PostgreSQL and MySQL are two of the most popular open-source databases available today. They both provide the database backend for many web applications, enterprise software packages, and data science projects. The two databases share some similarities in that they both adhere to the SQL standard.
However, some key differences might influence your decision to choose one over the other. PostgreSQL is known for its advanced features, impressive durability, and scalability. MySQL is well-known for its ease of use and speed in read/write operations.
Here’s an overview of their similarities and differences, including their architectures, data types, indexing schemes, security, and performance.
PostgreSQL and MySQL similarities
Both PostgreSQL (also known as “Postgres”) and MySQL are Relational Database Management Systems (RDBMS). That means both store data in rows and tables, have a mechanism to define the relationships between the data in the tables and provide the Structured Query Language (SQL) to access the data via standardized queries.
Both database systems are ACID-compliant. ACID (atomicity, consistency, isolation, durability) compliance ensures data consistency and integrity, even in the face of system errors, hardware failures, and power outages. Both support replication for adding more servers to host data with fault tolerance and a distributed workload.
MySQL and PostgreSQL are both free and open source, meaning that anyone can obtain the source code, install the software, and modify it how they see fit. Both offer tight integration with web servers like Apache and programming languages like PHP and Python.
Architectural differences and data types
While both MySQL and PostgreSQL are examples of an RDBMS, PostgreSQL also qualifies as an Object-Relational Database Management System or ORDBMS. This means that Postgres has the typical characteristics of a relational database, and it’s also capable of storing data as objects.
At a high level, objects in software development are models with attributes and properties that can be accessed with forms of code known as procedures and methods.
To see the difference, look at the supported data types in both systems. MySQL supports a set of standard data types, including VARCHAR (text fields limited to a certain length), TEXT (free-form text), INTEGER (an integer number), BOOLEAN (a true/false field), and DATE (a timestamp). Meanwhile, PostgreSQL supports the standard data types and a wide range of more complex data types not seen in a traditional RDBMS. This includes MONEY (a currency amount), INET (IP addresses), MACADDR (a network device’s MAC address), and many other specialized objects.
Perhaps most importantly, Postgres supports the JSON and JSONB data types, which are JSON text and binary JSON data. As most REST web service APIs today transfer data in JSON format, PostgreSQL is a favorite among app developers and system administrators. While MySQL can be made to store JSON text, the ability to natively query stored JSON data is a major advantage of PostgreSQL.
MySQL and PostgreSQL query languages
PostgreSQL supports creating custom data models with its PL/pgSQL query language, which is substantially more full-featured than MySQL’s standard SQL implementation.
PL/pgSQL can be seen as both a query language and a procedural programming language. PL/pgSQL supports programming constructs like loops, conditional statements, variables, and error handling. The language also makes it easy to implement user-defined functions and stored procedures in queries and scripts.
MySQL’s SQL implementation lacks these features and is best suited for simple queries, data sorting, and exporting.
Even though PL/pgSQL is unique to PostgreSQL, it actually has a stricter adherence to SQL standards than MySQL’s SQL implementation. Advanced SQL features like window functions and common table expressions (CTEs) are available in PostgreSQL but not MySQL.
Database ecosystem and tools
Both PostgreSQL and MySQL boast robust ecosystems supported by various tools and integrations that enhance their functionality and streamline database management.
PostgreSQL’s ecosystem is enriched by an extensive range of open-source and commercial tools designed for automation, scaling, sharding, and migration. Tools like pgAdmin and DBeaver provide intuitive interfaces for database management, while PgBouncer and Patroni simplify connection pooling and high-availability setups. For scaling, Citus offers advanced sharding capabilities, enabling horizontal scaling for large datasets and high traffic. Migration tools like pg_upgrade ensure seamless upgrades between PostgreSQL versions, while Ora2Pg facilitates migration from Oracle databases.
MySQL’s ecosystem is equally expansive, with tools catering to various database management needs. MySQL Workbench provides a comprehensive graphical interface for database design, administration, and performance tuning. For scaling, MySQL supports sharding through ProxySQL and Vitess, which allow for horizontal scaling and improved database performance. Percona Toolkit and AWS Database Migration Service (DMS) streamline migrations, making it easier for enterprises to transition to or from MySQL.
Both ecosystems support automation tools like Ansible and Terraform for infrastructure management, ensuring smoother deployment and scaling of database instances. Whether you choose PostgreSQL or MySQL, the ecosystems offer many tools to optimize database performance and simplify complex operations.
Indexing Methods
Indexes are crucial for database performance, speeding up data retrieval and optimizing queries. PostgreSQL and MySQL offer various indexing methods to suit different use cases:
- B-Tree Indexing: The default method in both databases, ideal for efficient data retrieval in large datasets.
- GiN & GiST Indexing: PostgreSQL-specific, designed for complex data types like arrays, JSON, and full-text search.
- R-Tree Indexing: Suitable for spatial data (points, lines, polygons), enabling faster geospatial queries.
- Hash Indexing: MySQL-specific, uses hash tables for efficient equality-based lookups but not range queries.
- Full-Text Indexing: Supports advanced text searches with keywords and phrases in both databases.
Choosing the right index type boosts query performance and ensures your database meets application demands.
PostgreSQL vs MySQL performance and scalability
Both PostgreSQL and MySQL are capable of scaling to handle large amounts of data and high levels of traffic and to support complex applications. However, scaling MySQL typically involves adding more hardware and database instances, while PostgreSQL has some advanced features that naturally support scaling.
PostgreSQL uses a system called MVCC (Multiversion Concurrency Control) that allows multiple users to access and modify data simultaneously without locking out or slowing down each other’s queries like MySQL. This is particularly helpful for applications requiring high read/write activity levels.
When adding additional servers, MySQL uses binary log-based replications, which is fast but can lead to data inconsistencies when network hiccups interrupt replication activities. PostgreSQL uses the “log-shipping” approach, which is more reliable but can be slower than binary log replication. However, PostgreSQL also supports table partitioning, which allows a single table to be spread across multiple smaller tables. This tends to improve performance because smaller amounts of data are queried simultaneously.
PostgreSQL also has a more advanced query optimizer than MySQL, which helps execute queries more efficiently. PostgreSQL also sports a larger maximum table size than MySQL, making it better suited for applications with large datasets.
Security
PostgreSQL and MySQL take different approaches to security. Both have mechanisms for granting access to schemas and tables to defined users, but PostgreSQL offers more advanced features.
PostgreSQL has a fine-grained approach to user privileges, allowing administrators to assign more specific user privileges and roles. MySQL, however, uses a broader and more basic authorization system with a combination of user accounts and global or database-specific privileges. PostgreSQL supports many authentication methods beyond the simple username and password combination. This includes authenticating against an LDAP server or Active Directory and certificate-based authentication.
Both systems support encryption, with PostgreSQL offering more options. In particular, PostgreSQL supports column-level encryption and a feature known as Transparent Data Encryption (TDE). With TDE, all data in a schema is encrypted using a symmetric encryption key. This key, in turn, is protected by a master key that can be stored in a software key management system or a hardware-based security module.
MySQL uses SSL (Secure Sockets Layer) to help ensure data integrity, which makes it a popular database for web applications. Beyond that, MySQL doesn’t offer as many security and encryption features as PostgreSQL. But that doesn’t mean it’s insecure. A MySQL installation can be secured well enough to meet enterprise standards through the judicious use of strong passwords and network-level security.
Transactions
An RDBMS’s transaction methodology ensures data consistency and integrity while playing a large part in the database’s overall performance. The speed at which transactions are performed defines whether a database system suits a particular task.
Since both PostgreSQL and MySQL are ACID-compliant, both support transaction rollbacks and commits. However, MySQL does not enable transactions by default, opting for “auto-commit” mode out of the box. This means each SQL statement is automatically committed or rolled back unless this setting is changed.
MySQL uses a locking mechanism optimized for performance but can lead to inconsistencies in some cases. PostgreSQL uses a strict locking mechanism for a higher level of consistency.
Community support
MySQL first gained popularity in Web 1.0 days, partly because it’s open source and works well with other free and open-source software such as the PHP language and operating systems built on the Linux kernel. A strong community has built around MySQL over time, making it one of the most popular open-source packages ever.
The well-known acronym LAMP—for Linux, Apache, MySQL, and PHP (or Perl, or Python)—came from this community in honor of the free software packages that have powered many dynamic websites for decades.
MySQL was created by Swedish developers Michael Widenius and David Axmark in 1995. A year later, the two founded the company MySQL AB to provide commercial support and consulting services for the database as it grew in popularity. In 2008, Sun Microsystems acquired MySQL AB for $1 billion. Two years later, Sun was acquired by Oracle Corporation, which means the tech giant owns MySQL.
This raised concerns in the open-source community that Oracle would prioritize its own proprietary RDBMS solutions over MySQL. These fears have mostly been unfounded, as Oracle continues to develop MySQL and offer it under the GNU General Public License (GPL), making it free for personal and non-commercial use. However, the GPL allows Oracle to charge for commercial uses of MySQL, which makes some in the community no longer consider MySQL to truly be “free and open source.”
In response to these concerns, a community-supported version of MySQL has emerged called MariaDB. While identical to MySQL in basic form and function, MariaDB lacks some of MySQL’s advanced features.
PostgreSQL is released under a modified version of the MIT license known as the PostgreSQL License. This is a permissive free and open-source license, allowing users a great deal of flexibility in how they can use and modify the software.
As a result, PostgreSQL remains one of the most popular open-source databases in the world, with a large community support base of many users, enterprise admins, and application developers. However, there are more community contributions to the MySQL and MariaDB ecosystems.
Recent developments
Both PostgreSQL and MySQL have introduced notable updates in recent versions, keeping them at the forefront of open-source database innovation.
The release of PostgreSQL 17 in September 2024 brought several advancements. A new memory management system for the VACUUM process reduces memory consumption and improves overall performance. SQL/JSON capabilities were expanded with functions like JSON_TABLE(), enabling seamless transformation of JSON data into table formats. Logical replication has seen enhancements, such as failover control and incremental backup support via pg_basebackup. Query performance improvements include optimized handling of sequential reads and high-concurrency write operations. PostgreSQL 17 also introduced a COPY command option, ON_ERROR ignore, which enhances data ingestion workflows by continuing operations even when encountering errors.
MySQL 8.0.40, released in October 2024, continues to refine database performance and compliance. Enhancements to the InnoDB storage engine improve adaptive hash indexing and parallel query performance. Security has been bolstered with updates to OpenSSL 3.0.15 integration, ensuring compliance with modern encryption standards. The introduction of the –system-command option allows for finer control over client commands, and a revamped sys schema improves the performance of key views like innodb_lock_waits. MySQL also focuses on developer flexibility with improved error handling and broader compatibility for tools and libraries.
These ongoing developments highlight the commitment of both database communities to addressing evolving performance, scalability, and security needs, ensuring their continued relevance in diverse application environments.
Use cases
MySQL is utilized by an untold number of websites thanks in part to the database being free and open source, as well as its out-of-the-box support for the PHP language. The combination of PHP and MySQL helped create a rush of dynamic websites that didn’t have their HTML code manually updated.
Early on, Google used MySQL for its search engine. Over time, as the search giant’s dataset grew, it moved to different database technologies optimized for unstructured data and fuzzy searches. (Today, Google search is powered by Google’s own distributed data storage system, Bigtable.)
MySQL is still widely used for many small- to medium-sized web applications. Content management systems and specialized web apps like Geographic Information Systems (GIS) almost always support MySQL as a database backend.
Many enterprises also use it as the data backend for their internal applications and data warehouses. PostgreSQL is used in many of the same scenarios. Most web apps that support MySQL will also support PostgreSQL, making the choice a matter of preference for sysadmins and database administrators.
PostgreSQL pros and cons
Here are some of the pros of choosing PostgreSQL:
- Performance and scalability that matches commercial RDBMS products.
- Concurrency support for multiple write operations and reads at the same time.
- The PL/pgSQL language and support for other programming languages, such as Java, JavaScript, C++, Python, and Ruby.
- Support for high availability of services and a reputation for durability.
Some of the cons of PostgreSQL include:
- It can be complex to set up and manage, particularly for newcomers.
- Reliability comes at a performance cost.
- Large databases used in complex applications can be memory intensive.
- Less community support than MySQL/MariaDB.
MySQL pros and cons
The pros of MySQL include:
- MySQL’s storage engines enable fast performance.
- A small footprint and an easy-to-use replication system make it easy to grow and scale.
- Open-source solid community support.
- Nearly all web applications and enterprise systems support MySQL.
Here are some cons of choosing MySQL:
- Not as scalable as PostgreSQL or newer database systems.
- Lack of advanced features like full-text search and complex data types.
- Less resilience when processing complex queries.
- There is no built-in support for backups, requiring third-party backup software.
PostgreSQL and MySQL: Which to choose?
Both PostgreSQL and MySQL are extremely capable RDBMS packages. While PostgreSQL clearly supports more advanced features and has a greater reputation for reliability, that doesn’t mean MySQL is a bad choice.
MySQL’s relative simplicity makes it a great choice for smaller and medium-sized web applications. Those new to SQL and RDBMS applications, in general, can pick up the basics of MySQL quickly, making it a great choice for enterprises with limited IT resources. MySQL also has a strong community, with decades of apps supporting MySQL.
If you will be dealing with a larger dataset or developing complex custom applications, PostgreSQL is an excellent choice. Its support for custom data types and the PL/pgSQL language make Postgres a favorite of sysadmins, web developers, and database administrators worldwide.
PostgreSQL vs MySQL: A side-by-side comparison
| Category | PostgreSQL | MySQL |
| Architecture | ORDBMS; advanced features like inheritance | RDBMS; simple and lightweight |
| Data Types | JSON/JSONB, arrays, custom types | Standard SQL types; basic JSON text support |
| Performance | Optimized for complex queries and writes | Fast for simple, read-heavy workloads |
| Scalability | Partitioning, logical replication, tools | Binary log replication; vertical scaling |
| Query Language | PL/pgSQL; advanced SQL features | Standard SQL; fewer advanced features |
| Security | Fine-grained access, encryption options | Basic privileges; SSL encryption |
| Community Support | Large, enterprise-focused | Widespread, beginner-friendly |
| Use Cases | Complex apps, analytics, REST APIs | Small-medium apps, LAMP stack |
| Licensing | Permissive, unrestricted | GPL; some paid features |
| Notable Features | Advanced indexing, full-text search | Lightweight, multiple storage engines |
Choose the right database, monitor with ease
Selecting between a PostgreSQL and MySQL database ultimately depends on your specific project requirements. PostgreSQL excels in handling complex queries, large datasets, and enterprise-grade features, making it ideal for analytics, REST APIs, and custom applications. MySQL, on the other hand, shines in simplicity, speed, and compatibility, making it perfect for small-to-medium-sized applications and high-traffic web platforms.
Whatever database you choose, ensuring its performance and reliability is critical to your IT infrastructure’s success. That’s where LogicMonitor’s database monitoring capabilities come in.
Comprehensively monitor all your databases in minutes with LogicMonitor. With autodiscovery, there’s no need for scripts, libraries, or complex configurations. LogicMonitor provides everything you need to monitor database performance and health alongside your entire infrastructure—whether on-premises or in the cloud.
Why LogicMonitor for Database Monitoring?
- Turn-key integrations: Monitor MySQL, PostgreSQL, and other databases effortlessly.
- Deep insights: Track query performance, active connections, cache hit rates, and more.
- Auto-discovery: Instantly discover database instances, jobs, and dependencies.
- Customizable alerts: Eliminate noise with thresholds and anomaly detection.
- Comprehensive dashboards: Gain visibility into database and infrastructure metrics in one platform.
