification mainly tests your cloud-native developer and DevOps skills. In contrast, the Certified Kubernetes Administrator exam requires a thorough knowledge of the entire Kubernetes infrastructure and Linux system.
While both exams test various similar features, the Certified Kubernetes Administrator takes it up a notch by evaluating your problem-solving skills in installing, troubleshooting, maintaining, and upgrading. It also means that getting CKAD certification may be a better approach for anyone relatively new to the Kubernetes environment.
Additional cloud native certifications
As the cloud-native ecosystem continues to expand, several certifications complement Kubernetes expertise by focusing on specific cloud-native technologies. These certifications enable IT professionals to deepen their knowledge in specialized areas such as monitoring, service mesh, and cloud-native application delivery.
Prometheus Certified Associate (PCA)
The Prometheus Certified Associate (PCA) certification validates a candidate’s knowledge of observability and monitoring using Prometheus. This exam covers Prometheus fundamentals, querying with PromQL, and setting up alerts and dashboards.
Istio Certified Associate (ICA)
The Istio Certified Associate (ICA) certification focuses on the Istio service mesh, emphasizing service discovery, traffic management, and microservice security. It is ideal for developers and operators of microservice-based applications.
Other cloud native certifications
- Helm Certified Associate: Focuses on using Helm to simplify Kubernetes application deployment and management. Candidates learn about creating, managing, and maintaining Helm charts and handling Helm releases and repositories.
- Fluent Certified Associate: Emphasizes centralized logging, data processing, and log aggregation in cloud-native environments. Candidates learn about configuring Fluentd for log collection, filtering, and forwarding in distributed systems.
- Envoy Certified Associate: Validates expertise in using Envoy proxy for securing, managing, and routing microservice traffic. Candidates learn about configuring Envoy for service discovery, load balancing, traffic routing, and applying security policies such as TLS encryption and access control.
What are the overall benefits of Kubernetes certification?
Containers and the cloud are rapidly changing the IT landscape. Besides a potential rise in pay, new career opportunities, and respect from your peers, Kubernetes certifications allow everyone to integrate the newly acquired knowledge into their existing environment.
The certification allows developers to create container-based management systems. Kubernetes’s flexible environment enables developers to use a variety of programming languages and frameworks to strengthen the existing cloud infrastructure.
Operations can use Kubernetes to bridge the gap between developers and users who are not adept at learning all the scripts and tools. The team can use the technology and expertise gained from certifications to package an application with its required infrastructure.
Security professionals can use Kubernetes and containers to increase the development speed while keeping everything secure. The end-to-end toolchain supporting the existing cloud-native infrastructure creates an attack surface, which is often challenging to defend. Kubernetes can help solve this problem.
How to prepare for Kubernetes exams
A few essential tips will come in handy when preparing for Kubernetes exams:
- You can review the exam guide on the Linux Foundation’s official website. It will help you get the latest updates in each domain.
- Don’t ignore the significance of hands-on training even if you have prior experience and know-how of Kubernetes. Competent training instructors can also answer unresolved queries.
- Master the Linux command line and practice problems using a text editor. Learn systems services because the exam environment relies on them.
- Get used to the exam console as it is different from stand-alone platforms. Shortcuts that work on other platforms may not work here.
- You should also learn how to set up and administer a cluster from scratch. Various online resources can help you do it.
- Maintain your speed by memorizing where to find specific topics in the documentation. Since you only need to solve two-thirds of the questions, skip time-consuming questions and solve them if you have the time.
Taking the next step
Achieving Kubernetes certifications and learning Kubernetes skills can transform your IT career by enhancing your technical expertise, boosting your resume, and opening up exciting job opportunities. Whether you’re just starting with Kubernetes or seeking advanced cloud-native security skills, these certifications validate your capabilities and set you apart in the tech industry.
Take the next step in managing your Kubernetes environment with LogicMonitor’s container monitoring solution. Our scalable, dynamic monitoring platform provides real-time visibility into your Kubernetes and Docker applications, automatically adapting to changes in containerized resources. Identify and resolve performance issues quickly while focusing on innovation.
If Artificial Intelligence is the ultimate multi-tool for IT operations (as discussed in our first article), then DevOps, Network Ops, Site Reliability Engineers (SREs), and SecOps are the teams using it. How each team uses AIOps’ capabilities will improve interconnectivity across an organization’s digital landscape, accelerate the production of high-priority business objectives, and reduce downtime to pave the way for a smoother developer and user experience.
Understanding the teams driving IT operations success
Before we map capabilities to teams, let’s establish some broad team definitions as they may currently exist within IT operations:
- DevOps: Ensure smooth collaboration between development and operations.
Priorities include automation, issue detection, and optimizing workflows to speed up software development and delivery.
- IT operations: Manage and maintain the organization’s IT infrastructure.
Priorities include improving operational efficiency, reducing downtime, and improving system reliability.
- Network operations: Manage and maintain the operation’s network infrastructure.
Priorities include identifying bottlenecks and predicting potential network issues.
- SRE: As an operational group, SREs own the back-end infrastructure responsible for the customer experience and consult with developer teams to ensure the infrastructure can support applications.
Priorities include avoiding downtime among revenue-critical systems, preventing bandwidth outages, and fixing configuration errors.
- Security operations: Protects the organization’s systems and data from security threats.
Priorities include security log analysis and response, as well as identifying anomalies or vulnerabilities.
Establishing a strong foundation: Key AIOps capabilities by team
AIOps uses artificial intelligence, machine learning, and consolidated operational platforms to automate repetitive or mundane tasks and streamline cross-team communications. An AIOps deployment is the scaffolding IT operations use to build evolving workflows so the teams can be more proactive, innovative, and able to accelerate the delivery of high-priority projects. That’s why we are seeing more AIOps success stories about how AIOps can liberate 40% of your engineering time through the automation of labor-intensive analysis or how Managed Service Providers (MSPs) are implementing AIOps’ intelligent alerting capabilities to dramatically reduce downtime.
So let’s dig into which three AIOps capabilities each team may leverage first:
DevOps
- Enhanced efficiency: Automating repetitive and manual tasks frees up time to focus on higher-value initiatives, increasing efficiency and productivity across the entire team.
- Faster mean time to resolution (MTTR): Streamlining incident management processes ensures faster issue identification, analysis, “next steps,” cross-team communications, and, ultimately, issue resolution. With automation doing the heavy lifting, these steps can happen outside of work hours. This 24/7 approach reduces the time to resolution, minimizing any impact on operations.
- Scalability and adaptability: AI and machine learning’s self-learning properties are made to handle complex and rapidly evolving technology stacks in dynamic environments.
Watch the 3-minute video below for more on how DevOps can use AIOps for faster issue resolution through integration with open-source provisioning and configuration management tools.
IT Operations
- Incident management: AIOps streamline incident identification and root cause analysis and escalate incidents to the right teams and people who can pinpoint the source of an issue and quickly fix it. Post-incident reviews are used to build resilience in systems to prevent future occurrences of similar incidents. Faster resolution reduces MTTR and operational impact.
- Scalability and adaptability: IT infrastructure has to adapt to business needs. AIOps systems handle the complexity of evolving modern stacks and dynamic environments, including hybrid and multi-cloud architectures. Faster scaling sets ITOps up for success in that they can effectively manage and monitor expanding IT landscapes at any stage of growth.
- Resource and cost optimization: Capacity planning and the automation of tasks lets ITOps teams allocate resources more efficiently, freeing up budget and personnel for new endeavors or headcount strategies.
Network Ops
- Streamlined troubleshooting: Automated root cause analysis capabilities quickly pinpoint the root causes of network issues, accelerating troubleshooting and improving uptime.
- Capacity planning: Historical and real-time data analysis on network use patterns, forecasted future demands, and resource allocation enables the team to reassign assets as needed to prevent network congestion and keep operations consistent while supporting business growth.
- Network security enhancement: Leveraging AI-driven algorithms that analyze network traffic, detect anomalies, and identify potential security threats enables Network Ops teams to take proactive measures ahead of a breach.
SRE
- Elasticity: As SRE teams manage complex and dynamic environments, including cloud-based systems and microservices architectures, AIOps provides the ability to scale and adapt to changing demands. AIOps ensures the SRE team can effectively monitor, manage, and optimize the system’s performance as it grows and evolves.
- Continuous optimization: AIOps analyzes data from various sources, including logs, metrics, and events, then identifies optimization opportunities that SRE teams can enact. Leveraging AI insights to make data-driven decisions, implement proactive measures, and continuously refine their infrastructure to achieve greater reliability.
- Collaboration and knowledge sharing: By providing a centralized platform for data collection, analysis, and visualization, AIOps facilitates communication and sharing of information so associated teams (such as developers) can align their efforts towards common goals, leading to improved teamwork and faster problem-solving.
SecOps
- Advanced threat detection: AIOps enhances threat detection capabilities by analyzing vast amounts of security-related data from various sources, such as logs, network traffic, and user behavior. AI-driven algorithms can identify patterns, anomalies, and potential security threats in real time, enabling SecOps teams to respond promptly to security incidents, minimizing damage caused by cyber threats.
- Threat intelligence integration: AIOps integrates with threat intelligence feeds and external security sources to enhance the effectiveness of security operations. By leveraging external threat intelligence data, AIOps enriches its analysis and detection capabilities, allowing SecOps teams to stay updated on the latest threats and attack vectors. This integration strengthens the overall security posture and enables proactive defense against emerging threats.
- Compliance and regulatory requirements: AIOps automate compliance monitoring and reporting processes and then compare them against predefined standards and regulations to evolve the automation and compliance process so teams consistently meet compliance and regulatory requirements.
Integrating AIOps for teams with existing tools
Seamless integration for unified operations
One of the standout advantages of AIOps is its ability to integrate with existing IT tools, providing a unified platform for monitoring, automation, and insights. Whether you’re leveraging monitoring tools like LogicMonitor, managing hybrid or multi-cloud environments, or maintaining CI/CD pipelines, AIOps can enhance and extend their functionality rather than replace them.
Compatibility with monitoring tools
AIOps platforms, such as LogicMonitor, act as a central hub, aggregating data from multiple monitoring tools to provide a unified view of IT operations. For example, integrating LogicMonitor with AIOps capabilities allows teams to consolidate alerts, correlate events, and automate responses—all from a single dashboard. This integration reduces manual intervention and provides actionable insights in real-time.
Enhancing cloud platforms
AIOps is designed to operate seamlessly in hybrid and multi-cloud environments. By analyzing data from cloud-native tools, AIOps systems provide predictive analytics, helping IT teams optimize workloads, prevent resource exhaustion, and identify anomalies before they escalate into problems.
Streamlining CI/CD pipelines
For DevOps teams, AIOps tools integrate with CI/CD platforms to enable continuous monitoring and intelligent automation throughout the development lifecycle. This ensures faster feedback loops, reduces downtime caused by deployment errors, and optimizes application performance.
Addressing legacy system concerns
One common concern when adopting AIOps is its compatibility with legacy systems. AIOps platforms are built with integration in mind, offering APIs and connectors that bridge the gap between older systems and modern tools. By applying machine learning to data generated by legacy tools, AIOps can derive valuable insights while extending the life of existing systems.
Laying the groundwork for success
To fully unlock the transformative potential of AIOps, organizations need to establish a strong foundation. These best practices ensure that teams can effectively leverage AIOps capabilities while minimizing disruptions and maximizing impact.
1. Prioritize data quality and accessibility
AIOps thrives on accurate and comprehensive data. Ensure all data sources—whether from legacy systems, monitoring tools, or cloud platforms—are clean, consistent, and consolidated. By breaking down data silos and standardizing formats, teams can enable AIOps to deliver actionable insights with precision.
2. Foster cross-team collaboration
AIOps works best when IT teams such as DevOps, Network Ops, and SREs collaborate seamlessly. Establish shared goals and encourage open communication to align team efforts. Unified dashboards, like those offered by LogicMonitor, help bridge gaps and provide everyone with a clear view of the operational landscape.
3. Start with targeted use cases
Rather than implementing AIOps broadly, begin with specific high-impact applications. Use cases such as automated incident management or anomaly detection are excellent starting points for demonstrating value and gaining stakeholder buy-in.
4. Balance automation with human oversight
While AIOps excels at automating repetitive tasks, human judgment remains critical for nuanced decision-making. Pair automated workflows with manual checks for complex scenarios to ensure both speed and accuracy in IT operations.
5. Commit to continuous improvement
AIOps systems evolve over time. Regularly monitor performance metrics, gather team feedback, and refine algorithms to adapt to changing environments. This iterative approach ensures long-term success and sustained benefits.
AIOps Use Cases
Here are some of the key use cases of AIOps in IT operations:
1. Identifying problems based on anomalies or deviations from normal behavior
AIOps enhances IT systems by using machine learning to detect anomalies and potential issues, unlike traditional tools that rely on manual configuration and threshold alerts. It analyzes data in real-time, flags deviations from normal behavior, and allows IT teams to address problems before they escalate.
2. Forecasting the value of a certain metric to prevent outages or downtime
AIOps forecasts crucial metrics like server capacity and network bandwidth, alerting IT teams before they reach critical levels. This proactive approach helps prevent outages and disruptions. By using machine learning algorithms, AIOps monitors data trends to predict threshold breaches, enabling preemptive actions to mitigate issues.
3. Improving incident response and resolution times
AIOps substantially improves incident response and resolution times by automatically correlating events from various sources and providing intelligent insights for root cause analysis. Machine learning algorithms effectively process large volumes of data from logs, alerts, and metrics to identify the root cause of incidents. This methodology not only expedites incident response but also reduces the mean time to resolution (MTTR), thereby minimizing the impact on business operations.
