Microservices are the future of software development. This approach serves as a server-side solution to development where services remain connected but work independently. More developers are using microservices to improve performance, precision, and productivity, and analytical tools provide them with valuable insights about performance and service levels.
The argument for microservices is getting louder: Different teams can work on services without affecting overall workflows, something that’s not possible with other architectural styles. In this guide, we’ll take a deep dive into microservices by learning what they are, what they do, and how they benefit your team.
What are microservices?
In software development, microservices are an architectural style that structures applications as a collection of loosely connected services. This approach makes it easier for developers to build and scale apps. Microservices differ from the conventional monolithic style, which treats software development as a single unit.
The microservices method breaks down software development into smaller, independent “chunks,” where each chunk executes a particular service or function. Microservices utilize integration, API management, and cloud deployment technologies.
The need for microservices has come out of necessity. As apps become larger and more complicated, developers need a novel approach to development—one that lets them quickly expand apps as user needs and requirements grow.
Did you know that more than 85 percent of organizations with at least 2,000 employees have adopted microservices since 2021?
Why use microservices?
Microservices bring multiple advantages to teams like yours:
Scalability
Microservices are much easier to scale than the monolithic method. Developers can scale specific services rather than an app as a whole and execute bespoke tasks and requests together with greater efficiency. There’s less work involved because developers concentrate on individual services rather than the whole app.
Faster development
Microservices lead to faster development cycles because developers concentrate on specific services that require deployment or debugging. Speedier development cycles positively impact projects, and developers can get products to market quicker.
Improved data security
Microservices communicate with one another through secure APIs, which might provide development teams with better data security than the monolithic method. Because teams work somewhat in silos (though microservices always remain connected), there’s more accountability for data security because developers handle specific services. As data safety becomes a greater concern in software development, microservices could provide developers with a reliable security solution.
Better data governance
Just like with data security, where teams handle specific services rather than the entire app, microservices allow for greater accountability when complying with data governance frameworks like GDPR and HIPAA. The monolithic method takes more of a holistic approach to data governance, which can cause problems for some teams. With microservices, there’s a more specific approach that benefits compliance workflows.
Multiple languages and technologies
Because teams work somewhat independently of each other, microservices allow different developers to use different programming languages and technologies without affecting the overall architectural structure of software development. For example, one developer might use Java to code specific app features, while another might use Python. This flexibility results in teams that are programming and technology “agnostic.”
For example, see how we scaled a stateful microservice using Redis.
Did you know 76 percent of organizations believe microservices fulfill a crucial business agenda?
Microservices architecture
Microservice architecture sounds a lot more complicated than it is. In simple terms, the architecture comprises small independent services that work closely together but ultimately fulfill a specific purpose. These services solve various software development problems through unique processes.
A good comparison is a football team, where all players share the same objective: To beat the other team. However, each player has an individual role to play, and they fulfill it without impacting any of the other players. Take a quarterback, for example, who calls the play in the huddle. If the quarterback performs poorly during a game, this performance shouldn’t affect the other team members. The quarterback is independent of the rest of the players but remains part of the team.
Unlike monolithic architectures, where every component is interdependent, microservices allow each service to be developed, deployed, and scaled independently.
Did you know the cloud microservices market was worth 1.63 billion in 2024?
Microservices vs. monolithic architectures
When you’re considering a microservices architecture, you’ll find that they offer a lot of benefits compared to a traditional monolithic architecture approach. They will allow your team to build agile, resilient, and flexible software. On the other hand, monolithic software is inherently complex and less flexible—something it pays to avoid in today’s world of increasingly complex software.
So, let’s look at why businesses like yours should embrace microservices, and examine a few challenges to look out for.
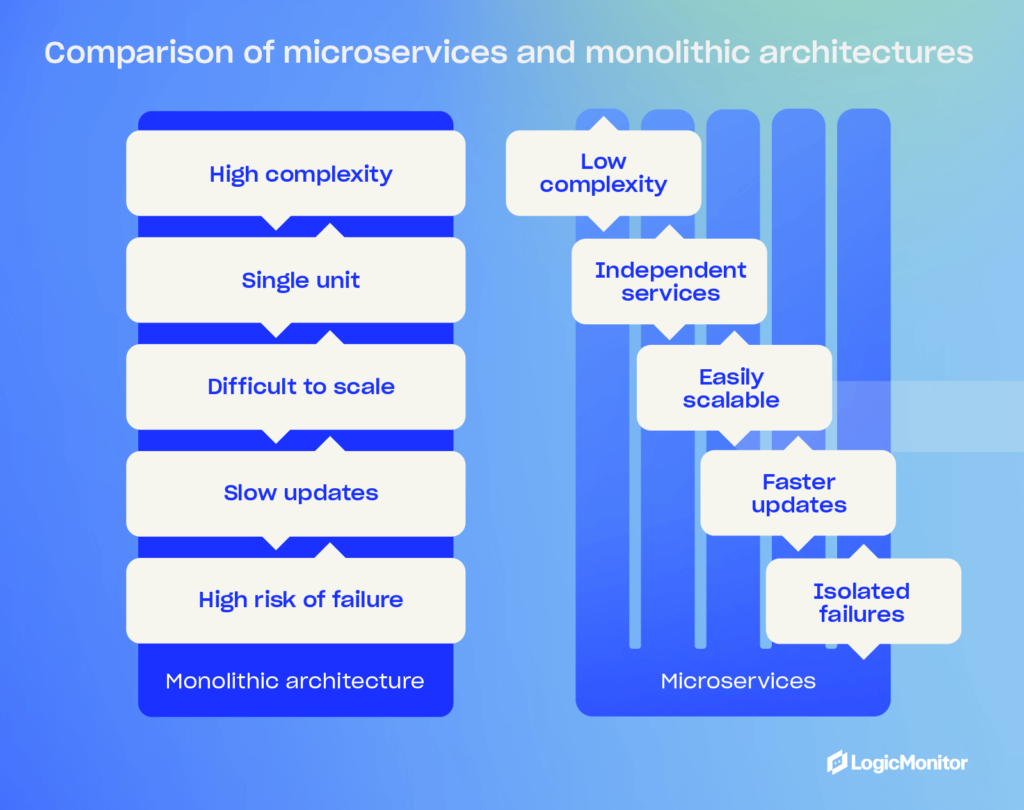
Microservices architecture advantages
- Agility and speed: By breaking your applications into smaller, independent services, you can speed up development cycles by allowing your teams to work on various services simultaneously, helping them perform quicker updates and release features faster.
- Resilience: Service independence and isolation improve your software’s overall stability since a service going offline is less likely to disrupt other services, meaning your application continues running while you troubleshoot individual service failures.
- Flexibility: Your team can use different technologies and frameworks for different services, allowing them to choose the best tools for specific tasks instead of sticking with a few specific technologies that may not be the right choice.
Monolithic architecture disadvantages
- Complexity and risk: When you build applications as single, cohesive units, your team needs to modify existing codes across several layers, including databases, front-ends, and back-ends—even when you only require a simple change. The process is time-consuming and risky, which adds stress to your team if they need to make regular changes, and a single change can impact entire systems.
- High dependency: When your application is made of highly dependent components, isolating services is more challenging. Changes to one part of a system can lead to unintended consequences across your entire application, resulting in downtime, impacted sales, and negative customer experience.
- Cost and inflexibility: Making changes to monolithic applications requires coordination and extensive testing across your teams, which means you’ll see a slower development process, potentially hindering your ability to respond quickly to problems and market demands.
Microservices in the cloud (AWS and Azure)
Perhaps the cloud is the most critical component of the microservices architecture. Developers use Docker containers for packaging and deploying microservices in private and hybrid cloud environments (more on this later.) Microservices and cloud environments are a match made in technological heaven, facilitating quick scalability and speed-to-market. Here are some benefits:
- Microservices run on different servers, but developers can access them from one cloud location.
- Developers make back-end changes to microservices via the cloud without affecting other microservices. If one microservice fails, the entire app remains unaffected.
- Developers create and scale microservices from any location in the world.
Various platforms automate many of the processes associated with microservices in the cloud. However, there are two developers should consider:
Once up and running, these systems require little human intervention from developers unless debugging problems occur.
AWS
Amazon pioneered microservices with service-based architecture many years ago. Now its AWS platform, available to developers worldwide, takes cloud microservices to the next level. Using this system, developers can break down monolithic architecture into individual microservices via three patterns: API-driven, event-driven, and data streaming. The process is much quicker than doing it manually, and development teams can create highly scalable applications for clients.
Azure
Azure is another cloud-based system that makes microservices easier. Developers use patterns like circuit breaking to improve reliability and security for individual services rather than tinkering with the whole app.
Azure lets you create APIs for microservices for both internal and external consumption. Other benefits include authentication, throttling, monitoring, and caching management. Like AWS, Azure is an essential tool for teams that want to improve agile software development.
Did you know the global cloud microservices market is expected to grow from USD 1.84 billion in 2024 to USD 8.33 billion by 2032, with a CAGR of 20.8%?
How are microservices built?
Developers used to package microservices in VM images but now typically use Docker containers for deployment on Linux systems or operating systems that support these containers.
Here are some benefits of Docker containers for microservices:
- Easy to deploy
- Quick to scale
- Launched in seconds
- Can deploy containers after migration or failure
Microservices in e-Commerce
Retailers used to rely on the monolithic method when maintaining apps, but this technique presented various problems:
- Developers had to change the underlying code of databases and front-end platforms for customizations and other tweaks, which took a long time and made some systems unstable.
- Monolithic architecture requires services that remain dependent on one another, making it difficult to separate them. This high dependency meant that some developers couldn’t change services because doing so would affect the entire system, leading to downtime and other problems that affected sales and the customer experience.
- Retailers found it expensive to change applications because of the number of developers that required these changes. The monolithic model doesn’t allow teams to work in silos, and all changes need to be tested several times before going ‘live.’
Microservices revolutionized e-commerce. Retailers can now use separate services for billing, accounts, merchandising, marketing, and campaign management tasks. This approach allows for more integrations and fewer problems. For example, developers can debug without affecting services like marketing and merchandising if there’s an issue with the retailer’s payment provider. API-based services let microservices communicate with one another but act independently. It’s a much simpler approach that benefits retailers in various niches.
Real-world examples of microservices in e-commerce
If you aren’t sure if microservers are the best choice for your company, just look at some of the big players that use microservices to serve their customers worldwide. Here are a few examples that we’ve seen that demonstrate how you can use microservices to build and scale your applications.
Netflix
Netflix began transitioning to microservices after a major outage due to a database failure in 2008 that caused four days of downtime, which exposed the limitations of its monolithic architecture. Netflix started the transition to microservices in 2009 and completed the migration to microservices in 2011. With microservices performing specific functions, such as user management, recommendations, streaming, and billing, Netflix can deploy new features faster, scale services independently based on demand, and improve the overall resilience of its platform.
Amazon
Amazon shifted to microservices in the early 2000s after moving to service-oriented architecture (SOA) to manage its large-scale e-commerce platform. Amazon’s microservices helped it handle different aspects of the company’s platform, such as order management, payment processing, inventory, and customer service. This helped Amazon innovate rapidly, handle massive traffic, and maintain uptime—even during peak shopping periods like Black Friday.
Spotify
Spotify uses microservices to support its platform features like playlist management, search functionality, user recommendations, and music streaming. Spotify’s approach allows the company to innovate quickly, scale individual services based on user demand, and improve the resilience of its platform against failures. Spotify implemented microservices between 2013 and 2014 to handle increasing user demand and feature complexity as it expanded globally.
Airbnb
Airbnb employs microservices to manage its booking platform services for property listings, user authentication, search, reservations, and payments. Implemented between 2017 and 2020, microservices helped Airbnb scale its services as the company experienced massive growth. Airbnb was able to improve performance based on user demand and deploy features more quickly.
PayPal
Since early 2013, PayPal has used microservices to handle payment processing, fraud detection, currency conversion, and customer support services. Microservices helps PayPal offer high availability, improve transaction processing times, and scale its services across different markets and geographies.
How do you monitor microservices?
Various platforms automate the processes associated with microservices, but you will still need to monitor your architecture regularly. As you do, you’ll gain a deeper understanding of software development and how each microservice works with the latest application metrics. Use them to monitor key performance indicators like network and service performance and improve debugging.
Here’s why you should monitor microservices:
- Identify problems quickly and ensure microservices are functioning correctly.
- Share reports and metrics with other team members and measure success over time.
- Change your architecture to improve application performance.
The best monitoring platforms will help you identify whether end-user services are meeting their SLAs and help teams drive an optimized end-user experience.
Tools like LM Envision provide comprehensive monitoring solutions that help you maintain high-performance levels across all your services.
Did you know the cloud microservices market could reach $2.7 billion by 2026?
Best practices for implementing microservices
As you’ve seen above, microservices will offer many benefits to your business. But they aren’t something you can just substitute in and expect to run flawlessly. Here are a few best practices that will help you implement microservices in your application:
- Start small: Switching to microservices isn’t something you should do all at once. Start small by breaking your application down into smaller components and do it a little at a time. This approach will allow your team to learn and adapt as they go.
- Use automation tools: Use CI/CD pipelines to automate the deployment and management of microservices. Automation reduces the chance of your team making mistakes and speeds up repetitive deployment processes to reduce development time.
- Ensure robust monitoring and logging: Implement comprehensive monitoring and logging solutions so your team can track the performance of each microservice and quickly identify any issues.
- Prioritize security: Each service can become a potential attack entry point with microservices and may be harder to secure and monitor for your team because of the more distributed architecture. Implement strong authentication, encryption, and other security measures to protect the system.
- Maintain communication between teams: Since microservices allow your team to work independently on different parts of the application, it’s crucial to maintain clear communication and collaboration to ensure that all services work together seamlessly.
What are the benefits of microservices? Why do they exist today?
Now that we’ve looked at microservices and a few primary benefits, let’s recap some of them to learn more about why they exist today.
- Greater scalability: Although microservices are loosely connected, they still operate independently, which allows your team to modify and scale specific services without impacting other systems.
- Faster development: Your team can move faster by working on individual services instead of a monolithic application, meaning you can focus on specific services without worrying as much about how changes will impact the entire application.
- Better performance: You can focus on the performance of individual services instead of entire applications, changing and debugging software at a smaller level to learn how to optimize for the best performance.
- Enhanced security and data governance: Using secure APIs and isolated services will help your team improve security by controlling access to data, securing individual services, and monitoring sensitive services—helping facilitate compliance with security regulations like HIPPA and GDRP.
- Flexible technology: You aren’t tied to specific programming languages, frameworks, databases, and other technologies with microservices, which means you can pick the best tool for the job for specific tasks.
- Cloud-native capabilities: Platforms like AWS and Azure make creating and managing microservices easier, which means your team can build, deploy, and manage software from anywhere in the world without having a physical infrastructure.
- Quick deployment: Software like Docker is available to make deploying microservices easy for your team, helping them streamline deployment and ensure microservices run in the exact environment they were built in.
The future of microservices
Microservices are a reliable way to build and deploy software, but they are still changing to meet the evolving needs of businesses. Let’s look at what you can expect to see as microservices continue to evolve in the future.
Serverless Architecture
Serverless architecture allows you to run microservices without managing any other infrastructure. AWS is already developing this technology with its Lambda platform, which takes care of all aspects of server management.
PaaS
Microservices as a Platform as a Service (PaaS) combines microservices with monitoring. This revolutionary approach provides developers with a centralized application deployment and architectural management framework. Current PaaS platforms that are well-suited for microservices are Red Hat OpenShift and Google App Engine.
In the future, PaaS could automate even more processes for development teams and make microservices more effective.
Multi-Cloud Environments
Developers can deploy microservices in multiple cloud environments, which provides teams with enhanced capabilities. This can mean using multiple cloud providers, and even combining cloud services with on-prem infrastructure (for cases when you need more control over the server environment and sensitive data).
“Microservices related to database and information management can utilize Oracle’s cloud environment for better optimization,” says technology company SoftClouds. “At the same time, other microservices can benefit from the Amazon S3 for extra storage and archiving, all the while integrating AI-based features and analytics from Azure across the application.”
Service mesh adoption
Service meshes are becoming critical for managing more complex microservice ecosystems. They will provide your team with a dedicated infrastructure for handling service-to-service communication. This infrastructure will help improve monitoring, incident response, and traffic flow.
DevOps and AIOps
The integration of DevOps and AIOps with microservices and ITOps will help streamline development and operations. For example, new DevOps tools will help developers automate many deployment tasks instead of manually configuring individual environments. AIOps will also help your team, as it uses AI and machine learning to improve monitoring and reduce the time your team needs to look through data to find problems.
Event-driven architecture
Event-driven architecture is gaining more popularity among microservices because it allows for more de-coupled, reactive systems that are easier to manage. It allows them to process real-time data and complex event sequences more efficiently.
Advanced observability
As multi-cloud environments become more common, more advanced tools are needed to monitor these environments. Hybrid observability solutions will help your team manage hybrid environments to gather performance metrics (CPU usage, memory usage) about your services in a central location and send alerts when something goes wrong. Advanced observability solutions also use AI to monitor environments to ensure your team only sees the most relevant events and trace information that indicates a potential problem.