Ready to optimize and simplify your database management? Try LogicMonitor for Free and ensure your databases deliver peak performance every day.
Once upon a time, the prospect of an organization letting another organization manage its IT infrastructure seemed either inconceivable or incredibly dangerous. It was like someone handing their house keys to a stranger. Times have changed.
Remote Infrastructure Management (RIM) — when Company X lets Company Y, or a piece of software, monitor and manage its infrastructure remotely — has become the standard in some industries. It’s sometimes the de facto method for IT security, storage, and support.
When did this happen? When organizations started working remotely.
When the COVID-19 pandemic spiraled and governments issued social distancing and stay-at-home orders, companies rolled down the blinds and closed the doors. When remote IT management was a business need, not a request, CIOs came around to the idea. There was no other choice. It was that or nothing.
The C-suite discovered what IT leaders had known for years: RIM is safe, cheap, and just as effective as in-house management.
RIM is not perfect. There are challenges. Problems persist. So, IT leaders need to iron out the kinks before RIM becomes the standard across all industries.
In this guide, learn the current state of RIM, then discover what the future holds.
What is remote infrastructure management?
RIM is the monitoring and management of IT infrastructure from a remote location. Company X outsources infrastructure management to Company Y, for example. Alternatively, super-smart software handles all this monitoring and management, and organizations can view management processes in real time from their devices. An administrator might need to visit the organization’s physical location (or, post-COVID, a home location) to repair broken hardware, but that should be a rare occurrence.
The term “IT infrastructure” — the thing or things that RIM monitors and manages — has different definitions but might include one or all of the below:
- Software
- Hardware
- Data centers
- Networks
- Devices
- Servers
- Databases
- Apps
- Emails
- Telephony
- IT services
- Customer relationship management (CRP) systems
- Enterprise resource planning (ERP) systems
The list goes on.
What is the current state of remote infrastructure management?
The IT infrastructure management landscape looks completely different from 18 months ago. Back then, most IT teams took care of monitoring and management. But then the pandemic hit. Suddenly, organizations required RIM solutions for several reasons:
- IT teams, now working from home, could no longer manage IT infrastructure on-site effectively.
- Work-from-home models presented unique security challenges that required a more scalable infrastructure management solution. Employees accessed different software on different devices at different locations, and only RIM could solve these challenges.
- As the economy stuttered, many organizations reduced IT spending, and RIM provided a cheaper solution than conventional in-house IT.
- New technologies like teleconferencing provided additional security challenges. Hence, there is a demand for a more comprehensive infrastructure management solution.
Recent research from LogicMonitor reveals the collective concerns of IT leaders who monitor and manage the IT infrastructure of at-home employees:
- 49% worry about dealing with internet outrages and other technical issues remotely.
- 49% think too many employees logging into systems remotely will cripple networks.
- 38% worry about employees logging into systems through virtual private networks (VPNs).
- 33% don’t have access to the hardware they need to do their jobs.
- 28% don’t think teleconferencing software is secure enough.
It’s no wonder, then, that so many of these IT leaders are looking for RIM solutions.
Read more fascinating insights from LogicMonitor’s Evolution of IT Research Report.
How much infrastructure management is currently ‘remote’?
The great thing about RIM is its flexibility. Organizations can choose what they want a service provider or software to monitor and manage depending on variables such as internal capabilities and cost. Company X might want to manage its networks remotely but not its software, for example. Research shows database and storage system management are the most popular infrastructure ‘types’ monitored and managed remotely.
Remote infrastructure management challenges
Not all RIMs are the same. CIOs and other IT leaders need to invest in a service provider or software that troubleshoots and solves these challenges:
Challenge 1: Growth and scalability
Only 39% of IT decision-makers feel ‘confident’ their organization can maintain continuous uptime in a crisis, while 54% feel ‘somewhat confident,’ according to LogicMonitor’s report. These professionals should seek an RIM solution that scales at the same rate as their organization.
There are other growth solutions for IT leaders concerned about uptime in a crisis. Streamlining infrastructure by investing in storage solutions such as cloud services reduces the need for hardware, software, and other equipment. With more IT virtualization, fewer problems will persist in a crisis, improving business continuity.
Challenge 2: Security
Security is an enormous concern for organizations in almost every sector. The pandemic has exasperated the problem, with the work-from-home model presenting security challenges for CIOs. There were nearly 800,000 incidents of suspected internet crime in 2020 — up 300,000 from the previous year — with reported losses of over $4 billion. Phishing remains the No.1 cybercrime.
CIOs need a RIM solution that improves data security without affecting employee productivity and performance. However, this continues to be a challenge. IT virtualization doesn’t eliminate cybercrime, and not all service providers and software provide adequate levels of security for data-driven teams.
There are several security frameworks to consider. IT leaders require a RIM solution that, at the least, adheres to SOC2 and ISO standards, preferably ISO 27001:2013 and ISO 27017:2015 — the gold standards of IT security. Other security must-haves include data encryption, authentication controls, and access controls.
Then there’s the problem of data governance. When moving data to a remote location, data-driven organizations must adhere to frameworks like GDPR, HIPAA, and CCPA. Otherwise, they could face expensive penalties for non-compliance.
Challenge 3: Costs
The cost of RIM remains a bugbear for many CIOs. As RIM is still a relatively new technology, some service providers charge larger organizations hundreds of thousands to manage and monitor hardware, software, networks, and servers.
Investing in monitoring software provides more value for money. These programs do nearly everything a RIM services provider does but without the expensive price tag. Service providers use software to automate monitoring and management, so organizations won’t notice a big difference.
Regardless of whether organizations choose a service provider or monitoring software, the costs of both methods should provide an investment return. Research shows the average cost of a data breach in the U.S. is $8.46 million, so if remote monitoring and management prevent a breach, it’s well worth it.
Challenge 4: Automation
As mentioned above, software automates much of remote monitoring. However, some monitoring and management tools are better at executing this process than others. That’s because RIM is still a new technology, and some vendors are working out the fine details. Regardless, monitoring tools are becoming more sophisticated daily, automating nearly all the manual processes associated with infrastructure management, such as network performance updates and security patch installation.
Challenge 5: AI/Machine learning
RIM has struggled with AI and machine learning, but this is changing fast. The best tools take advantage of these technologies by providing end-users with invaluable insights into every aspect of their IT infrastructure, from server uptime to network memory.
AI-driven tools leverage predictive analytics to analyze historical data, identify patterns, and predict potential failures before they occur, enabling IT teams to take proactive measures and prevent incidents. Machine learning enhances intelligent automation by optimizing tasks such as resource allocation and network performance, reducing the need for manual intervention and increasing overall efficiency.
AI-powered algorithms will continuously monitor your systems, detecting unusual behaviors or anomalies that could indicate security threats or performance issues, allowing for a swift response. Capacity planning is also improved as AI tools analyze infrastructure usage trends and provide recommendations for resource optimization, ensuring scalability while avoiding unnecessary costs.
Finally, machine learning models correlate data across diverse systems to generate actionable insights, helping CIOs make informed decisions, prioritize tasks, and allocate resources more effectively. These advancements are transforming RIM into a smarter, more efficient approach to infrastructure management.
Not all remote management tools use these technologies, so CIOs and software procurement teams should research the market and find the best platforms and RIM service providers.
Challenge 6: Cloud
RIM and the cloud are a match made in technological heaven. With IT virtualization, CIOs can manage much of their infrastructure (and data) in a cloud environment, which provides these remarkable benefits:
- The cloud reduces the amount of physical hardware (on-premise hardware) in an organization.
- It safeguards data for security and governance purposes.
- Team members can access data remotely wherever they are in the world.
- It protects the environment.
- It improves energy efficiency.
- It scales better.
- It provides cost savings.
The move to full virtualization won’t happen anytime soon, with many business leaders still skeptical about the cloud. 74% of IT leaders think 95% of public, private, and hybrid workloads will run in the cloud in the next five years, according to LogicMonitor’s report. 22% think it will take six years or more; 2% don’t believe it will ever happen. Still, more organizations are using the cloud than ever before.
The cloud brings security challenges for IT teams, but the right tools will ease any concerns.
How to implement remote infrastructure management services effectively
Implementing RIM successfully requires a structured approach that aligns with your organization’s needs, infrastructure, and goals. Below are actionable steps to ensure effective adoption:
1. Assess organizational needs
Before implementing RIM, identify what infrastructure components need to be managed remotely. This might include:
- Networks and servers for real-time monitoring
- Applications requiring frequent updates
- Critical data is subject to compliance regulations
Consider existing IT capabilities and pinpoint areas where RIM can add the most value, such as improving uptime or reducing costs.
2. Choose the right tools and providers
Select tools or service providers that match your infrastructure’s complexity and scalability requirements. Look for:
- Automation and AI capabilities to reduce manual effort
- Compliance with SOC2, ISO 27001, and other relevant standards
- Flexible pricing models that suit your organization’s budget
Ensure your chosen solution integrates seamlessly with existing systems, including hybrid and multi-cloud environments.
3. Prioritize security
Cybersecurity is a critical consideration for any RIM strategy. Implement:
- Data encryption to protect sensitive information
- Role-based access controls to minimize security risks
- Regular audits to ensure compliance with regulations like GDPR or CCPA
Security protocols should safeguard data without hampering employee productivity
4. Leverage automation and AI
Automating routine tasks such as performance monitoring and incident detection streamlines IT and business operations. Use tools that:
- Offer predictive analytics for proactive maintenance
- Automatically apply security patches and updates
This reduces downtime and frees up IT resources for strategic initiatives.
5. Plan for scalability
As your organization grows, your RIM strategy should scale accordingly. Opt for solutions that support:
- Increasing workloads without impacting performance
- Flexible infrastructure that adapts to changing needs, such as expanding cloud storage
Scalability ensures your IT operations remain efficient during growth.
6. Train your IT teams
Equip IT staff with the skills needed to manage RIM tools effectively. Training ensures:
- Seamless tool adoption
- Improved collaboration between teams managing on-premises and remote infrastructure
A well-trained team is critical for realizing the full benefits of RIM.
7. Monitor and optimize continuously
RIM implementation doesn’t end after setup. Continuously track key performance metrics, such as:
- System uptime and availability
- Incident response times
- Infrastructure costs
Use these insights to refine your strategy and improve efficiency.
RIM vs DCIM software
While RIM and Data Center Infrastructure Management (DCIM) software share overlapping goals, they are distinct in their approach and scope. Both focus on improving visibility and control over IT infrastructure, but each caters to different operational needs.
What is DCIM software?
DCIM software specializes in managing the physical components of data centers, such as power, cooling, and space utilization. It provides insights into infrastructure efficiency and helps data center operators optimize performance, reduce energy costs, and plan for future capacity needs.
How RIM differs from DCIM
- Scope of management
- RIM: Broadly encompasses remote monitoring and management of IT infrastructure, including software, hardware, servers, and networks, often across multiple geographic locations.
- DCIM: Primarily focuses on the physical aspects of a data center, such as racks, power distribution, and environmental conditions.
- Location
- RIM: Extends management capabilities beyond the data center, making it ideal for hybrid, remote, and multi-cloud environments.
- DCIM: Typically operates within the confines of a physical data center, offering on-premises insights.
- Key technologies
- RIM: Leverages automation, AI, and cloud-based tools to provide real-time monitoring and incident management.
- DCIM: Relies on sensors, physical monitoring tools, and predictive analytics for maintaining data center health and efficiency.
- Use cases
- RIM: Ideal for organizations with distributed infrastructure needing centralized, remote oversight.
- DCIM: Suited for enterprises managing large-scale, on-premises data centers requiring detailed physical infrastructure management.
When to use RIM or DCIM
Organizations that rely heavily on hybrid IT environments or need to support remote operations benefit from RIM’s flexibility. However, for businesses with significant investments in physical data centers, DCIM provides unparalleled insights into physical infrastructure performance.
Can RIM and DCIM work together?
Yes. These solutions complement one another, with RIM focusing on the IT layer and DCIM ensuring optimal physical conditions in the data center. Together, they provide a holistic view of infrastructure performance and health.
What is the future for remote infrastructure management?
More organizations are investing in RIM. Experts predict the global RIM market will be worth $54.5 billion by 2027, growing at a CAGR of 9.7% from now until then. Meanwhile, database management and storage system management will grow at CAGR rates of 10.4% and 10% over the next seven years. The two countries that will invest the most money in RIM during this same period will be China and the United States.
With such explosive growth, expect more RIM innovations in the next few years. The software will become smarter. Service providers will offer more infrastructure services. Full cloud monitoring may exist if all infrastructure moves to the cloud.
RIM could also trickle down to smaller businesses that still rely on manual processes for monitoring and management — or don’t carry out these critical tasks at all. As the costs of data centers, servers, and resources rise, small business owners will keep a closer eye on monitoring tools that provide them with insights such as network and bandwidth usage and infrastructure dependencies.
Take control of your IT infrastructure today
RIM has existed, in one form or another, for several years. However, the growing demands of work-from-home have brought remote monitoring and management into the spotlight. Whether it comes from software or a service provider, RIM takes care of software, hardware, server, and network tasks organizations don’t have the time for or don’t want to complete. Despite some challenges, the future of RIM looks bright, providing busy teams with bespoke monitoring and management benefits they can’t find anywhere else.
LogicMonitor is the cloud-based remote monitoring platform for CIOs and IT leaders everywhere. Users get full-stack visibility, world-class security, and network, cloud, and server management tools from one unified view. Welcome to the future of remote monitoring. Learn more or try LogicMonitor for free.
What is NoSQL?
NoSQL is a non-tabular database that has a different data structure than relational tables. It is sometimes referred to as Non-SQL. NoSQL typically avoids relational data storage; however, while it can handle relationships in data storage, those relationships are built for specialized purposes.
There is much debate regarding SQL vs. NoSQL, with each data management system geared toward specific uses. Unlike SQL, which was developed in the 1970s to limit data duplication, NoSQL is a relatively new type of database. NoSQL came about in response to increasing amounts of data, and it uses a distributed system to help organize large amounts of structured and unstructured data. NoSQL is popular in business tech and other industries, with large organizations such as Amazon, Google, and LinkedIn using NoSQL databases.
Today, large companies are increasingly using NoSQL for data management. For example, a business that needs to store large amounts of unstructured and structured data or manage real-time streaming will want to consider NoSQL.
How NoSQL databases work
NoSQL databases function differently from traditional relational databases, offering a more flexible and scalable approach to data management. Their unique operational mechanisms make them well-suited for handling large-scale, distributed data environments.
NoSQL databases use flexible schemas, allowing dynamic and adaptable data models. Unlike SQL databases with predefined schemas, NoSQL supports various data types, including structured, semi-structured, and unstructured formats. Developers can update schemas without disrupting existing records, enabling rapid application development.
These databases also operate on distributed architectures, spreading data across multiple servers or nodes to ensure high availability, fault tolerance, and seamless scaling. Data replication guarantees durability, while partitioning efficiently distributes workloads to maintain performance under heavy demand.
Additionally, NoSQL terminology differs from SQL’s traditional structure. Collections in NoSQL function similarly to tables, grouping related data. Documents replace rows, allowing more flexible records. Some NoSQL models use key-value pairs or column families instead of columns to organize data.
Types of NoSQL databases
The structure and layout of different NoSQL database types depend on the data model. The four main structures are document, graph, key-value, and wide-column.
Document Databases – These databases store data similar to JavaScript Object Notation (JSON). Every document will contain pairs of values and fields, but it does not need foreign keys because specific relationships between documents don’t exist. Other essential features include fast creation, easy maintenance, flexible schema, and open formats.