4. Enhancing IT operations through automation
AIOps presents substantial benefits by automating routine tasks and processes within IT operations, allowing IT teams to focus on higher-value activities such as strategic planning and problem-solving. This automation ranges from fundamental tasks like ticket routing and categorization to more complex processes such as incident remediation based on predefined rules. Consequently, it enhances efficiency, reduces the risk of human error, and streamlines workflows.
Take your IT operations to the next level
AIOps give teams the tools they need to transform from reactive to proactive. The combination of artificial intelligence and machine learning accelerates issue mitigation, breaks through work silos, improves systems security and scalability, increases productivity, reduces error risk and optimizes resources and costs. Having an AI-empowered IT operation means an organization’s infrastructure is instantly ready to handle roadblocks for a smoother developer and user experience.
LogicMonitor’s AIOps platform empowers businesses to transition from reactive troubleshooting to proactive, intelligent operations. With AI and machine learning capabilities, LogicMonitor provides meaningful alerts, illuminates patterns, and enables foresight and automation. Spend less time resolving issues and more time driving innovation.
LogicMonitor is proud to power the journey to AIOps by offering these free educational resources:
What is AIOps and How is it Changing IT Operations?
Simplify Troubleshooting with AIOps
Monitoring and Alerting Best Practices Guide
Sensirion Goes from 8 Monitoring Tools to Just One
Comprehensive AIOps for monitoring
Unlocking the Path to Automation with LogicMonitor
The art of monitoring the influence of an application’s performance on business outcomes is constantly evolving. It used to be directing IT teams to act on insights from an Application Performance Monitoring (APM) solution was enough to drive business outcomes. Now we know the user experience has a heavy hand in determining whether a digital platform survives or dies. An APM solution keeps tabs on the performance of application components such as servers, databases, and services. When it comes to monitoring user experience, Digital Experience Monitoring (DEM) is the key component organizations need to go a step further and really understand how users (human, machine, or digital) are interacting with their digital platforms.
So what is DEM exactly?
DEM is a practice within application performance management that focuses on monitoring and optimizing the overall user experience of digital apps and services. A DEM-enabled monitoring solution combines various techniques to gain insights into user behaviors, experience metrics (page load times, transaction responses, and error rates), application performance, network performance, and infrastructure performance. This allows organizations to proactively identify and address issues driving user satisfaction, improve the overall user experience, and positively drive business outcomes.
While DEM shares a connection with APM, it focuses more on the user’s perspective by tying performance metrics directly to user behaviors and experiences. DEM also complements observability practices by integrating telemetry data into user-centric insights, bridging the gap between technical performance and real-world user interactions.
Over time, DEM has evolved from basic performance monitoring to a sophisticated practice that combines real user monitoring, synthetic testing, and advanced analytics. This progression reflects the growing importance of delivering seamless digital experiences in increasingly complex environments.
Why does DEM matter?
As a monitoring capability, DEM is what mines and presents critical user patterns and trends to IT teams so they can collaboratively elevate their organization’s digital user experience from good to great. In many organizations, APM data gets splintered and analyzed through the lens of the team looking at it. Where DevOps teams are more likely to look at APM insights to keep tabs on application components and code-level performance, ITOps teams are more likely to pay attention to the data regarding broader infrastructure performance (servers, network devices, and databases). DEM provides unified insights from a variety of sources so both DevOps and ITOps get a unified look at the intertwined influences of user behavior, application performance, network metrics, and infrastructure data. This singular data set, coming directly from the users, gets IT teams out of their silos and at the whiteboard to collaborate on solutions.
Consider one scenario organizations will likely experience: a surge in CPU spikes on the servers. In the absence of DEM, DevOps and ITOps teams likely have separate insights into different application components and services, which limits their ability to troubleshoot the problem collaboratively. DEM bridges the gap between DevOps and ITOps, fostering a unified and cohesive approach to monitoring and optimizing the digital experience. It facilitates cross-functional collaboration, breaking down barriers that traditionally impede effective troubleshooting. By eliminating silos and promoting shared visibility, organizations can streamline incident response, reduce mean time to resolution (MTTR), and enhance the overall user experience.
How digital experience monitoring works
DEM works by leveraging a combination of monitoring techniques and technologies to capture, analyze, and interpret data related to user interactions with digital systems. The primary goal is to provide IT teams with actionable insights into how applications, networks, and infrastructure components impact the end-user experience. Here’s how it operates:
- Data collection: DEM solutions collect data from multiple sources, including real user monitoring (RUM), synthetic monitoring, application logs, and network performance metrics. This data spans application transactions, network latencies, server performance, and user interactions.
- Data correlation: Once collected, DEM correlates data points from these sources to build a cohesive picture of the end-to-end digital experience. For example, it links slow page load times with network bandwidth issues or high CPU usage on backend servers.
- Performance analysis: The solution uses advanced analytics and machine learning to identify patterns and anomalies. This enables IT teams to understand the root causes of performance bottlenecks, such as broken application dependencies or network congestion.
- Visualization of insights: DEM provides intuitive dashboards and reports that showcase user experience metrics, performance trends, and incident details. These visualizations are tailored to different teams, allowing DevOps to focus on application-level details while ITOps can monitor broader infrastructure health.
- Proactive alerting: By leveraging synthetic monitoring and threshold-based alerts, DEM identifies potential issues before they impact users. Simulated user journeys test critical workflows like logins or transactions, offering early warning signs of degradation.
- Collaboration enablement: DEM fosters cross-team collaboration by providing unified insights into user experience. Teams can access the same datasets, identify shared goals, and work cohesively to optimize performance and reduce mean time to resolution (MTTR).
By combining these operational mechanisms, DEM ensures organizations can maintain high-quality digital experiences for their users while proactively addressing performance challenges.
Components of digital experience monitoring
DEM is built on several key components that deliver a comprehensive view of the user experience. These components provide the data and insights necessary to monitor and optimize the performance of applications, networks, and infrastructure. Here are the essential building blocks of DEM:
- Real user monitoring (RUM):
RUM captures data from actual user interactions with an application or website in real time. It measures page load times, transaction durations, and error rates, offering insights into how users experience the platform. This component is invaluable for identifying pain points in the user journey and uncovering opportunities to enhance engagement. - Synthetic transaction monitoring:
Synthetic monitoring uses simulated user interactions to test critical workflows, such as logging into an account, completing a purchase, or searching for a product. By automating these tests, synthetic monitoring helps IT teams proactively detect issues like slow load times, failed transactions, or outages before they affect real users. - Endpoint monitoring:
Endpoint monitoring tracks the performance of devices and applications used by end users, such as desktops, laptops, and mobile devices. By analyzing factors like application responsiveness, network connectivity, and device health, this component ensures that user-side issues are addressed promptly, minimizing frustration and downtime. - Application performance monitoring (APM):
APM focuses on the performance of the application’s backend components, such as databases, APIs, and servers. It helps IT teams detect code-level issues, optimize application performance, and ensure smooth integration with other systems. - Network monitoring:
Since network performance directly affects the digital experience, DEM includes monitoring network metrics such as latency, bandwidth, and packet loss. This ensures that connectivity issues are identified and resolved to maintain seamless user interactions. - Session replay:
This component records and replays user sessions, allowing IT teams to see how users navigate and interact with digital platforms. Session replay is especially useful for diagnosing complex issues that require context beyond raw data points.
Why customer experience matters
Users don’t know which digital offerings use DEM to improve their experiences.
But they will ditch the ones that don’t.
Consider users in the e-commerce and digital retail space. DEM lets those platforms and websites monitor website performance, transaction times, and user interactions. If any of those experiences are suffering from downtime, disrupted transactions, or delayed user interactions, IT teams can use DEM analysis to identify the cause. They can then implement a solution and prevent a spike in cart abandonment rates while improving conversion rates and customer satisfaction ratings.
Let’s explore a second use case for Software-as-a-Service (SaaS) providers. DEM allows them to track user interactions, application response times, and errors to identify opportunities to enhance the customer experience and retain users (who hopefully tell their networks about the positive experience).
In both scenarios, integrating a DEM-enabled application monitoring solution would speed up the process of pinpointing the users’ pain points, diagnosing the root cause, and enabling IT teams to collaboratively solve the problem faster than they could without DEM insights.
Benefits of DEM
DEM-driven insights provide a variety of benefits to organizations looking for data-based strategies to help optimize their resources (both human and financial).
Enhanced user satisfaction
Organizations that monitor user experience metrics, such as page load times, transaction response times, and user interactions, can use this information to prioritize addressing the issues that have the most sway in user satisfaction. Proactively identifying and fixing those high-impact problems will result in higher engagement rates and increased customer loyalty.
Improved performance optimization
The holistic presentation of the end-to-end experience (application, network, and infrastructure performance) enables organizations to identify performance bottlenecks, diagnose issues, and prioritize areas for improvement faster than the competition ruled by an APM solution alone. Leveraging these insights lets IT teams optimize their applications and websites, resulting in faster load times, smoother interactions, and better overall performance.
Data-driven decision making
IT teams can know the solutions they are working on are backed by data that came from the users they are trying to impress. DEM helps developers uncover trends, patterns, and areas of improvement so those teams can prioritize resources to deliver an improved user experience effectively.
Drawbacks of DEM
Before investing, organizations need to consider some of the complexities they are signing up for when they deploy DEM capabilities in their monitoring solution.
Implementation complexity
For large or complex digital environments, integrating various monitoring techniques, tools, and systems may require upskilling or hiring the expertise needed for a successful implementation. In addition to configuring and fine-tuning the monitoring setup, ongoing maintenance and management of DEM can be a long-term investment.
Data volume challenges
DEM generates vast amounts of monitoring data, which can be overwhelming to process and analyze effectively. Organizations need to have robust data management and analysis capabilities already in place to sort through the onslaught of data, as well as a process in place for converting it into actionable insights for IT teams.
Resource considerations
Integrating and maintaining a DEM solution may require financial and resource investments ranging from procuring monitoring tools to hiring skilled personnel. Ongoing data analysis efforts may require long-term resource allocation.
Despite these drawbacks, many organizations will want to harness the benefits of DEM, as they outweigh the challenges.
Developing a digital experience monitoring strategy
Establishing an effective DEM strategy is essential for enhancing user satisfaction and business outcomes. A well-defined approach ensures that DEM integrates seamlessly with existing processes while delivering actionable insights. Here are the key steps to building a robust DEM strategy:
- Start with user-centric goals:
Define objectives that focus on improving the user experience. This includes reducing page load times, minimizing transaction errors, and ensuring seamless navigation. A user-centric approach aligns IT teams with what matters most—satisfaction and retention. - Leverage real-time analytics:
Enable real-time data collection and analysis to identify and resolve issues as they occur. This proactive monitoring approach minimizes downtime and ensures that problems are addressed before they impact users. - Integrate across tools and teams:
Ensure your DEM solution integrates with other monitoring tools, such as application performance monitoring (APM), network monitoring, and log management systems. This creates a unified view of the digital ecosystem, fostering cross-team collaboration between DevOps, ITOps, and other stakeholders. - Prioritize key metrics:
Identify and track metrics directly influencing the digital experience, such as transaction response times, error rates, and network latency. Tailor these metrics to your industry and use case to ensure relevance and accuracy. - Adopt synthetic monitoring:
Incorporate synthetic transaction monitoring to test critical workflows and identify issues before they reach end users. This proactive testing complements real user monitoring and strengthens overall system reliability. - Establish a feedback loop:
Create a process for continuously evaluating the effectiveness of your DEM strategy. Use insights from monitoring data to make iterative improvements, such as optimizing application code, upgrading network infrastructure, or refining user interfaces. - Communicate insights effectively:
Provide tailored dashboards and reports for different teams. For instance, technical teams may need granular data, while business teams benefit from high-level KPIs. Ensuring clarity in communication helps align efforts across the organization.
Not all DEM-enabled solutions are the same
Selecting the right APM is about more than the list of capabilities. The first consideration should be how a new DEM-enabled APM solution will complement any existing monitoring solutions.
Integration and compatibility
It is essential to evaluate how well the DEM-enabled APM solution integrates with your existing monitoring ecosystem. Consider whether it can seamlessly integrate with other monitoring tools and systems you rely on, such as application performance monitoring (APM) tools, log management, network monitoring, network performance diagnostics, or cloud monitoring platforms. Compatibility between the DEM-enabled APM solution and your existing infrastructure ensures smooth data aggregation, correlation, and analysis.
Scalability and flexibility
Consider whether the DEM-enabled APM solution can scale as your digital infrastructure grows and evolves. It should be able to handle increasing data volumes, monitor diverse applications and services, and adapt to changing technology stacks. Additionally, assess the flexibility of the solution in terms of customization and configuration to align with your specific monitoring requirements.
Context and correlation
An APM solution should provide DevOps and ITOps with context and correlation within observability platforms to manage application performance and gain digital experience insight across hybrid and multi-cloud environments to allow for cross-team collaboration. By proactively sharing those insights into the digital experience, both teams can own the solutions that enhance user satisfaction, increase productivity, and drive better business outcomes.
How LogicMonitor can help
If DEM is a measure of how much an organization values its users’ experiences, then LogicMonitor’s Application Performance Monitoring solution is how organizations show they’re serious about improving the processes and technologies that ensure their operations don’t just meet – but they exceed – users’ expectations.
OpenTelemetry integration monitors end-to-end application requests through distributed services in your existing environment.
Performance metrics capabilities can graph everything from high-level KPIs to granular technical metrics, visualizing business outcomes for the teams that need to deliver them.
Synthetic monitoring brings solution theories to life before users can test them in real time. This capability simulates end-user traffic through automated browser tests of user interactions or transactions, giving early insights into the quality of the end-user experience.