Before You Go
Microservices have had an immeasurable impact on software development recently. This alternative approach to the monolithic architectural model, which dominated software development for years, provides teams a streamlined way to create, monitor, manage, deploy, and scale all kinds of applications via the cloud. Platforms like AWS and Azure facilitate this process.
As you learn more about software development and microservices, you’ll discover new skills and become a more confident developer who solves the bespoke requirements of your clients. However, you should test your knowledge regularly to make every development project successful.
Do you want to become a more proficient software developer? Microservices Architecture has industry-leading self-assessments that test your microservice readiness, applicability, and architecture. How well will you do? Get started now.
Using multiple cloud environments in overly complex networks with outdated architectures puts tremendous strain on infrastructures. One of the best solutions for combating overworked architectures is Catalyst SD-WAN, Cisco’s new and improved version of Viptela SD-WAN.
Unveiled in 2023, Catalyst SD-WAN (an updated and rebranded version of Viptela SD-WAN technology) is one of the first Software-Defined Wide Area Network solutions. It provides increased infrastructure speeds and several other key features, like centralized management and security integration. The many benefits of SD-WAN technology are discussed in detail below.
Is Cisco Catalyst SD-WAN the same as Viptela SD-WAN?
Founded in 2012, Cisco Viptela was one of the first vendors to provide SD-WAN solutions. The Viptela SD-WAN platform gained such popularity that Cisco acquired the brand along with Viptela SD-WAN in 2017 and integrated the Viptela technology into its product portfolio.
In 2023, Cisco introduced Cisco Catalyst SD-WAN, an updated version of Viptela SD-WAN that not only rebrands the Viptela technology package but also offers advanced capabilities, like improved network performance, better security, and increased cost efficiency. Available as a PDF download, the Cisco SD-WAN Design Guide provides a deeper look into the evolution of Cisco’s SD-WAN platform.
The need for Catalyst SD-WAN
As network infrastructures become more complex and challenging to manage, traditional Wide Area Network (WAN) architectures struggle with scalability, flexibility, and cost-efficiency. Having an efficient, secure, and scalable network solution is no longer a luxury but a necessity, and Catalyst SD-WAN is one of the most effective solutions available. Using software-defined networking principles, Catalyst SD-WAN helps manage and control network traffic in a more agile and cost-effective manner.
How Catalyst SD-WAN works
Cisco Catalyst SD-WAN is built on a flexible architecture that includes several key components—vEdge routers, vSmart controllers, vManage, and vBond orchestrators. These components create a secure, scalable, and efficient network environment.
Architecture overview
- vEdge routers: Can be physical or virtual and are deployed at a network’s edge to provide secure connectivity and create an overlay network. They support various transport methods like MPLS, broadband, and LTE, ensuring reliable data transfer.
- vSmart controllers: Manage the control plane, handling policy enforcement and route distribution across a network. They ensure that a network’s operational policies are applied consistently and securely.
- vManage: Allows administrators to configure, monitor, and manage an SD-WAN environment, providing a unified network view by integrating data center analytics, automation, and real-time monitoring. The LogicMonitor monitoring platform for Cisco SD-WAN solutions uses vManage API to monitor performance and availability metrics for various edge devices across networks.
- vBond orchestrators: Responsible for initial device authentication and establishing secure connections between vEdge routers, vSmart controllers, and vManage. It plays a critical role in maintaining on-premises and cloud network security and reliability.
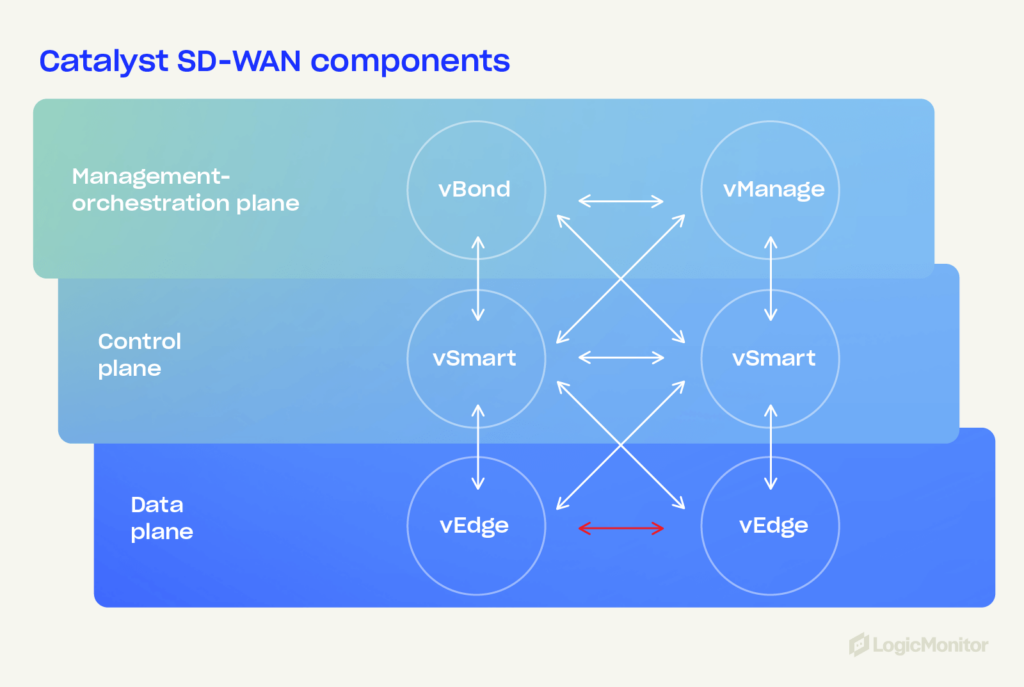
Data plane and control plane separation
Separating the data plane (data forwarding) from the control plane (network control) optimizes traffic flow and allows the application of security policies across networks.
Secure overlay network
An encrypted overlay network over existing transport mediums, such as MPLS, broadband, and LTE, ensures consistent and secure connectivity across all locations and provides a more reliable network foundation for business operations.
Policy enforcement mechanisms
Centralized policies that govern traffic flow, security rules, and application performance can be easily defined and updated based on business needs.
8 key features of Cisco Catalyst SD-WAN
Cisco Catalyst SD-WAN provides a powerful suite of features that streamline network management, bolster security, and optimize performance. From centralized control to comprehensive analytics, these eight key features are designed to address the complexities of modern network environments.
- Centralized management and policy enforcement: Centralized management through a single dashboard enables administrators to make real-time adjustments from anywhere and centralizes security policy enforcement across entire networks. It also provides uniform applications of security standards, reducing the risk of misconfigurations. LogicMonitor’s platform supports SD-WAN monitoring and offers a free downloadable solution brief to get started.
- Integrated security and threat protection: Provides end-to-end encryption and advanced threat protection, allowing for seamless management of both network and security policies through a single interface. Cisco Catalyst SD-WAN supports secure connectivity across multiple transport methods, including broadband, LTE, and MPLS.
- Zero-trust security model: Continuously verifies the identity of every device and user, reducing the risk of breaches. Complemented by secure device onboarding, the zero-trust security model of Catalyst SD-WAN automates the integration of new devices with Zero-Touch Provisioning (ZTP) and automated certificate management.
- Advanced threat protection: Includes advanced threat protection mechanisms, such as intrusion prevention systems (IPS), anti-malware, and URL filtering, which detect and block sophisticated threats in real time before they impact networks. Integrating Cisco Talos Intelligence Group, one of the world’s largest commercial threat intelligence teams, ensures that Catalyst SD-WAN stays updated with the latest threat intelligence.
- Scalability and flexibility: Easily adapts to growing network demands and integrates seamlessly with other security solutions, particularly Cisco Umbrella for cloud-delivered security and Cisco Secure Network Analytics (formerly Stealthwatch) for network visibility and security analytics. Simple integration abilities extend security beyond the SD-WAN to provide comprehensive protection against threats throughout a network.
- Application-aware routing: Optimizes data traffic by tracking path characteristics and selecting the best routes for different applications. This ensures that critical applications receive the bandwidth and quality of service they need, reducing issues like jitter and packet loss.
- Network segmentation: Allows businesses to create multiple virtual networks over a single physical infrastructure. By isolating different types of traffic, critical applications remain unaffected by less important traffic.
- Comprehensive analytics and visibility: Offers real-time monitoring and reporting for more comprehensive visibility into network performance. With predictive analytics, administrators can proactively manage networks, identify potential issues, and prevent downtime.
Benefits of using Catalyst SD-WAN
Catalyst SD-WAN is an attractive solution for network management due to its potential for enhanced application performance. Reducing a network’s complexity reduces the risk of latency and connectivity issues and improves consumers’ user experience.
- Improved network performance: Optimizes network performance by reducing latency and increasing throughput for critical applications. By leveraging multiple transport services, the solution ensures businesses can maximize their available bandwidth.
- Enhanced security: Offers robust security protocols that protect data in transit and at rest. With integrated security features, businesses can simplify compliance with industry regulations and safeguard their networks against modern threats.
- Cost efficiency: Leveraging cost-effective transport options, such as broadband and Cisco Catalyst SD-WAN, reduces operational costs and lowers hardware and maintenance expenses through centralized management and automation.
- Simplified network management: Simplifies the deployment and management of complex networks, allowing businesses to adapt quickly to changing network demands. With minimal manual effort required, IT teams can focus on strategic initiatives rather than routine network maintenance.
- Greater agility and flexibility: Enables rapid provisioning of new sites and services through seamless integration with cloud services and third-party applications, allowing businesses to remain agile and responsive to market changes.
- Enhanced user experience: Delivers consistent and reliable application performance, leading to improved end-user satisfaction. By prioritizing critical applications, business continuity is maintained and the overall user experience is enhanced.
Cisco Catalyst SD-WAN vs. traditional WAN solutions
Traditional WANs, rooted in hardware-centric models, struggle with scalability, flexibility, and the ability to adapt to modern network demands. Cisco Catalyst SD-WAN introduces a software-defined approach that addresses these challenges head-on. Upgrading network infrastructures requires understanding the distinct differences between SD-WAN and traditional WAN architecture.
Architecture comparison
Traditional WAN operations rely heavily on hardware, which isn’t always flexible and difficult to scale. In contrast, Cisco Catalyst SD-WAN uses a software-defined approach that separates network control from hardware, offering greater flexibility and scalability.
Performance and reliability
Cisco Catalyst SD-WAN offers superior performance compared to traditional WANs, with enhanced redundancy and failover capabilities. The solution’s dynamic routing and real-time traffic management features—compared to fixed pathways for data transmission—ensure that critical applications remain accessible even in the event of network disruptions.
Security considerations
While traditional WANs often rely on perimeter-based security models that offer limited visibility into network traffic, Cisco Catalyst SD-WAN integrates security into every layer of the network. This approach addresses modern security threats more effectively, providing a comprehensive defense against potential vulnerabilities with features like encryption, advanced threat detection, malware sandboxing, and centralized security policy management.
Cost and ROI
Catalyst SD-WAN offers a lower total cost of ownership (TCO) compared to traditional WANs by reducing hardware dependencies and leveraging cost-effective transport options. Because of centralized management, an SD-WAN can also lead to faster deployment (and lower operational costs), allowing businesses to achieve a higher return on investment (ROI).
Scalability and flexibility
Traditional WANs can struggle to adapt to changing network scales and configurations because they often require on-site physical configuration changes and struggle to integrate with new technology. Catalyst SD-WAN, however, is designed for scalability, allowing businesses to integrate new technologies—both on-prem and cloud services—as needs evolve.
Real-world applications of Catalyst SD-WAN
Understanding the practical applications of Cisco Catalyst SD-WAN can help illustrate its benefits for various industries. Here are some real-life scenarios that showcase how organizations leverage SD-WAN to enhance their network performance, security, and scalability.
1. Retail chain with distributed branch locations
Challenge: A large retail chain with hundreds of branch locations across different regions faces the challenge of managing network connectivity and security consistently across all stores. This means employees may not be able to do their jobs or serve customers. The traditional WAN infrastructure is complex and costly to maintain, and it is limited in its ability to prioritize critical applications like point-of-sale systems and inventory management.
Solution: By implementing Cisco Catalyst SD-WAN, the retail chain can centralize network management across all branches to gain complete visibility into the IT infrastructure and make changes on both high and low levels. The solution provides secure connectivity, application-aware routing, and network segmentation, ensuring that critical applications receive priority while maintaining robust security standards. With Zero-Touch Provisioning (ZTP), new branch locations can be brought online quickly, reducing setup time and operational costs.
2. Global financial services firm
Challenge: A global financial services company needs to ensure secure, high-performance connectivity for its offices and remote workers worldwide. Lost connectivity means customers may not be able to access their funds, leading to panic and lost revenue for the firm. The traditional WAN setup struggles with latency and security concerns, particularly as the firm expands into new markets and increases its reliance on cloud services.
Solution: Cisco Catalyst SD-WAN offers a scalable solution that enhances the firm’s global connectivity through optimized routing and integrated security features, ensuring fast online services for customers (something especially important for trading services like high-frequency trading). The firm can securely connect its offices and remote workers, leveraging multiple transport methods (like MPLS, broadband, and LTE) while ensuring compliance with stringent financial industry regulations—protecting customer data and avoiding hefty legal fees. The centralized management provided by vManage allows the IT team to monitor and manage the network in real time, responding quickly to any issues or threats.
3. Healthcare provider with multiple facilities
Challenge: A healthcare organization with multiple hospitals, clinics, and remote care facilities needs reliable, secure connectivity to support critical applications like electronic health records (EHR), telemedicine, and real-time patient monitoring. Traditional WAN solutions struggle to deliver the necessary performance and security, particularly as the organization expands its services.
Solution: With Cisco Catalyst SD-WAN, the healthcare service provider can create a secure, high-performance network that supports critical applications across all facilities. The solution’s integrated security features, including end-to-end encryption and advanced threat protection, ensure that patient data is protected, while application-aware routing optimizes the performance of essential healthcare applications. The SD-WAN’s scalability also allows the organization to quickly integrate new facilities, services, and technology (like IoT devices) into the network as it grows.
4. Manufacturing company with a global supply chain
Challenge: A manufacturing company with a global supply chain needs efficient and secure communication between its production facilities, suppliers, and distribution centers. Traditional WAN solutions can’t keep up with the dynamic nature of modern manufacturing, where real-time data and agile responses are critical for maintaining inventory and delivery schedules.
Solution: Cisco Catalyst SD-WAN enables the manufacturing company to establish a secure and agile network that connects all elements of its global supply chain. Using application-aware routing and network segmentation, the company can prioritize and protect critical communications and data transfers, giving each location the information it needs to make decisions and serve customers. This setup improves operational efficiency, reduces downtime, and supports the company’s digital transformation initiatives, such as the adoption of IoT and smart manufacturing technologies.
5. Educational institution with multiple campuses
Challenge: A university with multiple campuses and remote learning centers must provide reliable, high-performance connectivity to support online learning platforms, campus security systems, and administrative applications. The traditional WAN infrastructure is not flexible enough to adapt to the growing demand for bandwidth from student activity, new educational resources, and security.
Solution: Cisco Catalyst SD-WAN provides the university with a flexible, scalable network solution that ensures consistent connectivity across all campuses and remote learning centers. The centralized management platform allows the IT team to deploy security policies uniformly, optimize bandwidth allocation for critical applications, and monitor network performance in real time. The SD-WAN’s ability to integrate with cloud-based learning platforms also supports the university’s digital education initiatives.
Conclusion
By addressing the limitations of traditional WAN architecture, Catalyst SD-WAN enhances application performance, reduces costs, and simplifies network management. Its flexible and secure architecture enables organizations across various industries to remain agile, protect their data, and efficiently manage their infrastructures, whether for cloud migration, distributed systems, or global operations.
LogicMonitor’s tools help businesses improve network visibility while obtaining the maximum amount of benefits from Catalyst SD-WAN.
Network bandwidth is the maximum rate at which data can be transmitted over a network connection in a given time. Essentially, it’s the highway for your data. Bandwidth is often measured in bits per second (bps), but in larger systems, you’ll see measurements like megabits per second (Mbps) or gigabits per second (Gbps).
Bandwidth plays a critical role in IT infrastructure because it determines how quickly data can move. If you think of it like a road, bandwidth dictates how many cars can travel at once. This capacity lets IT teams decide how much traffic their systems can handle. Managing bandwidth helps you avoid congestion, ensuring that applications run smoothly and efficiently.
In this guide, we’ll explore network bandwidth, its impact on your infrastructure, and ways to optimize its usage to keep your systems running smoothly.
Basic concepts
To understand network bandwidth, learning its basic concepts and associated terms is important. Let’s break down these terms:
- Data rate: The speed at which data moves across a network
- Capacity: The maximum amount of data a network can handle
- Throughput: The actual amount of data that successfully travels across the network
- Bandwidth utilization: The percentage of total available bandwidth currently in use
- Packet: A small unit of data sent across the network
- Latency: The delay between sending and receiving data
- Jitter: Variability in packet delivery timing, which can cause delays or disruptions
Pro tip:
When dealing with latency issues, especially in real-time applications, aim to minimize traffic during peak hours and optimize your Quality of Service (QoS) settings to prioritize essential data streams.