Graph Databases – This format is primarily for data represented in a graph, such as road maps and public transportation information. The graphs store data in edges and nodes. Nodes generally contain information about people, places, and things, while edges store relational information between the nodes. Using a graph database enables quick identification of data relationships.
Wide-Column Databases – A wide-column database stores information in columns instead of rows. The columns form subgroups, and columns in the same family or cluster can contain different data types. Databases with columns read data more efficiently, and each column has a dynamic schema and isn’t fixed in a table. If you want to store large data, you’ll likely want to consider using wide-column databases.
Key-Value Databases – With the simplest format, key-value databases only have two columns containing keys and values. More extensive data models are sometimes extensions of the key-value database, which uses the associative array as the basic data model. Data also comes in a collection of key-value pairs, and each key never appears more than once in each collection. Important features of this type of database include simplicity, speed, and scalability.
You’ll also see several specific types of NoSQL databases. Examples include:
- BigTable
- Cassandra
- CouchDB
- FaunaDB
- HBase
- MongoDB
- Redis
NoSQL use cases
NoSQL databases excel in handling diverse and complex data environments, making them indispensable for a wide range of modern applications. Their scalability, flexibility, and high performance allow businesses to tackle demanding workloads effectively.
Real-time data management is one of the most compelling use cases for NoSQL. These databases handle large streams of incoming data with minimal latency, making them ideal for real-time analytics, fraud detection, and live social media feeds. Their ability to process data at lightning speed ensures a seamless user experience even during peak demand.
NoSQL databases play an important role in cloud security by supporting dynamic data models and secure storage. Their distributed nature ensures data integrity, availability, and disaster recovery, making them valuable for enterprises managing sensitive information across multiple cloud environments.
High-availability apps benefit greatly from NoSQL’s fault-tolerant and distributed design. Industries like finance, healthcare, and telecommunications rely on NoSQL databases to maintain uptime and continuous service delivery, even during infrastructure failures or spikes in user traffic.
Diverse workloads such as IoT and e-commerce also thrive with NoSQL. In IoT applications, vast amounts of sensor data require scalable storage solutions that can handle real-time processing and analysis. Similarly, e-commerce platforms depend on NoSQL databases for personalized product recommendations, dynamic pricing, and efficient inventory management.
Benefits
NoSQL offers several benefits:
- Easy for developers to use – One of the first advantages of NoSQL is that some systems only require a few lines of code. The databases also require less general maintenance.
- Flexible schemas – NoSQL is non-rigid, making testing and implementing updates easier. This is necessary for most modern applications because fields are different, and you will often need to make changes quickly and easily.
- Horizontal scaling – Expanding NoSQL is relatively easy and inexpensive, providing horizontal scaling because of its lack of structure. This means every element is independent and doesn’t need links. On the other hand, SQL will require upgrades such as more RAM or CPUs for vertical expansion.
- High performance – NoSQL often has higher performance levels than SQL because it doesn’t need to query data through various tables. Since things move much quicker with all the information in one database, doing 10,000 queries each second with some NoSQL databases is possible.
- Large data storage – NoSQL databases have the potential to store massive amounts of data sets, and they can do so at high rates of speed. For example, Cloud BigTable is a NoSQL database that lets you store structured data while allowing addition and deletion without disturbance.
Drawbacks
The potential drawbacks include the following:
- Requires multiple databases – Since the databases are specialized for particular use cases, you’ll need to use various data models and databases. You might still need to use SQL to help streamline the overall process.
- Requires more support – NoSQL is much newer than SQL. SQL is, therefore, more mature and has a lot of online instructional support. With NoSQL, you’ll likely have more difficulty finding expert support when you need assistance.
- Lack of consistency – NoSQL databases lack standardization, and the programming language and design of these databases vary extensively. This variation among NoSQL products is more extensive than with SQL databases.
- Lack of compatibility – NoSQL is not always entirely compatible with SQL instructions.
- Limited ACID applications – Most NoSQL systems don’t support ACID (atomicity, consistency, isolation, durability) transactions. MongoDB is an exception to this situation.
Choosing a NoSQL database
Selecting the right NoSQL database depends on several factors that align with your organization’s data management needs and business goals. NoSQL databases come in various models, each suited to specific use cases, making it essential to evaluate your options carefully. Key considerations include:
1. Data model selection
- Document databases: Ideal for applications requiring flexible schemas, such as content management systems.
- Key-value stores: Best for caching and real-time session management.
- Wide-column stores: Useful for high-volume analytical applications.
- Graph databases: Perfect for applications emphasizing relationships, like social networks.
2. Consistency trade-offs
- Consider your application’s tolerance for data inconsistency. NoSQL databases often sacrifice strict consistency for availability and scalability, following the CAP theorem.
- Use databases with configurable consistency settings if data accuracy is critical.
3. Cloud compatibility
- Choose a NoSQL database that integrates seamlessly with your cloud provider’s ecosystem.
- Consider managed services to reduce operational overhead and focus on development.
4. Migration strategies
- Plan for data migration if switching from a relational database to NoSQL.
- Ensure your team has the skills and tools necessary for a smooth migration process.
Assessing these factors can help you identify the NoSQL database that best meets your business needs, ensuring optimal performance, scalability, and reliability.
What is MongoDB?
MongoDB is a type of NoSQL database that is document-oriented and uses various documents and collections. It is primarily for high-volume data storage. Key-value pairs are the basic unit for MongoDB.
The following are a few of the essential features of MongoDB:
- MongoDB is very scalable. This system allows developers to write code in whatever language they choose.
- It doesn’t need a schema before starting. You can create the fields as you go.
- Every database will contain collections, with each collection housing documents. Each document can have fields with varying sizes and different content.
- It provides quicker query responses.
- MongoDB provides advanced searching.
- The database features indexing to improve search query performance.
- MongoDB provides data replication to send it to multiple nodes. Both primary and secondary nodes can replicate data.
- It supports advanced features for searching any field, range of queries, or regular expression.
- MongoDB provides the oplog (operations log) feature. This is a system that collects and stores all database changes. It keeps the changes chronologically and can help with deeper analysis since the oplog is entirely granular.
Many of these features point to a common theme, which is flexibility. When using SQL best practices, you must work within the database structure. There’s usually only one best way to do things. When using MongoDB, you’ll have several options for optimizing code throughout the process.
Is MongoDB NoSQL?
Yes, MongoDB is a type of NoSQL. MongoDB is a database management system that stores data using binary storage in flat files. This structure is helpful for large amounts of data since data storage is efficient and compact. It is document-based and open-sourced.
When using MongoDB, consider the following tips:
- The _id field must appear in every MongoDB document.
- Sharding is a way to distribute data through several partitions.
- There are size limits to keep in mind. When using MongoDB, you cannot exceed 16 MB for documents.
- There are limits on nested data. However, storing too many arbitrary objects when using MongoDB is usually not a good idea.
- Note that MongoDB restricts certain characters, including the $ sign and a period (.).
Like NoSQL, you’ll need to monitor MongoDB effectively. Several specific areas need monitoring:
- Instance Status
- Instance Hardware Metrics
- Replication Metrics
- Connections Metrics and Cluster Operations
What is the difference between SQL and NoSQL?
SQL is the acronym for Structured Query Language. As the most basic type of database management, SQL is a relational model that searches and retrieves information through different data, fields, and structures. Some of the most fundamental differences between SQL and NoSQL include:
- NoSQL uses dynamic schema for its unstructured data, while SQL uses queried language with a predefined schema.
- NoSQL databases are scalable horizontally, while SQL is scalable vertically.
- NoSQL has document, graph, key-value, or wide-column store databases, while SQL has table-based databases.
- NoSQL is better suited for unstructured data, while SQL will likely use multi-row transactions.
The bottom line
Each database has its merits, but when considering SQL vs. NoSQL, it’s important to remember a few key points. These include SQL being relational while NoSQL is non-relational, SQL databases generally scaling vertically, and NoSQL falling into four types of structures. When selecting from the NoSQL options, consider MongoDB an advanced database capable of handling dynamic schema and big data.
When evaluating NoSQL databases, consider factors such as scalability, consistency, and use case compatibility. Databases like MongoDB, Cassandra, and Redis provide powerful features designed to handle massive workloads and dynamic data models, making them essential for modern cloud-native applications.
Looking to optimize your data management strategy? Explore how LogicMonitor can help you monitor and manage your database infrastructure. Our comprehensive platform ensures visibility, performance, and reliability across all your IT environments.
IT automation uses software and technology to handle repetitive IT tasks automatically, reducing the need for manual work and accelerating processes like infrastructure management and application deployment. This transformation is essential for IT teams needing to scale efficiently, as seen in the case of Sogeti, a Managed Service Provider (MSP) that provides tech and engineering resources worldwide.
Sogeti had a crucial IT challenge to solve. The MSP operates in more than 100 locations globally and uses six different monitoring tools to monitor its customers’ environments. It was a classic example of tool sprawl and needing to scale where multiple teams of engineers relied on too many disparate tools to manage their customers’ environments. It soon became too arduous for the service provider to collect, integrate, and analyze the data from those tools.
Sogeti had teams of technicians managing different technologies, and they all existed in silos. But what if there was a way to combine those resources?
IT automation provided a solution.
After working with LogicMonitor, Sogeti replaced the bulk of its repeatable internal processes with automated systems and sequences. The result? Now, they could continue to scale their business with a view of those processes from a single pane of glass.
Conundrum cracked.
That’s just one example of how IT automation tools completely revolutionizes how an IT services company like an MSP or DevOps vendor can better execute its day-to-day responsibilities.
By automating repeatable, manual processes, IT enterprises streamline even the most complicated workflows, tasks, and batch processes. No human intervention is required. All it takes is the right tech to do it so IT teams can focus on more strategic, high-priority efforts.
But what exactly is IT automation? How does it work? What are the different types? Why should IT companies even care?
IT automation, explained
IT automation is the creation of repeated software processes to reduce or eliminate manual or human-initiated IT tasks. It allows IT companies with MSPs, DevOps teams, and ITOps teams to automate jobs, save time, and free up resources.
IT automation takes many forms but almost always involves software that triggers a repeated sequence of events to solve common business problems—for example, automating a file transfer. It moves from one system to another without human intervention or autogenerates network performance reports.
Almost all medium and large-sized IT-focused organizations use some automation to facilitate system and software processes, and smaller companies benefit from this tech, too. The most successful ones invest heavily in the latest tools and tech to automate an incredible range of tasks and processes to scale their business.
The production, agricultural, and manufacturing sectors were the first industries to adopt IT automation. However, this technology has since extended to niches such as healthcare, finance, retail, marketing, services, and more. Now, IT-orientated companies like MSPs and enterprise vendors can incorporate automation into their workflows and grow their businesses exponentially.
How does IT automation work?
The software does all the hard work. Clever programs automate tasks that humans lack the time or resources to complete themselves.
Developers code these programs to execute a sequence of instructions that trigger specific events from specific operating systems at specific times. For example, programming software so customer data from a customer relationship management system (CRM) generates a report every morning at 9 a.m. Users of those programs can then customize instructions based on their business requirements.
With so many benefits of IT automation, it’s no wonder that two-thirds of CFOs plan to accelerate the automation of repetitive tasks within their companies.
Why do businesses use IT automation?
IT-focused businesses use automation for various reasons:
- It makes life easier for tech teams. For example, engineers and technicians at MSP companies no longer have to execute tasks like network performance analysis, data security management, or reporting manually. The software takes care of everything for them so they can better focus their efforts on other tasks.
- It makes life easier for non-tech teams. Employees across all departments within an IT-focused organization benefit from automation because they can carry out responsibilities on software and systems with less manual work. For example, administrative employees in a DevOps consulting firm can generate payroll reports without manually entering information into a computer by hand.
- It helps CIOs and executives scale their businesses because other employees, such as engineers and MSP professionals, can complete jobs with minimum effort. Automation frees up tech resources and removes as much manual IT work as possible, allowing IT-centered organizations to improve their margins and grow.
- It helps CIOs and executives fulfill client-orientated objectives by improving service delivery. Automation can also advance productivity across an organization, which results in better service level agreement (SLA) outcomes. Again, the right automation software reduces as much manual work for tech teams so businesses can grow and carry out responsibilities more efficiently.
- It allows MSPs and other IT companies, especially smaller ones, to survive in ever-competitive environments. By automating IT processes, these enterprises can stay competitive with more tech resources and reduced manual labor.
- It allows for improved profitability in IT companies. For example, MSPs can onboard more clients without hiring new engineers. That’s because automated systems delegate tasks and resources seamlessly.
- It reduces costs for IT companies by saving time and improving operational efficiencies. For example, by freeing up human resources, enterprises can focus on generating more sales and revenue. As a result, CIOs and executives have more money to spend on labor and can add highly skilled IT professionals to their tech teams.
Key benefits of IT automation
IT automation delivers many advantages that extend beyond simple task delegation. Let’s look at a few benefits your organization will see.
Enhanced organizational efficiency
With the complexity of modern IT infrastructure, modern environments may handle thousands of requests daily—everything from password resets to system failures. Automation can help reduce the time it takes to handle many of those requests. For example, look at an IT telecommunications company with a lot of infrastructure. They can automate their network configuration process, cutting the deployment time from a few weeks to less than a day.
Reduce errors
Human error in IT environments can be costly. Errors can lead to unexpected system downtime, security breaches, and data entry errors—all of which you can avoid by standardizing consistency and standards through automation. Automation helps your team eliminate routine data entry and other tasks and greatly reduces the chance of human error. For example, your team may decide to create backup scripts for more complicated setups to ensure you always have reliable backups.
Faster service delivery
Automation helps speed up responses to common IT requests. If your IT team is stuck needing to perform every task manually, it increases incident response time and the length of time your customer waits on the other end of the line for a fix. Automation speeds up common tasks—setting up VPN access, account resets, report creation, and security scans—allowing your team to focus on finding the root cause of problems, deploying resources, and bringing systems back online.
Streamlined resource allocation
Your organization’s IT needs may fluctuate depending on how many users you have and their activities. A strict guide for resource usage may result in some users being unable to work efficiently because of slow systems. Automation can help by automating resource allocation. For cloud services, you can scale your servers based on demand, and for network traffic, you can dynamically adjust traffic routes based on usage.
Enhanced compliance and security
Automated systems can help your team maintain detailed audit trails and enforce consistent security policies. They can also help with continuous monitoring, allowing your team to get alerts immediately when your solution detects suspicious activity. Additionally, your IT systems can automatically generate compliance reports, such as SOC 2, for review, helping your team find potential problems and comply with audit requests.
Different IT automation types
IT companies benefit from various types of IT automation.
Artificial intelligence
A branch of computer science concerned with developing machines that automate repeatable processes across industries. In an IT-specific context, artificial intelligence (AI) automates repetitive jobs for engineers and IT staff, reduces the human error associated with manual labor, and allows companies to carry out tasks 24 hours a day.
Machine learning
Machine learning (ML) is a type of AI that uses algorithms and statistics to find real-time trends in data. This intelligence proves valuable for MSPs, DevOps, and ITOps companies. Employees can stay agile and discover context-specific patterns over a wide range of IT environments while significantly reducing the need for case-by-case investigations.
Robot process automation
Robot Process Automation (RPA) is a technology that instructs ‘robots’ (machines) to emulate various human actions. Although less common in IT environments than in AI and ML, RPA still provides value for MSPs and other professionals. For example, enterprises can use RPA to manage servers, data centers, and other physical infrastructure.
Infrastructure automation
IT infrastructure automation involves using tools and scripts to manage computing resource provisioning with manual intervention. This includes tasks like server provisioning, bandwidth management, and storage allocation. This allows for dynamic resource usage, with the most resources going to the users and applications with the most need.