How to maximize value with Jira and AWS Lambda integration
One of our engineers on the TechOps team coined the term “Value++.” It references the shorthand operator for “increment” in various coding languages. It is also a motto for what we should be doing as a team—always adding value.
Here are a few things in our day-to-day operations that have been a serious “value –”
- Answering JIRA tickets that have no description
- “Customer has issue B,” but both the customer name and issue details are omitted from that sentence
- Doing things manually, over and over again
At LogicMonitor, most of the tasks requested of the TechOps team come in the form of JIRA tickets. A new application may be ready for deployment, or a customer account may require a rename. We also have to deal with operational tasks like moving new customer accounts from demo to production environments.
Because LogicMonitor is rapidly growing, we always try to be more efficient by automating ourselves out of work. We decided to automate parts of our DevOps tasks through AWS Lambda functions, API calls, and JIRA tickets. This allows the team to keep track of existing tasks that show up in our queue and spend their time doing more important things.
It’s “Value ++.”
Understanding projects and issue types for automation
We first had to lock down specific JIRA projects and issue types to differentiate tasks from other items, creating a separate issue type for every task we wanted to automate. This makes things easy to organize and allows us to lock down who can or cannot make specific tickets.
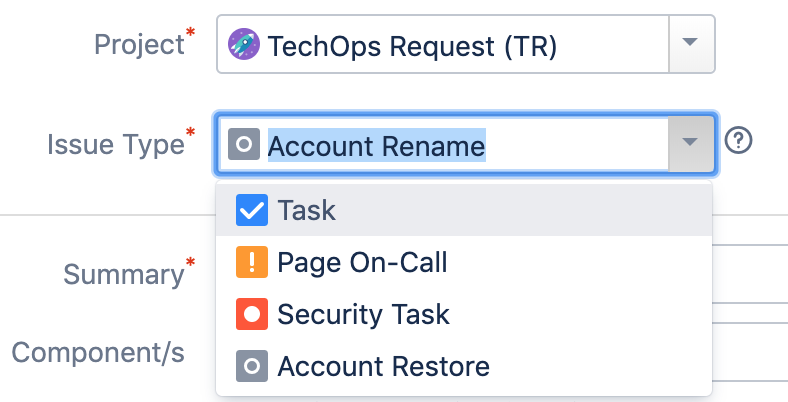
In this blog, we’ll go over one of our simpler use cases: automatically performing an account rename.
Streamlining workflows with straightforward solutions: The simple stupid
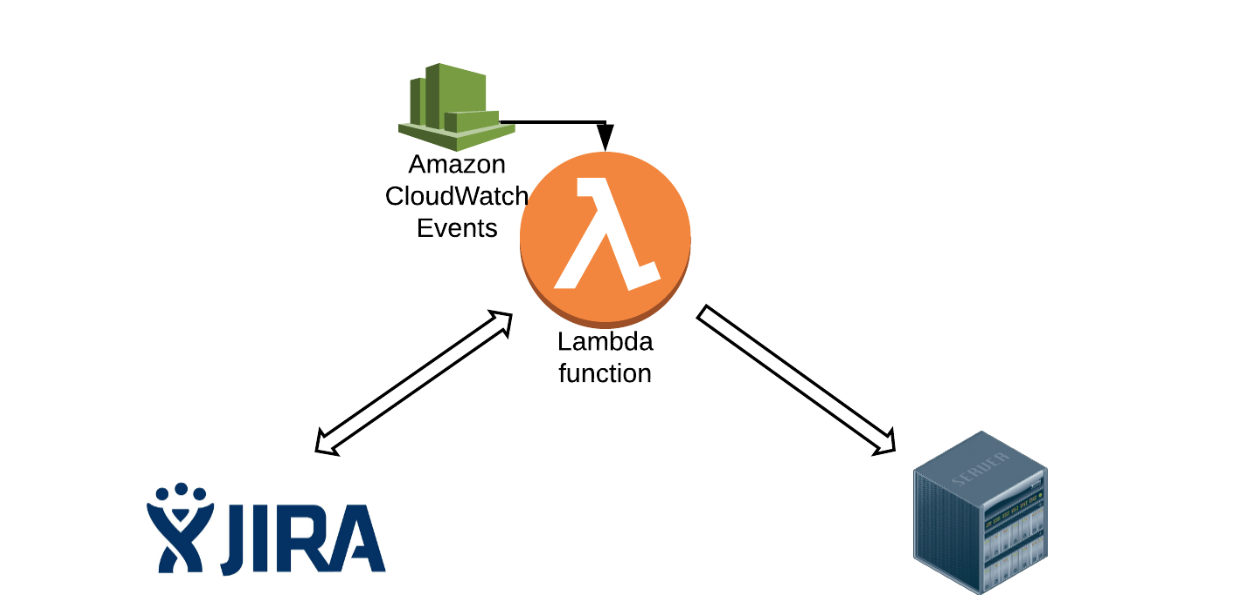
This crude Lucidchart (below) shows the basics of what we did. Every 5 minutes, a CloudWatch Event rule triggers a Lambda function. The function will make a JIRA API call to retrieve a list of tickets. Using those tickets, we will grab the necessary information and make subsequent API calls to backend services within LogicMonitor to perform specific actions, such as renames. Lambda will also actively update and close the tickets upon task completion. The first thing we need to do is know what tickets to look for.
Executing JQL queries directly from AWS Lambda
JIRA Query Language (JQL) is one of the most flexible ways to search for issues in JIRA. We use a JQL query with the JIRA REST API to find specific open tickets with issue types of “account rename.” This should return a list of associated tickets.
endpoint = "https://jira_url/rest/api"
jql_issuetype = "issuetype='Account Rename'"
jql_project = "project='TechOps Request'"
status = "status=Open"
jql = ("jql=" + jql_project +
"+AND+" + jql_issuetype +
"+AND+" + status
)
r = session.get(endpoint + "/2/search?" + jql % locals(), headers=headers_jira)
response = json.loads(r.text)
for issues in response["issues"]:
customer = issues["fields"]["customfield_10001"]
target_name = issues["fields"]["customfield_14673"]
Taking the list of open tickets, we need to be able to glean important information out of them, some of them in the form of custom fields.
Customizing workflows with Jira’s custom fields
Users create custom fields, which are not by default available in JIRA. For our specific use case, we created a few fields, such as customer name, target name, and rename date. From the code example above, you can see that within the JIRA API, you can not specify just the field’s name; you’ll need to add a customfield_id.
Pro tip:
If you don’t want to look at a page of ugly JSON, you can also use the advanced JIRA search bar and type in the field’s name.

Embracing event-driven automation with AWS Lambda… most of the time
Usually, when we build apps on Lambda, we have components like Lambda functions and event sources. An event source is an AWS service that publishes events for processing by code within a Lambda function. In this case, performing a rename upon JIRA ticket creation could have been handled with a post function and an API Gateway. However, customers have their own maintenance windows and preferred times for an account rename to happen. Sometimes, customers may want their account renamed on Saturday at 4 a.m. during my personal maintenance (sleep) window. As a workaround, we decided to use a CloudWatch event as a lambda scheduler.

today = datetime.datetime.today() - datetime.timedelta(hours=7)
desired_date = datetime.datetime.strptime(issues["fields"]["customfield_16105"].replace("-0700",""), "%Y-%m-%dT%H:%M:%S.%f")
if today > desired_date:
create_rename(customer, target_name)
Our CloudWatch event would run every 5 minutes, triggering our Lambda function. The function will first check if the current time exceeds the value we parsed from the custom field rename date (see code above), and then we will allow the function to continue.
Combining tools to create seamless automation
At this point, we have collected the information we need. We can perform the rename by making API calls to the backend LogicMonitor services, but we won’t show that code in this blog. However, we also want to treat the JIRA ticket as a state file. We don’t want to keep grabbing the same open tickets repeatedly. This is where we want to use another JIRA API call to move the ticket to a different workflow step (e.g., from “Open” to “In Progress”). However, just like custom fields, we need a specific transition id, which you can find by editing your existing project workflow. We can now update the status of our JIRA ticket programmatically:
def changeStatus(key, id):
jira_request = {"transition":{"id": id }, "fields": {"resolution": {"name": "Done"}}}
endpoint = "https://jira_url.com/rest/api"
r = session.post(endpoint + "/2/issue/%(key)s/transitions?expand=transitions.fields" % locals(), data=json.dumps(jira_request), headers=headers_jira)
return r.text
Reducing human errors through intelligent automation: Saving people from people
Customer renames for the team used to be an extremely arduous task. Looking back at the Confluence revision history for our account rename runbook is akin to cleaning out your basement after 20 years. Besides being extremely time-consuming, the process involved halting puppets and, for unknown reasons, executing both a Ruby and a Bash script simultaneously. Sometimes, an application restart was required, but it was not always. As we grow, the only scalable solution is to automate repetitive, manual, and often mind-boggling tasks. It allows us to provide better service for customers and allows us to bypass the mundane to embrace the innovative.
One last tip—and this is the most important part—when we want to automate anything that requires manual input from other people, we have to take human stupidity… uh… error into consideration. Make sure to create validators and conditionals to combat this.
Plus, witty warning messages are a “value++.”

The Java Management Extensions (JMX) framework is a well-known tool for any experienced Java developer. The purpose of the JMX framework is to simplify the management of local and remote Java applications while providing a user-friendly interface.
The primary advantages of the JMX framework are that it’s highly reliable, scalable, and easy to configure. However, it’s also known for introducing the concept of MBeans, which unlocks the capacity for real-time Java application management. Here’s a closer look at the JMX framework and JMX monitoring.
Contents
- What Is JMX?
- What Is JMX Monitoring?
- What Are MBeans?
- How Is Data Collected?
- Comparing JMX Monitoring Solutions
- Why Should I Monitor Java Applications?
- Why Is JMX Monitoring Important for DevOps?
- Conclusion
What Is JMX?
Since Java 1.5, the Java Management Extensions (JMX) framework has been widely adopted as a user-friendly infrastructure solution to help manage both remote and local Java applications. Since JMX introduced the concept of MBeans, it helped to revolutionize Java application management and bring real-time management tools into the picture.
The features of JMX include the ability to:
- Easily manage Java apps and services without making heavy investments of time or resources. Since JMX needs only a core managed object server, you can manage your Java apps without really impacting how they are designed.
- Scale your management architecture as needed, without unnecessary complexity. Once you have set up the JMX agent service, it will run independently. Through this component-based approach, you can scale your JMX solution almost infinitely with hardly any changes necessary to the program itself.
- Leverage flexible and dynamic solutions to help you stay on top of future concepts. With the ability to use emerging technologies, you can stay ahead of the competition without completely reworking your solution every time a new approach or technology is released.
- Focus on managing your apps and services without a lot of legwork. You can certainly utilize JMX within a distributed environment, but the APIs make it simple to add management tools for your services, applications, systems, and networks.
As you can see, there are many reasons to utilize JMX if you’re currently working with Java applications. However, one of the best features of JMX is known as JMX monitoring. So, let’s take a closer look at how you can leverage it.
What Is JMX Monitoring?
The purpose of the JMX framework is to support monitoring and management initiatives for Java applications. By creating a generic system for monitoring Java applications, JMX monitoring unlocks some fundamental tools, such as notifications that can alert a team when an app needs attention or when the state of an application changes.
In addition to notifications, JMX monitoring can also help improve observability by exposing run time metrics and revealing resource utilization and allocation. One of the most crucial components to understanding JMX monitoring is the MBeans that help developers recognize and organize resources on their Java Virtual Machines (JVMs).
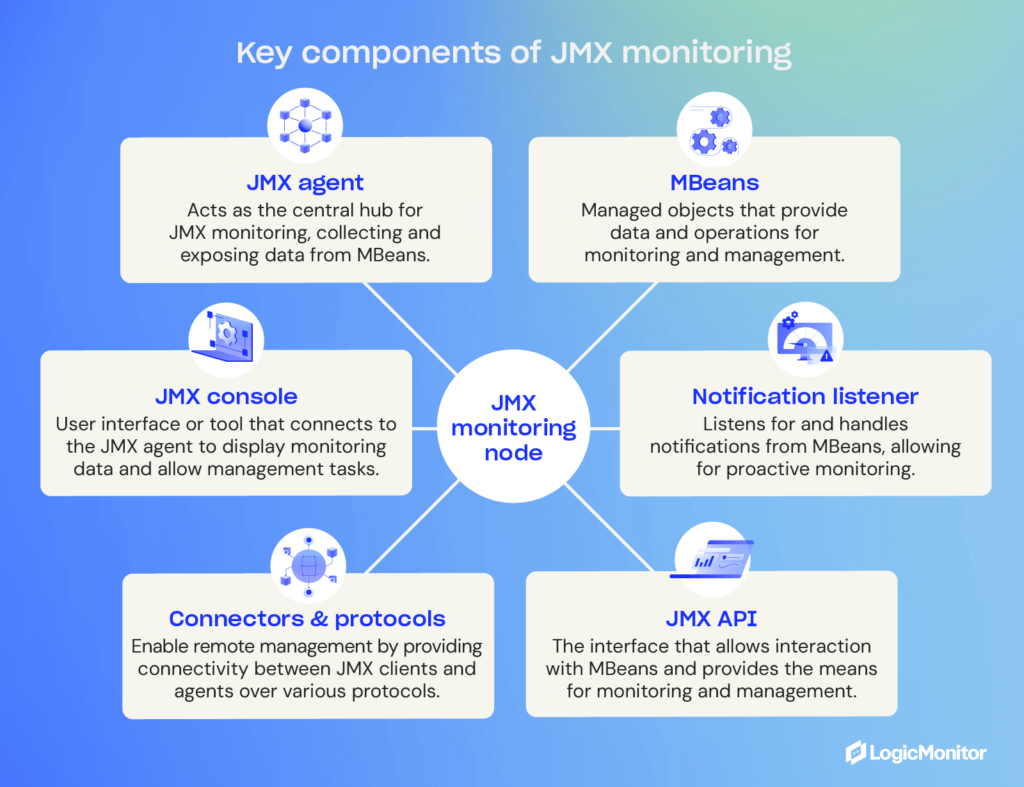
Overall, there are three tiers of components involved in JMX monitoring:
- The probe or instrumentation level is made up of MBeans wrapped around individual resources.