How network bandwidth works
When data is transferred over a network, it gets broken into smaller units called packets. These packets are sent through the network to their destination, where they’re reassembled. However, various factors—such as infrastructure quality and network congestion—affect how smoothly this process happens.
Think of bandwidth as the width of a pipe: a larger pipe allows more water (data) to pass through, but obstructions (network issues) can slow everything down.
A customer I worked with, a mid-sized financial firm, was experiencing frequent network slowdowns, especially during peak business hours. After an assessment, they discovered that their network relied on outdated routers and switches that couldn’t handle the increased traffic from newer applications and employee devices.
By upgrading their equipment to support modern network standards (including WiFi 6 and gigabit ethernet switches), they were able to increase bandwidth efficiency dramatically. This upgrade reduced bottlenecks and allowed critical applications, like their real-time financial tracking systems, to run smoothly even during heavy traffic periods.
Pro tip:
When facing network congestion, assess your hardware first. Outdated equipment can be a hidden cause of slowdowns, and upgrading to the latest technology often delivers significant improvements in both bandwidth and overall performance.
Factors affecting network bandwidth and performance
Many factors impact network bandwidth and performance. These include internal factors within your organization and external factors that may be outside of your control.
Internal factors:
- Network hardware and configuration: The quality and configuration of network equipment like routers and modems
- Software and protocol efficiency: Applications and protocols used to transmit data across networks, including hardware firmware, device applications, and protocols (TCP, UDP, HTTP, FTP)
External factors:
- ISP limitations: Sometimes, your internet service provider’s infrastructure is the bottleneck
- Environmental interference: Environmental problems, such as physical obstacles, electromagnetic interference (disrupting WiFi), and distance, may degrade performance
Understanding network performance
Several factors impact network performance, and they often show up as issues like latency—one of the most common culprits. While bandwidth indicates how much data can be transferred, latency refers to how long it takes for that data to travel. This delay is especially problematic in real-time applications, like video conferencing or online gaming, where even small delays can cause noticeable disruptions.
Factors that increase latency include:
- High volumes of data, especially when nearing bandwidth limits.
- Type of internet connection (Cable, Fiber, DSL, Satellite).
- Network traffic volume during peak times.
- Quality of Service (QoS) settings that prioritize certain types of traffic.
- Distance between your device and the server.
- Network design and topology.
- Device performance, such as outdated routers or network switches.
Bandwidth vs. throughput vs. speed
Though bandwidth, throughput, and speed are often used interchangeably, they refer to different aspects of network performance.
Bandwidth is the maximum capacity—the total amount of data your network can handle at once. Think of it as the number of lanes on a highway. Throughput is the actual amount of data that reaches its destination. It’s affected by factors like network congestion and distance, making it the real-world measure of your network’s performance. Speed is how fast data moves from one point to another. While bandwidth defines potential, speed represents how quickly data can travel under current conditions.
Imagine bandwidth as the width of the road and speed as how fast cars are traveling. Throughput is how many cars (or data packets) actually make it to the end of the highway without hitting traffic jams.
Throughput in networking
Throughput gives you a clear picture of your network’s real-world performance—how much data is making it to its destination. Monitoring throughput can help identify issues such as:
- Extra data being transmitted, reducing efficiency
- Too much traffic slowing things down
- Older routers or switches struggling to keep up with demand
- Poorly optimized applications slowing down data transfer
Common bandwidth bottlenecks
Bandwidth bottlenecks can occur at various points in your network, from internal devices to external ISP limitations. Common causes include:
- Device limitations: Too many devices on a network can overwhelm available bandwidth, especially in large organizations where workstations, servers, and personal devices all compete for resources
- Old equipment: Outdated routers, switches, or network cables can limit your available bandwidth, slowing down data flow.
- Insufficient capacity: Sometimes, internet service providers don’t deliver enough bandwidth to meet your needs, particularly in small businesses or homes
- Peak usage times: During high-traffic periods, shared connections—whether at home or in the office—can become congested, causing slowdowns.
Recognizing these factors can help you start troubleshooting and optimizing your network performance more effectively.
Monitoring network bandwidth
Effective network monitoring helps you maintain performance and ensures your organization’s employees can access the resources they need to do their jobs.
You likely have a range of tools available to help with this, like network monitoring software, Simple Network Management Protocol (SNMP), and traffic analyzers. Here’s how you monitor your bandwidth in the most effective way possible:
- Establish a baseline by measuring your current network performance
- Reduce interference by testing under ideal conditions
- Connect a device directly to a modem or router to eliminate variability from WiFi interference
- Conduct tests during both peak and off-peak hours to identify patterns of network congestion
- Use your tool to breakdown bandwidth by application to understand what’s consuming the most resources
- Run multiple tests to gather reliable data, then compare against your expected performance benchmarks
- Rerun tests in different environments to look for differences in network speed based on different factors
- Document results and create a plan to improve network bandwidth, which may include tweaking QoS settings or addressing peak-time congestion
Pro tip:
Don’t just measure speed—track latency and packet loss, as these affect performance even when bandwidth seems sufficient
Monitoring network bandwidth with this approach helps with immediate issue detection, resulting in less downtime and improved operations—letting you do more strategic work rather than putting out fires. It also allows you to find network congestion areas and reallocate resources for more efficient operations. Lastly, you can detect unusual traffic patterns that may indicate threats, keeping you ahead of any security incidents.
Optimizing network bandwidth monitoring
Although your organization can use tools to monitor network traffic, a comprehensive tool allows you to combine multiple data sources in one solution and perform advanced analysis.
LogicMonitor offers the LM Envision platform, a complete solution for hybrid observability powered by AI. Here are a few features that can help you monitor network traffic:
- Monitoring of historical network performance to check for usage patterns that may indicate problems
- AI features to automatically look for anomalies instead of manually inspecting traffic logs and getting caught in the noise
- Reporting tools to plan the network for performance, capacity planning, and improved bandwidth usage
- Predictive analytics to get in front of problems proactively instead of reacting after they happen
- Security improvement through the detection of unusual bandwidth patterns that indicate potential security breaches
Improving and optimizing bandwidth
In my experience, optimizing bandwidth isn’t just about increasing capacity—it’s about making sure the network is designed and managed efficiently. Here are some strategies that I’ve found to be particularly effective when improving network performance.
Improve network design and architecture:
One of the quickest wins I’ve seen when optimizing bandwidth is improving network design. A well-planned architecture ensures data flows efficiently, and investing in modern equipment pays off almost immediately.
- Upgrade equipment: Outdated routers and switches are often the hidden culprits of slow networks. Moving to newer models, especially those supporting WiFi 6, made a huge difference in several projects I’ve worked on.
- Optimize topology: I once worked with a company where removing just a few unnecessary network hops drastically reduced latency and increased throughput. Simplifying your network’s layout is a low-cost way to free up bandwidth.
Manage traffic
Traffic management is critical. In large networks, I’ve seen bottlenecks occur simply because non-essential traffic was eating up precious bandwidth. By prioritizing the right services, you can avoid that.
- Set QoS policies: In a financial firm I worked with, implementing Quality of Service (QoS) ensured that mission-critical apps like trading platforms got the bandwidth they needed while less urgent traffic was deprioritized.
- Traffic shaping: Another useful trick is rate-limiting. We limited bandwidth for non-essential services like video streaming during peak hours, ensuring that critical operations weren’t affected.
Control bandwidth usage
You don’t always need more bandwidth. Sometimes, it’s about controlling when and how it’s used. I’ve seen great results by scheduling tasks that eat up bandwidth—like backups or updates—outside of peak times.
- Schedule intensive tasks: With one customer, simply running updates after hours dramatically reduced congestion during the workday.
- Set quotas: For some customers, setting bandwidth quotas for non-essential users prevented individual teams from consuming too much bandwidth and ensured more important processes always had enough to function smoothly.
- Educate users: I always recommend educating users. When employees understand that bandwidth isn’t infinite, they’re more likely to limit unnecessary activities like streaming or large file downloads during business hours.
Regularly monitor bandwidth usage
From my experience, regular monitoring is one of the most important steps for keeping a network running smoothly. You need to have visibility into what’s happening on your network in real-time and historically.
- Monitor in real-time: I’ve seen businesses thrive using tools like LM Envision, which allow you to identify issues as they happen. You can set alerts for unusual bandwidth usage, preventing problems before they affect users.
- Historical data analysis: Reviewing historical trends has helped many of my customers identify and resolve recurring bandwidth bottlenecks. By looking at when spikes occur, we were able to make smarter decisions about bandwidth allocation.
Planning for network bandwidth
Network demands don’t stay static, and I always encourage businesses to plan for growth. Your current setup might be fine now, but you need to think about what’s coming next.
Assess your needs
Start by assessing what you have now. I usually begin by looking at which applications are using the most bandwidth and how much traffic flows through both wired and wireless networks.
Remember, peak times matter. I’ve worked with customers who didn’t realize how much their network was struggling during peak hours until we analyzed the data. Knowing when your network is busiest helps you make smarter infrastructure decisions.
Plan for future growth
Planning ahead has saved many of my customers from network slowdowns. Look at your projected business growth—whether it’s more employees, new technologies, or cloud expansion—and make sure your network can handle the extra load.
The biggest mistake I see is companies waiting until they hit a bandwidth limit before upgrading. Planning for future growth prevents sudden crashes and keeps your business running smoothly.
Add redundancies
No matter how much planning you do, things can still go wrong. I always advise building redundancies into your network to avoid downtime when issues arise.
- Backup ISP: Having a secondary internet provider has saved several of my customers during outages. It’s a small investment for the peace of mind it brings.
- Load balancing: I’ve worked with teams that use load balancing to distribute traffic across servers, ensuring that no one server gets overwhelmed, especially during peak times.
- SD-WAN: For businesses that deal with a lot of traffic across multiple locations, SD-WAN has been a game changer. It automatically reroutes traffic to the best available path, reducing congestion and improving performance.
Applications of network bandwidth
Bandwidth isn’t just about the raw numbers; it’s about what you’re using it for. I’ve worked with customers across industries, and their bandwidth needs can vary dramatically depending on their use cases.
- Everyday tasks: For basic internet use—email, browsing, and remote work—the bandwidth requirements are modest
- Business applications: However, more advanced applications like ERP systems, cloud services, or data centers require significantly more bandwidth
- Advanced tech: For businesses dealing with AI, big data, or IoT services, planning for high bandwidth is crucial
Assessing how you use bandwidth today and how that might change in the future helps you design an IT infrastructure that supports growth.
Wrapping up
Understanding and managing network bandwidth is one of the most impactful things you can do to keep your IT infrastructure running smoothly. It’s not just about having enough bandwidth—it’s about optimizing how you use it. By controlling traffic, staying ahead of bottlenecks, and planning for future growth, you’ll set your business up for long-term success. I’ve seen firsthand how businesses that prioritize bandwidth management experience fewer slowdowns, better performance, and the ability to scale effortlessly. With the right approach, you’ll not only meet today’s needs but also be ready for whatever comes next.
In recent years, Software-Defined WAN Technology (SD-WAN) has changed the way networking professionals secure, manage, and optimize connectivity. As organizations continue to implement cloud applications, conventional backhaul traffic processes are now inefficient and can cause security concerns.
SD-WAN is a virtual architecture that enables organizations to use different combinations of transport services that can connect users to applications. Sending traffic from branch offices to data centers using SD-WAN provides consistent application performance, better security, and automates traffic based on application needs. It also delivers an exceptional user experience, increases productivity, and can reduce tech costs.
What is SD-WAN?
SD-WAN implements software to safely and effectively manage the services between cloud resources, data centers, and offices. It does this by decoupling the data plane and the control plane. The deployment process often includes vCPE (virtual customer premise equipment) and existing switches and routers. These run software that control most management functions, such as networking, policy, and security.
Until recently, a Wide Area Network (WAN) was the best method for connecting users to applications on data center servers. This would typically include Multiprotocol Label Switching (MPLS) circuits for secure connections. But today, MPLS is no longer adequate if you’re dealing with large amounts of data and working in the cloud. Backhauling from branch offices to corporate headquarters impairs performance. Gone are the days of connecting to corporate data centers to use business applications.
With SD-WAN, it’s now easier for you to deliver exceptional network experiences with less operational responsibility for IT staff.
What is the SD-WAN architecture?
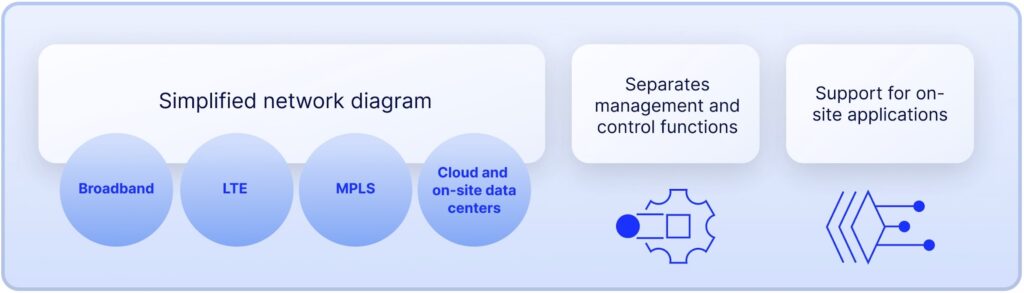
Traditional WANs can limit growth and productivity due to their dependence on total hardwire network devices. SD-WAN depends on software to provide a virtual approach while implementing traditional technologies such as broadband connections.
The traditional architecture with conventional routers was not created for the cloud. Backhauling traffic was required from branch offices to data centers so detailed security inspection could occur. This method often hinders performance, causing a loss in productivity and a poor user experience.
SD-WAN, however, can fully support applications in on-site data centers. This includes SaaS services such as Microsoft 365 and Dropbox. The architecture can separate management and control functions, WAN transport services, and all applications. With centralized control, you can store and control all the data on the applications. The control plane can adapt traffic to fit application demands and provide a high-quality user experience.
How does SD-WAN work?
SD-WAN uses communication tunnels, network encryption, and firewall software to manage and safeguard computer networks across several locations. SD-WAN can distinguish and separate network hardware from central controls and streamline operations. A business that uses SD-WAN can create higher-performance WANS by using the internet instead of MPLS.
Traffic flows through a specific SD-WAN appliance, with each appliance centrally controlled and managed. This enables the consistent enforcement of policies. SD-WAN can determine each application traffic and has the ability to route each one to the correct destination. These machine learning-based capabilities enable the software to base destination routes on existing policies.
Because SD-WAN is built to work efficiently, these solutions generally offer greater bandwidth efficiency, increased application performance, and easy access to the cloud. Users enjoy all these benefits without sacrificing data privacy or security. This can also improve customer satisfaction and business productivity.
Furthermore, SD-WAN can identify different applications and provide specific security enforcement. This means that business needs are met, and the business is protected from threats. One of the reasons SD-WAN is so effective is because it can leverage new software technologies while implementing machine learning.
There are a few specific aspects of SD-WAN that enable it to work so well:
Ability to self-learn and adapt
SD-WAN normally guides traffic according to programmed templates and predefined rules. It has the ability to continuously self-monitor and learn. This is done by adapting to various changes in the network. These changes could include transport outages, network congestion, or brownouts. This adaptation occurs automatically and in real time. This limits the amount of manual technical intervention that is needed.
Ability to simultaneously use multiple forms of WAN transport
If a particular path is congested or fails, the system can implement solutions to redirect traffic to another link. SD-WAN can manage each transport service seamlessly and intelligently. The primary purpose of SASE is to provide the best experience possible for cloud applications. The ultimate goal is to be high quality for the user. The advanced capabilities provided by SD-WAN are necessary to enable optimum SASE and find solutions for these purposes in the event of technical problems.
How does SD-WAN and automation work?
SD-WAN already provides a certain amount of automation. To improve this process, each of the SD-WAN elements needs to communicate through APIs. Improving the communication will also enhance the changes the system can make to WAN edge devices. This affects the configuration of resources such as AWS, Google Cloud, and Microsoft Azure. This way, automation works through the entire system, not just in individual components.
Real-time path selection is an example of automation. As communication within the systems improves, the ability to increase the speed and precision of automated decisions will also improve. Insights based on instantaneous data collection will continue to increase efficiency and precision. You will want to continually integrate and update SD-WAN solutions with various machine learning forms to improve manual tasks’ automation. This will enable you to simplify and scale your system to meet the specific needs of each business operation.
Several SD-WAN benefits result from improved automation. These include less human error, faster operations, and improving quality of service. In the long run, the more automation you have, the more likely you will reduce overall operating costs. Automation means reducing the need to hire more engineers and other IT professionals. A self-learning network will increasingly automate many tasks currently done by humans.
What are the benefits of SD-WAN?
SD-WAN is able to offer solutions to many of the challenges you will likely experience when using traditional WAN. The many benefits of SD-WAN include:
Greater agility
While MPLS is good at routing traffic when there are only a few static locations, it’s certainly not as effective when doing business on the cloud. Policy-based routing is the key to SD-WAN’s agility. Traffic is sent through a network focusing on the needs of each basic application. You can use several different transport structures in the WAN. SD-WAN provides predictable agility while supporting cloud migration. This agility includes the ability to use a variety of connections interchangeably, including MPLS, LTE, and broadband.