How can businesses use IT automation?
A proper automation strategy is critical for IT companies. CIOs and executives should decide how to achieve automation within their organizations and then choose the right tools and technologies that facilitate these objectives.
Doing so will benefit your business in many ways.
- Improve your company’s operation by removing redundant tasks and freeing up time to work on more mission-critical jobs
- Enhance customer satisfaction by more quickly responding and resolving problems
- Improve employee satisfaction by making sure business systems stay online, helping meet their expectations and improving their ability to do their jobs
Here are some examples of how IT companies use automation:
Templating/blueprints
Companies can automate templates and blueprints, promoting the successful rollout of services such as network security and data center administration.
Workflow/technology integration
Automation allows companies to integrate technology with workflows. As a result, CIOs and executives complete day-to-day tasks more effectively with the latest hardware and software. For example, automating server management to improve service level management workflows proves useful if clients expect a particular amount of uptime from an MSP.
AI/ML integration
AI and ML might be hard for some companies to grasp at first. However, teams can learn these technologies over time and eventually combine them for even more effective automation within their organizations.
Auto-discovery
Automated applications like the LogicMonitor Collector, which runs on Linux or Windows servers within an organization’s infrastructure, use monitoring protocols to track processes without manual configuration. Users discover network changes and network asset changes automatically.
Auto-scaling
IT companies can monitor components like device clusters or a VM in a public cloud and scale resources up or down as necessary.
Automated remediation/problem resolution
Hardware and software can provide companies like MSPs with all kinds of problems (downtime, system errors, security vulnerabilities, alert storms, etc.). Automation, however, identifies and resolves infrastructure and system issues with little or no human effort.
Performance monitoring and reporting
Automation can automatically generate regular performance reports, SLA reports, compliance reports, and capacity planning forecasts. It can also generate automated alerting systems in case of problems and report trends to help your business with capacity planning.
Best practices for automation success
Successfully automating IT in business requires careful planning and thoughtful execution. Follow these best practices to avoid the common mistakes and maximize efficiency:
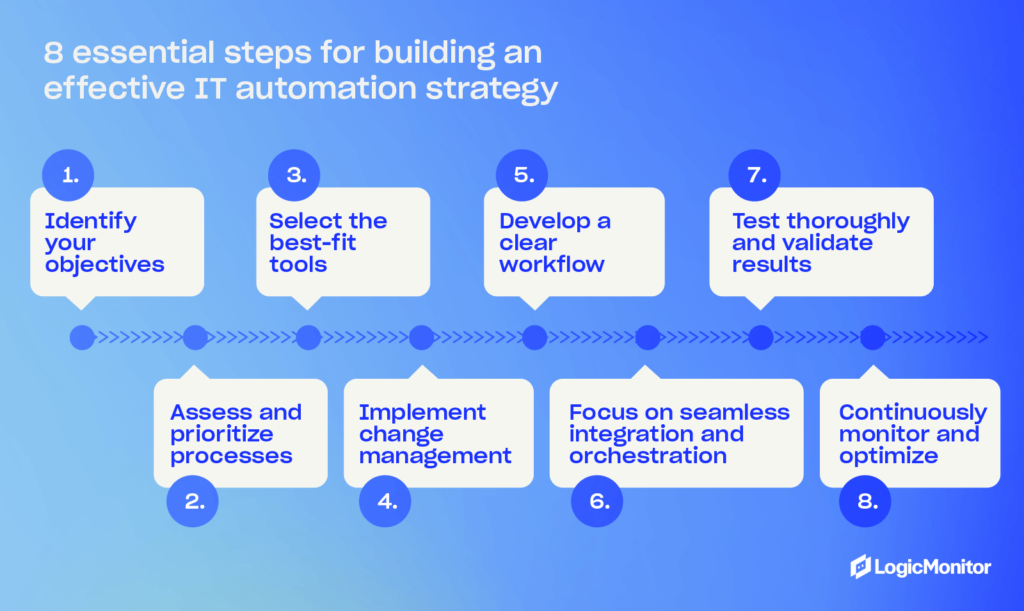
- Align automation and business goals: Don’t just start automating everything possible without a plan. Begin by identifying what you want to achieve with automation. Look for areas to reduce operational costs, improve service, and enhance customer satisfaction, and start with the areas that have the most impact and help you reach your goals. Consider asking stakeholders and employees about their biggest friction points and the ability to automate them.
- Start small: Investing in IT automation is an ongoing task, and you may not do things right the first time. Start small with quick wins. Learn what works for your business and pilot your initial automation tasks to test how they work. Eventually, begin scaling as you gain insights from smaller projects to inform larger, more impactful ones.
- Focus on security: Although your team may not be working with data manually as much, security is still a must with IT automation. Integrate secure protocols at every layer of your systems and processes. Look at your regulatory requirements to determine your needs, and regularly audit your systems to identify potential weaknesses.
- Document everything: If things go wrong, you need detailed records about your automation process. Create documents that detail every system, automation tools and scripts that belong to those systems, and common troubleshooting tips for quickly dealing with problems. Make documentation available to team members so all your team members can look up how things work and manage their designated automation systems.
- Monitor performance: Establish metrics that indicate the success of your automation efforts. Look for improvements in uptime, response time, and other performance data. Regularly look for areas that don’t meet your performance metrics and investigate areas of improvement.
IT Automation Pros and Cons
Here are some pros and cons of automation for those working in IT:
Pros
- Enhanced productivity (improved workflows, higher production rates, better use of technologies and human resources, freeing up IT resources, etc.).
- Better customer/client outcomes (improved SLAs, faster and more consistent services, higher-quality outputs, enhanced business relationships, etc.).
- Reduced total cost of ownership (auto-discovery tools prevent expensive errors, freeing up labor resources, automatic discovery of cost-cutting technologies, etc.).
Cons
- Automation requires an initial cost investment and engineers’ time to set up. That’s why IT-focused companies should choose a cost-effective automation platform that generates an ongoing return on investment.
- Some team members may find it difficult to adopt automation technologies. The best course of action is to select a simplified automation tool.
- Automation may amplify security issues. Software and configuration vulnerabilities can quickly spread in your organization before being detected, which means security considerations and testing must be done before introducing automation.

Read more: The Leading Hybrid Observability Powered by AI Platform for MSPs
Will IT automation replace jobs?
There’s a misconception that IT automation will cause job losses. While this might prove true for some sectors, such as manufacturing, IT-focused companies have little to worry about. That’s because automation tools don’t work in silos. Skilled IT professionals need to customize automation tools based on organizational requirements and client demands. MSPs that use ML, for example, need to define and determine the algorithms that identify real-time trends in data. ML models might generate data trends automatically, but MSPs still need to select the data sets that feed those models.
Even if automation takes over the responsibilities of a specific team member within an IT organization, executives can upskill or reskill that employee instead of replacing them. According to LogicMonitor’s Future of the MSP Industry Research Report, 95% of MSP leaders agree that automation is the key to helping businesses achieve strategic goals and innovation. By training employees who currently carry out manual tasks, executives can develop a stronger, higher-skilled workforce that still benefits from IT automation.
Future of IT automation
AI, machine learning, and cloud computing advancements are significantly altering how businesses manage their IT infrastructure. As these technologies continue to evolve, how you manage your business will change along with them.
Here’s what to expect in the future of IT automation:
Intelligent automation
Traditional automation tools use a rules-based approach: a certain event (e.g., time of day, hardware failure, log events) triggers an action through the automation systems.
Advanced AI operations tools are changing that with their ability to predict future events based on data. That leads to more intelligent automation that doesn’t require a rules-based system. These systems understand natural language, recognize patterns, and make decisions based on real-time data. They allow for more responsive IT systems that anticipate and fix problems.
Hybrid cloud automation
The growing adoption of cloud environments—which include private, public, and on-prem resources—requires your business to adopt new strategies to manage infrastructure and automate tasks. You need tools that seamlessly integrate with all environments to ensure performance and compliance where the data resides.
Hybrid environments also allow for more flexibility and scalability for IT infrastructure. Instead of being limited by physical constraints, your business can use the cloud to scale computing resources as much as needed. Automated provisioning and deployment means you can do this at scale with minimal IT resources.
Edge computing automation
As workforces and companies become more distributed, your business needs a way to provide resources to customers and employees in different regions. This may mean a web service for customers or a way for employees to access business services.
Edge devices can help supply resources. Automation will help your business manage edge devices, process data on the edge, and ensure you offer performant applications to customers and employees who need them.
Choosing the right IT automation platform
Successful data-driven IT teams require technology that scales as their business does, providing CIOs and executives with ongoing value. LogicMonitor is the world’s only cloud-based hybrid infrastructure monitoring platform that automates tasks for IT service companies like MSPs.
LogicMonitor features include:
- An all-in-one monitoring platform that revolutionizes digital transformation for MSPs and DevOps/ITOps teams worldwide.
- Complete 360-degree visibility of utilization, network performance, resource consumption, cloud instances, and much more.
- Full observability of technologies and resources such as servers, data centers, and cloud-based environments.
- The ability to identify problems with legacy tools before they happen.
- Real-time reports and forecasts that reduce internal costs, improve SLA outcomes, and power engineers and other IT professionals.
- No additional hardware maintenance or technical resources. LogicMonitor is ready out of the box.
Final Word
IT automation has revolutionized the IT sector, reducing the manual responsibilities that, for years, have plagued this industry. MSPs no longer need to enter network performance data into multiple systems, physically inspect servers, manage and provision networks manually, analyze performance reports, or perform other redundant tasks manually. Automation does a lot of the hard work so that these IT professionals can focus on far more critical tasks. By incorporating cloud-based infrastructure monitoring, AI, machine learning, and other new technologies, your IT executives improve productivity, enhance workflows, reduce IT resources, promote better client outcomes, and reduce costs over time.
NetApp, formerly Network Appliance Inc., is a computer technology company specializing in data storage and management software.
Known for its innovative approach to data solutions, NetApp provides comprehensive cloud data services to help businesses efficiently manage, secure, and access their data across diverse environments. Alongside data storage, NetApp offers advanced management solutions for applications, enabling organizations to streamline operations and enhance data-driven decision-making across hybrid and multi-cloud platforms.
What is NetApp?
NetApp is a computer technology company that provides on-premises storage, cloud services, and hybrid data services in the cloud. Its hardware includes storage systems for file, block, and object storage. It also integrates its services with public cloud providers. NetApp’s services offer solutions for data management, enterprise applications, cybersecurity, and supporting AI workloads. Some of its main products include different storage software and servers.
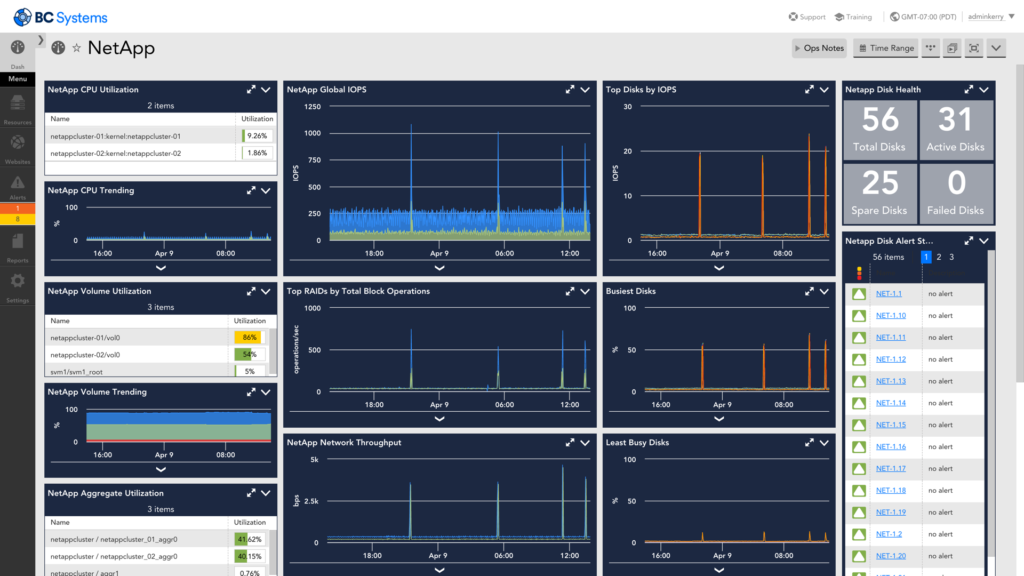
NetApp has developed various products and services, and according to Gartner, was ranked the number one storage company in 2019. The following includes detailed definitions of NetApp’s key terms and services.
Azure NetApp is a popular shared file-storage service used for migrating POSIX-compliant Linux and Windows applications, HPC infrastructure, databases, SAP HANA, and enterprise web applications.
Why choose NetApp?
NetApp provides organizations with advanced data storage and management solutions designed to support diverse IT environments, from on-premises to multi-cloud. For businesses looking to enhance their infrastructure, NetApp offers several key advantages:
- Cost efficiency: NetApp’s tools help optimize cloud expenses, enabling companies to manage data growth without excessive costs, while its efficient storage solutions reduce overall spending.
- Scalability: Built to grow with your business, NetApp’s services seamlessly scale across cloud, hybrid, and on-premises environments, making it easier to expand as data needs evolve.
- Enhanced security: NetApp prioritizes data protection with features designed to defend against cyber threats, ensuring high levels of security for critical information.
- Seamless cloud integration: With strong support for leading cloud providers like Google Cloud Platform (GCP) and AWS, NetApp simplifies hybrid cloud setups and provides smooth data migration across platforms.
Understanding the dos and don’ts of NetApp monitoring can help you maximize its benefits. By selecting NetApp, IT professionals and decision-makers can leverage streamlined data management, improved performance, and flexible integration options that fit their organization’s unique needs.
What are NetApp’s key services?
NetApp offers several important services and products to help customers meet their data storage and management goals.
Ansible
Ansible is a platform for automating networking, servers, and storage. This configuration management system enables arduous manual tasks to become repeatable and less susceptible to mistakes. The biggest selling points are that it’s easy to use, reliable, and provides strong security.
CVO
CVO (Cloud Volumes ONTAP) is a type of storage delivering data management for block and file workloads. This advanced storage allows you to make the most of your cloud expenses while improving application performance. It also helps with compliance and data protection.
Dynamic Disc Pool
Dynamic Disc Pool technology (DDP) addresses the problem of RAID rebuild times and the potential increase in disk failure and reduced performance this may cause. DDP delivers prime storage solutions while maintaining performance. The technology can rebuild up to four times more quickly while featuring exceptional data protection. DDP allows you to group similar disks in a pool topology with faster rebuilds than RAID 5 or 6.
For more on monitoring disk performance and latency in NetApp environments, explore how LogicMonitor visualizes these metrics to optimize storage efficiency.
FAS
FAS (Fabric Attached Storage) is a unified storage platform in the cloud. FAS is one of the company’s core products. NetApp currently has six models of storage to choose from, allowing users to select the best model that meets their organization’s storage needs. These products consist of storage controllers with shelves made of hard disk enclosures. In some entry-level products, the storage controller contains the actual drives.
Flexpod
Flexpod is a type of architecture for network, server, and storage components. The components of a Flexpod consist of three layers: computing, networking, and storage. Flexpod allows users to select specific components, making it ideal for almost any type of business. Whether you’re looking for rack components or optimizing for artificial intelligence, Flexpod can help you put together the architecture your organization needs.
FlexCache
FlexCache offers remote simplified file distribution. It can also improve WAN usage with lower bandwidth costs and latency. You can distribute through multiple sites. FlexCache provides a more significant storage system ROI, improves the ability to handle workload increases, and limits remote access latency. It’s also easier to scale out storage performance with read-heavy applications. ONTAP Select running on 9.5 versions or later, FAS, and AFF support FlexCache.