- The agent level consists of the MBean Server that exposes MBeans to applications on the next layer.
- The management level is where the connectors exist that allow your remote applications to access the MBean Server for monitoring and management purposes.
With these things in mind, here’s a more thorough explanation of how MBeans work and what developers can do with them to improve the monitoring and management of their Java applications.
What Are MBeans?
Managed Beans, or MBeans, form the foundation for JMX monitoring. The purpose of an MBean is to represent a resource within a Java Virtual Machine (JVM) to make it easier to configure and utilize. Within the JMX console, developers can expose a resource/MBean using a JVM port. From the console, developers can also group your MBeans into domains to help them easily track where all of their resources belong.
When looking at a Java Virtual Machine (JVM), you’ll generally see multiple domains, each with many MBeans assigned to it. For instance, a Java application using tomcat might have domains named Catalina and Java.lang. The former would include all resources (MBeans) for the Apache tomcat container known as Catalina, and the latter would contain all of the MBeans for the JVM run-time.
Depending on how a team manages things, they can choose to create custom domains for individual applications. This flexibility is important because today’s applications have very different requirements, with some requiring only a small footprint and others needing significant resources. While teams can optimize applications themselves during development, optimizing a JVM run-time and container is often handled after the fact.
When it comes to run-time and container optimization for Java apps, many developers might already be familiar with how to alter heap size or garbage collection, but MBeans can also play a role by helping them to allocate resources where they’re needed most.
How Is Data Collected?
Now that you understand the big picture overview of how JVM monitoring works and what MBeans serve to do, it’s also worth explaining how data is collected within Java Virtual Machines (JVMs).
The technical explanation involves some mostly unseen components, including MBeans and an MBean Server. The MBeans themselves take on the role of Java wrappers for components, apps, devices, and services within your network. Meanwhile, the MBean Server is where you can find and manage the resources that the MBeans represent.
Therefore, the MBean Server is the central focus of your JMX monitoring endeavor. If you want to get technical, a JMX agent consists of the MBean Server and the services necessary to handle the MBeans, such as an application performance monitoring (APM) solution. This setup keeps your resources independent of whatever infrastructure you use to manage them, which provides added flexibility.
If you’re using remote management tools, there are standard connectors (known as “JMX connectors”) that you can use to connect things together regardless of communication protocols. This means that you can use JMX connectors to use systems and apps that are not compatible with JMX specifically, as long as they support JMX agents.
Comparing JMX Monitoring Solutions
Once JMX agents are in place, you’re one step closer to easily managing and monitoring your Java applications. However, another important part of the process is deciding which monitoring solution you wish to use. Some of the most popular include:
- JConsole: Works alongside Java Management Extensions for both remote and local applications but is more ideal for development and prototyping than live deployments due to its intense resource consumption. Still, JConsole provides a wealth of information, including uptime, live threads, peak, etc.
- JMX Console: This management console is used by JBoss and allows developers to tap into the raw data produced by MBeans and unlocks the option to start or stop components and complete simple tasks. Keep in mind that JBoss is an open-source middleware solution provided by Red Hat, but a paid subscription is available for extra documentation and support.
- JManage: If you’re working with distributed applications, JManage is an open-source solution that’s worth considering, and it offers both web-based and command-line interface tools. It also supports an SNMP network along with JMX. The team behind JManage strives to offer a solution suitable for managing entire production environments.
- ManageEngine Applications Manager: If you’re interested in an on-premises paid software package, ManageEngine is comprehensive enough to enable entire IT departments and DevOps teams to implement JMX monitoring on any Windows or Linux server. A professional and enterprise edition is available, depending on a client’s budget and requirements.
- AppDynamics: Another paid solution, AppDynamics can provide additional flexibility since it is web-based. This platform is compatible with MBeans and can compile detailed activity reports for all your Java apps. Multiple tiers are available to fit various business sizes. This platform is part of the Cisco corporation and is widely trusted by enterprises.
- LogicMonitor: We use LogicMonitor to monitor our own infrastructure using JMX metrics. Since it’s so customizable, we’re able to track individual processes for particular microservices to get an overall idea of the service’s health and performance. It can be really useful for knowing when things go wrong (hello alerts!) and for helping unlock bottlenecks (hello dashboards!).
Depending on your needs and preferences (e.g., on-premises versus web-based or open-source versus paid), there are several other JMX monitoring solutions on the market. You do your research to make sure that investing in this area is worthwhile and that you know what you want to achieve going forward.
Why Should I Monitor Java Applications?
There are countless reasons to monitor your Java applications, but the most significant advantage is unlocking a heap of performance metrics that can help you fine-tune your JVMs and applications to make sure you’re making the most of all resources available to you.
While many developers are familiar with how to configure garbage collection or other settings to help boost the performance of their Java apps, learning to use the JVM framework will take them that much farther when it comes to optimization.
If you’re on the fence about using JVM monitoring to keep tabs on your Java applications, here are some practical reasons and considerations to keep in mind:
- Through monitoring, you can identify issues and potential issues sooner, giving you the best opportunity to correct them before they harm your end-users.
- By revealing the number of resources being consumed by your applications and understanding specific metrics and usage patterns, you can help avoid downtime and delays by allocating more resources when and where they’re needed.
- In the case of applications with a smaller footprint that don’t require a lot of resources, you can improve resource utilization across the board by taking unused resources away and allocating them elsewhere.
- The right metrics can help reveal bottlenecks and room for improvement, allowing you to speed up applications and improve the end-user experience.
Overall, there are countless reasons to pursue Java application monitoring and very few reasons not to. Especially when using JMX monitoring, which is relatively easy to use and implement, your business is likely to notice far more improvements and advantages than it will negative impacts on staff or internal resources.
Why Is JMX Monitoring Important for DevOps?
DevOps teams rely on powerful monitoring tools to better understand how development work behind-the-scenes impacts operations and vice versa. Monitoring tools like JMX can reveal opportunities to boost operational performance by re-evaluating the development processes that negatively impact an application.
Likewise, JMX monitoring can reveal information to the operational team about where future development projects may be necessary or tell the development team how operations are utilizing (or not utilizing) an app. Altogether, JMX monitoring provides numbers that increase observability and helps DevOps work together to achieve better outcomes.
Conclusion
Fine-tuning Java performance has long been a focus of Java developers everywhere, but there are few approaches that don’t require heavy time and resource investments. That’s why combining JMX with the correct monitoring tool is one of the easiest ways to give your team a headstart on understanding and improving the performance of your Java apps.
Whether you’re hoping to better allocate resources to help you keep scaling up, set up notifications to minimize negative end-user experiences, or keep an eye on the numbers to ensure continued success, JMX monitoring offers a suite of tools that can help you get there with ease.
If you are running Java applications, there are a few reasons not to use JMX monitoring. Thanks to its ease of use and plentiful documentation, your team will likely find that implementing and utilizing JMX monitoring is far easier than any manual processes you may already have in place — and your results will improve ten-fold.
Distributed tracing is an essential process in the modern world of cloud-based applications. Tracing tracks and observes each service request an application makes across distributed systems. Developers may find distributed tracing most prevalent in microservice architectures where user requests pass through multiple services before providing the desired results.
In this blog, we will explore the concept of spans within distributed tracing, delve into their composition and role in monitoring, and discuss best practices for effectively implementing span tracing to optimize the performance and reliability of cloud-based applications.
Introduction to span tracing
Span tracing is a critical component of distributed tracing, which is essential for monitoring and managing the performance of modern cloud-based applications. In distributed systems, particularly those utilizing microservice architectures, user requests often traverse multiple services before delivering the desired outcome.
Spans serve as the foundational elements of this tracing process, representing individual units of work within a trace. By breaking down each service request into smaller, time-measured individual operations, span tracing provides developers with granular visibility into the flow of requests across a distributed environment.
Understanding spans is crucial because they offer the detailed insights needed to diagnose performance bottlenecks, track the flow of requests, and ultimately optimize the reliability and efficiency of distributed applications.
Understanding distributed tracing
Developers can acquire a comprehensive perspective of their software environment by combining distributed traces, metrics, events, and logs to optimize end-to-end monitoring and operations. Spans serve as the fundamental building blocks in distributed tracing and represent the smallest measure of work in the system.
DevOps engineers can set up distributed tracing across their operations by equipping their digital infrastructures with the necessary data collection and correlation tools, which should apply to the whole distributed system.
The collected system data gives insightful information while offering the earliest signs of an anomalous event (e.g. unusually high latency) to drive faster responses.
A closer look at spans in distributed tracing
A trace comprises a combination of spans, with each span serving as a timed operation as part of a workflow. Traces display the timestamp of each span, logging its start time and completion. Timestamps make it easier for users to understand the timeline of events that run within the software. Spans contain specific tags and information on the performed request, including potentially complex correlations between each span attribute.
Parent Spans
The parent, or root spans, occur at the start of a trace upon the initial service request and show the total time taken by a user request. Parent spans contain the end-to-end latency of the entire web request. For example, a parent span can measure the time it takes for a user to click on an online button (i.e., user request) for subscribing to a newsletter. During the process, errors and mistakes may occur, causing parent spans to stop. These spans branch out to child spans, which may divide into child spans of their own across the distributed system. It is important to note that parent spans may finish after a child span in asynchronous scenarios.
Detailed visualization of parent-child references provides a clear breakdown of dependencies between spans and the timeline of every execution.
Developers should refer to every span – parent/root and subsequent child spans – in distributed tracing to gain a comprehensive breakdown of request performance throughout the entire lifecycle.
Key components of a span
Every span contains specific descriptors that comprise the function and details of logical work performed in a system. A standard span in distributed tracing includes:
- A service/operation name – a title of the work performed
- Timestamps – a reference from the start to the end of the system process
- A set of key:value span tags
- A group of key:value span logs
- SpanContext includes IDs that identify and monitor spans across multiple process boundaries and baggage items such as key:value pairs that cross process boundaries
- References to Zero value or causally related spans
Span Tags
Essentially, span tags allow users to define customized annotations that facilitate querying, filtering, and other functions involving trace data. Examples of span tags include db.instances that identify a data host, serverID, userID, and HTTP response code.
Developers may apply standard tags across common scenarios, including db.type (string tag), which refers to database type and peer.service (integer tag) that references a remote port. Key:value pairs provide spans with additional contexts, such as the specific operation it tracks.
Tags provide developers with the specific information necessary for monitoring multi-dimensional queries that analyze a trace. For instance, with span tags, developers can quickly home in on the digital users facing errors or determine the API endpoints with the slowest performance.
Developers should consider maintaining a simple naming convention for span tags to fulfill operations with ease and minimal confusion.
Span Logs
Key:value span logs enable users to capture span-specific messages and other data input from an application. Users refer to span logs to document exact events and timelines in a trace. While tags apply to the whole span, logs refer to a “snapshot” of the trace.
SpanContext
The SpanContext carries data across various points/boundaries in a process. Logically, a SpanContext is divided into two major components: user-level baggage and implementation-specific fields that provide context for the associated span instance.
Essentially, baggage items are key:value pairs that cross process boundaries across distributed systems. Each instance of a baggage item contains valuable data that users may access throughout a trace. Developers can conveniently refer to the SpanContext for contextual metrics (e.g., service requests and duration) to facilitate troubleshooting and debugging processes.
Best practices for effective span tracing
To maximize the benefits of span tracing, developers should follow best practices that enhance the accuracy and efficiency of their observability efforts. One key practice is to choose the right tags for each span, ensuring that they provide meaningful and actionable insights. Standardized tags such as http.method, db.type, and error help streamline database queries and filtering, making it easier to diagnose issues across distributed systems.
Managing span volume is another crucial aspect. In large-scale environments, excessive span data can lead to performance overhead and make traces harder to analyze. Developers should focus on capturing only the most relevant spans and data points, prioritizing critical paths and high-impact operations. By strategically reducing unnecessary spans, teams can maintain the performance of their tracing system while still gathering essential metrics.
Optimizing span data involves careful instrumentation, including the use of concise and consistent naming conventions for operations and services. Ensuring that each old or new span includes key-value pairs that accurately reflect the operation it represents will facilitate more precise monitoring and troubleshooting. Additionally, developers should regularly review and refine their span tracing setup, adjusting as their systems evolve to maintain optimal observability and performance.
Spans vs. traces: What’s the difference?
At its core, a trace represents a service or transaction under a distributed tracing structure. Spans represent a single logical structure within a given trace. Trace context is a significant component for traces within a distributed system as they provide components with easy identification through the use of unique IDs.
Implementation of a trace context typically involves a four-step process:
- Assigning a unique identifier to every user request within the distributed system
- Applying a unique identification to each step within a trace
- Encoding the contextual information of the identities
- Transferring or propagating the encoded information between systems in an app environment
Traces capture the data of a user service request, including the errors, custom attributes, timelines of each event, and spans (i.e., tagged time intervals) that contain detailed metadata of logical work. Therefore, a trace ID refers to the execution path within a distributed system, while a span represents a single request within that execution path.
Summary of spans in distributed tracing
Distributed tracing enables developers to track and observe service requests as they flow across multiple systems. A trace serves as performance data linked to a specific user request in a function, application, or microservice. Each trace comprises spans representing the smallest measurement of logical data and contains metrics that direct users to specific events.