Increased efficiency
Sending traffic from remote offices to primary data hubs can cause delays. SD-WAN can effectively tie in cloud services. As the use of cloud applications and containers that need edge access increases, so does the need to implement SD-WAN technology. Cloud resources are easily connected with the data hubs in a fast and cost-effective manner. This enables private data centers to grow while organizations can still efficiently expand their use of public cloud services. There is also a reduction in latency issues, which means greater application performance.
Improved security
SD-WAN allows security specification for individual customers that is scalable. Organizations can set up secure zones to guide traffic based on their business policies. A company can protect critical assets with specific partitions while also using firewalls as part of the security process. You can create partitioned areas, basing them on particular roles or identities. You can also monitor network connections, enable deep packet inspection, add data encryptions, and log all security events.
Reduced costs
Backhauling is not only more time-consuming, it’s also costly. MPLS connections between offices and data centers cost more than wireless WAN links or internet broadband. It may take weeks or longer to supply new MPLS links, and MPLS bandwidth is potentially expensive. The same process takes only days when using SD-WAN. In many ways, particularly when it comes to expense, SD-WAN is superior to MPLS. It can also save money by lowering maintenance and equipment costs.
Increased simplification
SD-WAN simplifies turning up new links to remote offices while managing how each link is used more effectively. There is sometimes the need to use several stand-alone appliances with MPLS. You’re able to centralize operations and more easily scale a growing network when using SD-WAN.
Better app performance
Supporting cloud usage and SaaS apps is a necessary part of the digital progress. Applications generally need a lot of bandwidth. SD-WAN provides adequate support with high priority for critical applications. The network hardware separates from the control pane using an overlay network. Network connections then determine the best paths for every application in real time.
Remote access
Cloud access is the primary reason many organizations choose SD-WAN. No matter where your branch or office is, you can easily access all available cloud applications. You can also direct traffic through the data center for critical business applications.
What are the drawbacks of SD-WAN?
SD-WAN has some disadvantages, but the correct tools can overcome many of these drawbacks. Some disadvantages include:
Providing security
Because of how network security is set up, a breach could occur in several remote locations throughout the organization if a hacker breaches security and gains access to the central data branch. This type of connectivity could affect an entire company.
Training staff
Adapting to SD-WAN is not always easy if you’re running or working for a smaller business. Your current staff may not have adequate training to understand and implement this particular technology. In some cases, you may find it counterproductive to hire new IT personnel or train existing staff to build and maintain SD-WAN systems.
Supporting WAN routers
Your SD-WAN system may not support WAN routers. An ethernet connection is likely to interfere with the WAN architecture. You’ll have to come up with a method to eliminate this potential problem. Time-division multiplexing is one option.
How do you select the best SD-WAN?
You’ll want to consider several factors when selecting any SD-WAN model:
- The SD-WAN you select should have the ability to collect real-time statistics.
- The model should connect with all endpoints from any software and application.
- Your selection must be able to encrypt all traffic over the network.
- You should choose a model that provides policy-driven solutions.
- You’ll want an SD-WAN with advanced security that meets your organization’s needs.
- You’ll want to select an SD-WAN that can efficiently utilize bandwidth.
- Your selection should have mobility features, including access control and automatic ideal route selection.
- Your selection should be able to connect with several stations with various internet data services.
What SD-WAN choices are available?
The following are a few of the best-rated SD-WAN solutions:
- Cisco Meraki SD-Wan – This model provides visibility and connects to any application.
- Oracle SD-WAN – Besides routing and firewall, Oracle provides cost-efficient internet connections and high bandwidth.
- CenturyLink SD-WAN – This will help you create a more agile and wide network. It also gives users data reports and analytics.
- Fortinet FortiGate SD-WAN – This solution offers next-generation firewall and advanced routing.
- Wanify SD-WAN – This model delivers VeloCloud SD-WAN through a partnership with VeloCloud. You’ll have end-to-end process management and Wanify’s customer support.
- Aruba Edge Connect – Ratings state that this software is one of the easier types to use. It focuses on reducing costs while simplifying the process.
- Masergy SD-WAN – Masergy has built-in Fortinet security. It also uses AI for its IT operations.
If your organization is using the cloud and subscribing to SaaS, connecting back to a central data center to access applications is no longer efficient or cost-effective. SD-WAN provides a software-centric process that will give your organization optimal access to cloud applications from all remote locations. Your team can create a network that relates to the company’s business policies and promotes the long-term goals of the organization.
Palo Alto Panorama is an advanced management platform that streamlines the oversight of Palo Alto Networks firewalls. It offers centralized control, real-time insights, and simplified security management through a user-friendly web interface.
Implementing Palo Alto Panorama reduces administrator workload by building a real-time dashboard where you can monitor all of your IT operations in one place. It also alerts users of an impending threat so that they can protect themselves before an attack penetrates their network.
You can customize this centralized management to analyze and report specific logistics of interest to your company. It is a network security system that will enhance your security and protect your company.
The role of Palo Alto Panorama in network security
Palo Alto Panorama is essential to your company’s network security, as it gives you an easy way to protect sensitive information. You can manage all your firewall gateways, even in different regions. Since next-generation firewalls prevent unauthorized access, they must be managed effectively to maintain network security.
By using Palo Alto Networks Panorama, users can avoid duplication of work on their network security, especially if they need similar configurations on multiple firewalls—it continuously monitors the status of these firewalls. Palo Alto Panorama is excellent for large companies that have numerous firewall systems.
Palo Alto Panorama also monitors hardware firewalls, tracking traffic to and from all devices connected to the network. This monitoring helps enforce access controls and security policies, ensuring the network boundary remains secure.
A centralized management interface allows a company to observe, control, and review every firewall it wants to monitor. Palo Alto Panorama is crucial for businesses that must continuously monitor their network security, ensuring it operates correctly and preventing cyber-attacks or data center breaches.
How Palo Alto Panorama enhances network security
On top of the benefits mentioned above, Palo Alto Panorama has several benefits that help enhance network security, such as:
- Centralized updates: Allow simultaneous updates to the firewall and network settings for improved efficiency
- Automation: Automate specific processes for monitoring and updating specific security factors
- Comprehensive overview: Get a more complete view of your network security state and how it performs
- Customization: Use specific features to monitor parameters tailored to your needs instead of using pre-defined configurations
Features of Palo Alto Panorama
Palo Alto Panorama offers several features, including:
- Manages all firewalls and security tools
- Ensures consistency in firewall, threat prevention, URL filtering, and user identification rules
- Provides visibility into network traffic
- Offers actionable insights when threats are detected
- Identifies malicious behavior, viruses, malware, and ransomware
- Organizes firewall management with preconfigured templates for efficiency
- Implements the latest security updates with a single update
- Maintains a consistent web-based interface
- Performs analysis, reporting, and forensics on stored security data
Benefits of using Palo Alto Panorama
Palo Alto Panorama provides a centralized management system that simplifies network security management. Key benefits include:
- Monitors and updates applications automatically and efficiently
- Configures firewalls by group for simultaneous updates or changes
- Enables quick response to network threats
- Scales easily to grow with your company
- Supports additional services like data loss prevention and web protection
- Reduces time spent on network security by up to 50%
- Streamlines network security operations for better efficiency
- Adds an extra layer of security for more consistent management
How to set up and configure Palo Alto Panorama
You can set up Palo Alto Panorama by following a few simple steps. Use the small guide below to deploy it in your organization and get it ready to customize for your unique needs.
- Installation: Read the minimum requirements for Panorama and find dedicated hardware or virtual appliances that meet those specifications. Deploy on your chosen environment once chosen.
- Initial configuration: Connect to the Panorama web interface (192.168.1.1 by default). Set up the system settings (like IP address, DNS, and NTP) and activate the licenses. Then, update the software to the latest version.
- Set up managed devices: Connect your Palo Alto Network firewalls and other devices to Panorama and verify the device management connection.
- Create device groups and templates: Organize firewalls into logical groups. Once done, create configuration templates to ensure consistent policies across devices.
- Define policies: Define policies—such as NAT rules—and other device configurations. Use Panorama to push your configuration to managed devices.
- Configure logging and reporting: Configure log collector settings based on your organization’s needs. Set up custom reports and alerts to get notifications about potential issues.
- Set up User Access Controls (UAC): Create administrative accounts with proper permissions to control access to Panorama. Increase security by using multi-factor authentication.
- Test and verify: Conduct thorough testing to ensure all firewalls are properly managed. Check individual devices to verify policies are applied across the network.
Panorama Management Architecture
Panorama is a centralized management platform that offers simplified policy deployment, visibility and control over multiple firewalls within an organization. It offers a hierarchical structure for managing firewalls, with the ability to create templates and push policies across all devices, reducing the risk of misconfiguration and ensuring consistent security.
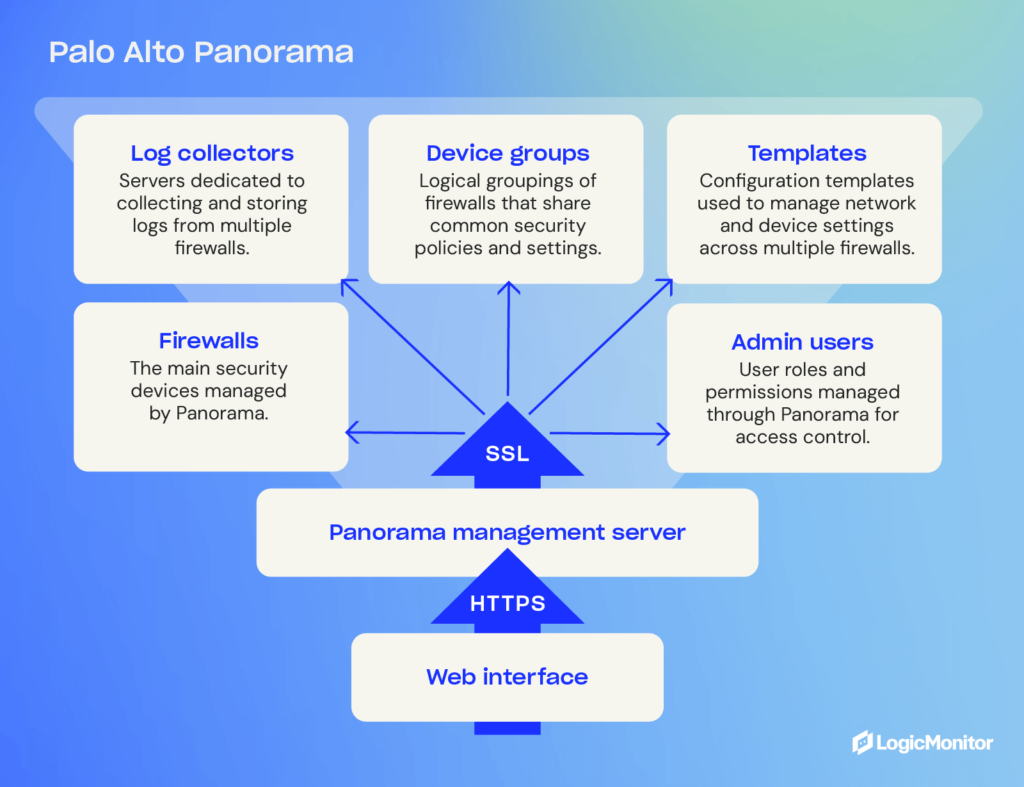
Device Groups
Device groups are logical groupings of firewalls within an organization that share similar characteristics. They can be created based on location, function or department.
These groups allow administrators to apply policies, templates and configurations to multiple firewalls simultaneously, saving time and effort. Device groups also provide a way to logically organize firewall management tasks and delegate responsibilities to different teams.
Templates
Templates in Panorama are preconfigured sets of rules and settings that can be applied to device groups or individual devices. This allows for consistent policy enforcement across all managed firewalls.
Templates can be created for different purposes, such as network security, web filtering, or threat prevention. They can also be customized to meet the specific needs of each device group or individual firewall. This level of flexibility and control ensures that policies are tailored to the unique requirements of each network segment.
Advanced capabilities of Palo Alto Panorama
Palo Alto Panorama offers a range of advanced features that make it useful for a range of applications and work environments. These capabilities can help your organization address specific security challenges and compliance requirements.
Some features you may find useful include:
- Application-layer visibility: Get deep insights into application usage across the network to gain a more granular level of control and policy enforcement
- Threat intelligence: Integrate with external threat intelligence feeds to boost detection and response capabilities
- Action automation: Automatic actions based on specific security events to lock down threats and improve incident response time
- Cloud support: Support both on-prem and cloud integration, allowing your organization to enforce consistent policies in every environment
- API support: Extensive API capabilities to integrate with other security tools to enhance capabilities, reporting, and automation
- Log correlation: Advanced log analysis to identify complex attack patterns across multiple devices
These features allow companies in any industry to meet their security requirements. Here are a few examples of how specific industries can put them to use.
Finance
Financial industries have strict requirements to protect customer data. They are required to comply with privacy rules like PCI DSS and OCX and held accountable if they don’t. Financial companies can use Palo Alto to detect potential intrusions that put customer records and funds at risk. It also helps segment specific banking services to put the most strict policies on the data that matters most.
Healthcare
Healthcare organizations must comply with HIPAA regulations to protect patient data. As healthcare environments become more complex, with IoT healthcare devices rolling out in healthcare facilities, facilities need advanced SaaS tools for managing and troubleshooting those devices. Palo Alto Panorama helps facilities create custom security solutions to manage constantly evolving healthcare environments and ensures they can detect potential threats that arise.
Education
Educational institutes are responsible for ensuring the safety of their students and staff. Depending on the student’s age, they may also need to comply with the CIPA. Pano Alto Panorama helps institutions manage internet access for students, faculty, and staff—ensuring data is protected and internet access is controlled and monitored. It also helps isolate research data for higher-education institutions for sensitive research data.
Palo Alto Panorama offers flexible and robust security
Palos Alto Panorama offers an advanced management platform to streamline the management of Palo Alto devices. Advanced features like automation, centralized management, and customized alerting will help your organization build a reliable security solution. As a result, you can protect customer and proprietary data and comply with your business’s compliance requirements.
Definition
The WMI Provider Host (WmiPrvSE.exe) is a critical Windows process that acts as an intermediary between system hardware and software, allowing applications to access system information. You can view it in Task Manager to check its status. This process is part of the Microsoft Windows operating system. Microsoft built WMI management tools into each Windows version starting with NT 3.1.
What is WMI?
Windows Management Instrumentation (WMI) is the primary method for obtaining information from Windows for various systems. It provides specific data regarding configurations and overall performance to help DevOps and administrators monitor and automate tasks.
You might worry about network security and whether the WMI Provider Host (WmiPrvSE.exe) is safe. Yes, it is. Many aspects of your personal computer wouldn’t function without it. These are some general purposes that the WMI Provider Host fulfills for users:
- It gives information as a task manager to assorted applications without requiring direct action from the user.
- It offers information regarding event log entries, internal data storage status, and even the motherboard model number.
- It has a set of extensions in the Windows Driver Model. This includes an interface with components that provide notifications and other types of information.
- It allows third-party software to query operating information.
- It reduces the cost and maintenance of managing network components.
Security considerations
Potential security risks related to WMI provider host
While the WMI Provider Host (WmiPrvSE.exe) is an essential component of the Windows operating system, it can pose potential security risks if not properly managed. Malicious actors can exploit WMI for various types of attacks, such as:
- Unauthorized access: If a system’s WMI settings are not properly configured, unauthorized users may gain access to sensitive information or system configurations.
- Malware exploitation: Malware can leverage WMI to execute scripts or commands, retrieve system information, and perform other malicious activities without detection.
- Privilege escalation: Poorly configured WMI permissions can allow attackers to escalate their privileges on a system, potentially gaining control over critical components.
Best practices for securing the WMI provider host
To mitigate potential security risks, it’s important to follow best practices for securing the WMI Provider Host:
- Restrict WMI access
- Ensure that only authorized users and applications have access to WMI. Use Group Policy settings to manage and restrict WMI permissions.
- Review and update access control lists (ACLs) regularly to ensure they comply with the principle of least privilege.
- Monitor WMI activity
- Continuously monitor WMI activity logs for any unusual or suspicious behavior. Use tools like the Event Viewer to track and analyze WMI events.
- Implement a centralized logging system to consolidate and review WMI logs from multiple systems.
- Keep systems updated
- Apply security patches and updates regularly to your operating system and related components. This helps protect against known vulnerabilities that attackers could exploit.
- Enable automatic updates to ensure your system remains protected against the latest threats.
- Implement network security measures
- Use firewalls and network segmentation to limit access to WMI-enabled systems. This can help contain potential attacks and prevent lateral movement within your network.
- Configure network security groups and access control lists (ACLs) to restrict inbound and outbound traffic related to WMI.
- Use strong authentication and encryption
- Implement strong authentication methods, such as multi-factor authentication (MFA), for accessing WMI. This adds an additional layer of security to prevent unauthorized access.
- Ensure that WMI communications are encrypted to protect sensitive information from being intercepted during transmission.
What is a provider host?
A provider host allows third-party software to interact with and query operating system information. It’s important to note that, besides the Windows WMI providers, there are sometimes other providers on your system. Microsoft and third-party developers may install other apps on your computer that use different types of providers. If you experience problems with your system, you may need to use troubleshooting determine which WMI provider is causing the issue.