OnCommand (OCI)
An OnCommand Insight Server (OCI) provides access to storage information and receives updates involving environment changes from acquisition units. The updates pass through a secure channel and then go to storage in the database. OCI can simplify virtual environments and manage complex private cloud systems. OCI allows analysis and management across networks, servers, and storage in both virtual and physical environments. It specifically enables cross-domain management.
OnCommand has two different Acquisition units. These are the Local Acquisition Unit (LAU), which you can install along with the OnCommand Insight Server, and the Remote Acquisition Unit (RAU). This one is optional. You can install it on a single remote server or several servers.
ONTAP
This is the operating system for hybrid cloud enhancement that helps with staffing, data security, and promoting future growth. New features for ONTAP include greater protection from ransomware, simplification for configuring security profiles, and more flexibility for accessing storage.
StorageGRID
If your organization has large data sets to store, StorageGrid is a solution that can help you manage the data cost-efficiently. StorageGrid offers storage and management for large amounts of unstructured data. You can reduce costs and optimize workflows when you place content in the correct storage tier. Some of the reviews for NetApp StorageGRID state that three of its best features are its valuable backup features, easy deployment, and cost-effectiveness.
Snapshot
Snapshots are designed to help with data protection but can be used for other purposes. NetApp snapshots are for backup and restoring purposes. When you have a snapshot backup, you save a specific moment-in-time image of the Unified database files in case your data is lost or the system fails. The Snapshot backup is periodically written on an ONTAP cluster. This way, you’ll have an updated copy.
Solidfire
Solidfire is one of NetApp’s many acquisitions, as it took over the company in January 2016. Solidfire uses the Element operating system for its arrays. This NetApp product provides all-flash storage solutions. SolidFire is not as successful as other products at NetApp; ONTAP, in particular, overshadows SolidFire. Some industry professionals may question how long SolidFire will continue as a NetApp product. So far, SolidFire is still a private cloud hardware platform.
Trident
Trident is an open-source project that can meet your container application demands. It utilizes Kubernetes clusters as pods. This offers exceptional storage services and allows containerized apps to consume storage from different sources. Trident provides full support as an open-source project and uses industry-standard interfaces. These interfaces include the Container Storage Interface.
NetApp’s integration with public cloud platforms
NetApp’s solutions are designed to support organizations working across hybrid and multi-cloud environments, offering seamless compatibility with major cloud providers like GCP and AWS. NetApp’s tools, including CVO and StorageGRID, enable efficient data management, transfer, and protection, ensuring that businesses can maintain control of their data infrastructure across platforms.
- CVO: CVO offers data management across cloud environments by combining NetApp’s ONTAP capabilities with public cloud infrastructure. This solution allows organizations to optimize cloud storage costs and manage data protection, compliance, and performance. For example, a company using CVO with GCP can streamline its data backup processes, reducing both costs and latency by storing frequently accessed data close to applications.
- StorageGRID: Designed for storing large amounts of unstructured data, StorageGRID enables multi-cloud data management with the flexibility to tier data across cloud and on-premises environments. By supporting object storage and efficient data retrieval, StorageGRID allows businesses to manage compliance and access requirements for big data applications. A healthcare organization, for example, could use StorageGRID to store and retrieve extensive medical records across both private and public cloud environments, ensuring secure and compliant access to data when needed.
With NetApp’s hybrid and multi-cloud capabilities, businesses can reduce the complexity of managing data across cloud platforms, optimize storage expenses, and maintain compliance, all while ensuring data accessibility and security across environments.
What are NetApp’s key terms?
To understand how NetApp works, it’s necessary to know some of its terminology and product selections. The following are some basic terms and products with brief definitions.
Aggregate
An aggregate is a collection of physical disks you can organize and configure to support various performance and security needs. According to NetApp, if your environment contains certain configurations, you’ll need to create aggregates manually. A few of these configurations include flash pool aggregates and MetroCluster configurations.
Cluster MTU
This feature enables you to configure MTU size by using an ONTAP Select multi-node cluster. An MTU is the maximum transmission unit size that specifies the jumbo frame size on 10 Gigabit interfaces as well as 1 Gigabit Ethernet. Using the ifconfig command, you can select the particular MTU size for transmission between a client and storage.
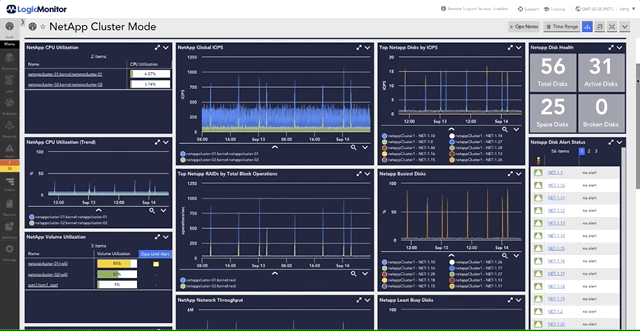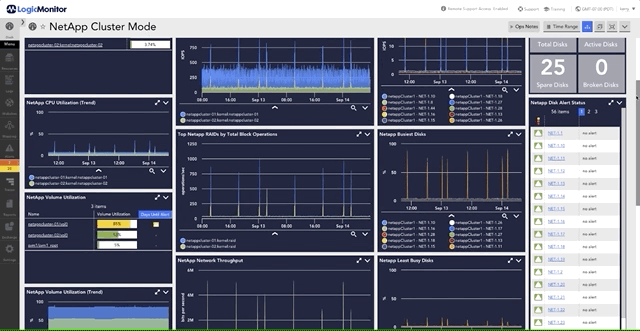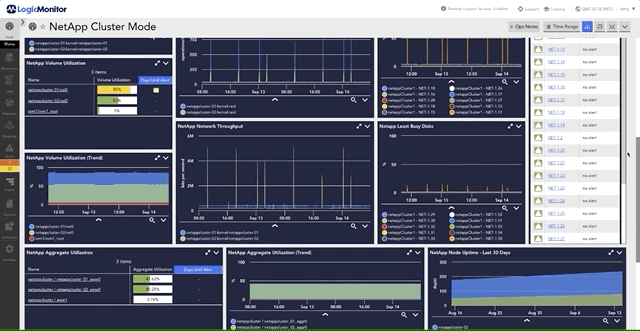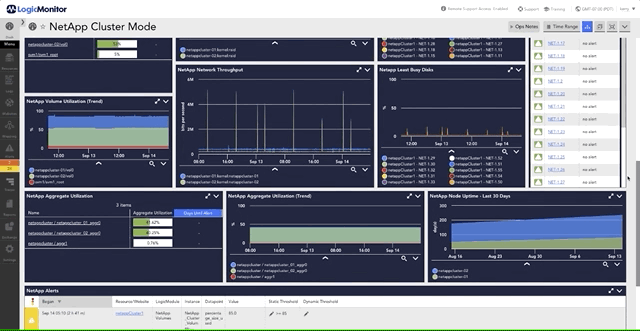
FlexVol Volume
FlexVol volumes are a type of volume that generally connects to each of its containing aggregates. Several FlexVol volumes can receive their storage sources from a single aggregate. Since these volumes are separate from the aggregates, you can dynamically change the size of each FlexVol volume without a disruption in the environment.
Initiator
An initiator is a port for connecting with a LUN. You can select an iSCSI hardware or software adapter or an FC. The ONTAP System Manager enables you to manage initiator groups. If you want to control which LIFs each initiator has access to, you can do this with portsets.
IOPS
IOPS measures how many Input/Output operations per second occur. You would generally use IOPS to measure your storage performance in units of bytes for read or write operations. You’ll sometimes need different IOP limits in various operations that are in the same application.
License Manager
This software component is part of the Deploy administration utility. This is an API you can use to update an IP address when the IP address changes. To generate a file, you need to use the License Lock ID (LLID) and the capacity pool license serial number.
LUN
LUNs are block-based storage objects that you can format in various ways. They work through the FC or iSCSI protocol. ONTAP System Manager is able to help you create LUNS if there is available free space. There are many ways you can use LUNs; for example, you might develop a LUN for a QTree, volume, or aggregate that you already have.
Multiple Cluster Systems
If you need an at-scale system for a growing organization, you’ll want to consider NetApp systems that have multiple clusters. A cluster consists of grouped nodes to create scalable clusters. This is done primarily to use the nodes more effectively and distribute the workload throughout the cluster. An advantage of having clusters is to provide continuous service for users even if an individual node goes offline.
ONTAP Select Cluster
You can create clusters with one, two, four, six, or even eight nodes. A cluster with only one node doesn’t produce any HA capability. Clusters with more than one node, however, will have at least one HA pair.
ONTAP Select Deploy
You can use this administration utility to deploy ONTAP Select clusters. The web user interface provides access to the Deploy utility. The REST API and CLI management shell also provide access.
Qtrees
Qtrees are file systems that are often subdirectories of a primary directory. You might want to use qtrees if you’re managing or configuring quotas. You can create them within volumes when you need smaller segments of each volume. Developing as many as 4,995 qtrees in each internal volume is possible. Internal volumes and qtrees have many similarities. Primary differences include that qtrees can’t support space guarantees or space reservations. Individual qtrees also can’t enable or disable snapshot copies. Clients will see the qtree as a directory when they access that particular volume.
Snapshot Copy
Snapshot copy is a read-only image that captures a moment-in-time of storage system volume. The technology behind ONTAP Snapshot enables the image to take up a minimum of storage space. Instead of copying data blocks, ONTAP creates Snapshot copies by referencing metadata. You can recover LUNS, contents of a volume, or individual files with a Snapshot copy.
SnapMirror
This replication software runs as a part of the Data ONTAP system. SnapMirror can replicate data from a qtree or a source volume. It’s essential to establish a connection between the source and the destination before copying data with SnapMirror. After creating a snapshot copy and copying it to the destination, the result is a read-only qtree or volume containing the same information as the source when it was last updated.
You will want to use SnapMirror in asynchronous, synchronous, or semi-synchronous mode. If at the qtree level, SnapMirror runs only in asynchronous mode. Before setting up a SnapMirror operation, you need a separate license and must enable the correct license on the destination and source systems.
Storage Pools
Storage pools are data containers with the ability to hide physical storage. Storage pools increase overall storage efficiency. The benefit is that you may need to buy fewer disks. The drawback is disk failure can have a ripple effect when several are members of the same storage pool.
System Manager
If you’re just beginning to use NetApp and need a basic, browser-based interface, you may want to consider the OnCommand System Manager. System Manager includes detailed tables, graphs, and charts for tracking past and current performance.
Discover the power of NetApp with LogicMonitor
NetApp provides valuable data and storage services to help your organization access and manage data throughout multi-cloud environments more efficiently. With various products and services, NetApp enables you to put together the data management and storage solutions that meet your organization’s needs.
As a trusted NetApp technology partner, LogicMonitor brings automated, insightful monitoring to your NetApp environment. Transition seamlessly from manual tracking to advanced automated monitoring and gain access to essential metrics like CPU usage, disk activity, and latency analysis—all without configuration work.
With LogicMonitor’s platform, your team can focus on strategic goals, while LogicMonitor ensures efficient and precise monitoring across your NetApp systems, including ONTAP.
At the heart of LogicMonitor’s monitoring solution is the LogicMonitor Collector, a crucial application that gathers device data and sends it to the LogicMonitor platform. This real-time monitoring feature tracks the health and performance of Collectors and ensures continuous data collection by sending alerts about potential issues before they escalate. When issues arise, understanding the Collector Status is key to quickly resolving them.
This guide walks through steps for troubleshooting issues related to the Collector Status, ensuring that the monitoring setup remains reliable and effective.
What is Collector Status?
Collector Status provides real-time insights into the health and performance of LogicMonitor Collectors. It tracks essential metrics such as CPU load, memory usage, and network connectivity, sending notifications to users about potential issues before they escalate into major problems. Regular monitoring of the Collector Status prevents downtime, optimizes performance, ensures continuous data collection, and gives the ability to personalize solutions.
Step 1: Check the Collector and Watchdog services
The first step in troubleshooting is to validate that the LogicMonitor Collector and Watchdog services are running properly on the host machine. These services are essential for maintaining communication between devices and the LogicMonitor platform. If either service is down, the status of the Collector will reflect this, and gaps in monitoring data may become apparent.
- Action: Verify that both services are active by checking the status on the host machine. If they are not running, attempt to restart them. If the services fail to start, investigate further by checking operating system logs or updating the services.
Learn more about troubleshooting and managing Collector services.
Step 2: Verify credentials and permissions
Incorrect credentials or insufficient permissions can cause the Collector to fail to communicate with your monitored devices, which will be reflected in the Collector Status. This is a common issue, particularly in Windows environments.
- Action: Ensure that the credentials the Collector and Watchdog services use have the correct permissions. The Collector service should have “Log on as a service” rights under the Local Policy/User Rights Assignment settings in the host OS. If not using an account on the same domain, ensure the local administrator credentials are correct by verifying wmi.user and wmi.password properties in LogicMonitor. This will help maintain a healthy Collector Status.
Step 3: Check the Collector connection to LogicMonitor servers
A common reason for a degraded Collector Status is connectivity issues. The LogicMonitor Collector needs to connect to LogicMonitor’s cloud servers over port 443 using HTTPS/TLS. If this connection is interrupted, the Collector cannot send data, and monitoring will be disrupted.
- Action: Test the connectivity from the Collector host to LogicMonitor’s cloud servers. Do this by accessing the LogicMonitor portal from a web browser on the Collector host. Ensure that firewall rules and whitelists (if using IP address whitelisting instead of DNS) are up to date to allow traffic over port 443. I
Get detailed instructions on monitoring Collector connectivity and health.
Step 4: Review antivirus software settings
Antivirus software can sometimes interfere with the Collector’s operation by blocking necessary files or processes. This can lead to a poor Collector Status as the Collector may not be able to perform its functions correctly.
- Action: Check antivirus software settings and ensure the LogicMonitor directory is added as an exclusion (C:\Program Files (x86)\LogicMonitor\ by default). This will prevent the antivirus from blocking the Collector’s operations, helping to maintain a positive Collector Status.
Step 5: Monitor Collector health with Collector Status
The Collector Status in LogicMonitor is the primary tool for monitoring the health and performance of Collectors. Regularly reviewing the Collector Status can help to identify potential issues, such as high CPU load, memory overuse, or connectivity problems, before they lead to downtime.
- Action: Regularly check the Collector Status in the LogicMonitor portal. Look for any warning or error messages related to load, memory, or failed polls, and address them promptly to keep monitoring infrastructure running smoothly.
Explore LogicMonitor’s guide to best practices for optimizing Collector performance.

Collector Status is a great place to check on Collector health. It can indicate potentially problematic load issues and LogicModules with abnormally high numbers of failed polls.


Collector Status is not intended to provide a complete view of Collector performance but is an excellent tool for quickly identifying the source of issues. It offers several features that help IT teams quickly pinpoint problems and get an overview of a Collector’s overall health:
- Highlighted issues: Instantly find issues that point to an area of concern that may impact the Collector’s health.
- Configuration check: Find potential issues with Collector configuration that may impact performance.
The Collector also tracks restarts and errors reported by Watchdog, which is very useful when looking for patterns that indicate problems.

Step 6: Set up resilient monitoring
To further protect the monitoring setup, consider implementing resilient monitoring strategies. This includes setting up a backup Collector or using an Auto-Balanced Collector Group to distribute the monitoring load across multiple Collectors. This helps maintain a healthy Collector Status and ensures that monitoring continues without interruption, even if one Collector goes down.