Specifically, a trace is the complete processing of a user request as it moves through every point of a distributed system (i.e., multiple endpoints/components located in separate remote locations).
Spans in distributed tracing provide IT specialists with granular control over data transferred between multiple end-users, improving the monitoring and diagnostics of IT operations.
Advantages of spans and distributed tracing
Modern digital operations involve complex technologies such as cloud, site reliability engineering (SRE), and serverless functions. Software managers and engineers typically accustomed to managing single services lack the technological capabilities to monitor system performance on such a scale.
As such, remote online processes involve multiple user requests passing through distributed tracing to different functions and microservices, resulting in increased system speed and reduced delays in transforming code into products.
Distributed tracing (and spans that serve as the essential logical measurement of work within these functions) optimizes observability strategies for developers within complex and remote app environments.
Combining distributed tracing and a good understanding and implementation of spans allow software teams to pinpoint challenges or faults when managing user requests from multiple endpoints for expedited troubleshooting. Some immediate benefits of a distributed tracing and span-based approach include:
- Improved user experiences that lead to a more favorable business reputation and outcomes
- Holistic management of software systems that minimize downtime for maximum efficiency
- Creation of a proactive software environment that gives the company an edge over other companies in the increasingly competitive digital landscape
- Accurate and responsive identification of user priorities so system managers can quickly determine the steps and measures to keep digital users/customers satisfied
Developers may implement distributed tracing through various methods with differing difficulties. Choosing a method depends on the user’s current programming knowledge, infrastructure, and skill sets. Building a distributed tracing system from scratch provides the most flexibility and customization.
Take your observability to the next level with LogicMonitor
At LogicMonitor, we help companies transform what’s next to deliver extraordinary employee and customer experiences. Our solutions empower you to achieve comprehensive monitoring and streamlined operations.
Microservices are becoming increasingly popular and are considered to be the next flexible, scalable, and reliable approach. Without a doubt, many developers are rethinking their application development methods. However, while many have been quick to jump on the microservices bandwagon, moving from monolithic architecture is not a decision that you should make lightly.
Before you decide the best way forward in your application development endeavors, it’s important that you understand the differences between legacy/monolithic architecture and microservices applications and the inherent pros and cons that each one holds. So, let’s dive in.
Contents
- What Is a Legacy Application?
- What Is a Monolithic Application?
- What Are The Pros and Cons of Monolithic Applications?
- What Is a Microservices Application?
- What Are The Pros and Cons of Microservices?
- When and Why Should You Choose Monolithic Development?
- When and Why Should You Choose Microservices Development?
- Combining monolithic and microservices: A hybrid approach
- What are the pros and cons of hybrid approaches?
- When to consider a hybrid approach?
- Choosing the right architecture for your application
What is a legacy application?
While monolithic applications are often referred to as legacy applications and vice versa, the two concepts are different. Many legacy applications are monolithic applications, but the term “legacy” actually refers to the state of development.
Typically, legacy applications are not being actively improved anymore, but they are being maintained enough to keep them running for the users who rely on them. Legacy applications eventually get phased out–either because the limited development of features and the user interface poses constraints for users or because the operations team decides they no longer want to maintain it.
In any case, migrating away from legacy applications and replacing them with something newer has many advantages for a business, but sometimes that approach presents just as many challenges. Rarely does a business rely on a legacy application because it lacks better options. Usually, there are better options, but moving to them is difficult because their business workflows are so tightly coupled with the legacy app.
What Is a monolithic application?
Many legacy applications fall under the umbrella of monolithic applications because monolithic development was extremely popular. Monolithic development creates single-tier applications where every component the application requires is built into itself.
The design of a monolithic application means that making changes to a feature is complicated. There are so many dependencies within the large applications that even a small update is time-consuming, and it requires all users to download an entirely new version for things to work. That’s why most monolithic applications are approached with a waterfall software development process where changes might be released annually or semi-annually.
Pros and cons of monolithic applications?
While the concept of monolithic applications might seem to contradict many modern best practices of application development, there are certain use cases where a monolithic approach might be ideal. Understanding the pros and cons of monolithic applications will help you decide if there’s ever a good time for you to take this approach.
Pros of monolithic applications
- Monolithic applications are simple to build, test, and deploy, with regard to software engineering. Because everything is housed together, developers will favor how easy it is to actually launch the application initially, but maintenance down the road is a different concern.
- Horizontal scaling is possible. Many people think that scaling a monolithic application is difficult. Still, they can actually scale horizontally fairly easily, and teams just need to run several copies of the app behind a load balancer to meet demand. Of course, this is most easily done in one direction because it’s hard to scale back once you’ve scaled up.
- Fewer cross-cutting concerns. Given that monolithic applications have one codebase for everything, there are fewer cross-cutting concerns when it comes to logging and monitoring performance.
- Improved performance. Since all the components in a monolithic application can share memory, they can boost performance because it’s faster than using service-to-service communications.
Cons of monolithic applications
- By nature, monolithic applications are fixed and linear instead of modular, and this contributes to the tight coupling of components. Entanglement and coupling impact the team’s ability to manage, scale, and update the application over time.
- One error can bring the whole thing down. Reliability is a major problem with monolithic applications. Because of the tight coupling of components, if one thing goes wrong in any module, it might make the entire application unusable.
- Updates require the entire application to be redeployed. Because there’s one large codebase with components so tightly coupled together, developers must re-deploy the entire application for every update.
- Technology limitations. In order to design a monolithic application, developers must use the same technology stack throughout the application. Making changes to this tech stack down the road will prove costly.
What is a microservices application?
Microservices are not just an approach to development but a greater approach to systems software architecture that will have a ripple effect throughout an entire company. The concept is appealing, and it can offer a myriad of advantages, but that has led a number of businesses to adopt microservices without fully thinking through the complications of doing so.
To put it simply, microservices applications are applications that are loosely coupled. Instead of creating an all-encompassing application, like a monolith, the microservices approach seeks to break each application down into standalone functionality components, dubbed a “microservice.”
Most often, microservices are packaged into containers, which are runtime environments that only contain the elements absolutely necessary to run the microservice. This gives developers, for example e-commerce developers, the freedom to pick and choose microservices and piece them together like a puzzle, allowing applications to be assembled. With microservices, each service can be added, changed, or entirely removed independently of the other microservices that make up an application.
Pros and cons of microservices
The loose coupling and independence of microservices have made them a de facto standard for DevOps, but it’s important to realize that DevOps and microservices aren’t the right fit for everyone. Let’s explore the pros and cons of microservices to help you decide if it’s the right approach for your development projects.
Pros of Microservices Applications
- Microservices are highly scalable. One of the biggest advantages of using microservices is that each component (i.e., microservice) can be scaled up individually and independently of the others, which makes optimizing resources very straightforward.
- Loose coupling simplifies changes. Since each microservice is loosely coupled to the others, development teams can easily test each component on its own and make changes to them over time.
- Improved fault isolation. When one microservice breaks, it won’t take down your entire application. In fact, you’ll be able to work with that broken microservice independently and get it up and running again faster.
- Language and tech agnostic. With microservices, you can select the best programming language or platform for each individual service, which makes utilizing the best-matched skill sets and new technology easy.
Cons of Microservices Applications
- Microservices go beyond development. Microservices architecture impacts systems, tools, methods, and many other components. Implementing microservices successfully starts with having a team that can support them.
- Tracking and monitoring can be extremely difficult. Breaking your apps down into multiple components makes development easier, but it makes tracking and monitoring things like performance and errors much more difficult and costly. To offset this, it is recommended to invest in a comprehensive container monitoring platform to gain full visibility into your microservices and containerized applications.
- Implementation leads to many anti-patterns. Many teams end up completely offsetting the advantages of implementing microservices by failing to properly plan out the implementation process and effectively change their approach and infrastructure. That’s why moving to microservices takes a great deal of time and research.
When to choose monolithic architecture
With the rise of microservices popularity, many developers have been quick to dismiss “traditional” development approaches like monoliths. But microservices are not a one-size-fits-all solution.
Overall, you’ll want to choose a monolithic architecture if:
- You’re working with a small team. If you’re working on your own or with a small team, don’t put the complexity of microservices on your to-do list. A monolith will be able to meet your needs without making you change your entire approach to development.
- You’re creating a simple application. A small application does not have the requirements in regards to flexibility or scalability to justify pursuing microservices. A monolith approach will help you by keeping everything together.
- You know nothing about microservices. Microservices require an incredible amount of research and practice. You won’t see any business value if you or your team aren’t already experts in microservices.
- You want to launch quickly. A monolith application will help you develop and launch the solution as soon as possible, and it can reduce your initial costs and help you validate the idea sooner.
When to choose microservices development
It’s easy to be enticed by all the benefits of microservices architecture and the potential that this development approach offers. However, microservices simply aren’t feasible for everyone. In fact, microservices applications can be needlessly costly and hard to monitor.
Before you choose microservices for your applications, it’s important to remember that implementing microservices isn’t an easy feat and it’s not something you should take lightly. Make sure you can check these boxes:
- Your entire team has microservices expertise. You and your team have to possess the skills and knowledge necessary to effectively implement microservices architecture and follow the best practices. You also need relevant experience in things like DevOps, containerization, and domain modeling.
- You have the appropriate resources. Appropriately implementing and managing microservices requires multiple dedicated teams. So, beyond expertise, make sure you have enough resources ready to devote to the endeavor.
- You’re working with a complex application that needs to scale. Microservices architecture really shines when working with highly complicated applications that demand superior scalability. You’ll be able to add new features with ease and accommodate a large user base without missing a beat.
Combining monolithic and microservices: A hybrid approach
While the debate between monolithic and microservices architectures often presents them as mutually exclusive, many organizations find that a hybrid approach can offer the best of both worlds. By blending elements of monolithic and microservices architectures, businesses can strategically leverage the simplicity and straightforward deployment of monoliths alongside the flexibility and scalability of microservices.
What is a hybrid approach?
A hybrid approach involves integrating microservices into a primarily monolithic application or maintaining some monolithic components while developing new features as microservices. This strategy allows teams to modernize at their own pace, without the need for a full-scale migration to microservices all at once. For instance, a core set of stable features might remain in the monolith, while newer, more dynamic components are developed as microservices to enhance agility and scalability.
What are the pros and cons of hybrid approaches?
This approach is particularly appealing for businesses looking to modernize their systems without the high upfront costs and risks of a complete overhaul. However, navigating a hybrid model isn’t without its challenges, and careful planning is essential to manage the increased complexity and integration demands.
Pros of a hybrid approach
- Hybrid models enable a gradual shift from monolithic to microservices architecture, reducing the immediate complexity and risks associated with a full migration. Teams can modernize specific application components step-by-step, prioritizing the most critical areas first.
- By retaining core monolithic elements, companies can avoid the extensive disruptions often associated with re-architecting an entire application. This ensures continuity and stability, especially for legacy systems that are deeply integrated with existing business processes.
- In a hybrid setup, microservices can be used to offload performance-critical or frequently updated components. This allows businesses to scale those particular services independently, without having to overhaul the entire application.
Cons of a hybrid approach
- Managing a hybrid architecture can introduce its own set of complexities. Teams must maintain the operational integrity of both monolithic and microservices components, requiring a careful balance of tools, skills, and processes.
- Ensuring seamless communication and data consistency between monolithic and microservices components can be challenging. Hybrid systems often require robust API management and integration strategies to handle the increased interactions between different architectural styles.
When to consider a hybrid approach
A hybrid approach can be particularly beneficial when dealing with large, complex legacy systems that cannot be easily decomposed into microservices. It’s also a good fit for organizations looking to explore the benefits of microservices without committing to a full transition immediately. By adopting a hybrid strategy, teams can take a more measured and risk-averse path to modernizing their application architecture.
Ultimately, the choice to adopt a hybrid approach should be guided by your specific application needs, team capabilities, and long-term goals. By carefully planning and implementing a hybrid architecture, businesses can leverage the strengths of both monolithic and microservices models to set their applications up for long-term success.
Choosing the right architecture for your application
The question of monolithic vs. microservices is being asked more and more every day, but don’t let the excitement of microservices fool you. While microservices have a number of use cases, you shouldn’t be so quick to dismiss monolithic applications–especially if you’re working with a small app or small team. From here, it’s up to you to choose the best option for your next development project.
Computer science is crucial to our lives today, and programming languages play a fundamental role. These languages act as a programmer’s toolbox. However, choosing a language can be challenging, especially when deciding between the two most popular options: Java and Python.
When comparing Java vs. Python speed, Python is easier to use and read, but being an interpreted language, it’s slower as it executes code line-by-line. Running on the JVM (Java Virtual Machine) as a compiled language, Java offers a faster runtime. The choice depends on the programmer’s goals. Programmers widely use Java and Python as general-purpose languages for desktop and web applications. Although the two have many similarities, they also have significant differences, which make one programming language ideal over the other.
Understanding the key differences between Python vs. Java can help you make an informed decision. Python is an interpreted language that executes code line by line, making it ideal for scripting and rapid development due to its clean and readable syntax. Java, a compiled language, converts code into bytecode and is run by the Java Virtual Machine (JVM). This ensures strong performance and cross-platform compatibility, making Java a preferred choice for large-scale enterprise applications.
Both of these object-oriented programming languages offer significant cross-platform support and extensive libraries. However, they excel in different applications. Recent trends show that Python is becoming more popular than Java, likely because of its great use for experimentation. However, Java is better for production code.
Java overview
Java remains one of the most popular programming languages in the world. First created in 1995 by James Gosling at Sun Microsystems, Oracle owns Java today. Over three billion devices run Java, using this programming language for everything from mobile apps to web apps and games to web servers.