According to Microsoft, several hosting model values exist for providers operating within the Wmiprvse.exe process. These are a few examples of values in _Win32Provider.HostingModel.
- NetworkServiceHost: If the WMI provider’s hosting model is not specified, this is the default model beginning with Windows Vista. This type limits the possibility of privilege attacks.
- LocalSystemHost: If the provider is in process, it’s part of a shared host within LocalSystem.
- LocalServiceHost: If its implementation is in progress, the provider is part of the Wmiprvse.exe process under the LocalService account.
- SelfHost: Instead of using an in-process model, the provider works through a local server implementation.
Why is a provider host important?
A provider host enables different applications to request information about how your system is operating. The host will normally run in the background when supporting your computer. Some of the important features that a WMI provider host provides include the following:
- .Net Management Capabilities: The existing WMI provider and all its classes are available to every .NET application.
- Automation Capabilities: Automation interfaces are part of the WMI operating system and ready for use.
- Event Capabilities: Through the WMI, a subscriber can receive notifications for a variety of events. WMI uses query language to submit event queries.
- Remote Capabilities: WMI providers offer more than local COM ability. This includes DCOM transports and sometimes SOAP requests and responses.
Integration with system management tools
The WMI Provider Host integrates seamlessly with various system management and monitoring tools. These tools, such as Microsoft System Center, Nagios, and LogicMonitor, use WMI to gather detailed system information, monitor performance, and automate administrative tasks. This integration allows administrators to access real-time data and manage systems more efficiently.
Benefits of leveraging these integrations for better system management
- Improved monitoring: By leveraging WMI integrations, administrators can monitor system health, performance, and configurations in real time, allowing for quicker identification and resolution of issues.
- Enhanced automation: Integrating WMI with management tools enables the automation of routine administrative tasks, such as system updates, backups, and resource allocation, reducing manual workload and minimizing errors.
- Centralized management: WMI integration allows for centralized management of multiple systems from a single interface, simplifying complex environments and improving operational efficiency.
- Comprehensive reporting: Management tools using WMI can generate detailed reports on system performance, security, and compliance, helping organizations make informed decisions and maintain regulatory standards.
- Scalability: WMI integrations support the management of large-scale environments, making it easier to scale operations and maintain control over extensive IT infrastructures.
How do you access WMI events and manage WMI service configuration?
When you install Windows, the WMI automatically begins. If you’re looking for the WMI Provider Host on your system, you can find it by following these instructions:
- Press X and the Windows logo key at the same time (You can also right-click the start button on Windows 8 or 10). This is how you view verbose WMI activity events.
- Click the Event Viewer.
- Click the View button.
- Click Analytic and Debug Logs.
- Click on Applications and Service Logs (on the left side of the screen).
- Follow the path from Applications and Service Logs to Microsoft to Windows and then to WMI-Activity.
Another way to access the WMI Provider:
- Right-click the Windows logo/start and choose “Computer Management.”
- Then, click “Services and Applications.”
- Right-click on WMI Control.
- Select Properties.
What are some tips to keep your WMI provider host working effectively?
You may need these tips to keep your WMI provider running smoothly:
Monitor for High CPU Issues
To diagnose high CPU usage by Windows Management Instrumentation (WMI) on Windows, start by identifying whether WmiPrvse.exe or svchost.exe (hosting the Winmgmt service) is causing the issue.
Open Task Manager, enable the PID column, and locate the process-consuming CPU. Use Performance Monitor (Perfmon) for a graphical view of CPU usage per process. If svchost.exe is the cause, isolate the Winmgmt service by running sc config Winmgmt type= own in an elevated command prompt and restarting it, which allows tracking WMI independently.
Finally, investigate the specific WMI providers and client processes responsible using tools like Event Viewer, Process Explorer, or scripts, focusing on high-frequency queries and tasks tied to the identified process.
Disabling WMI
While turning off the WMI system is possible, you’re strongly advised not to do this. It is a crucial element of your Microsoft Windows 10 operating system, and if you deactivate it, most Windows software won’t operate correctly. Your WMI Provider Host is a system service that you shouldn’t turn off or disable.
How to Fix WMI Provider Host
To address high CPU usage by WMI Provider Host (WmiPrvSE.exe), it’s essential to run a thorough virus and malware scan to rule out any malicious software as a potential cause. Malicious programs often disguise themselves as system processes, like WMI, to avoid detection while consuming CPU and memory resources.
Start by updating your antivirus software and performing a full system scan. Additionally, use a trusted anti-malware tool to detect threats that antivirus might miss. If the scan identifies malware, follow the removal steps carefully and restart your system.
This step is crucial because resolving any underlying infections often restores normal CPU usage and protects your system’s performance and stability.
Safe Mode
If malware is detected and difficult to remove, restarting your computer in Safe Mode can help. Safe Mode runs only essential Windows processes, blocking most third-party programs and malware from starting up, making it easier to identify and remove persistent threats.
To enter Safe Mode, restart your computer, and press the F8 or Shift+Restart key (depending on your system) to access the advanced startup options. Choose Safe Mode with Networking to allow internet access if you need to download additional scanning tools.
Once in Safe Mode, rerun your antivirus and anti-malware scans. This environment often improves the effectiveness of removal tools, helping to clear out threats more completely and ensuring your system can run WMI Provider Host without interference from malicious software.
Conclusion
A WMI Provider Host is a necessary part of your operating system. It provides essential information, helps APIs run efficiently, and facilitates cloud computing. Keeping your WMI Provider Host running smoothly will help you successfully manage everything from operational environments to remote systems. While generally safe, it requires careful management to mitigate potential security risks. Restricting access, monitoring activity, and keeping systems updated can ensure an efficient and effective Windows environment supporting local and remote system management.
Managing observability across hybrid and multi-cloud environments is like flying a fleet of planes, each with different routes, altitudes, and destinations. You’re not just piloting a single aircraft; you’re coordinating across multiple clouds, on-premises systems, and services while ensuring performance, availability, and cost-efficiency. AWS customers, in particular, face challenges with workloads spanning multiple regions, data centers, and cloud providers. Having a unified observability platform that provides visibility across every layer is critical.
This is where LogicMonitor Envision excels. Its ability to seamlessly integrate observability across AWS, Azure, Google Cloud, and on-premises systems gives customers a comprehensive view of real-time performance metrics and logs, such as EC2 CPU utilization or Amazon RDS database logs. Additionally, LM Envision delivers visibility before, during, and after cloud migrations—whether you’re rehosting or replatforming workloads.
Let’s dive into how LogicMonitor makes managing these complex environments easier, focusing on features like Active Discovery, unified dashboards, and Cost Optimization.
The challenge of hybrid and multi-cloud: Coordinating your fleet across complex skies
Hybrid and multi-cloud environments are like managing multiple aircraft, each with its own systems and control panels. AWS workloads, on-prem servers, and Azure or Google Cloud applications have their own monitoring tools and APIs, creating silos that limit visibility. Without a unified observability platform, you’re flying blind, constantly reacting to issues rather than proactively managing your fleet.
Working at LogicMonitor, I’ve seen many customers struggle to manage hybrid environments. One customer managed 10,000 assets across multiple regions and cloud providers, using separate monitoring tools for AWS, on-prem, and their private cloud. They described it as “trying to control each plane separately without an overall view of the airspace.” (The analogy that inspired this blog!) This led to constant reactive management. By switching to LM Envision, they eliminated blind spots and gained complete visibility across their entire infrastructure, shifting to proactive management—the dream for ITOps teams everywhere.
Active Discovery: The radar system for automatically detecting new resources
Think of your infrastructure as an expanding airport. New terminals (services), planes (instances), and runways (connections) are constantly being added or modified. Manually tracking these changes is like trying to direct planes without radar. LM Envision simplifies this by automatically discovering AWS resources, on-prem data center infrastructure, and other cloud providers like Azure and Google Cloud. This visibility provides a comprehensive real-time view across services like Amazon EC2, AWS Lambda, and Amazon RDS.
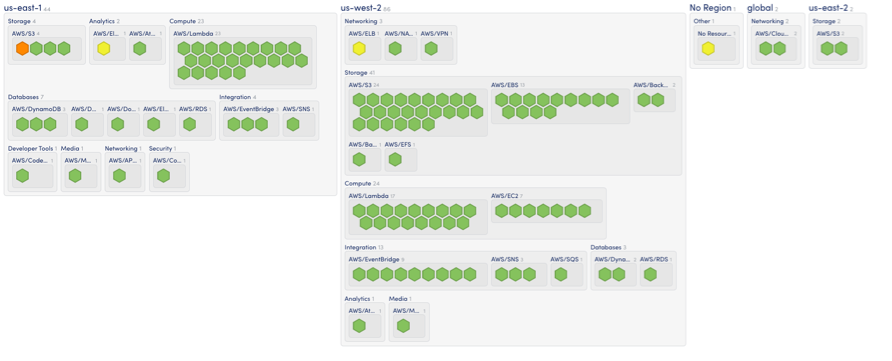
Now, think of LM Envision’s Active Discovery as the radar system that continually updates as new planes enter your airspace. For example, when you’re spinning up new AWS EC2 instances for a major campaign, you don’t have to worry about manually adding those instances to your monitoring setup. LM Envision automatically detects them, gathers performance metrics, and sends real-time alerts. It’s like flying a plane—LM Envision is the instrument panel, providing instant feedback so you can make quick decisions. You’ll always have a clear view of performance, allowing you to react immediately and prevent potential outages, ensuring smooth operations from takeoff to landing.
Unified dashboards: The control tower for complete IT visibility
In any complex environment, especially hybrid or multi-cloud setups, visibility is key. LM Envision’s unified dashboards act like the control tower for your fleet, offering a single pane of glass across AWS, on-premises systems, Azure, and Google Cloud. These customizable dashboards allow you to track key performance metrics such as CPU utilization, database performance, and network latency across all your environments.
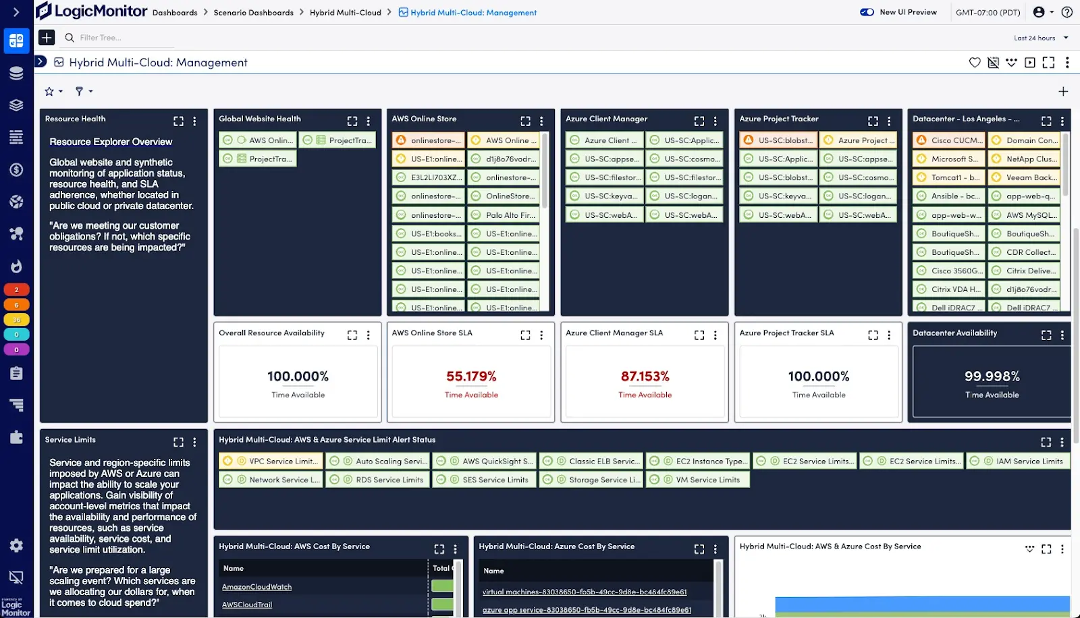
Think of these dashboards as your control tower. In a large airport, planes constantly land, take off, or taxi, and the control tower ensures everything runs smoothly. With LM Envision’s dashboards, you can monitor the health of your entire infrastructure in real time, from AWS EC2 instances to on-prem database health.
I’ve seen first-hand how these dashboards can transform operations. In one case, application latency spiked across multiple regions, but a customer’s traditional monitoring tools were siloed. They couldn’t easily tell if it was a network issue, a load balancer problem, or an AWS region failure. Once they implemented LM Envision, they built custom dashboards that provided insights into each layer of their stack, from the application down to the server and network level. When this issue happened again, within minutes, they isolated the root cause to an AWS load balancer misconfiguration in one region, drastically cutting troubleshooting time.
Cost optimization: The fuel gauge for efficient cloud spending
Managing costs in multi-cloud environments is like monitoring fuel consumption on long-haul flights—small inefficiencies can lead to massive overruns. AWS and Azure bills can quickly spiral out of control without proper visibility. LM Envision’s Cost Optimization tools, powered by Amazon QuickSight Embedded, provide a real-time view of your cloud spending. These dashboards enable you to identify idle EC2 instances, unattached EBS volumes, and other underutilized resources, ensuring you’re not wasting capacity.
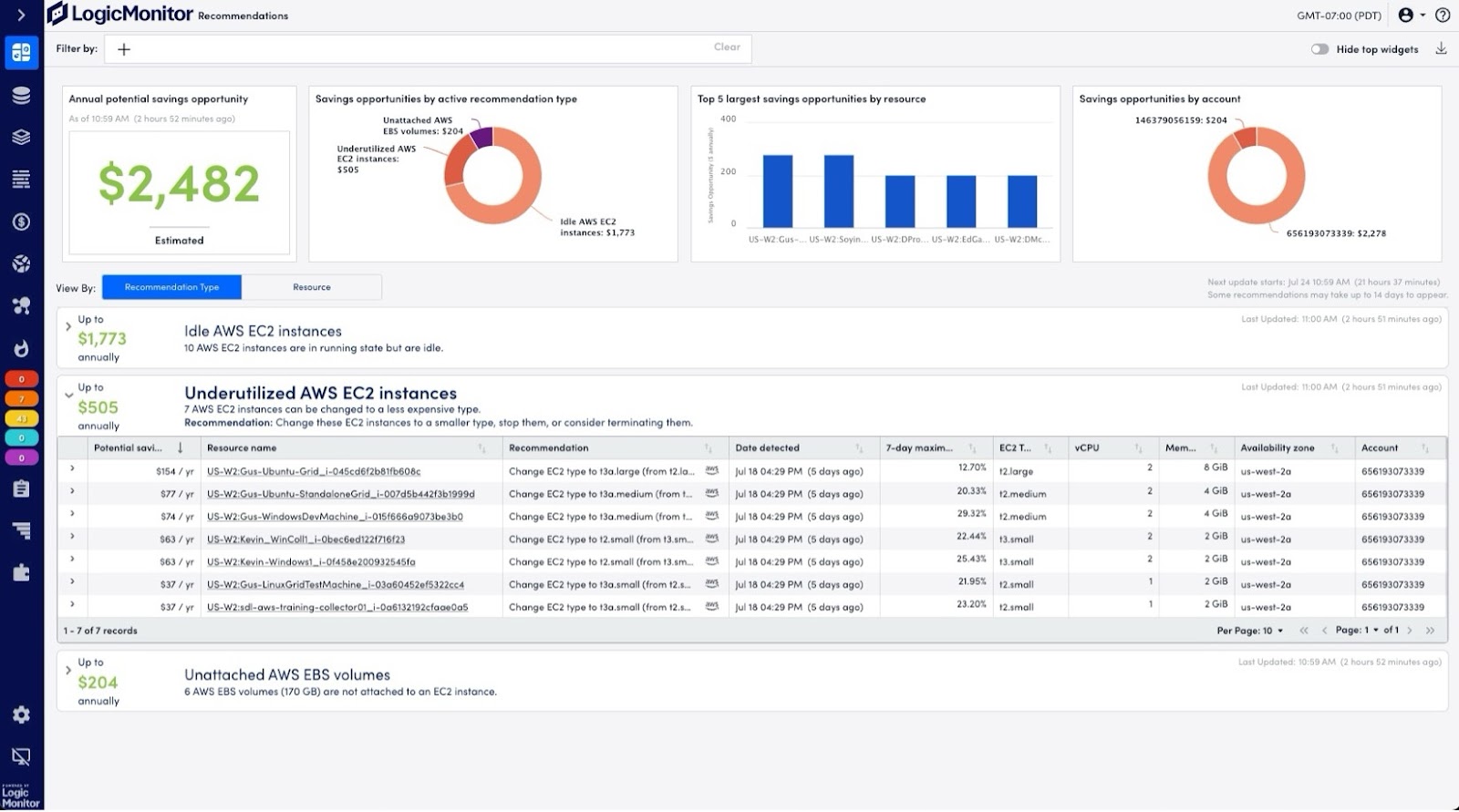
LogicModules—with over 3,000 pre-configured integrations for technologies such as HPE, Cisco, NetApp, and AWS services—help monitor your infrastructure for the latest efficiencies. This allows you to right-size your cloud infrastructure based on real-time usage data.