- Action: Evaluate the current monitoring setup and determine if adding a backup Collector or implementing Auto-Balanced Collector Groups would benefit the environment. These steps can significantly reduce the risk of downtime and improve your overall monitoring resilience.
LogicMonitor’s article, Collector Capacity, offers a broader understanding of how Collectors handle workloads.
Maintain a healthy Collector Status
Understanding and regularly checking the Collector Status ensures that LogicMonitor Collectors are performing optimally and providing continuous and reliable monitoring for IT infrastructures. Implementing the steps outlined in this troubleshooting guide can help resolve issues that arise and guide the setup of a resilient monitoring system that protects against future problems.
Microservices are the future of software development. This approach serves as a server-side solution to development where services remain connected but work independently. More developers are using microservices to improve performance, precision, and productivity, and analytical tools provide them with valuable insights about performance and service levels.
The argument for microservices is getting louder: Different teams can work on services without affecting overall workflows, something that’s not possible with other architectural styles. In this guide, we’ll take a deep dive into microservices by learning what they are, what they do, and how they benefit your team.
What are microservices?
In software development, microservices are an architectural style that structures applications as a collection of loosely connected services. This approach makes it easier for developers to build and scale apps. Microservices differ from the conventional monolithic style, which treats software development as a single unit.
The microservices method breaks down software development into smaller, independent “chunks,” where each chunk executes a particular service or function. Microservices utilize integration, API management, and cloud deployment technologies.
The need for microservices has come out of necessity. As apps become larger and more complicated, developers need a novel approach to development—one that lets them quickly expand apps as user needs and requirements grow.
Did you know that more than 85 percent of organizations with at least 2,000 employees have adopted microservices since 2021?
Why use microservices?
Microservices bring multiple advantages to teams like yours:
Scalability
Microservices are much easier to scale than the monolithic method. Developers can scale specific services rather than an app as a whole and execute bespoke tasks and requests together with greater efficiency. There’s less work involved because developers concentrate on individual services rather than the whole app.
Faster development
Microservices lead to faster development cycles because developers concentrate on specific services that require deployment or debugging. Speedier development cycles positively impact projects, and developers can get products to market quicker.
Improved data security
Microservices communicate with one another through secure APIs, which might provide development teams with better data security than the monolithic method. Because teams work somewhat in silos (though microservices always remain connected), there’s more accountability for data security because developers handle specific services. As data safety becomes a greater concern in software development, microservices could provide developers with a reliable security solution.
Better data governance
Just like with data security, where teams handle specific services rather than the entire app, microservices allow for greater accountability when complying with data governance frameworks like GDPR and HIPAA. The monolithic method takes more of a holistic approach to data governance, which can cause problems for some teams. With microservices, there’s a more specific approach that benefits compliance workflows.
Multiple languages and technologies
Because teams work somewhat independently of each other, microservices allow different developers to use different programming languages and technologies without affecting the overall architectural structure of software development. For example, one developer might use Java to code specific app features, while another might use Python. This flexibility results in teams that are programming and technology “agnostic.”
For example, see how we scaled a stateful microservice using Redis.
Did you know 76 percent of organizations believe microservices fulfill a crucial business agenda?
Microservices architecture
Microservice architecture sounds a lot more complicated than it is. In simple terms, the architecture comprises small independent services that work closely together but ultimately fulfill a specific purpose. These services solve various software development problems through unique processes.
A good comparison is a football team, where all players share the same objective: To beat the other team. However, each player has an individual role to play, and they fulfill it without impacting any of the other players. Take a quarterback, for example, who calls the play in the huddle. If the quarterback performs poorly during a game, this performance shouldn’t affect the other team members. The quarterback is independent of the rest of the players but remains part of the team.
Unlike monolithic architectures, where every component is interdependent, microservices allow each service to be developed, deployed, and scaled independently.
Did you know the cloud microservices market was worth 1.63 billion in 2024?
Microservices vs. monolithic architectures
When you’re considering a microservices architecture, you’ll find that they offer a lot of benefits compared to a traditional monolithic architecture approach. They will allow your team to build agile, resilient, and flexible software. On the other hand, monolithic software is inherently complex and less flexible—something it pays to avoid in today’s world of increasingly complex software.
So, let’s look at why businesses like yours should embrace microservices, and examine a few challenges to look out for.
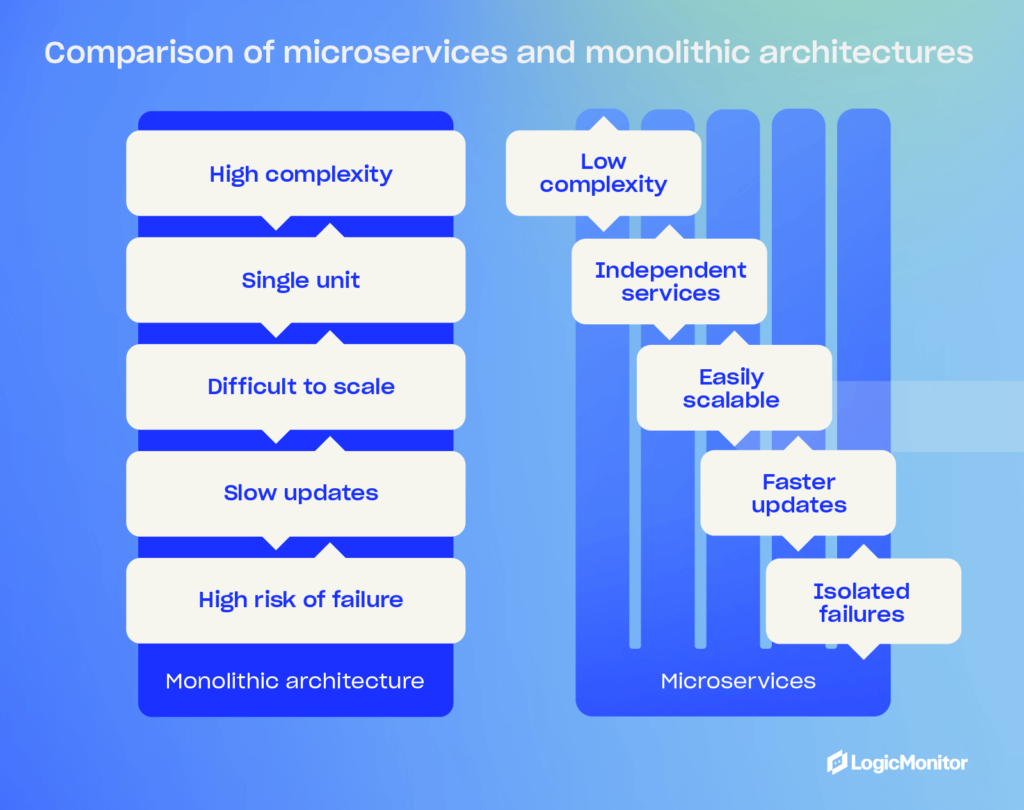
Microservices architecture advantages
- Agility and speed: By breaking your applications into smaller, independent services, you can speed up development cycles by allowing your teams to work on various services simultaneously, helping them perform quicker updates and release features faster.
- Resilience: Service independence and isolation improve your software’s overall stability since a service going offline is less likely to disrupt other services, meaning your application continues running while you troubleshoot individual service failures.
- Flexibility: Your team can use different technologies and frameworks for different services, allowing them to choose the best tools for specific tasks instead of sticking with a few specific technologies that may not be the right choice.
Monolithic architecture disadvantages
- Complexity and risk: When you build applications as single, cohesive units, your team needs to modify existing codes across several layers, including databases, front-ends, and back-ends—even when you only require a simple change. The process is time-consuming and risky, which adds stress to your team if they need to make regular changes, and a single change can impact entire systems.
- High dependency: When your application is made of highly dependent components, isolating services is more challenging. Changes to one part of a system can lead to unintended consequences across your entire application, resulting in downtime, impacted sales, and negative customer experience.
- Cost and inflexibility: Making changes to monolithic applications requires coordination and extensive testing across your teams, which means you’ll see a slower development process, potentially hindering your ability to respond quickly to problems and market demands.
Microservices in the cloud (AWS and Azure)
Perhaps the cloud is the most critical component of the microservices architecture. Developers use Docker containers for packaging and deploying microservices in private and hybrid cloud environments (more on this later.) Microservices and cloud environments are a match made in technological heaven, facilitating quick scalability and speed-to-market. Here are some benefits:
- Microservices run on different servers, but developers can access them from one cloud location.
- Developers make back-end changes to microservices via the cloud without affecting other microservices. If one microservice fails, the entire app remains unaffected.
- Developers create and scale microservices from any location in the world.
Various platforms automate many of the processes associated with microservices in the cloud. However, there are two developers should consider:
Once up and running, these systems require little human intervention from developers unless debugging problems occur.
AWS
Amazon pioneered microservices with service-based architecture many years ago. Now its AWS platform, available to developers worldwide, takes cloud microservices to the next level. Using this system, developers can break down monolithic architecture into individual microservices via three patterns: API-driven, event-driven, and data streaming. The process is much quicker than doing it manually, and development teams can create highly scalable applications for clients.
Azure
Azure is another cloud-based system that makes microservices easier. Developers use patterns like circuit breaking to improve reliability and security for individual services rather than tinkering with the whole app.
Azure lets you create APIs for microservices for both internal and external consumption. Other benefits include authentication, throttling, monitoring, and caching management. Like AWS, Azure is an essential tool for teams that want to improve agile software development.
Did you know the global cloud microservices market is expected to grow from USD 1.84 billion in 2024 to USD 8.33 billion by 2032, with a CAGR of 20.8%?
How are microservices built?
Developers used to package microservices in VM images but now typically use Docker containers for deployment on Linux systems or operating systems that support these containers.
Here are some benefits of Docker containers for microservices:
- Easy to deploy
- Quick to scale
- Launched in seconds
- Can deploy containers after migration or failure
Microservices in e-Commerce
Retailers used to rely on the monolithic method when maintaining apps, but this technique presented various problems:
- Developers had to change the underlying code of databases and front-end platforms for customizations and other tweaks, which took a long time and made some systems unstable.
- Monolithic architecture requires services that remain dependent on one another, making it difficult to separate them. This high dependency meant that some developers couldn’t change services because doing so would affect the entire system, leading to downtime and other problems that affected sales and the customer experience.
- Retailers found it expensive to change applications because of the number of developers that required these changes. The monolithic model doesn’t allow teams to work in silos, and all changes need to be tested several times before going ‘live.’
Microservices revolutionized e-commerce. Retailers can now use separate services for billing, accounts, merchandising, marketing, and campaign management tasks. This approach allows for more integrations and fewer problems. For example, developers can debug without affecting services like marketing and merchandising if there’s an issue with the retailer’s payment provider. API-based services let microservices communicate with one another but act independently. It’s a much simpler approach that benefits retailers in various niches.
Real-world examples of microservices in e-commerce
If you aren’t sure if microservers are the best choice for your company, just look at some of the big players that use microservices to serve their customers worldwide. Here are a few examples that we’ve seen that demonstrate how you can use microservices to build and scale your applications.
Netflix
Netflix began transitioning to microservices after a major outage due to a database failure in 2008 that caused four days of downtime, which exposed the limitations of its monolithic architecture. Netflix started the transition to microservices in 2009 and completed the migration to microservices in 2011. With microservices performing specific functions, such as user management, recommendations, streaming, and billing, Netflix can deploy new features faster, scale services independently based on demand, and improve the overall resilience of its platform.
Amazon
Amazon shifted to microservices in the early 2000s after moving to service-oriented architecture (SOA) to manage its large-scale e-commerce platform. Amazon’s microservices helped it handle different aspects of the company’s platform, such as order management, payment processing, inventory, and customer service. This helped Amazon innovate rapidly, handle massive traffic, and maintain uptime—even during peak shopping periods like Black Friday.
Spotify
Spotify uses microservices to support its platform features like playlist management, search functionality, user recommendations, and music streaming. Spotify’s approach allows the company to innovate quickly, scale individual services based on user demand, and improve the resilience of its platform against failures. Spotify implemented microservices between 2013 and 2014 to handle increasing user demand and feature complexity as it expanded globally.
Airbnb
Airbnb employs microservices to manage its booking platform services for property listings, user authentication, search, reservations, and payments. Implemented between 2017 and 2020, microservices helped Airbnb scale its services as the company experienced massive growth. Airbnb was able to improve performance based on user demand and deploy features more quickly.
PayPal
Since early 2013, PayPal has used microservices to handle payment processing, fraud detection, currency conversion, and customer support services. Microservices helps PayPal offer high availability, improve transaction processing times, and scale its services across different markets and geographies.
How do you monitor microservices?
Various platforms automate the processes associated with microservices, but you will still need to monitor your architecture regularly. As you do, you’ll gain a deeper understanding of software development and how each microservice works with the latest application metrics. Use them to monitor key performance indicators like network and service performance and improve debugging.
Here’s why you should monitor microservices:
- Identify problems quickly and ensure microservices are functioning correctly.
- Share reports and metrics with other team members and measure success over time.
- Change your architecture to improve application performance.
The best monitoring platforms will help you identify whether end-user services are meeting their SLAs and help teams drive an optimized end-user experience.
Tools like LM Envision provide comprehensive monitoring solutions that help you maintain high-performance levels across all your services.
Did you know the cloud microservices market could reach $2.7 billion by 2026?
Best practices for implementing microservices
As you’ve seen above, microservices will offer many benefits to your business. But they aren’t something you can just substitute in and expect to run flawlessly. Here are a few best practices that will help you implement microservices in your application:
- Start small: Switching to microservices isn’t something you should do all at once. Start small by breaking your application down into smaller components and do it a little at a time. This approach will allow your team to learn and adapt as they go.
- Use automation tools: Use CI/CD pipelines to automate the deployment and management of microservices. Automation reduces the chance of your team making mistakes and speeds up repetitive deployment processes to reduce development time.
- Ensure robust monitoring and logging: Implement comprehensive monitoring and logging solutions so your team can track the performance of each microservice and quickly identify any issues.
- Prioritize security: Each service can become a potential attack entry point with microservices and may be harder to secure and monitor for your team because of the more distributed architecture. Implement strong authentication, encryption, and other security measures to protect the system.
- Maintain communication between teams: Since microservices allow your team to work independently on different parts of the application, it’s crucial to maintain clear communication and collaboration to ensure that all services work together seamlessly.
What are the benefits of microservices? Why do they exist today?
Now that we’ve looked at microservices and a few primary benefits, let’s recap some of them to learn more about why they exist today.
- Greater scalability: Although microservices are loosely connected, they still operate independently, which allows your team to modify and scale specific services without impacting other systems.
- Faster development: Your team can move faster by working on individual services instead of a monolithic application, meaning you can focus on specific services without worrying as much about how changes will impact the entire application.
- Better performance: You can focus on the performance of individual services instead of entire applications, changing and debugging software at a smaller level to learn how to optimize for the best performance.
- Enhanced security and data governance: Using secure APIs and isolated services will help your team improve security by controlling access to data, securing individual services, and monitoring sensitive services—helping facilitate compliance with security regulations like HIPPA and GDRP.
- Flexible technology: You aren’t tied to specific programming languages, frameworks, databases, and other technologies with microservices, which means you can pick the best tool for the job for specific tasks.
- Cloud-native capabilities: Platforms like AWS and Azure make creating and managing microservices easier, which means your team can build, deploy, and manage software from anywhere in the world without having a physical infrastructure.
- Quick deployment: Software like Docker is available to make deploying microservices easy for your team, helping them streamline deployment and ensure microservices run in the exact environment they were built in.