When first created, the intention was for Java to be WORA — write once, run anywhere. It is a statically typed and compiled language.
Based on its history and plethora of available libraries, Java does offer a large community when in need of support. This ongoing support can make programming in Java reasonably straightforward. If a programmer is looking for code, Java’s libraries make it easy to find code previously written for a specific purpose.
Java continues to be a popular programming language based on its simplicity and ease of use. It is also open-source and free.
Most common use cases for Java
Java has many applications but is often used for web development. The most common applications for Java include:
- Desktop GUI apps
- Enterprise solutions
- Embedded systems
- Web applications
- Scientific applications
- Financial sector server applications
- Android applications
- Software tools
These use cases show how versatile and robust the Java programming language is. According to StackShare, nearly 10,000 corporations use Java in their tech stacks, including Google, Uber, Instagram, Netflix, and Airbnb. However, there are billions of active Java virtual machines globally. Real-world use cases are seen across many industries, including real estate, eCommerce, healthcare, retail, and more.
Python overview
First released in 1991, Python also has an impressive history. Developed by Guido van Rossum at the National Research Institute for Mathematics and Computer Science in the Netherlands, Python is considered a powerful programming language.
Python was designed to be highly readable to fulfill general purposes upon its creation. It is a dynamically typed and interpreted language.
Based on its vast libraries, Python allows programmers to get started quickly. For example, if a programmer is interested in machine learning, there’s a library for that. A minimal amount of code needs to be started from scratch, so this programming language is ideal for beginners. However, it’s also great for sharing code with others.
Most common use cases for Python
Python also has many use cases. Concerning use cases, Python is excellent for big data. There are many reasons for this, including:
- Available Python packages
- Machine learning algorithms
- Python’s active community
- Licensing structure
- Data visualization (e.g. Matplotib)
The most common applications for Python include:
- Machine learning
- Image processing
- Scientific and numeric computing
- Language development
- Learning applications
Python applications are now mainstream, with a presence across many different industries — and the applications are increasing each day. Many of the companies discussed above, that use Java, also use Python. These include Netflix, Google, Instagram, Spotify, Dropbox, and Quora.
Aside from web application development, data science, and AI, Python has a strong presence in the gaming industry. This programming language uses Python libraries like PyGame and PySoy to develop Battlefield 2 and other successful games.
Is Java faster than Python?
The speed of a programming language comes from the processing time it takes to read and execute the program. The speed of each depends on the implementation, but Java typically reads and executes much faster. Historically, Java was up to 25+ times faster, but that has since changed following the release of Python 3. Regardless, Java still runs significantly faster in almost every circumstance, so it remains the dominant choice for enterprise-level software development.
Compared to Java, Python sacrifices some performance to be a more flexible option known for its high-level programming features. Unlike Java, which must be compiled with each change, developers can make changes to Python on the fly as needed. This ability to adapt quickly makes Python the ideal choice for data analytics, where variables might frequently change.
In short, if you’re developing efficient code execution that is scalable to enterprise-level applications, Java is the clear choice. If you need to apply extensive scripts or require agility and flexibility in development, and execution speed is less of a factor, Python will likely suit your purposes much better.
Java vs. Python – Biggest differences in code
Unlike Python, Java is one of the two official programming languages used for Android. However, Python has gained popularity simply because people grasp it more easily.
Type of programming language
Both programming languages are high-level. Python is an interpreted programming language, which means it can convert human-readable code into machine-readable code. In comparison, Java is what’s known as a compiled programming language. Java code is initially compiled into a binary bytecode, which can then run on any platform or device with Java Virtual Machine (JVM). However, because JVM is a software-based interpreter, Java can be considered a compiled and interpreted language.
Programming paradigms
Both Java and Python support several programming paradigms. Both are object-oriented.
In addition:
- Python supports imperative, functional, and procedural programming paradigms.
- Java was initially developed as a concurrent, class-based programming language and is still heavy on classes.
Readability
Code readability is a major selling point for Python, as this programming language keeps code clean, concise, and readable. These benefits are one of the core reasons why many developers prefer Python. Developers can avoid writing additional code to keep applications maintainable.
As Java releases new versions, new language features are included to simplify the software development process. For example, Java 9 developers can structure software applications with modules. Java modules are for better package distributions and enhanced security.
Performance
The performance of a programming language is crucial. It determines how efficiently a program runs, handles concurrent tasks, and responds to user interactions, affecting user experience and system reliability. In programming, the choice of language impacts application performance, influencing everything from security to scalability.
Security
Malicious software and hackers are ever-present threats to web applications. Automated code injections, such as webworms, are particularly insidious, finding their way into any systems that unknowingly allow them access. These worms carry malicious code that injects commands or malicious scripts to modify stored SQL data. Active hackers often use specialized malicious programs to find their way into systems and gain access to source code.
Java has integrated security features that safeguard it from hackers and code injections much more effectively than Python. While Python doesn’t have Java’s built-in security, its agility and ease of use make it particularly desirable for web development. Users often develop or purchase external security to better protect Python-based applications.
Ecosystem and tooling
Python and Java both have an immense collection of libraries, frameworks, and developer tools available for users to take advantage of. Both can utilize REST and CRUD API frameworks, though they may each take a slightly different route to get there. Beyond API access, each language has specialized toolkits. Some expand a language’s capabilities, others simplify the development process.
Python’s effectiveness in machine learning and data analytics has led to the emergence of several commercial and open-source frameworks that leverage its agility and dynamic number-crunching abilities. Frameworks like FLASK and Streamlit empower developers to quickly build, scale, and share applications. Tools like Scrapy and libraries like Beautiful Soup enable Python applications to extract data from web pages while employing powerful tools like pandas or SQLAlchemy to manage and analyze the extracted information.
Java has long been a widely preferred web application development language, and a dedicated community has created numerous integrated developer environments to add greater simplicity and agility to Java programming. Visual Studio Code (VS Code) has been a staple for Java development for years, simplifying code writing and enabling developers to switch between multiple languages quickly. The open-source IDE NetBeans gives developers a more streamlined environment to build and roll out Java applications, with an array of onboard dynamic and static libraries to expand development capabilities.
Parallelism and hyperthreading
When comparing Python vs. Java in terms of parallelism and hyperthreading capabilities, most developers agree that Java has a distinct advantage. Java’s ability to run parallel processes and multitask has made it a solid choice for scalability and enterprise-level applications for decades. As a compiled language, compared to Python, which is an interpreted language, Java applications don’t have to contend with a global interpreter lock (GIL), which limits Python’s ability to hyperthread.
It’s clear that Python is a solid choice for producing agile serial functionality in an application. However, when your application needs the capacity to run concurrent cores and perform multiple simultaneous functions, Java has Python beat hands-down.
Mobile App Development
Unlike Python, Java is one of the official programming languages of the world’s most popular operating system. Many developers today count on Java to build apps and games for Android.
In comparison, developers lack any options to use Python to build native mobile apps for mobile platforms. It is still possible to develop Python-based apps using libraries like Kivy. However, to deliver an optimal user experience, a significant amount of time and effort is required to build Python-based apps.
Agile and DevOps
Enterprises continue to adopt agile development methodologies to rapidly deliver high-quality software applications. To do so, organizations often opt for DevOps to accelerate development, testing, and deployment processes.
Both Java and Python make this possible. The difference is that Java features a static type system, making it easier for programmers to simplify refactoring — while Python allows developers to automate refactoring via a dynamic type system. Python has an edge in that it enables programmers to experiment with ideas based on its simple and expressive syntax.
Learning curve – Which is easier to learn?
Beginners tend to favor Python over Java. Python’s syntax is relatively straightforward, making this language a more user-friendly option.
Java is more complex and challenging, showcasing a high entry point. It takes time to fully understand and utilize the capabilities of Java.
The overall consensus is that while Python is easier to learn, learning Java is far from impossible — it just takes longer. While some argue Java can lead to higher quality code, an experienced Python developer can also benefit from the same functionalities associated with Java. Outstanding developers benefit from learning both languages, especially since each language excels at different applications.
Key Python vs. Java comparisons
| Aspect | Python | Java |
| Syntax | • Created for readability and simplicity. • Blocks defined by indents. • Dynamic typing, which usually requires less code, but may lead to runtime errors. | • Verbose, typically requiring several lines of code for simple blocks. • Uses bracers to explicitly define blocks. • Statically typed, requiring more code at compile time. |
| Performance | • Interpreted code and dynamic typing, generally making it slower when running. • More suited for rapid development rather than application performance. | • Compiling to bytecode and JVM execution typically helps Java to run faster. • Ideal for application performance. |
| Scalability | • Scalable, but may experience global interpreter lock (GIL) performance bottlenecks. • Often requires integrated frameworks like Django or Flask for web scaling. | • Highly scalable, assisted by multithreading capabilities and concurrency support. • Enterprise-grade framework integrations support large applications. |
| Community Support | • Robust community, with many libraries and frameworks for a wide array of tasks. • Community forums offer frequent updates and conduct active discussions. | • Loyal, established community with extensive libraries and frameworks. • Strong enterprise support and numerous community resources. |
| Typical Use Cases | • Data science, machine learning, web development, and scripting. • Quick development times, prototyping, and rollouts. | • Enterprise applications, web applications, and Android mobile apps. • Suitable for large-scale systems such as financial services and processing large amounts of data. |
| Learning Curve | • Simple syntax makes Python an ideal language for beginners. | • Complex syntax and concepts give Java a much steeper learning curve. |
| Platform Dependency | • Works across multiple platforms, but different systems may have issues with certain libraries. | • JVM enables Java to run on just about any platform without having to modify the code to fit different platform requirements. |
Which language is used more?
For many years, Java reigned supreme in the world of web application development. However, Python slid past Java on all the charts. Today, more developers create in Python than Java by a respectable margin.
Statistics vary by source, but most show Python with a respectable lead, as reported by Stackoverflow, Statista, and GitHub.
According to the Tiobe Index, Python overtook Java for the first time in 2021, and the gap has only widened since. The dramatic rise in Python’s use can be credited to its becoming the preferred language for teaching and the popularity of Python frameworks, such as TensorFlow, for machine learning. Python now boasts considerably more users, and its ease of use continues to propel it upwards in the charts.
Java’s rigorous syntax rules may also contribute to it falling behind Python, but it remains highly popular for enterprise application development due to its security and scalability. Many loyal Java developers argue that Java’s greater stability gives it an edge, unlike Python, which tests syntax during the runtime. In Java, developers must test and review all of the code before running. This testing process means the code must be very well-written, which has the benefit of reducing the likelihood of application crashes.
Which language should you use first?
For beginners, the question remains — which programming language should be used first?
Python is the clear choice for most new programmers. Offering a straightforward syntax, Python is a good starting point, especially among those most interested in deep learning, machine learning, and the AI field as a whole. For data analysis and visualization, Python offers advantages.
With that in mind, some prefer to start with Java, as it’s often challenging to transition to languages like Java after focusing primarily on Python. In contrast, taking the leap from Java to Python is rather comfortable. Java has a vast range of libraries and frameworks to lean on during the initial learning process.
The best language to learn for each programmer will depend on the individual. For those interested in programming, Python is an excellent choice. A programmer can see how far they can go with Python before branching out. For those who plan to pursue a career in computer science, it may be best to jump right in and learn Java first.
Why?
Because Java will help a programmer understand the inner workings of programming. Leaping from Java to Python after will allow programmers to see how this programming language makes things easier, yet they will still hold that core knowledge and skill. Learning Java is also the preferred option when the goal is to make mobile apps. Once a programmer learns Java for Android, they can easily switch to Swift to move into iOS as well. So, while Java requires more initial time and effort to learn, the ongoing benefits of learning this programming language are significant.
When Java and Python are used together
Both Python and Java are well-suited for many people. After all, they both have large communities behind them.
Since Python is simpler to understand and implement in most cases today, most programmers lean towards this programming language. Those interested in learning multiple languages will often migrate to Java afterward—but in this case, it is advantageous to learn Java first.
When a programmer utilizes both Java and Python within a single application, they can effectively combine these two languages to accomplish a greater objective. After all, both Java and Python are object-oriented programming languages.
For example, one could be used for typical subtasks, while you can use the other for expanding the customization of an application you’re developing.
Another example would be using a Python-Java interpreter like Jython, which translates Python source code directly into Java bytecode. The advantage here is speed.
Other tools include:
- JPype: Allows Python to run Java commands.
- Jepp: Java embedded Python.
- JCC: A C++ code generator for calling Java from Python/C++.
So, when it comes to Java vs. Python, it’s clear why these two programming languages are so popular. While Python is easier to learn and use, Java is generally more efficient and optimal for debugging. When a programmer’s top priority is development speed, Python is ideal,due to its ease of use and flexibility, especially at a smaller scale. If the goal is to create a large-scale, stable application that executes more quickly, Java is the better choice.
Learn how LogicMonitor’s DevOps and Monitoring solutions can help fit Java and Python into your DevOps strategy. Discover ways to streamline development and operations to enhance efficiency and application performance.pment speed, Python is ideal, but if the top priority is stability over all else, Java is the better choice.
Observability tools, like OpenTelemetry and Prometheus, are critical for ensuring optimal performance and reliability in cloud-native applications. While OpenTelemetry provides comprehensive telemetry data collection, supporting traces, logs, and metrics for whole-system observability, Prometheus excels in monitoring and analyzing time-series data.
While you can use Prometheus and OpenTelemetry together, they have distinctly different capabilities that set each apart. Prometheus is ideal for dynamic systems and focused monitoring of individual components, and OpenTelementry offers a unified view across distributed systems. Both OpenTelemetry and Prometheus provide options for data collection but are significantly different from one another.