In fact, a customer identified thousands of dollars in savings by using LM Envision’s cost forecasting tools, which provided actionable insights into resource usage. It’s like ensuring your planes fly with just the right amount of fuel and optimizing their routes to avoid costly detours.
Monitoring cloud migrations: Navigating turbulence with real-time insights
Cloud migrations can feel like flying through turbulence—downtime, cost overruns, and performance degradation are some common challenges. With LM Envision, you can monitor each step of the migration process, whether you’re rehosting or replatforming workloads to AWS.
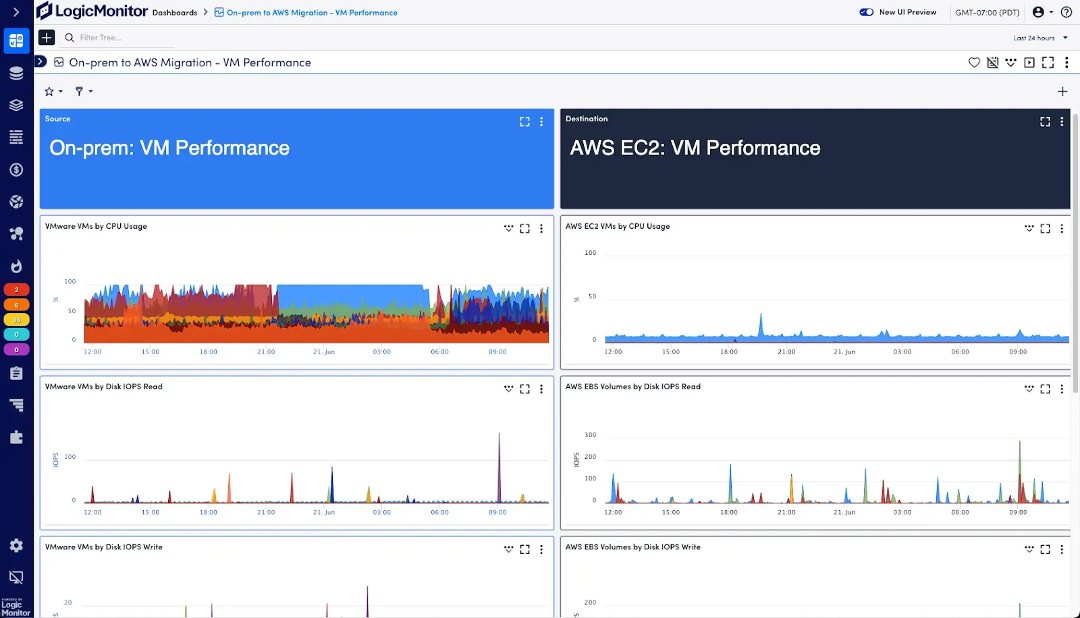
I’ve seen multiple cloud migrations where resource usage spiked unpredictably. In one migration to AWS, a customer saw sudden increases in EC2 CPU usage due to unexpected workloads. LM Envision allowed them to monitor the migration in real-time and adjust instance types accordingly, avoiding major downtime. The system’s real-time alerts during migration help you navigate smoothly, much like flight instruments helping pilots adjust their routes during turbulence.
Wrapping up
Managing hybrid and multi-cloud environments is now the standard, and effective management requires an observability platform that scales with your infrastructure. LM Envision not only provides real-time visibility and cost optimization but also reduces complexity, making it easier for IT teams to manage distributed workloads proactively.
With LM Envision, you transition from being a reactive firefighter to a skilled pilot managing your fleet from the control tower. It ensures you keep your operations running smoothly, whether monitoring performance, scaling your infrastructure, or optimizing costs.
In today’s complex IT environments, logs are the unsung heroes of infrastructure management. They hold a wealth of information that can mean the difference between reactive firefighting and proactive performance tuning.
What is log analysis?
Log analysis is a process in modern IT and security environments that involves collecting, processing, and interpreting log information generated by computer systems. These systems include the various applications and devices on a business network.
From security breaches to system performance optimization, log analysis is indispensable for IT operations and security teams alike. However, understanding how to efficiently leverage this wealth of data is no small feat.
Based on my decades of experience managing IT environments, I’ve seen firsthand the critical role of effective log analysis in maintaining system health, security, and compliance. Over the years, this discipline has evolved—from manual log parsing in the early days to today’s AI-powered insights that help teams manage vast amounts of data in real-time.
In this guide, I’ll walk you through core log analysis concepts, share advanced techniques, and provide real-world insights to help you understand how to extract actionable information from your logs.
Core concepts of log analysis
At its essence, log analysis is a step-by-step process that involves collecting data from various devices and ingesting it into monitoring applications for review.
You can break it down into several steps:
Data collection
Effective log analysis begins with collecting data from various sources like servers, applications, and network devices. This process is often underestimated, but it’s the foundation for everything that follows. One common pitfall I’ve seen is missing log sources, leading to incomplete analyses and delayed troubleshooting.
I once missed a critical log source in a third-party vendor’s server, which delayed our root cause analysis by hours. After adding that missing source, we finally pinpointed the issue—a simple configuration error that could have been caught earlier with proper log collection.
By ensuring complete coverage of all devices and systems, you can prevent major issues from going undetected, simplifying later steps in the process.
PRO TIP
Configure all data sources properly to avoid gaps in your log data.
Data processing
Once logs are collected, the next challenge is processing them effectively. Raw logs contain a lot of noise—irrelevant data that can cloud your analysis. In my experience, indexing and normalizing logs is crucial for reducing this noise and ensuring you can focus on the actionable data.
Many teams make the mistake of assuming they can get away with analyzing raw logs. Unstructured logs often lead to information overload, making it hard to extract meaningful insights. Structuring your data through normalization makes things far easier, allowing you to search, analyze, and correlate events across your systems more easily.
Data analysis
Now comes the part that used to be the most time-consuming—analyzing the logs. In the past, IT teams would spend hours manually combing through logs, looking for patterns. However, this approach is neither practical nor scalable in today’s complex hybrid environments. Tools that leverage AI and machine learning have become essential in detecting patterns and anomalies in real-time, significantly improving troubleshooting and incident detection efficiency.
I remember an incident where AI flagged a series of login attempts across multiple devices. It appeared normal on the surface, but on closer inspection, these were part of a coordinated brute force attack. Without AI’s pattern recognition abilities, this might have slipped through the cracks. The takeaway here is that manual log analysis is outdated. AI-powered tools are essential to keep up with the volume and complexity of modern IT environments.
Data visualization
Log data is only valuable if you can quickly interpret it, which is why visualization is crucial. Dashboards and reports help surface trends and anomalies, helping your team make quicker decisions with a real-time system health and performance overview.
I’ve seen poorly designed dashboards cost teams hours—if not days—of productivity. One time, I was dealing with performance issues, but our dashboard wasn’t set up to visualize the right metrics. It took hours to isolate the problem. After redesigning the dashboard to prioritize key performance indicators (KPIs), we identified issues in minutes. The right visualization tools make the difference between proactive monitoring and reactive firefighting.
PRO TIP
Executives appreciate dashboards that help them understand what they care about most in one quick-to-digest view.
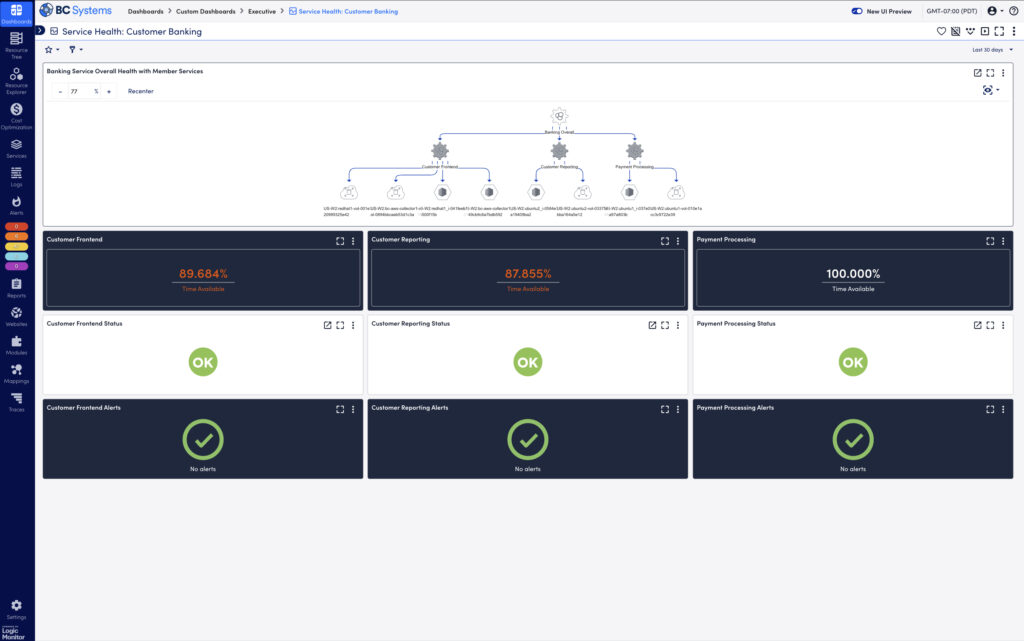
What is log file analysis?
Log file analysis involves examining logs generated by IT systems to understand events, detect issues, and monitor performance. This step is critical in maintaining a healthy IT infrastructure. Proper log parsing can reveal invaluable insights about what’s happening under the hood, whether you’re troubleshooting or investigating security incidents.
In my experience, the biggest challenge is often dealing with unstructured log files. We already discussed how overwhelming raw logs can be, and finding a single root cause can feel like searching for a needle in a haystack. Here’s where techniques like parsing, filtering, and time-based analysis come into play:
- Parsing: This breaks down log files into structured data fields, making categorizing and understanding events easier. For example, during a major outage, we used log parsing to quickly identify misconfigurations in a load balancer, which helped resolve the issue in minutes rather than hours.
- Filtering: Effective log filtering isolates relevant log entries, helping you narrow your focus. I recall a scenario where we filtered out hundreds of benign logs to zero in on suspicious activity linked to unauthorized access attempts.
- Pattern matching: Recognizing recurring patterns in log files is crucial for detecting repeated failures or malicious activity. For example, we once identified a repeated log entry pattern that pointed to intermittent system crashes caused by a faulty update.
- Time-based analysis: This technique examines log entries within specific time frames to understand event sequences and dependencies. In one incident, we used time-based analysis to trace a system outage back to scheduled network maintenance that conflicted with other critical processes. By analyzing logs in the hours leading up to the issue, we discovered that overlapping changes caused a cascade of failures. This approach is especially useful for troubleshooting complex incidents where timing plays a key role.
These techniques allow you to break complex, individual files into manageable components to structure data, quickly sort it, and surface relevant information. They also structure data to allow it to be imported into a central server, helping you gain a bird’s-eye view of a computer network and its individual components from a central location.
PRO TIP
A centralized monitoring solution streamlines log analysis by aggregating logs from multiple sources, applying filters and analysis techniques to surface relevant information faster. This reduces team overhead and response times, while enabling advanced features like cross-system correlation, simplifying the resolution of complex issues.
What is security log analysis?
Security log analysis is a specialized form of log analysis that your security team can use to examine logs to mitigate security threats. With cybersecurity now a top priority for organizations, effective log analysis has become a critical component of a robust security posture. From my experience, analyzing security logs effectively requires more than just looking for unusual activity—it’s about correlating events across different log sources. Here’s how security log analysis can help:
- Detect unauthorized access: Monitoring logs for failed login attempts, suspicious IP addresses, and privilege escalations can help identify malicious activities. I’ve seen how correlating these seemingly isolated events can reveal larger coordinated attacks.
- Investigate security breaches: When a breach occurs, log analysis plays a pivotal role in understanding what went wrong. In one case, analyzing logs helped us trace back a data exfiltration event to a compromised user account, allowing us to mitigate the damage.
- Real-time threat detection: Advanced security log analysis tools leverage AI and machine learning to detect anomalous behavior automatically. For instance, we once identified malware attempting lateral movement in our network thanks to real-time anomaly detection. Without this, the malware could have spread unnoticed.
- Compliance monitoring: In regulated industries (e.g., healthcare, finance), security log analysis helps ensure compliance with frameworks like GDPR, HIPAA, and PCI DSS by maintaining thorough audit logs and generating compliance reports. In my experience, failing to configure security logging properly is a common mistake that can lead to compliance violations.
Integrating log analysis with Security Information and Event Management (SIEM) tools, which automate threat detection and correlate events across the network, is essential to reduce response times and improve overall security posture.
What is event and network log analysis?
Both event and network logs are critical for understanding system health, application behavior, and network traffic flow. Event logs come from individual devices and detail what happens on the systems and any errors. Network logs look at network devices (such as switches, modems, and hardware firewalls) and help network engineers understand traffic flow.
Analyzing these logs can help IT teams ensure system reliability and network performance while preempting potential issues.
Event log analysis
Event logs provide detailed information about system events and application behavior. These logs are invaluable when it comes to:
- Troubleshooting application errors: Event logs are the first place I look when diagnosing application failures. For instance, when an internal CRM system crashed intermittently, the event log helped us pinpoint a memory leak causing the issue.
- Monitoring system health: By regularly analyzing event logs, IT teams can identify issues before they lead to system outages. I’ve used this to detect disk failures in advance, allowing us to replace faulty hardware without downtime.
- Tracking user activity: Event logs can track user activity, including authorization events. This helps ensure that only authorized personnel access critical systems, adding an extra layer of security.
Network log analysis
On the other hand, network log analysis focuses on network devices like routers, switches, and firewalls, helping you understand traffic flow and network health:
- Network performance: In my experience, analyzing network logs is essential for spotting bandwidth issues or network bottlenecks. For example, network logs helped us detect and troubleshoot a bandwidth hog disrupting our video conferencing services.
- Detecting network anomalies: Network logs can reveal unusual traffic patterns or suspicious connections. A few years ago, a spike in network traffic during off-hours prompted us to investigate. Network logs confirmed data exfiltration attempts, allowing us to take immediate action.
- Connectivity issues: Network logs provide crucial insights when diagnosing connectivity problems. They can help you verify whether issues are caused by misconfigured devices, ISP problems, or internal hardware failures.
CONSIDER THIS SCENARIO
You’ve just implemented a routine firmware update on your firewall, and suddenly, your network connectivity starts behaving erratically. It’s a situation that can quickly escalate from a minor inconvenience to a major problem affecting your entire organization.
In these moments, network logs become an invaluable troubleshooting resource. They act as a detailed record of your network’s behavior, offering crucial insights into the root cause of the problem. Here’s what to look for:
TIMING CORRELATION:
Your logs will pinpoint exactly when the issues began, often aligning perfectly with the update’s timestamp.
ERROR MESSAGES:
Keep an eye out for specific error codes related to the new firmware. These can indicate compatibility issues or problems with the update itself.
TRAFFIC ANOMALIES:
Unusual patterns in packet handling or connection resets can signal that your firewall isn’t processing traffic correctly post-update.
CONFIGURATION CHANGES:
Sometimes, updates can inadvertently alter firewall rules. Your logs might reveal these unexpected changes.
PERFORMANCE METRICS:
Sudden spikes in CPU usage or memory consumption on the firewall can indicate that the new firmware is causing resource issues.
By carefully analyzing these log entries, you can quickly identify whether the firmware update is the culprit and take appropriate action. This might involve rolling back to a previous version or applying additional patches to resolve the issue.
Combining network and event log analysis gives a comprehensive overview of your IT environment, helping you maintain end-to-end visibility across both systems and networks. This integrated approach is particularly useful when investigating complex issues, as it lets you see how events in one system may affect network performance and vice versa.
Advanced techniques in log analysis
While basic log analysis can provide immediate insights, the real value comes from using advanced techniques to uncover patterns, correlations, and trends.
Pattern recognition and anomaly detection
Pattern recognition goes beyond manual analysis by using tools to analyze log files—whether individual log files or network logs—to find patterns. It uses machine learning (ML) and statistical algorithms to establish a baseline for “normal” behavior across your systems. Comparing new log entries against this baseline through tools like ML can detect anomalies that might indicate a security breach, performance issue, or other critical event. I’ve found that implementing these tools has significantly reduced false positives, allowing teams to focus on real threats rather than sifting through noise.
For instance, pattern recognition once helped my team identify a recurring issue in a distributed application. We could predict system crashes hours before they occurred, enabling us to implement preventative measures and avoid costly downtime.

Correlation and event linking
Correlation and event linking work by connecting log events across different sources, helping you to piece together the full scope of incidents. For example, a single failed login might not raise alarms, but it could indicate an attempted breach when it’s correlated with similar events across multiple devices. This technique helps teams track the path of attacks and identify the root cause of complex issues.
In one memorable case, event correlation allowed us to stop a malware infection before it spread to critical systems. Multiple unrelated log events pointed to what seemed like minor issues, but once correlated, they revealed the early stages of a significant security incident.
Visualization and dashboards
When dealing with tens of thousands of log events, it’s easy to miss the bigger picture. Data visualization tools can help you spot trends, anomalies, and potential issues in real-time. For example, using a historical performance graph, I’ve been able to visually track performance metrics over time, which was critical in pinpointing an issue. We noticed that performance would degrade noticeably every day at a specific time. This led us to investigate correlated events in the logs, revealing a recurring resource contention issue with a background task that coincided with peak user activity. Without these visualizations, that pattern might have gone unnoticed.