The future of microservices
Microservices are a reliable way to build and deploy software, but they are still changing to meet the evolving needs of businesses. Let’s look at what you can expect to see as microservices continue to evolve in the future.
Serverless Architecture
Serverless architecture allows you to run microservices without managing any other infrastructure. AWS is already developing this technology with its Lambda platform, which takes care of all aspects of server management.
PaaS
Microservices as a Platform as a Service (PaaS) combines microservices with monitoring. This revolutionary approach provides developers with a centralized application deployment and architectural management framework. Current PaaS platforms that are well-suited for microservices are Red Hat OpenShift and Google App Engine.
In the future, PaaS could automate even more processes for development teams and make microservices more effective.
Multi-Cloud Environments
Developers can deploy microservices in multiple cloud environments, which provides teams with enhanced capabilities. This can mean using multiple cloud providers, and even combining cloud services with on-prem infrastructure (for cases when you need more control over the server environment and sensitive data).
“Microservices related to database and information management can utilize Oracle’s cloud environment for better optimization,” says technology company SoftClouds. “At the same time, other microservices can benefit from the Amazon S3 for extra storage and archiving, all the while integrating AI-based features and analytics from Azure across the application.”
Service mesh adoption
Service meshes are becoming critical for managing more complex microservice ecosystems. They will provide your team with a dedicated infrastructure for handling service-to-service communication. This infrastructure will help improve monitoring, incident response, and traffic flow.
DevOps and AIOps
The integration of DevOps and AIOps with microservices and ITOps will help streamline development and operations. For example, new DevOps tools will help developers automate many deployment tasks instead of manually configuring individual environments. AIOps will also help your team, as it uses AI and machine learning to improve monitoring and reduce the time your team needs to look through data to find problems.
Event-driven architecture
Event-driven architecture is gaining more popularity among microservices because it allows for more de-coupled, reactive systems that are easier to manage. It allows them to process real-time data and complex event sequences more efficiently.
Advanced observability
As multi-cloud environments become more common, more advanced tools are needed to monitor these environments. Hybrid observability solutions will help your team manage hybrid environments to gather performance metrics (CPU usage, memory usage) about your services in a central location and send alerts when something goes wrong. Advanced observability solutions also use AI to monitor environments to ensure your team only sees the most relevant events and trace information that indicates a potential problem.
Before You Go
Microservices have had an immeasurable impact on software development recently. This alternative approach to the monolithic architectural model, which dominated software development for years, provides teams a streamlined way to create, monitor, manage, deploy, and scale all kinds of applications via the cloud. Platforms like AWS and Azure facilitate this process.
As you learn more about software development and microservices, you’ll discover new skills and become a more confident developer who solves the bespoke requirements of your clients. However, you should test your knowledge regularly to make every development project successful.
Do you want to become a more proficient software developer? Microservices Architecture has industry-leading self-assessments that test your microservice readiness, applicability, and architecture. How well will you do? Get started now.
The Java Management Extensions (JMX) framework is a well-known tool for any experienced Java developer. The purpose of the JMX framework is to simplify the management of local and remote Java applications while providing a user-friendly interface.
The primary advantages of the JMX framework are that it’s highly reliable, scalable, and easy to configure. However, it’s also known for introducing the concept of MBeans, which unlocks the capacity for real-time Java application management. Here’s a closer look at the JMX framework and JMX monitoring.
Contents
- What Is JMX?
- What Is JMX Monitoring?
- What Are MBeans?
- How Is Data Collected?
- Comparing JMX Monitoring Solutions
- Why Should I Monitor Java Applications?
- Why Is JMX Monitoring Important for DevOps?
- Conclusion
What Is JMX?
Since Java 1.5, the Java Management Extensions (JMX) framework has been widely adopted as a user-friendly infrastructure solution to help manage both remote and local Java applications. Since JMX introduced the concept of MBeans, it helped to revolutionize Java application management and bring real-time management tools into the picture.
The features of JMX include the ability to:
- Easily manage Java apps and services without making heavy investments of time or resources. Since JMX needs only a core managed object server, you can manage your Java apps without really impacting how they are designed.
- Scale your management architecture as needed, without unnecessary complexity. Once you have set up the JMX agent service, it will run independently. Through this component-based approach, you can scale your JMX solution almost infinitely with hardly any changes necessary to the program itself.
- Leverage flexible and dynamic solutions to help you stay on top of future concepts. With the ability to use emerging technologies, you can stay ahead of the competition without completely reworking your solution every time a new approach or technology is released.
- Focus on managing your apps and services without a lot of legwork. You can certainly utilize JMX within a distributed environment, but the APIs make it simple to add management tools for your services, applications, systems, and networks.
As you can see, there are many reasons to utilize JMX if you’re currently working with Java applications. However, one of the best features of JMX is known as JMX monitoring. So, let’s take a closer look at how you can leverage it.
What Is JMX Monitoring?
The purpose of the JMX framework is to support monitoring and management initiatives for Java applications. By creating a generic system for monitoring Java applications, JMX monitoring unlocks some fundamental tools, such as notifications that can alert a team when an app needs attention or when the state of an application changes.
In addition to notifications, JMX monitoring can also help improve observability by exposing run time metrics and revealing resource utilization and allocation. One of the most crucial components to understanding JMX monitoring is the MBeans that help developers recognize and organize resources on their Java Virtual Machines (JVMs).
Overall, there are three tiers of components involved in JMX monitoring:
- The probe or instrumentation level is made up of MBeans wrapped around individual resources.
- The agent level consists of the MBean Server that exposes MBeans to applications on the next layer.
- The management level is where the connectors exist that allow your remote applications to access the MBean Server for monitoring and management purposes.
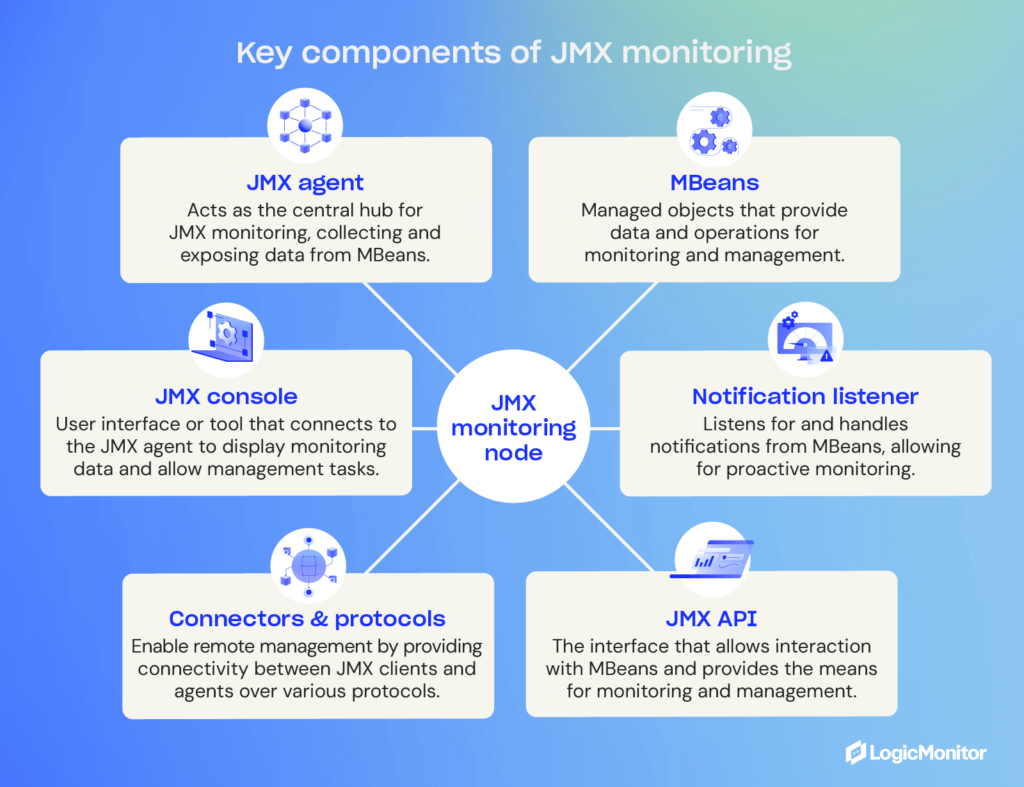
With these things in mind, here’s a more thorough explanation of how MBeans work and what developers can do with them to improve the monitoring and management of their Java applications.
What Are MBeans?
Managed Beans, or MBeans, form the foundation for JMX monitoring. The purpose of an MBean is to represent a resource within a Java Virtual Machine (JVM) to make it easier to configure and utilize. Within the JMX console, developers can expose a resource/MBean using a JVM port. From the console, developers can also group your MBeans into domains to help them easily track where all of their resources belong.
When looking at a Java Virtual Machine (JVM), you’ll generally see multiple domains, each with many MBeans assigned to it. For instance, a Java application using tomcat might have domains named Catalina and Java.lang. The former would include all resources (MBeans) for the Apache tomcat container known as Catalina, and the latter would contain all of the MBeans for the JVM run-time.
Depending on how a team manages things, they can choose to create custom domains for individual applications. This flexibility is important because today’s applications have very different requirements, with some requiring only a small footprint and others needing significant resources. While teams can optimize applications themselves during development, optimizing a JVM run-time and container is often handled after the fact.
When it comes to run-time and container optimization for Java apps, many developers might already be familiar with how to alter heap size or garbage collection, but MBeans can also play a role by helping them to allocate resources where they’re needed most.
How Is Data Collected?
Now that you understand the big picture overview of how JVM monitoring works and what MBeans serve to do, it’s also worth explaining how data is collected within Java Virtual Machines (JVMs).
The technical explanation involves some mostly unseen components, including MBeans and an MBean Server. The MBeans themselves take on the role of Java wrappers for components, apps, devices, and services within your network. Meanwhile, the MBean Server is where you can find and manage the resources that the MBeans represent.
Therefore, the MBean Server is the central focus of your JMX monitoring endeavor. If you want to get technical, a JMX agent consists of the MBean Server and the services necessary to handle the MBeans, such as an application performance monitoring (APM) solution. This setup keeps your resources independent of whatever infrastructure you use to manage them, which provides added flexibility.
If you’re using remote management tools, there are standard connectors (known as “JMX connectors”) that you can use to connect things together regardless of communication protocols. This means that you can use JMX connectors to use systems and apps that are not compatible with JMX specifically, as long as they support JMX agents.
Comparing JMX Monitoring Solutions
Once JMX agents are in place, you’re one step closer to easily managing and monitoring your Java applications. However, another important part of the process is deciding which monitoring solution you wish to use. Some of the most popular include:
- JConsole: Works alongside Java Management Extensions for both remote and local applications but is more ideal for development and prototyping than live deployments due to its intense resource consumption. Still, JConsole provides a wealth of information, including uptime, live threads, peak, etc.
- JMX Console: This management console is used by JBoss and allows developers to tap into the raw data produced by MBeans and unlocks the option to start or stop components and complete simple tasks. Keep in mind that JBoss is an open-source middleware solution provided by Red Hat, but a paid subscription is available for extra documentation and support.
- JManage: If you’re working with distributed applications, JManage is an open-source solution that’s worth considering, and it offers both web-based and command-line interface tools. It also supports an SNMP network along with JMX. The team behind JManage strives to offer a solution suitable for managing entire production environments.
- ManageEngine Applications Manager: If you’re interested in an on-premises paid software package, ManageEngine is comprehensive enough to enable entire IT departments and DevOps teams to implement JMX monitoring on any Windows or Linux server. A professional and enterprise edition is available, depending on a client’s budget and requirements.
- AppDynamics: Another paid solution, AppDynamics can provide additional flexibility since it is web-based. This platform is compatible with MBeans and can compile detailed activity reports for all your Java apps. Multiple tiers are available to fit various business sizes. This platform is part of the Cisco corporation and is widely trusted by enterprises.
- LogicMonitor: We use LogicMonitor to monitor our own infrastructure using JMX metrics. Since it’s so customizable, we’re able to track individual processes for particular microservices to get an overall idea of the service’s health and performance. It can be really useful for knowing when things go wrong (hello alerts!) and for helping unlock bottlenecks (hello dashboards!).
Depending on your needs and preferences (e.g., on-premises versus web-based or open-source versus paid), there are several other JMX monitoring solutions on the market. You do your research to make sure that investing in this area is worthwhile and that you know what you want to achieve going forward.
Why Should I Monitor Java Applications?
There are countless reasons to monitor your Java applications, but the most significant advantage is unlocking a heap of performance metrics that can help you fine-tune your JVMs and applications to make sure you’re making the most of all resources available to you.
While many developers are familiar with how to configure garbage collection or other settings to help boost the performance of their Java apps, learning to use the JVM framework will take them that much farther when it comes to optimization.
If you’re on the fence about using JVM monitoring to keep tabs on your Java applications, here are some practical reasons and considerations to keep in mind:
- Through monitoring, you can identify issues and potential issues sooner, giving you the best opportunity to correct them before they harm your end-users.
- By revealing the number of resources being consumed by your applications and understanding specific metrics and usage patterns, you can help avoid downtime and delays by allocating more resources when and where they’re needed.
- In the case of applications with a smaller footprint that don’t require a lot of resources, you can improve resource utilization across the board by taking unused resources away and allocating them elsewhere.
- The right metrics can help reveal bottlenecks and room for improvement, allowing you to speed up applications and improve the end-user experience.
Overall, there are countless reasons to pursue Java application monitoring and very few reasons not to. Especially when using JMX monitoring, which is relatively easy to use and implement, your business is likely to notice far more improvements and advantages than it will negative impacts on staff or internal resources.
Why Is JMX Monitoring Important for DevOps?
DevOps teams rely on powerful monitoring tools to better understand how development work behind-the-scenes impacts operations and vice versa. Monitoring tools like JMX can reveal opportunities to boost operational performance by re-evaluating the development processes that negatively impact an application.
Likewise, JMX monitoring can reveal information to the operational team about where future development projects may be necessary or tell the development team how operations are utilizing (or not utilizing) an app. Altogether, JMX monitoring provides numbers that increase observability and helps DevOps work together to achieve better outcomes.
Conclusion
Fine-tuning Java performance has long been a focus of Java developers everywhere, but there are few approaches that don’t require heavy time and resource investments. That’s why combining JMX with the correct monitoring tool is one of the easiest ways to give your team a headstart on understanding and improving the performance of your Java apps.
Whether you’re hoping to better allocate resources to help you keep scaling up, set up notifications to minimize negative end-user experiences, or keep an eye on the numbers to ensure continued success, JMX monitoring offers a suite of tools that can help you get there with ease.
If you are running Java applications, there are a few reasons not to use JMX monitoring. Thanks to its ease of use and plentiful documentation, your team will likely find that implementing and utilizing JMX monitoring is far easier than any manual processes you may already have in place — and your results will improve ten-fold.
HAProxy (High Availability Proxy) is free, open-source software that acts as a load balancer and proxy for managing TCP and HTTP traffic, ensuring reliable performance and high availability. Known for its speed and efficiency, HAProxy provides high availability by distributing incoming web traffic across multiple servers, preventing overloads at startup, and improving overall reliability.
The tool’s popularity has grown among developers and network engineers due to the volume of features available, which help reduce downtime and manage web traffic. This article discusses those features, as well as uses, load-balancing techniques, and key features of 2.7.0, the latest version of HAProxy.
HAProxy includes reverse proxy and load-balancing capabilities for HTTP-based applications and TCP-based applications. Load balancing involves routing traffic to servers based on pre-configured rules, such as looking for high-performance servers with the least amount of traffic or telling proxies to send connections to multiple servers.
Why use HAProxy?