This comprehensive overview of OpenTelemetry and Prometheus covers key features and capabilities, as well as advantages and disadvantages, of both tools.
What is OpenTelemetry (OTel)?
For cloud-native applications, OpenTelemetry is the future of instrumentation. It’s the first critical step that allows companies to monitor and improve application performance. OpenTelemetry also supports multiple programming languages and technologies.
Key features and capabilities
In addition to collecting telemetry data across applications, OpenTelemetry provides services and supporting infrastructures for those applications. It is a vendor-neutral telemetry standard used throughout the industry. OTel combines cloud technologies, orchestration engines, and containers to facilitate faster digital innovation.
Of course, OpenTelemetry also provides enterprises with flexibility by allowing them to standardize the way they collect data with less vendor lock-in and greater interoperability. The best way for companies to move forward is by understanding their customers’ needs and how they interact with their online experiences.
Supported programming languages and technologies
OpenTelemetry’s vendor-neutral open-source tools, APIs, and SDKs support multiple programming languages, including Go, Java, and Python. These tools work together to execute the measurement by specifying what needs to be measured, collecting relevant data, cleaning and organizing information, and exporting data to a monitoring backend.
What is Prometheus?
Prometheus is a metrics monitoring tool used for monitoring time-series data that changes over time. Initially developed at SoundCloud in 2012, the CloudNative Computing Foundation accepted Prometheus in 2016 as the second project slated to graduate from the foundation after the open-source system Kubernetes.
Key features and capabilities
Prometheus prioritizes reliability over accuracy, making it an ideal solution for cloud-based dynamic systems, such as microservices. The system also works with billing applications that require accuracy and may provide the best solution for relative monitoring applications and infrastructures.
Historical background and community support
SoundCloud originally developed Prometheus as a toolkit for alerting and monitoring systems. It’s a free, open-source software application, so it’s easy to integrate natively. Since its launch, many organizations and companies have adopted Prometheus, and the project has an active user and developer community.
Performance and scalability
OTel is becoming the industry standard in telemetry data generation. Distributed systems rely heavily on observability to gauge their health, and telemetry data makes observability possible. Using OpenTelemetry, companies can generate telemetry data without depending on multiple vendors.
OpenTelemetry allows companies to collect telemetry data regardless of the provider. Distributed systems rely heavily on telemetry data for monitoring their states. Therefore, a global standard is required for microservices and polyglot architectures. As of now, OTel is well positioned to fill this void.
Furthermore, OpenTelemetry’s components are loosely coupled to provide integration options. The main OpenTelemetry components are:
- Application programming interfaces (APIs): Instrument code and coordinate data collection across entire systems.
- Data specifications: The data specifications define the OpenTelemetry Protocol (OTLP) and relevant semantic conventions used by applications.
- Software development kits (SDKs): Using libraries, SDKs implement and support APIs for data gathering, processing, and exporting. The SDKs are also language-specific, similar to APIs.
- OpenTelemetry Collector: Can be used across a wide range of systems, whether open-source or commercial.
In short, OpenTelemetry APIs, SDKs, libraries, and integrations can collect and manage telemetry data (traces, metrics, and logs). The OpenTelemetry project was created through a merger between OpenCensus and OpenTracing. The Cloud Native Computing Foundation (CNCF) also incubated Kubernetes.
How is Prometheus built?
Prometheus stores data locally on disk so that it can be accessed and queried quickly. It also allows metrics to be stored remotely. Prometheus servers are stand-alone and do not rely on remote services or network storage.
How does Prometheus monitoring work?
In Prometheus, data is collected as a time series generated by an underlying pull model. At specific intervals of time, Prometheus queries a list of data sources or exporters. For reference and querying, Prometheus data is stored in metrics.
Prometheus stores data locally on disk so it can be accessed and queried quickly. It also allows metrics to be stored remotely. In addition, the Prometheus servers are stand-alone and do not rely on remote services or network storage.
As a multidimensional data model, Prometheus supports PromQL*, a language that allows companies to query the metrics data collected. Not only can companies pull model data collection over HTTP with Prometheus, but it also supports a basic visualization layer and offers an alert manager to handle alerts.
What is PromQL?
Prometheus Query Language, or PromQL, is the query language provided by Prometheus for selecting and aggregating data. It is precisely adjusted to work in convention with a time-series database and offers time-related query functionalities.
What are the features of Prometheus?
Prometheus’s main features are:
- Autonomous, dedicated server nodes that do not rely on distributed storage
- A data model that identifies time series data by metric name and key/value pairs
- Integrated dashboards that support internal graphic displays
- Choice of static configuration or service discovery for the discovery of targets
- Use of a pull model over an HTTP connection for time series collection
- Time series pushed through an intermediary gateway
- Flexible querying with PromQL to leverage dimensionality
How does OTel work?
OpenTelemetry works with three major forms of telemetry data: tracing, metrics, and logging. OTel can help track requests within a system to identify performance issues and failures. In terms of metrics, the system tracks and reports on processes through histograms, gauges, and other graphical reports that are easy to understand. Finally, the last way to analyze logging messages is to analyze those specific to a given application.
Tracing, metrics, and logging have always been crucial to observing a system across its entire lifecycle. However, the complexity of modern applications and resource layers makes it difficult to implement tracing across all services. For example, a single incident can be tracked for hours when paired with vague log data because the information needs to be siloed consistently.
OpenTelemetry (and other similar products) seeks to correct this problem through its consolidated system for metrics, tracing, and logging. GitHub provides a platform for those interested in participating in a community to influence and improve OpenTelemetry as an open-source project. Analyzing telemetry data can help create a multi-layered ecosystem. As a result, your company may be able to address performance issues more efficiently.
What are the features of OTel?
OpenTelemetry’s main features include the following:
- Support for telemetry data in consistent formats across all major programming
- Exports telemetry data in multiple formats to a backend of choice
- Allows logging, monitoring of metrics, and telemetry data tracing
- Supports multi-language and technology-agnostic instrumentation
Key differences between OpenTelemetry vs. Prometheus
Data collection and metrics
- OpenTelemetry: Provides unified data collection, handling metrics, traces, and logs.
- Prometheus: Focused primarily on metrics and time-series data.
Flexibility and integration
- OpenTelemetry: Vendor-neutral with high flexibility and broad ecosystem integration.
- Prometheus: Integrates well with other CNCF projects but is metrics-centric.
Visualization and storage
- OpenTelemetry: Lacks a built-in visualization layer and relies on external tools.
- Prometheus: Includes basic visualization capabilities with built-in storage.

OpenTelemetry advantages
- Better performance: Manages and generates telemetry efficiently.
- Collector: Allows companies to receive, process, and export telemetry data in various formats.
- Easy to use: Business-friendly, with documentation for troubleshooting and repairing bugs.
- Language support: Supports C++, Go, Java, Javascript, Python, and more.
- Libraries: Offers auto-instrument frameworks and libraries to reduce codebase change requirements.
- Observability: Integration points allow collected data to be ingested by observability platforms.
- Partners and backers: Includes Google, Microsoft, and other prominent cloud vendors.
- Flexibility: Vendor-neutral, which allows companies to switch tools.
OpenTelemetry disadvantages
- Lack of storage: Does not provide a visualization layer or backend storage.
- Poor support: Room for improvement with support and documentation.
Prometheus advantages
- Pull-built: Actively scrapes targets to retrieve metrics; server initiates HTTP call to fetch system/app metrics from endpoints to exporter.
- Control: Pull-based system enables rate control for flexibility in multiple scrap configurations; multiple rates for different targets allow better server control.
Prometheus disadvantages
- Limited use cases: Great tool for metrics monitoring but doesn’t go further than that.
- Full-stack: Not a full-stack application monitoring tool.
- Logs: Only tracks metrics, so users need to rely on other tools for logging.
- Static: Designed for a single machine; lacks flexibility and cannot scale horizontally.
- Time: Requires effort and time to effectively set up exporters for valuable visualization.
- Traces: Does not support traces or root cause analysis.
Best practices for integration with existing systems
Integrating OpenTelemetry
By following these practices, you can help ensure a smooth and effective OTel integration.
- Compatibility: Ensure that OpenTelemetry can work with your existing monitoring tools and backends.
- Collaboration: Work closely with development and operations teams to ensure agreement on observability goals.
- Gradual adoption: Start by instrumenting critical paths in your application, gradually expanding coverage as you need it.
- Custom instrumentation: Use manual instrumentation where automatic options aren’t feasible.
- Version management: Keep OpenTelemetry libraries updated to benefit from the most current improvements.
Integrating Prometheus
By following these practices, you can effectively integrate Prometheus into your existing systems.
- Start with core services: Ensure high availability and performance by monitoring the most critical services.
- Use exporters: Take advantage of official and community exporters to monitor various systems such as databases, caches, and hardware.
- Adjust scrape intervals: Dial in scrape intervals based on the criticality and nature of the data to balance performance and resource usage.
- Alerting: Configure alerting thresholds in Prometheus to receive notifications before any issues can impact users.
- Data retention: Manage data retention policies to balance storage costs with the need for historical data.
- Utilize service discovery: Use service discovery to dynamically manage targets as your infrastructure scales or changes.
- Documentation: Document your Prometheus configuration thoroughly, including tracked metrics, alerting rules, and dashboard setup.
- Security: Employ authentication access and network restrictions to secure Prometheus instances, preventing unauthorized access to sensitive metrics.
Setting up OpenTelemetry
This step-by-step guide provides an example of OpenTelemetry setup using Go.
- Check Go installation: Make sure Go is installed on your system. You can confirm this by running ‘go version‘ in your terminal.
- Set up a Go project: Navigate to your project directory or create a new one using ‘go mod init <module_name>‘ to initialize a Go module to manage dependencies.
- Install dependencies: Run ‘go get go.opentelemetry.io/otel‘ to install OpenTelemetry packages.
- Set up tracer: Initialize a tracer provider and configure it to export traces.
- Instrument code: Use the tracer to create spans around the code you want to monitor.
- Run your application: Execute your Go application; the telemetry data will be collected and exported.
- Analyze Data: Review the exported data using your chosen backend.
For more details on setting up OTel, visit the OpenTelemetry Go guide.
Setting up Prometheus
Getting started with Prometheus is fairly simple and straightforward. These steps will help you get your Prometheus setup underway.
- Download Prometheus: Get the latest version from the Prometheus website.
- Extract and configure: Unzip the file, navigate to the folder, and edit prometheus.yml to define scrape targets.
- Run Prometheus: Start Prometheus with ‘./prometheus –config.file=prometheus.yml‘.
- Access Web UI: Open http://localhost:9090 in your browser to access the Prometheus dashboard.
- Start monitoring: Use the UI to query and monitor your systems.
The Prometheus getting started guide offers more in-depth details for setting up Prometheus.
Why is OpenTelemetry important?
To collect and transmit telemetry data to backend platforms, OpenTelemetry is essential. The common instrumentation format overcomes visibility gaps across all services. In addition, engineers can install a new proprietary agent whenever a backend platform is changed.
OpenTelemetry also handles new technologies, unlike commercial solutions, which must be integrated to make products work together. Aside from simplifying alerting, troubleshooting, and debugging, OTel data is helpful for monitoring, too.
Collecting and analyzing telemetry data has always been used to understand system behavior. However, recent network complexity has made this more challenging. Tracing the cause of an individual incident in these labyrinthine systems can take hours or days.
OpenTelemetry can help correlate traces, logs, and metrics from across applications and services, improving observability. The open-source project also enables APM (application performance monitoring) and other vital functions by removing roadblocks to instrumentation. Ultimately, this results in better service reliability, reduced downtime, and efficiency in identifying and resolving incidents.
OpenTelemetry use cases
Distributed tracing
Organizations widely use OpenTelemetry to trace requests across complex microservice architectures. This helps developers identify performance bottlenecks and track the flow of requests. Shopify uses OTel for tracing in its distributed systems.
Monitoring cloud-native applications
OpenTelemetry provides unified observability across cloud-native environments, enabling effective monitoring of applications running on many kinds of modern infrastructures. Google integrates OpenTelemetry into its cloud-native services to give customers superior cloud monitoring capabilities.
Enhancing observability with metrics and logs
By collecting and correlating metrics, traces, and logs, OpenTelemetry gives teams a comprehensive view of their systems and provides root cause analysis. Microsoft employs OpenTelemetry in Azure services to standardize observability across its cloud platform.
Why is Prometheus important?
Prometheus is popular due to its powerful features for monitoring metrics, providing alerts, and automating responses to changing conditions with orchestration systems. In addition to collecting metrics—or concise descriptions of events, such as dates, times, and descriptive values—about applications and infrastructure, Prometheus can monitor performance. The Prometheus software gathers only a little bit of data about many things rather than collecting a lot of data about one thing.
Prometheus use cases
Infrastructure monitoring
Users rely on Prometheus to monitor servers, containers, and networking equipment and offer real-time data on system health and performance. Reddit relies on Prometheus to monitor its large-scale infrastructure, monitor the environment, and quickly identify issues.
Application performance monitoring (APM)
Prometheus collects metrics from applications to track performance and ensure reliable operation across connected environments. GitLab employs Prometheus to monitor their CI/CD pipeline performance and monitor application services to help maintain high availability and optimize application performance.
Alerting
Prometheus can integrate with alerting tools like Alertmanager to notify teams of issues based on custom thresholds, ensuring rapid response to incidents. SoundCloud, the pioneer of Prometheus, takes advantage of its alert functions to quickly notify them of issues in its streaming service infrastructure.