Well-configured dashboards allow for faster incident response and allow both technical teams and executives to make informed decisions based on real-time insights. This empowers informed decision-making for proactive system maintenance or strategic infrastructure planning.
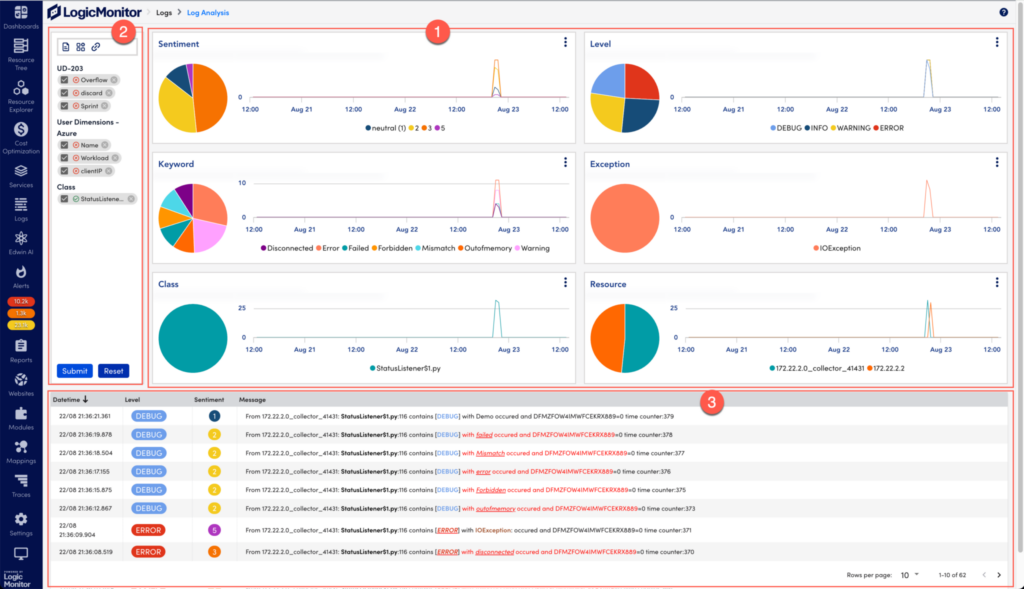
Common challenges in log analysis
While the benefits of log analysis are clear, there are also significant challenges to overcome.
Data volume and complexity
The sheer volume and variety of data collected with logs—especially in large enterprises—can be overwhelming.
A few things I recommend are:
- Implement efficient log aggregation and storage solutions to ensure only actionable information surfaces
- Use scalable platforms to avoid storage problems, lost data, and proper log retention
- Use intelligent filtering and prioritization techniques to help you find the necessary information
Focus on what’s critical first so you’re not drowning in unnecessary data.
PRO TIP
Ensure redundancy in log management by implementing backup strategies with both on-premises and cloud systems. This protects against data loss, supports compliance, and guarantees audit trails and log accessibility during storage failures.
False positives and real-time analytics
Another challenge is false positives. I’ve seen teams waste time chasing down harmless events because of poorly tuned alerting systems. Your team can address this challenge in a few ways:
- Fine-tune alerting thresholds and rules to surface the most relevant information. In one instance, after tuning our alert thresholds and adjusting the conditions under which alerts were triggered, we reduced false positives by over 50%. By narrowing down the scope of what triggered alerts, we were able to filter out events that were normal system behaviors and focus on genuinely anomalous activity.
- Use machine learning algorithms with monitoring software to help isolate the most relevant alerts. These algorithms help isolate the most relevant alerts by learning what normal operational patterns look like over time. In one case, after implementing machine learning-based monitoring, we saw a 60-70% reduction in false positives, as the system became better at recognizing typical behavior and flagging only outlier events.
- Use context-aware analysis to improve alert accuracy. For example, a CPU spike might trigger an alert, but context-aware analysis could recognize that the spike coincided with a scheduled batch job, preventing an unnecessary alert. With this method, we managed to trim down our false positive rate even further, leading to a more streamlined and effective incident response process.
Alerting mechanisms
Getting alerting mechanisms to produce the most relevant alerts can be challenging in complex logging environments. The process involves thinking about the most critical information, isolating it, and surfacing it above irrelevant data.
Some solutions are to:
- Prioritize alerts based on severity and impact to ensure that your team is responding to the most critical issues first
- Implement automated response workflows based on the severity of events, allowing for quicker resolution of common, low-severity incidents while reserving human intervention for more complex issues
- Ensure alerts are actionable and provide clear next steps so that responders can immediately know what to do when an alert is triggered, reducing the time spent diagnosing the problem
In one of our environments, we were dealing with a flood of alerts, many of which were of low priority or false positives. By refining our alerting mechanisms to focus on severity and impact, and implementing automated response workflows, we saw a dramatic improvement in our incident response times. For example, we automated responses for low-severity issues like disk space nearing capacity by scripting automatic clean-up tasks. This reduced human intervention by about 30% in these cases.
Additionally, we ensured that higher-priority alerts, such as potential security breaches or application downtime, were accompanied by detailed action steps, reducing ambiguity and the time it took to resolve incidents. As a result, our team’s mean time to resolution (MTTR) for critical incidents improved by 40%, and we responded to significant issues faster without being bogged down by less relevant alerts. This approach enhanced response times, minimized alert fatigue, and allowed our team to focus on the most pressing matters.
Use cases and real-world applications
Log analysis has proven invaluable across many different industries and applications. Let’s explore some real-world log analysis applications and stories we’ve seen that highlight its potential.
CMA Technologies
CMA Technologies switched anti-virus solutions and encountered problems with virtual machines that caused them to go offline. Their previous infrastructure didn’t offer enough information to perform root cause analysis to find the cause of the problem, putting customers in jeopardy and introducing security issues.
Implementing LM Logs allowed CMA Technologies to receive actionable alerts when a potential issue could bring a virtual machine offline, allowing them to reduce their Mean Time to Recovery (MTTR). It also provided dashboards that offered more visibility into the entire organization.
Bachem Holding AG
Bachem’s IT team suffered from major alert fatigue. Although they were able to collect information about what was happening in the IT infrastructure, the sheer number of alerts made it hard to hone in on the important alerts to deal with critical issues.
LogicMonitor offered a solution to help get the most out of log analysis. Proper log analysis reduced the number of alerts and saved the team 10 hours. This allowed them to focus on the important issues and refocus on projects that help the business.
Future of log analysis
Log analysis is evolving rapidly, and the future looks promising for what’s to come on the horizon. Some things I’ve gathered from industry leaders and reports are that:
- AI and machine learning will continue to grow within log analysis to improve predictive analytics, automated root cause analysis, and anomaly detection
- There will be faster, real-time processing at the network edge, which will allow organizations to handle exponential data growth
- Interactive dashboards and augmented analytics will make data interpretation even more intuitive
- There will be better logging capabilities through new technology like IoT devices and 5G connections
- With more businesses moving to cloud-native and microservices architectures, advanced logging will be essential to maintain visibility across distributed systems
LogicMonitor Envision’s log analysis features
LogicMonitor Envision’s log analysis feature helps your organization surface errors in log data—helping teams of all levels and industries find problems with just a few clicks.
Instead of indexing, looking through data with query language, or training, you can use AI to analyze thousands of logs. Your data is categorized by severity, class, and keywords, making manual searches obsolete.
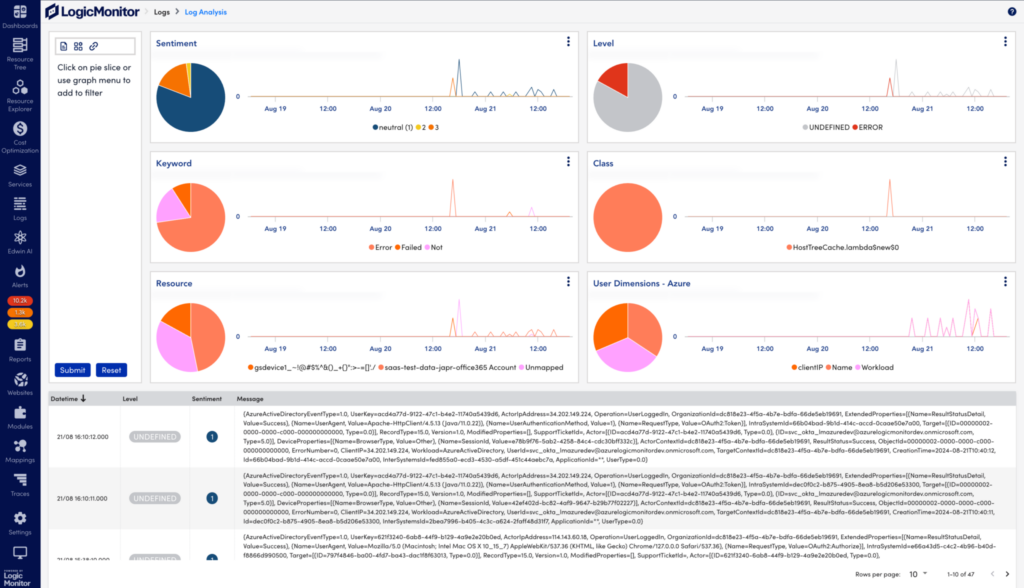
LM Envision can do this with a few key features:
- AI-powered analysis: Automatically categorizes logs to surface information without manual searches and detect anomalies to save you the manual work of categorizing and monitoring information
- Intuitive visualizations: Correlates IT and business metrics to understand the true impact of IT performance and perform root cause analysis, helping you troubleshoot faster to reduce MTTR
- Sentiment scoring: Prioritizes issues based on severity levels—allowing you to focus on the most critical problems
- Negative phrases: Tags logs with negative keywords to surface only important information. For example, add less critical keywords to negative phrases and look at errors that can pinpoint problems
- Customizable insights: Tailors log analysis based on your organization’s needs and goals, such as alerting by keyword, sentiment scores, and other filters
- Central log management: Centralizes log management to make it easier to monitor system performance, avoid the need to monitor individual devices, and save time
- Edwin AI: LogicMonitor’s GenAI-powered assistant allows organizations to use natural language to query log data built using unstructured and structured data from your organization
Wrapping up
Log analysis isn’t just a troubleshooting tool—it’s a strategic asset that can enhance your IT environment’s security posture, performance, and compliance. By leveraging advanced techniques like AI-powered pattern recognition, event correlation, and real-time visualization, your team can proactively address issues before they become critical.
O11y (short for Observability and pronounced “Ollie“), is the ability to understand a system’s internal state by analyzing external data like logs, metrics, and traces. It helps IT teams monitor systems, diagnose issues, and ensure reliability. In modern tech environments, observability prevents downtime and optimizes user experiences.
O11y builds on the original concept pioneered by Rudolf Emil Kalman through his work in control theory. In essence, it allows teams to monitor complex systems without requiring additional coding or services, which can otherwise lead to costly downtime.
Observability vs. monitoring
Is observability the same as monitoring? No, although the ability to achieve observability may somewhat rely on effective monitoring tools and platforms. It could be said that effective monitoring tools augment the observability of a system.
Monitoring is an action, something someone does: they monitor the effectiveness or performance of a system, either manually or by using various forms of automation. Tools for monitoring collate and analyze data from a system or systems, providing insights and suggesting actions or adjustments where necessary. Some monitoring tools can provide basic but crucial information, such as alerting a system administrator when a system goes down or, conversely, when it goes live again. Other monitoring tools might measure latency, traffic, or other aspects of a system that can affect the overall user experience. More advanced tools may link to dozens, hundreds, or even thousands of data streams, providing broad-ranging data and analysis for complex systems.
Observability isn’t a form of monitoring. Rather, it’s a description of the overall system, an aspect of the system that can be considered as a whole, in the same way that someone might talk about the functionality of the system. The observability of a system determines how well an observer can assess the system’s internal state simply by monitoring the outputs. If a developer can use the outputs of a system — for example, those provided by APM — to accurately infer the holistic performance of the system, that’s observability.
To summarize, monitoring is not a synonym for observability or vice versa. It’s possible to monitor a system and still not achieve observability if the monitoring is ineffective or the outputs of the system don’t provide the right data. The right monitoring tools or platforms help a system achieve observability.
Understanding the three pillars of observability
A common way to discuss observability is to break it down into three types of telemetry: metrics, traces, and logs. These three critical data points are often referred to as the three pillars of observability. It’s important to remember that although these pillars are key to achieving observability, they are only the telemetry and not the end result.
Logs
Just like the captain’s log on a ship, logs in the technology and development world provide a written record of events within a system. Logs are time-stamped and may come in a variety of formats, including binary and plain text. There are also structured logs that combine text and metadata and are often easier to query. A log can be the quickest way to access what’s gone wrong within a system.
Metrics
Metrics are various values monitored over a period of time. Metrics may be key performance indicators (KPIs), CPU capacity, memory, or any other measurement of the health and performance of a system. Understanding fluctuations in performance over time helps IT teams better understand the user experience, which in turn helps them improve it.
Traces
A trace is a way to record a user request right along its journey, from the user interface throughout the system, and back to the user when they receive confirmation that their request has been processed. Every operation performed upon the request is recorded as part of the trace. In a complex system, a single request may go through dozens of microservices. Each of these separate operations, or spans, contains crucial data that becomes a part of the trace. Traces are critical for identifying bottlenecks in systems or seeing where a process broke down.
Additional factors for achieving observability
Even using this telemetry, observability isn’t guaranteed. However, obtaining detailed metrics, logs, and traces is a great way to approach observability. There is some crossover between these different types of telemetry, especially in the data they provide.
For example, metrics around latency may provide similar information to a trace-set on user requests that also give information on latency by showing where latency occurs in the system. That’s why it’s important to view observability as a holistic solution — a view of the system as a whole, but created using various types of telemetry.
Events are another type of telemetry that can be used to help achieve observability. Often, logs, metrics, and traces are used to provide a cohesive view of system events, so they can be considered as more detailed telemetry of the original data provided by various events within a system.
Dependencies or dependency maps give the viewer an understanding of how each system component relies on other components. This helps with resource management, as ITOps can clearly understand which applications and environments use the IT resources within a system.
Regardless of which exact types of telemetry are used, observability can only be achieved by combining various forms of data to create this “big picture” view. Any single one of the pillars of observability on its own provides very little value in terms of visibility and maintenance of a system.
The importance of observability and its growing adoption
Although observability as a concept comes from the realm of engineering and control theory, it’s widely adopted by the tech world. Technology is advancing so quickly that developers are under pressure to constantly update and evolve systems, so it’s never been more crucial to understand what’s going on inside those rapidly changing systems.
Achieving observability empowers users to update and deploy software and apps safely without a negative impact on the end-user experience. In other words, o11y gives IT teams the confidence to innovate with their apps and software as needed.
Observability provides developers and operations teams with a far greater level of control over their systems. This is even more true for distributed systems, which are essentially a collection of various components or even other, smaller systems networked together. There are so many data streams coming from these various systems that manually collating this data would be impossible, which is where automation and advanced, ideally cloud-based, modern monitoring solutions are crucial to deal with the sheer volume of data. However, to achieve observability, the quality of these data streams has to provide a level of deep visibility that allows questions around availability and performance to be answered and dealt with efficiently.
Modern development practices include continuous deployment and continuous integration, container-based environments like Docker and Kubernetes, serverless functions, and a range of agile development tools. APM-only solutions simply can’t provide the real-time data needed to provide the insights that teams need to keep today’s apps, services, and infrastructure up and running and relevant to a digitally demanding consumer base. Observability indicates high-fidelity records of data that are context-rich, allowing for deeper and more useful insights.
Expanding beyond the three pillars of observability
It’s important to note that the three pillars of observability by themselves don’t provide the holistic view that’s desirable when considering the internal states of systems. A better way to think about hybrid observability might be to cohesively combine the three pillars plus those other considerations mentioned above to look at an overall, detailed image of the entire tech ecosystem rather than focusing on individual components.
Imagine one of those pictures made with multiple leaves of tracing paper. The first leaf has a background on it. Lay down the next leaf, and you can see some trees, maybe some houses. The next leaf has some characters on it, while the final leaf has speech bubbles, showing what everyone is saying and doing. Each leaf on its own is an accurate part of the picture but makes little sense on its own. It’s completely out of context.
Putting all the components together creates a detailed picture that everyone can understand. That is effective observability, and it can only be achieved by carefully considering all the components as one holistic view of the system. Each data point is a form of telemetry, and observability is achieved by combining telemetry effectively. Observability-based solutions provide a platform and dashboard that allow users to tap into that detailed telemetry and maximize their development opportunities.
There’s a tendency for IT teams to believe they have to pay three different vendors to provide the three pillars of observability, which becomes a potentially costly exercise. Once again, we return to the very crucial point that observability is holistic, which means that having all this telemetry separately is not the key to achieving observability. The telemetry needs to work together, meaning that while the three pillars are a good starting point, they’re not an endpoint or a guarantee of an effectively maintainable system.
