Developing an alerting strategy saves IT Operations and Development teams time, money, and eliminates notifications from low priority alerts. Learn more!
Reacting to alerts can be a pain, however, there are ways to be proactive and decrease frustration concerning IT Alerting. Developing an alerting strategy saves IT Operations and Development teams time, money, and eliminates notifications from low priority alerts. Keep reading for more information on routing and escalation chains, fielding alerts, and how to communicate an alerting strategy to management.
Alert levels of severity
Most alerts have three levels of severity: warning, error, and critical, with warning alerts usually being the least severe. Severity levels vary from organization to organization, but most internal alerting has a variation of these three levels.
Warning: Warnings indicate that there is something to be aware of, that may or may not be a problem now, but can definitely become an error in the near future. Often, with proper proactive measurements in place, warnings can be fixed before they escalate further.
Error: Errors indicate that something is wrong, or isn’t behaving properly. These may need to be fixed quickly, and should be investigated.
Critical: Critical issues typically mean something has broken in a way that needs attention immediately and actions should be taken to remedy any critical issues ASAP.
Routing and escalation chains serve the purpose of capturing which alerts should be routed to which teams. They also determine the severity of those alerts and the corresponding levels of notifications for them.
The most simple escalation chain is sending warning-level alerts to emails or web-only systems. Too many warning-level alerts sent via text or phone can lead to alert fatigue and feeling overwhelmed by your alerts. The goal is to ensure that the problem is remediated, but you don’t want to take unnecessary action, such as waking someone up in the middle of the night for a system that can tolerate a short outage.
Error or critical alerts necessitate SMS or other live push-based notification systems. They can be escalated amongst multiple members of the team. This is dependent on who acknowledges the alert, which would then stop the escalation. Escalation chains can be used to stagger how people get notified. Other options are a “hail-mary” approach where you spam the entire team depending upon the severity of the alert.
Fielding alerts
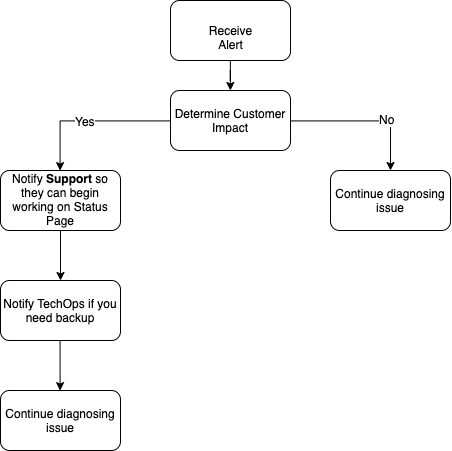
Upon being notified of an alert, the person on-call to troubleshoot the issue should be able to quickly assess the severity of the alert based on its customer impact. Customer impact examines both customer and employee. If employees are being distracted by alerts with no customer impact, that alert’s settings might need some adjustments. There should be a consistent process in place to field alerts and resolve the issue.
Acknowledging an alert is critical to either stop the escalation of that alert or immediately escalate it to the next team who can provide support. It’s important to continue diagnosing the issue, even after it’s resolved. A critical step is to go back and evaluate whether the alert could be tuned in any way to improve its effectiveness. A good question to ask would be, “Is the alert customer-facing?” If the answer is yes, then respond immediately. If not, examine how urgent the alert truly is.
How to communicate alerting strategy to management
With a more efficient alerting system, companies are able to save money and reallocate it to other areas of their business. IT teams are also able to free up more of their time by avoiding alert fatigue and unnecessary distractions from priority work. Identifying the time and money saved, along with any other relevant data, is the best way to communicate an alerting strategy to management. Numbers go a long way and show the strategic value of making a change. Remember to include your team members in these discussions, because if you are making their job easier you will likely have their full support.
When taking a close look at your team’s current alerting practices, note that no system is perfect. However, working to improve IT Alerting escalation policies with LogicMonitor’s guidance is a step to bettering the function of IT Infrastructure.
Originally published July 14, 2020. Updated November 2022
Disclaimer: The views expressed on this blog are those of the author and do not necessarily reflect the views of LogicMonitor or its affiliates.