What the future holds
The future of OpenTelemetry
OpenTelemetry expects to focus on enhancing its capabilities across the board, particularly focusing on improving support for logs, metrics, and traces. OTel will likely emphasize better integration with various backends and increased automation capabilities. Users can expect advancements in community collaboration, a broader toolset for simplifying implementation, and OpenTelemetry’s use in complex cloud ecosystems. OTel also expects to provide enhanced observability in mobile environments and bring deeper integration with mobile platforms.
The future of Prometheus
Prometheus has prepared a roadmap that outlines developer ambitions for the platform. Plans include improving scalability and enhanced availability features, as well as smoother integration with other cloud-native systems. Prometheus will likely continue developing long-term storage solutions, strive for better support for service discovery, and seek to boost query performance. The Prometheus community is also focused on refining the user experience, including the development of more robust visualization and alerting functions.
Conclusion
Organizations with higher levels of observability have a much easier time tracking down and resolving issues, resulting in more reliable operations and fewer downtimes. Tools like OpenTelemetry and Prometheus can aid organizations in meeting observability goals in different ways. While Prometheus supports rich queries, metrics, and interoperability as part of the cloud-native ecosystem, OpenTelemetry collects metrics, traces, metadata, and logs and scales with organizational growth.
Unlock comprehensive observability for your cloud-native environments and seamlessly integrate LogicMonitor with OpenTelemetry and Prometheus. Learn more today.
CRUD and REST are two of the most popular concepts in the Application Program Interface (API) industry:
CRUD stands for Create, Read, Update, and Delete, focusing on managing data.
REST, or Representational State Transfer, is a way to design web services that focuses on how clients and servers interact and communicate.
As both work on manipulating databases’ data, it’s easy to see why people are confused about them. This blog will discuss what REST and CRUD are, the basic principles that govern them, and their similarities and differences.
What Is REST?
REST is an abbreviation for Representational State Transfer. It is a software architectural style that provides standards for computers on the web, dictating how the systems interact. Roy Fielding, the founder of the REST protocol, defines it as “an abstraction of the architectural elements within a distributed hypermedia system.”
The origins of REST
Before the launch of the REST protocol in 2000, web developers had no standard of how to develop a web API or even use one. Many protocols were used at that time, but they proved too tedious and complicated to carry out. Together with his colleagues, Roy Fielding sought to address this problem and developed what is known today as the REST protocol. The development of REST allowed two servers to exchange data worldwide.
REST-compliant systems are called RESTful systems. These systems are characterized by their statelessness and the separation of client and server concerns. Since its launch in 2000, many companies such as eBay and Amazon have used the REST protocol.
The 5 core principles of REST
REST operates with five basic principles.
1. Independent client-server interaction
The REST protocol allows for independent implementation for the client and the server. This independence means that both parties can make changes without knowing or interacting with one another. Defining what a server and client are is the first step to understanding this principle.
- Server: Simply put, servers are machines that provide services to other devices. There are different types of servers, such as boot servers, database servers, print servers, and specialized servers for specific applications. Various applications rely on other applications to deliver a service. For example, a search engine will direct information to its web server. In contrast, a printer on a network will funnel information to the printer server to generate a result.
- Client: A client is a remote system that uses services from a server. All the machines connected to a server are called clients. Because some clients have limited disk capacity, they rely on remote file systems to function. Some devices can both be a client and a server at the same time.
The REST protocol allows the two systems to work independently without affecting the result. As long as the client and the server know what format to use when sending messages, different clients eventually reach the same REST endpoints. The client and server interface separation also allows both systems to evolve independently.
2. Stateless communication in REST APIs
RESTful APIs do not cache anything about the HTTP request made on the client side. Not caching means the server treats every session as new and cannot take advantage of any previous information stored on the server. To be genuinely stateless, a server does not store any authentication details of any prior session by the same client. Because a REST API is stateless, a client must provide all the necessary information every session to enable a server to complete a task.
3. Enhancing efficiency with caching
Requests on a server go through different pathways or caches. These caches can either be a local cache, proxy cache, or reverse proxy, and a RESTful API’s server can mark information as either cacheable or non-cacheable. When a client requests their end, this request goes through a series of caches. If any caches along that path have a fresh copy of the representation, it uses that cache to generate a result. When none of the caches can fulfill the request, it returns to the origin server. A RESTful API’s servers determine whether the information is cacheable or non-cacheable.
Caching has several benefits, some of which are:
- Reduces bandwidth
- Decrease latency by decreasing the number of trips to and from the server to fetch data from memory
- Reduces server load
- Decreases network failures
4. Predictable interactions via a uniform interface
A system that utilizes the REST API has the client and the server interacting predictably. A resource in the system follows only one logical Uniform Resource Identifier (URI). What differentiates RESTful APIs from non-REST APIs is the uniformity of this interface regardless of the device or application used. Resources on a REST API use Hypermedia as the Engine of Application State (HATEOAS) to fetch related information whenever applicable. All resources on RESTful APIs follow specific guidelines with naming conventions and link formats. A uniform interface follows four guiding principles:
- Resource-based: Each resource uses URI as a resource identifier.
- Actions on Resources Through Representations: A resource associated with metadata contains information on the server that you can modify or delete.
- Self-descriptive Messages: Each message has all the information to describe how it is processed.
- Hypermedia as the Engine of Application State (HATEOAS): Clients provide states by body content, request headers, and URI, and the service provides customers with the state by response codes, response headers, and body content. This is called Hypermedia.
5. Leveraged layered architecture for scalability
A RESTful API relies on a layered system to deliver results. This approach allows developers to modularize their systems. For example, see how you can write a custom Terraform provider with OpenAPI to streamline API management. This layered system provides a hierarchy that constrains a layer from seeing beyond its assigned layer and allows the developer to deploy various functions to different servers. Each layer works independently, and each layer does not know the functionality of other layers besides its own. On the user end, a layered system does not allow users to ordinarily differentiate whether they are connected to a primary or intermediary server. The importance of intermediary servers is their ability to provide load-balancing cache sharing.
“Mastering both CRUD and REST is essential for building scalable and efficient web services.”
What is CRUD?: Data management basics
CRUD is an acronym for CREATE, READ, UPDATE, and DELETE. These four database commands are the foundation of CRUD. This acronym is well-known among programmers, but many software developers view it as more of guidance since CRUD was not made as a modern way to create API. After all, its origins are in the database. By its definition, it’s more of a cycle than an architectural system.
Many programming protocols and languages have their own CRUD version with different names and a slight change in what they do. A good example is SQL (structured query language), which uses Insert, Select, Update, and Delete. Also, there are CRUD cycles in a dynamic website, such as a buyer on any eCommerce site (Amazon, Mango, etc.). Users can create an account, update information and delete things from their shopping cart. Other programming languages that use the CRUD frameworks are Java (JOOQ, iBAtis), Phyton (Django), PHP (Propel, Doctrine), and .NET (NHibernate, LLBLGEN Pro), to name a few.
A short history of CRUD
The CRUD acronym was thought to have been created in the 1980s to describe database functionality used by structured query language (SQL). The term first became known in the 1983 book Managing the Data-base Environment by James Martin. The first reference to CRUD operations was in a 1990 article, “From Semantic to Object-Oriented Data Modeling” by Haim Kilov.
The CRUD cycle was designed as a set of functions to enhance persistent storage with a database, which often outlives the processes that started it. In modern software programming and development, CRUD has exceeded its start as a function and lent itself to design principles for applications like SQL, DDS, and HTTP protocol.
The four fundamental operations of CRUD
As discussed above, the four fundamental operations of the CRUD cycle are: CREATE, READ, UPDATE and DELETE.
- CREATE: Adds one or more entries and is the equivalent of the Insert function in SQL.
- READ: Retrieves data based on different criteria and is equivalent to the Select function in SQL.
- UPDATE: Change procedures and modify records without overwriting.
- DELETE: Removes one or more specified entries.
L and S: Additions to CRUD
Sometimes, CRUD is expanded to include LISTING (CRUDL). Listing helps prevent more extensive data from being stored in easy memory storage without going to pagination.
Some programmers add an S to CRUD (SCRUD) for SEARCH. Data retrieval is only used for updates and deletions, while software application users sometimes need to search a database for data to see a list of search results
Security considerations for REST and CRUD
APIs enable applications to connect and communicate across networks and the Internet. Since REST and CRUD systems are APIs, these practices can leave cracks if the application isn’t secured effectively. Implementing these practices helps to close gaps and tighten security for your applications, whichever API method you choose.
Authentication and authorization
Implement authentication requirements to ensure only authorized users can access data. The 0Auth2 framework works well for applications and services utilizing REST principles, while role-based access controls work best for CRUD interactions.
Data validation
Implement protocols to ensure all data inputs meet specific criteria, such as file type and format, and that the system removes any potentially harmful data before processing.
Encryption
Use secure HTTP (https) when transferring data and encrypt stored data to ensure it’s not accessible or viewable by unauthorized users.
Rate limiting
Limit the number of requests available for each client to prevent the API from overloading and ensure no client utilizes its share of resources. By gatekeeping API requests, rate limiting also helps guard the server from denial of service (DoS) attacks.
Implementation examples for REST and CRUD
To solidify your understanding, let’s look at how CRUD operations and RESTful services are implemented:
CRUD example using SQL
-- Insert a new user into the 'users' table
INSERT INTO users (name, email) VALUES ('John Doe', '[email protected]');
-- Select a user from the 'users' table where the ID is 1
SELECT * FROM users WHERE id = 1;
-- Update the email of the user where the ID is 1
UPDATE users SET email = '[email protected]' WHERE id = 1;
-- Delete a user from the 'users' table where the name is 'John Doe' and the email is '[email protected]'
DELETE FROM users WHERE name = 'John Doe' AND email = '[email protected]';Using the example graphic above, the CRUD steps outlined in the graphic perform the following functions using SQL.
- Create: In this step, the command inserts a new record into the users table of the database named John Doe with an email address of [email protected].
- Read: This command retrieves the record for viewing from the users table with the value of 1 in the id column of the SQL table.
- Update: This line overwrites the information in the ’email’ column of the record with an ‘id’ value of 1 with the email address [email protected].
- Delete: This command deletes an erroneous record from the database in which the name was entered as ‘John Doo’ with the same email address.
REST example using HTTP methods
# Create a new user (POST request)
POST /users
{
"name": "John Doe",
"email": "[email protected]"
}
# Retrieve user information by ID (GET request)
GET /users/1
# Update user information (PUT request)
PUT /users/1
{
"email": "[email protected]"
}
# Delete a user by ID (DELETE request)
DELETE /users/1In the example graphic above, these REST commands perform the following tasks:
- POST: The POST /users request creates a user incident with the name value “John Doe” and the email value “[email protected].”
- PUT: The PUT /users/1 request updates the email value in the incident with the ID of 1 to “[email protected].” This example assumes the John Doe record has the ID of 1.
Practical use cases for REST and CRUD
While engineers often use the two systems together in a REST-CRUD combination, each has its own strengths for practical use when building applications and services.
REST is meant for interactions between clients and stateless servers. This concept works well for public APIs such as social media applications, streaming services, and online banking. REST is also ideal for developing interoperable systems like microservices and Internet of Things (IoT) applications.
CRUD is suitable for basic data-management applications, such as simple CMS editors, interactive calendars, and event management applications. It’s also ideal for building applications and tools that require direct data manipulation, including internal applications such as admin dashboards and inventory management systems.
“CRUD focuses on data operations, while REST defines how web services communicate.”
What are the similarities between CRUD vs. REST?
Some purists may argue that REST and CRUD are in no way related. However, a closer look at their commands reveals similarities.
REST Commands
- POST: This creates a new record in the database.
- GET: This request reads information sourced from a database.
- PUT/PATCH: This updates an object.
- DELETE: This removes a record from the database.
CRUD Commands
- CREATE: This creates a new record through INSERT statements. In REST, this is a POST command.
- READ/RETRIEVE: These procedures grab data based on input parameters. In REST, this is equivalent to a GET command.
- UPDATE: This updates data without overwriting it. In REST, this is a PUT request.
- DELETE: This removes data from the database. REST uses the same request to delete data.
What are the differences between CRUD vs. REST?
Because of their similarities, it’s easy to mistake REST and CRUD for having the same function. But that’s far from the truth. Diving a little bit deeper explores their differences.
- REST is an architectural system centered around resources and Hypermedia using HTTP commands. CRUD is a cycle meant to maintain records in a database setting. In its base form, CRUD is a way of manipulating information and describing an application’s function. REST is a way of controlling data through HTTP commands. It is a way of creating, modifying, and deleting information for the user.
- CRUD functions can exist in a REST API, but REST APIs are not limited to CRUD functions. CRUD can operate within a REST architecture, but REST APIs can exist independently of CRUD. For example, a REST API can allow clients to reboot a server even if it doesn’t correspond to any CRUD functions. REST can do this as long as it uses the proper HTTP methods.
- REST usually refers to using data through HTTP commands. It’s a dogma that facilitates how users manipulate data onscreen and save the information on the server. Programmers can create a REST API that can handle the essential CRUD functions, but the same can’t be said the other way around.
- The functions of REST and CRUD are similar (as discussed above), but they are not the same. PUT replaces a resource, even one that doesn’t exist yet. POST adds a new resource. Both of these commands create a new resource, but PUT is usually used to update resources that are already there. PATCH is mainly used to update a part of a resource, but PUT is used only to update an entire resource by replacing it.
REST and CRUD work together, but they are not the same
REST and CRUD work together because CRUD can exist within a REST environment, and their functions often correspond to each other, but they are not the same. The best way to differentiate between them is to remember that REST is a standard (an API architecture), and CRUD is a function. Understanding this essential but straightforward difference is necessary for understanding both.
Explore LogicMonitor’s application performance monitoring (APM) platform and find out how you can get the most out of your REST and CRUD APIs.