User experience and business analytics in observability
While the three pillars of observability—metrics, logs, and traces—are essential, focusing on these alone may overlook the critical aspect of user experience (UX) and business analytics. Modern observability platforms, like LogicMonitor, provide insights that go beyond raw data, offering a seamless One-Click-Observability™ experience to evaluate the user journey across systems.
User experience as a core focus
In today’s distributed environments, achieving full observability means more than just tracking internal system states. It also requires ensuring that users experience optimal performance without disruptions. LogicMonitor’s One-Click-Observability™ allows teams to quickly correlate alerts with relevant logs and metrics without manual intervention, providing a holistic view of how system issues impact end-user performance. By automatically detecting anomalies and offering pre-configured views, IT teams can confidently identify root causes and improve the user experience, resulting in reduced downtime and faster response times.
Business analytics: Aligning IT with business outcomes
Effective observability directly impacts business outcomes. With the ability to track system performance metrics in real time, observability platforms allow businesses to monitor how application performance influences key objectives, such as conversion rates, user engagement, and revenue generation. By integrating business analytics into observability dashboards, companies can correlate IT metrics with operational performance, enabling teams to proactively optimize resources and support growth strategies. LogicMonitor’s platform empowers businesses to make data-driven decisions, using observability to not only resolve technical issues but also enhance overall business efficiency.
Key benefits of observability
Of course, there’s no point in focusing on improving a system’s observability unless there are measurable benefits, not just to the developer in terms of ease of system maintenance and improvement but also to the business as a whole.
Reducing costs
The majority of decisions in any business are driven by concerns about cost or profit. The more costly an app or system is to develop, operate, and update, the more that cost has to be potentially passed on to the consumer. That can reduce the apparent value of systems, so anything that keeps costs down and increases profits is welcome. ITOps and DevOps costs can be lowered by having a better and more intuitive understanding of the internal states of systems. Effective data streams paired with data analytics and the right monitoring platforms mean less manual observation is required, plus updates can happen faster and with more confidence. This reduces the number of employee hours required to keep a system at peak performance, plus faster, more effective updates increase the value of the system as a whole.
Enabling DevOps to prioritize user experience
When developers and operations teams don’t have to spend hours diving deep into the internal workings of a system, they have more productive time available. This is time that can be spent creating better ways for users to engage with the metrics that matter and improving the overall user experience. Again, this has financial implications, as the better a system works, the more desirable it is to consumers. Even free-of-charge software and apps increase the value of a company when they work seamlessly because of the increase in positive reputation of the development team in question.
Preventing downtime and system failures
Whether a business’s systems are completely internal or used to provide services to consumers, downtime can be devastating. It’s great to have contingency plans in place for when IT crises occur, but it’s even better to have an observable solution that allows systems to stay online for the majority of the time. Having a detailed yet holistic understanding of the state of a system allows changes and updates to be made promptly to deal with issues that may otherwise cause the system to go down entirely. Observability promotes stability, something consumers expect more and more from the apps and software they use daily.
Improving future planning and scalability
Deep visibility of the internal workings of a system combined with rich data and event analysis doesn’t just help DevOps deal with what’s happening right now; it helps them project future events and plan effectively for the future. This can be done by understanding potential peak times and capacity fluctuations, allowing for the effective reallocation of resources. This can also alert DevOps to quieter times when testing of new services might be more appropriate. Plus, having an observable system means those tests become all the more effective and less likely to cause a system crash or downtime.
Common observability use cases
Some common use cases of observability in modern IT systems include:
- Monitoring System Health: Observable systems enable real-time monitoring of health and performance, allowing for quick issue resolution.
- Detecting Anomalies: Observable systems help identify anomalies and patterns, allowing proactive management of potential future issues.
- Identifying Bottlenecks: Observability reveals insights that help DevOps find bottlenecks and improve scalability by reallocating resources.
- Troubleshooting: With data lineage tracking, DevOps can quickly troubleshoot and identify root causes, reducing mean time to resolution (MTTR).
- Optimizing Resources: A clear understanding of resource utilization allows DevOps to optimize allocation for better efficiency and cost savings.
- Validating Changes: Monitoring system performance before and after changes ensures that updates do not negatively impact overall system performance.
Main challenges in achieving observability
We’ve already mentioned some of the challenges that occur when trying to achieve observability. A key one is becoming fixated on having the best metrics data, or the most complete traces, to the point of paying individual vendors to provide these. While this can be an effective solution for those companies willing and able to collate and combine this telemetry, it’s much closer to observability to have all this information in one place.
Another frequently occurring challenge is not getting hung up on the three pillars of observability but being willing to look beyond them, as we explored further up in the article. Other challenges include:
- Scalability – achieving the same level of observability no matter how software, apps, and systems grow (or shrink).
- Increasingly complex cloud environments.
- Dynamic containers and microservices.
- Increasing volumes and types of data and alerts from a variety of sources.
- DevOps and other teams use multiple monitoring or analytics tools that don’t necessarily sync with each other.
It may seem daunting for some companies to overcome these obstacles, but it is possible to achieve good observability by looking at sensible and efficient ways to deal with these challenges head-on.
Building a future-proof observability strategy
Dealing with the scalability of observability means addressing some of those other challenges first. When your system deals with a range of cloud-based environments, it’s worth thinking about advanced monitoring tools that function either exclusively on the cloud or in a hybrid environment. Tools that are built to deal with the modern cloud are more likely to adapt to changes within cloud environments, giving users stability and consistency in data analysis.
Major vendors like Amazon Web Services (AWS), GCP, and Azure all support something called OTel, or the OpenTelemetry Project. This project aims “to make high-quality telemetry a built-in feature of cloud-native software.” This is great news for DevOps teams investing in a cloud-based future for their apps and software. OTel bills itself as “an observability framework,” providing tools, SDKs, and APIs purely for analysis of a system’s performance and behavior. The aim is to provide some level of observability regardless of which third-party vendors businesses choose and to provide low-code or no-code solutions for observability.
Another way to ensure scalability for observability solutions is to ensure the right type of data store is used. Datastores and data warehouses need to be able to expand and diversify exponentially to deal with the increasing volume of data and the various types of data streaming from a variety of sources. ETL and ELT solutions help bring data together in a single, usable format and into a single destination. Again, it’s about looking at how the system works as a whole and ensuring that every aspect of it can grow as the system or software does.
What does the future of IT observability look like in 2025?
While it’s difficult to predict the exact trajectory of IT observability in the future, we can identify several trends that are likely to shape the industry in the coming years:
- Continued AI and ML advancements: As AI and ML technologies continue to mature, we can expect further improvements in automated anomaly detection, root cause analysis, and predictive analytics. This will enable organizations to be even more proactive in identifying and resolving issues before they impact end-users.
- AIOps and the rise of autonomous systems: The integration of AI and ML into IT operations (AIOps) will pave the way for more autonomous systems capable of self-healing and self-optimization. This will help reduce the burden on IT teams and improve overall system reliability.
- Serverless and Function as a Service (FaaS) observability: With the growing adoption of serverless architectures and FaaS, new observability challenges will arise. The industry will need to develop new approaches and tools to monitor, troubleshoot, and optimize serverless applications and infrastructure.
- Privacy-aware observability: As privacy regulations continue to evolve, there will be an increased emphasis on ensuring that observability data is collected, stored, and processed in compliance with applicable laws and regulations. This may lead to the development of privacy-preserving observability techniques and tools.
- Enhanced network observability: With the continued expansion of edge computing, 5G, and IoT, network observability will become even more critical. Advanced monitoring and analytics tools will be required to manage the growing complexity and scale of these networks.
- More granular and real-time insights: As organizations become more reliant on their IT systems, the demand for real-time, granular insights into system performance and health will continue to grow. This will drive the development of more sophisticated monitoring and analytics tools capable of providing this level of detail.
- Observability for quantum computing: As quantum computing begins to gain traction, new observability tools and techniques will be required to monitor, manage, and optimize these emerging systems.
How close are you to full observability?
Understanding how close you are to full observability revolves around thinking about the following questions:
- How easy is it for you to obtain key telemetry such as logs, traces, and metrics?
- What level of analysis do you get from this telemetry? How useful is it to you?
- Do you have to do additional coding and development to understand the internal states of your systems?
- Can you gain a big-picture analysis of your whole system in real time?
If you answered “Very easy,” “Very detailed,” “No,” and “Yes” in that order, then you might be close to achieving full observability within your systems and software. A sudden surge in your scaling shouldn’t be an issue because your detailed analysis will project this and offer solutions that you can easily implement without draining the system’s existing resources. Problems with latency or infrastructure are easily identified thanks to effective traces combined with accurate logs and metrics, displayed effectively for you to address head-on. Downtime rarely happens, and when it does, it’s for the minimal time possible because of the detailed and cohesive view and understanding you have of the systems involved.
If you’re still finding that you can’t deal with issues like these, it may be worth examining the overall observability of your system and what tools or changes you need to make your system more resilient.
Maximizing observability for long-term success
In summary, the three pillars of observability are important, but they are the sources of telemetry for achieving observability and not the end goal themselves. On top of this, you can use any other useful source of data to help you achieve observability. Complex systems rely on effective monitoring tools that are built with cloud-based environments in mind — but utilizing these tools does not guarantee observability, as observability is a holistic concept regarding the system itself. Finally, whatever observability solutions you are investing in should be adaptable and scalable to grow with your business.
Distributed tracing is an essential process in the modern world of cloud-based applications. Tracing tracks and observes each service request an application makes across distributed systems. Developers may find distributed tracing most prevalent in microservice architectures where user requests pass through multiple services before providing the desired results.
In this blog, we will explore the concept of spans within distributed tracing, delve into their composition and role in monitoring, and discuss best practices for effectively implementing span tracing to optimize the performance and reliability of cloud-based applications.
Introduction to span tracing
Span tracing is a critical component of distributed tracing, which is essential for monitoring and managing the performance of modern cloud-based applications. In distributed systems, particularly those utilizing microservice architectures, user requests often traverse multiple services before delivering the desired outcome.
Spans serve as the foundational elements of this tracing process, representing individual units of work within a trace. By breaking down each service request into smaller, time-measured individual operations, span tracing provides developers with granular visibility into the flow of requests across a distributed environment.
Understanding spans is crucial because they offer the detailed insights needed to diagnose performance bottlenecks, track the flow of requests, and ultimately optimize the reliability and efficiency of distributed applications.
Understanding distributed tracing
Developers can acquire a comprehensive perspective of their software environment by combining distributed traces, metrics, events, and logs to optimize end-to-end monitoring and operations. Spans serve as the fundamental building blocks in distributed tracing and represent the smallest measure of work in the system.
DevOps engineers can set up distributed tracing across their operations by equipping their digital infrastructures with the necessary data collection and correlation tools, which should apply to the whole distributed system.
The collected system data gives insightful information while offering the earliest signs of an anomalous event (e.g. unusually high latency) to drive faster responses.
A closer look at spans in distributed tracing
A trace comprises a combination of spans, with each span serving as a timed operation as part of a workflow. Traces display the timestamp of each span, logging its start time and completion. Timestamps make it easier for users to understand the timeline of events that run within the software. Spans contain specific tags and information on the performed request, including potentially complex correlations between each span attribute.
Parent Spans
The parent, or root spans, occur at the start of a trace upon the initial service request and show the total time taken by a user request. Parent spans contain the end-to-end latency of the entire web request. For example, a parent span can measure the time it takes for a user to click on an online button (i.e., user request) for subscribing to a newsletter. During the process, errors and mistakes may occur, causing parent spans to stop. These spans branch out to child spans, which may divide into child spans of their own across the distributed system. It is important to note that parent spans may finish after a child span in asynchronous scenarios.
Detailed visualization of parent-child references provides a clear breakdown of dependencies between spans and the timeline of every execution.
Developers should refer to every span – parent/root and subsequent child spans – in distributed tracing to gain a comprehensive breakdown of request performance throughout the entire lifecycle.
Key components of a span
Every span contains specific descriptors that comprise the function and details of logical work performed in a system. A standard span in distributed tracing includes:
- A service/operation name – a title of the work performed
- Timestamps – a reference from the start to the end of the system process
- A set of key:value span tags
- A group of key:value span logs
- SpanContext includes IDs that identify and monitor spans across multiple process boundaries and baggage items such as key:value pairs that cross process boundaries
- References to Zero value or causally related spans
Span Tags
Essentially, span tags allow users to define customized annotations that facilitate querying, filtering, and other functions involving trace data. Examples of span tags include db.instances that identify a data host, serverID, userID, and HTTP response code.
Developers may apply standard tags across common scenarios, including db.type (string tag), which refers to database type and peer.service (integer tag) that references a remote port. Key:value pairs provide spans with additional contexts, such as the specific operation it tracks.
Tags provide developers with the specific information necessary for monitoring multi-dimensional queries that analyze a trace. For instance, with span tags, developers can quickly home in on the digital users facing errors or determine the API endpoints with the slowest performance.
Developers should consider maintaining a simple naming convention for span tags to fulfill operations with ease and minimal confusion.
Span Logs
Key:value span logs enable users to capture span-specific messages and other data input from an application. Users refer to span logs to document exact events and timelines in a trace. While tags apply to the whole span, logs refer to a “snapshot” of the trace.
SpanContext
The SpanContext carries data across various points/boundaries in a process. Logically, a SpanContext is divided into two major components: user-level baggage and implementation-specific fields that provide context for the associated span instance.
Essentially, baggage items are key:value pairs that cross process boundaries across distributed systems. Each instance of a baggage item contains valuable data that users may access throughout a trace. Developers can conveniently refer to the SpanContext for contextual metrics (e.g., service requests and duration) to facilitate troubleshooting and debugging processes.
Best practices for effective span tracing
To maximize the benefits of span tracing, developers should follow best practices that enhance the accuracy and efficiency of their observability efforts. One key practice is to choose the right tags for each span, ensuring that they provide meaningful and actionable insights. Standardized tags such as http.method, db.type, and error help streamline database queries and filtering, making it easier to diagnose issues across distributed systems.
Managing span volume is another crucial aspect. In large-scale environments, excessive span data can lead to performance overhead and make traces harder to analyze. Developers should focus on capturing only the most relevant spans and data points, prioritizing critical paths and high-impact operations. By strategically reducing unnecessary spans, teams can maintain the performance of their tracing system while still gathering essential metrics.
Optimizing span data involves careful instrumentation, including the use of concise and consistent naming conventions for operations and services. Ensuring that each old or new span includes key-value pairs that accurately reflect the operation it represents will facilitate more precise monitoring and troubleshooting. Additionally, developers should regularly review and refine their span tracing setup, adjusting as their systems evolve to maintain optimal observability and performance.
Spans vs. traces: What’s the difference?
At its core, a trace represents a service or transaction under a distributed tracing structure. Spans represent a single logical structure within a given trace. Trace context is a significant component for traces within a distributed system as they provide components with easy identification through the use of unique IDs.
Implementation of a trace context typically involves a four-step process:
- Assigning a unique identifier to every user request within the distributed system
- Applying a unique identification to each step within a trace
- Encoding the contextual information of the identities
- Transferring or propagating the encoded information between systems in an app environment
Traces capture the data of a user service request, including the errors, custom attributes, timelines of each event, and spans (i.e., tagged time intervals) that contain detailed metadata of logical work. Therefore, a trace ID refers to the execution path within a distributed system, while a span represents a single request within that execution path.
Summary of spans in distributed tracing
Distributed tracing enables developers to track and observe service requests as they flow across multiple systems. A trace serves as performance data linked to a specific user request in a function, application, or microservice. Each trace comprises spans representing the smallest measurement of logical data and contains metrics that direct users to specific events.
Specifically, a trace is the complete processing of a user request as it moves through every point of a distributed system (i.e., multiple endpoints/components located in separate remote locations).
Spans in distributed tracing provide IT specialists with granular control over data transferred between multiple end-users, improving the monitoring and diagnostics of IT operations.
Advantages of spans and distributed tracing
Modern digital operations involve complex technologies such as cloud, site reliability engineering (SRE), and serverless functions. Software managers and engineers typically accustomed to managing single services lack the technological capabilities to monitor system performance on such a scale.
As such, remote online processes involve multiple user requests passing through distributed tracing to different functions and microservices, resulting in increased system speed and reduced delays in transforming code into products.
Distributed tracing (and spans that serve as the essential logical measurement of work within these functions) optimizes observability strategies for developers within complex and remote app environments.
Combining distributed tracing and a good understanding and implementation of spans allow software teams to pinpoint challenges or faults when managing user requests from multiple endpoints for expedited troubleshooting. Some immediate benefits of a distributed tracing and span-based approach include:
- Improved user experiences that lead to a more favorable business reputation and outcomes
- Holistic management of software systems that minimize downtime for maximum efficiency
- Creation of a proactive software environment that gives the company an edge over other companies in the increasingly competitive digital landscape
- Accurate and responsive identification of user priorities so system managers can quickly determine the steps and measures to keep digital users/customers satisfied
Developers may implement distributed tracing through various methods with differing difficulties. Choosing a method depends on the user’s current programming knowledge, infrastructure, and skill sets. Building a distributed tracing system from scratch provides the most flexibility and customization.
Take your observability to the next level with LogicMonitor
At LogicMonitor, we help companies transform what’s next to deliver extraordinary employee and customer experiences. Our solutions empower you to achieve comprehensive monitoring and streamlined operations.