HAProxy also provides SSL termination, health checks, and detailed logging capabilities, along with its load-balancing features. This open-source software is ideal for websites and web applications that experience high volumes of traffic or traffic that spikes on occasion.
As such, many large organizations prefer HAProxy for its efficiency, scalability, and strong supportive community. It simplifies the management experience and reduces downtime by persistently load-balancing heavy traffic, which increases availability for applications and network layers, improving the user experience.
Top reasons to use HAProxy
- Scalability: Handles increased traffic without compromising performance
- Reliability: Trusted by organizations like JPMorgan Chase & Co. and Boeing, the largest aerospace company in the world (HG Insights)
How does HAProxy work?
HAProxy can be installed free using a system’s package manager or as a Docker container.
- Frontend and backend setup: Configure HAProxy by defining the front end (receiving traffic) and backend (managing servers). You can set rules to direct traffic to specific servers based on IP addresses, ports, or HTTP load-balancing algorithms.
- Traffic management: Intelligently routes traffic based on configurations, ensuring optimal server usage and reliability.
HAProxy One offers a range of tools and platforms that enhance the benefits of HAProxy’s free proxy and load-balancing software.
Load balancing techniques
Load balancing in a web application environment depends on the type of load balancing used.
- Web server load balancing (layer 4): The simplest load balancing solution for multiple web servers is layer 4, or transport layer, load balancing. This setup uses a load balancer, a predefined range of IP addresses, and a port to determine where to route traffic, allowing multiple servers to respond to user requests efficiently.
- Application server load balancing (layer 7): Layer 7 load balancing routes requests to different backend servers, depending on requests, and requires more complex rules to connect user requests to the correct backend servers. For example, you might house blog articles on one server while you host an e-shop page on another. So, a request for a blog article will be routed through a different server than a request for an e-shop product, even though the requests are generated from the same website.
- Reverse proxy: Reverse proxies sit between applications and backends to ensure user requests reach appropriate servers. They also provide security, reliability improvements, and traffic management.
Key features of HAProxy
Due to its extensive features, HAProxy is preferred over alternative proxies like NGINX and LoadMaster.
- HTTP/2 protocol support: Enhances web performance
- SSL/TLS termination: Improves security by managing encryption and decryption
- Detailed logs: Offers comprehensive logs for monitoring and observability
- RDP cookie support: Supports secure, reliable sessions
- CLI for management: Provides in-depth server management capabilities
Implementing HAProxy: A step-by-step guide
Step 1: Install HAProxy
- Download and install via package manager or Docker.
- Opt for the HAProxy One version if additional features are needed.
Step 2: Configure the frontend and backend
- Define the IP addresses and ports for the frontend.
- Set up the backend servers and the rules for routing traffic.
Step 3: Select load-balancing algorithms
- Based on traffic needs, choose an algorithm like Roundrobin or Leastconn. Roundrobin is the default load-balancing algorithm that selects servers in a specific order, and Leastconn is an alternative algorithm that searches for servers with the fewest connections.
Step 4: Enable SSL/TLS termination
- Configure SSL settings to ensure secure traffic handling.
HAProxy vs. other solutions
When evaluating load balancers and proxy solutions, it is important to choose one that best fits the specific infrastructure needs. HAProxy, NGINX, and LoadMaster are among the top contenders, each offering distinct features that cater to different operational demands.
HAProxy vs. NGINX
Both HAProxy and NGINX are popular choices for managing web traffic, but they excel in different areas.
- Performance: HAProxy is optimized for low-latency environments, making it ideal for applications that require real-time responsiveness and high availability. In contrast, NGINX is better suited for caching and delivering static content, offering a simpler solution for web applications that prioritize speed over complexity.
- Logging: One of HAProxy’s major advantages is its detailed logging capabilities. For environments that require deep traffic analysis and precise monitoring, HAProxy provides comprehensive logs that track each request and connection. NGINX, while effective, offers more basic logging, which may not be sufficient for enterprises needing extensive traffic visibility.
- Configuration complexity: HAProxy offers more advanced configuration options, allowing users to customize traffic routing based on a wide range of conditions. This flexibility comes with increased complexity, making it a better fit for organizations with dedicated DevOps teams or advanced networking needs. On the other hand, NGINX provides a simpler, more beginner-friendly configuration process, making it an appealing choice for smaller projects or businesses with less demanding requirements.
HAProxy vs. LoadMaster
The distinction between HAProxy and LoadMaster is open-source flexibility and proprietary convenience.
- Flexibility: As an open-source solution, HAProxy allows full customization, enabling businesses to tailor the tool to their specific needs without paying for additional features or upgrades. This makes HAProxy particularly attractive to organizations that want to maintain control over their infrastructure. In contrast, LoadMaster, a proprietary tool, provides pre-configured solutions that are easier to deploy but may lack the flexibility needed for more complex environments.
- Cost-Effectiveness: HAProxy’s open-source nature means it can be implemented at no cost, regardless of the scale of operations. For businesses that need to manage large volumes of traffic without the burden of licensing fees, HAProxy presents a cost-effective solution. LoadMaster, however, is a paid option that includes professional support and additional features. While this may benefit enterprises that prioritize customer support and streamlined implementation, it can become costly, especially as traffic demands grow.
Real-world use cases
The power of HAProxy is demonstrated by organizations like GitHub, which rely on it to manage millions of concurrent connections efficiently. In these large-scale environments, HAProxy’s ability to handle complex configurations and provide real-time performance metrics far surpasses the capabilities of NGINX and LoadMaster without significant customization.
Which to choose?
Ultimately, HAProxy stands out as the optimal choice for organizations looking for maximum flexibility, scalability, and a robust feature set to manage high volumes of traffic. For environments with static content or simpler traffic needs, NGINX may be a more suitable option. LoadMaster offers a more simplified, pre-configured solution but may be costly, particularly for enterprises looking to scale.
Community support and resources
HAProxy’s community support and resources are vast, offering many user options, from official documentation to active community forums. With a HAProxy One subscription, users can benefit from expanded paid support options.
HAProxy supports users of current and latest versions and assists in critical fixes on any version. Documentation, including configuration tutorials and detailed manuals, is available on the HAProxy website, and the HAProxy blog offers helpful articles that you can filter according to specific inquiries. Current HAProxy One subscribers can contact support through the HAProxy Portal, providing convenient access to assistance.
Conclusion
HAProxy is a powerful, scalable solution for managing heavy or unpredictable web traffic. As a free, open-source tool, it provides smaller organizations the same reliability and performance enjoyed by large enterprises like JPMorgan Chase & Co. and Boeing. Implementing HAProxy is a strategic move for any business looking to enhance its web infrastructure’s reliability and performance.
Azure Stack HCI (hyperconverged infrastructure) is a robust solution that integrates Windows and Linux virtual machines (VMs) or containerized workloads. It can do this with seamless connectivity to Microsoft Azure for enhanced cloud-based services, comprehensive monitoring, and streamlined management.
This hybrid solution modernizes on-premises data centers by integrating them with cloud services for improved performance, scalability, and security.
How Azure Stack HCI works in cloud computing
With a hybrid cloud approach, your business can take control of its cloud journey, seamlessly integrating on-premises hardware with cloud services at a pace that suits your unique needs and timelines. This is thanks to seamless integration with Azure services like Microsoft Entra ID (formerly Azure Active Directory), Azure Monitor, Azure Backup, and more.
This integration ensures a consistent experience across on-premise and cloud infrastructures. You use the same management tools as an administrator across all your services. As a result, Azure Stack HCI is one of the fastest ways to get up and running with cloud computing.
This also means there can be significant cost savings when using Azure Stack HCI instead of making a hard switch from on-premise hardware to the cloud. At implementation time, you can use existing servers or commodity hardware, and then you can gradually move to cost-effective cloud solutions.
Beyond these benefits, Azure Stack HCI offers robust security features. With hyper-converged infrastructure, you can easily achieve virtual machine encryption and network micro-segmentation. Compared to implementing the same functionality in hardware, you can more easily manage HCI solutions and be more cost-effective.
How does Azure Stack HCI work?
Azure Stack HCI works by combining the functionality of traditional hardware elements (computing, storage, networking) into a single HCI solution with virtualization. On a practical level, you can administer all of these components through the Windows Admin Center.
Windows Admin Center is a web-based management console for managing a complete IT infrastructure. Since components like networking and storage are virtualized in an HCI environment, it’s much faster and less expensive to get up and running compared to the old ways of buying hardware, installing it, and maintaining it.
So, if an IT administrator wants to deploy a new instance of Microsoft SQL Server, creating a new virtual machine using storage from the Azure cloud is effortless. Similarly, you can quickly deploy a Docker application in a new Linux instance.
The tight integration with other Azure services simplifies the setup of other critical components, like authentication against Entra ID and defining network topology. With all the essential tasks of managing an IT environment available at a sysadmin’s fingertips, it empowers an organization to deploy new solutions rapidly.

Why choose Azure Stack HCI?
Azure Stack HCI offers a robust set of benefits that make it an excellent choice for organizations looking to modernize infrastructure and take advantage of hybrid cloud computing. Here are a few of the key benefits companies can expect to see:
- Hybrid cloud infrastructure: Offers seamless integration between on-premise infrastructure and cloud services, allowing organizations to maintain control over sensitive data while still taking advantage of cloud capabilities.
- Edge computing capabilities: Process data closer to the source, reducing latency and improving the performance of edge applications.
- Azure service integration: Get integration with various Azure services that make life easier, like Azure Backup, Azure Security Center, Azure Monitor, and others.
- Cost management and optimization: Allows organizations to use existing hardware to manage costs and a flexible pricing model that helps them grow into their cloud infrastructure.
- Robust security and compliance: Includes advanced security features like shielded virtual machines, encrypted networks, and Security Center integrations to help organizations protect their data and comply with regulations.
- Scalability and flexibility: Allows teams to easily scale their resource usage based on current needs and quickly adapt when the situation changes.
- Performance enhancements: Includes technology like Storage Spaces Direct and Software-Defined Networking to deliver high performance to both traditional and cloud environments.
The key features of Azure Stack HCI
HCI technologies greatly simplify security, scalability, and management. However, Azure Stack HCI’s hybrid cloud functionality makes it stand out from the crowd. With built-in integration with Microsoft’s Azure cloud service, you can easily transition from on-premise, hardware-defined infrastructure to a modern cloud-based environment.
Azure Stack HCI offers all the standard features of HCI solutions.
Virtualization
Two popular virtualization options Azure HCI offers are Hyper-V and containerization. Hyper-V allows for multiple virtual machines on the same server, while containerization allows teams to set up containerized workflows using the Azure Kubernetes Services (AKS) and similar software.
Software-defined infrastructure
Azure HCI also allows organizations to use software to define the infrastructure for networking and storage, where the configuration is abstracted away from the underlying hardware. These features allow teams to change infrastructure in real-time and programmatically based on current needs without investing in new hardware, licenses, and other expenses.
Edge computing
Edge computing allows the deployment and management of workloads closer to data generation points, reducing system latency and performance. Azure HCI includes Azure Arc, allowing organizations to connect their management services to on-premise, edge, and cloud services.
Security
Azure HCI comes secure out of the box, including consistent Secure Boot, UEFI, and TPM settings. It also contains security features that make things easier:
- Windows admin security tool
- Device and credential guard
- Bitlocker and SMB encryption
- Windows Defender antivirus
Azure HCI also has resources to help organizations comply with security standards, including PCI, HIPPA, and FIPS.
Simple management
Azure HCI offers an easy management portal for organizations to set up and modify their IT infrastructure. The Azure Portal gives an overview of HCI clusters, allowing teams to monitor systems at scale and manage Azure Services. Windows Admin Center is also available, giving teams the ability to manage individual virtual machines and edge services. Additionally, it provides many resources to collect resource metrics to see what resources your environment uses.
Performance optimization
Azure HCI offers many performance tools to help teams manage high-demand environments. It offers many solutions that help teams monitor performance across their infrastructure and increase performance. Some common performance tools available are high-performance disks for quick file access and data optimization and GPU partitioning for AI and machine learning jobs.
Azure Stack HCI management and deployment options
While the Windows Admin Center greatly simplifies IT deployments, Azure Stack HCI offers other flexible management options. Depending on your company’s existing cloud footprint and the abilities of your sysadmins, some of the other management and deployment options might be a better fit.
For example, organizations already using some Azure cloud services can use Azure Portal to manage their Azure Stack HCI components. Administrators experienced with Microsoft’s PowerShell can also use that environment to create programmatic and script deployment and management tasks.
Azure Stack HCI supports a specialized form of scripts known as Deployment Scripts, which provide advanced deployment automation options. This can be especially handy for larger organizations that want to scale their Azure Stack HCI footprint faster.
Companies that invest in virtualization solutions can also utilize some of their preexisting tools, including VMWare Center and System Center. The ability to use the tools that administrators are already familiar with is another reason that Azure Stack HCI can be a cost-effective way to migrate your organization’s infrastructure into the cloud.
Deploying Azure Stack HCI
Deploying Azure HCI will require some basic information:
- Server name
- Domain name
- Computer account names
- Organizational unit (OU)
- Static IP address
- RDMA networking
- VLAN ID
- Site names (for stretched clusters)
Steps to deploy Azure Stack HCI
There are several steps to deploy Azure HCI once you make a plan and gather the data for deployment:
- Initial setup: Install Windows on each node and configure the networking. Run the Azure HCI OS setup wizard to begin the installation.
- Cluster creation: Use Windows Admin Center to create the cluster and validate the configuration.
- Azure registration: Register the created clusters with Azure and set up Azure Arc for management.
- Integrate with existing systems: Configure Azure hybrid services and install Azure monitoring and management tools. Connect systems with pre-existing on-prem systems.
Deployment best practices
Deploying Azure HCI may be complex, especially if you have a large deployment. Several best practices are available that will help ensure a smooth installation.
- Thoroughly plan the deployment, including the network infrastructure, storage requirements, and software requirements.
- Document the deployment process to ensure you can repeat it in the future.
- Create a small-scale deployment to test before deploying at scale.
- Keep all systems updated with patches before deployment.
- Verify the minimum server requirements and that all servers have the same make and model (64-bit Intel Nehalem or AMD EPYC, minimum 1.4 GHz, 32 GB of RAM per node, 4 GB of RAM per TB of cache, high-bandwidth, low-latency network connection).
Use cases for Azure Stack HCI
In addition to the ability to quickly roll out IT infrastructure and applications, Azure Stack HCI has an almost unlimited number of use cases.
You can use Azure Stack HCI to create private clouds that offer a company the benefits of cloud computing with the security of on-premise installations. This is especially important for regulated industries like finance and healthcare. HCI allows organizations to store data securely, such as Electronic Health Records (EHR), financial data, and customer information.
You can also use it to make a high-performance computing cluster for demanding scientific and engineering applications by quickly creating virtual clusters. Doing this helps researchers create clusters to perform tasks like complex calculations, weather modeling, and genomic sequencing.
Azure HCI is also beneficial to any organization in the content distribution business. It can serve as the content delivery network, delivering text, images, and videos to customers worldwide using edge servers to manage delivery.
Adding remote offices to a corporate network with Azure Stack HCI is also easy. Using the Azure cloud as a bridge, remote workers can have the same experience as being on a corporate network, thanks to Azure Stack HCI’s virtualized networking solutions.
Azure Stack HCI is also well-suited to creating a DevOps environment for modern application development, testing, and deployment. It allows you to quickly deploy new apps and services and automate testing and debugging processes.
Learn more about Azure integrations
Are you ready to enhance your IT infrastructure by using Azure? Visit our Azure Monitoring Solutions page to learn more about how LogicMonitor can help you seamlessly integrate Azure with your current infrastructure.