Amazon Web Services (AWS) products can feel countless, and at LogicMonitor, we are working tirelessly to bring monitoring support to as many of them as possible. With so many products and tools already on your plate, we want to make sure that monitoring is not a hassle, but rather a trusted companion.
AWS provides tools that help with application management, machine learning, end-user computing, and much more. While the list of tools AWS offers continues to grow, LogicMonitor consolidates data from these services and empowers users to monitor them side by side with the rest of their infrastructure, whether it’s in the cloud or on-premises. See how LogicMonitor uses tools from analytics and services for business continuity.
Jump to:
- Monitoring AWS Analytics
- AWS Athena
- AWS Glue
- Monitoring AWS Application-Related Services
- Document DB
- RDS Service Limits
- MQ
- Codebuild
- Monitoring AWS Services For Business Continuity
- AWS Opsworks Stacks
- AWS AppStream 2.0
- AWS Connect
- AWS SageMaker
Monitoring AWS Analytics

AWS Athena
Amazon Athena is an interactive query service that analyzes data stored in Amazon Simple Storage Service (S3) using standard SQL. By monitoring Athena, we give users insight into failed queries and long-running queries. This allows them to catch issues sooner and resolve them faster, thus maximizing uptime and performance.
The data is collected into two query types: Data Definition Language (DDL) and Data Manipulation Language (DML). Each extracted metric is identified by the state of the query: canceled, failed, and succeeded. With that indicator, you can focus your attention on the metrics that are relevant to your task. You can also create a dashboard specifically for failed queries, which is useful for troubleshooting, and another dashboard for successful queries, which will help you come up with acceptable baselines for more accurate thresholds. While troubleshooting, you want to track the execution time. By bringing all the time metrics such as query queue, query planning, engine execution, and service processing into one place, you can quickly identify bottlenecks or the place where things break down. Once you feel like you are in a steady-state and things are running smoothly, make sure to go back and set suitable thresholds for the time metrics. With this, along with our dynamic thresholds feature, you can rest assured that you will only get notified when it matters.
AWS Glue
AWS Glue is a fully managed extract, transform, and load (ETL) service that helps customers prepare and load their data for analytics. The service automatically detects an enterprise’s structured or unstructured data when it is stored within other AWS services, such as data lakes in Amazon Simple Storage Service (S3), data warehouses in Amazon Redshift, and other databases that are part of the Amazon Relational Database Service. All of these can be monitored by LogicMonitor. The only objects from AWS Glue with measurable data are the Jobs, so this DataSource discovers the jobs automatically.
To accurately monitor Jobs, we need to keep track of executors, stages, and tasks.
The number of actively running job executors, “active executors”, can be helpful to identify any delays due to straggler scenarios. Keep an eye on active executors and the max executors metrics to know when it is time to provision more data processing units (DPUs). Make sure to create an alert and warnings for active executors metric as it approaches the max executors value.
As your job goes through different stages, it is helpful to have the completed stages metric on a dashboard to monitor the progress. If you notice that some stages are taking too long, you can correlate the CPU load, memory, and elapsed time metrics to triage the issue and potentially add more resources. Or you can repartition the load to lower the elapsed time. If there is any parallelism within your stages, it is essential to track the completed task and failed tasks. Depending on the workflow of the job, you need to set an appropriate threshold for failed tasks. These failed tasks can help determine abnormalities within the data, cluster, or script.
Monitoring AWS Application-Related Services
Document DB* (Database)
Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. Our users already monitor traditional MongoDB workloads, and with this DataSource, they can now monitor AWS DocumentDB workloads within LogicMonitor’s platform. For organizations that are planning to migrate from a traditional MongoDB environment to DocumentDB, LogicMonitor will provide metrics to closely monitor the transition and alert if there are any hiccups.
Keep the clusters healthy by monitoring the CPU, memory, network activity, database connections, and IOPS metrics. In the case of a node going down, you can monitor the replication lag metric (instanceReplicaLag). There is a chance that if the lag is too high, then your data is at risk of not correctly syncing, so make sure to keep an eye on this metric.
It is crucial to keep backups either via the retention period or snapshots, but it is also essential to know how much storage space these backup are using. Overlooking storage in a cloud environment can create massive headaches, so keep track of the larger backup files to make sure you stay within the storage budget. By tracking these metrics, backupRetentionPeriodStorageUsed, and snapshotStorageUsed, you’ll be able to see any unexpected spikes and take action immediately.
RDS Service Limits* (Database)
LogicMonitor already has RDS specific Datasources that will handle useful monitoring metrics. This new enhancement is adding unique metrics to monitor the RDS service limits. Amazon sets service limits on the number of RDS resources that can be created by an AWS account. A few of these resources include the number of database clusters, instances, parameters, snapshots, and allocated storage. With this data, you can be on top of the limits/quotas Amazon has on your RDS resources. You won’t get caught off guard and will be able to respond accordingly when critical resources are closing in on the quota.
MQ (Application Integration)
Frequently, users will have complex services that may partially rely on MQ and partially on other infrastructure running elsewhere, either on-premise or Cloud. Centralized monitoring in LogicMonitor equips them with more visibility so they can proactively prevent issues with these complex services in hybrid environments. Amazon MQ is a managed message broker service for Apache ActiveMQ. LM provides visibility into these managed brokers so that application teams can maximize uptime and performance with metrics such as message counts, CPU, memory, storage, and network utilization.

For active/standby deployments, LogicMonitor has a DataSource specifically for the standby resources. Separating the active and standby metrics allows for more clarity and keeps the data consistent.
Codebuild (Developer Tools)
AWS CodeBuild is a fully managed continuous integration service that compiles source code, runs tests, and produces software packages that are ready to deploy. You can monitor the build projects to ensure builds are running successfully and at the right time. It is ultimately giving you the information to optimize performance and uptime alongside your infrastructure data.
Application development teams need to be aware when builds fail. This DataSource has predefined thresholds that will automatically trigger notifications in the case of a failed build. Builds need to happen promptly, and with the breakdown of build time, you can pinpoint the step in the build that is causing delays and possibly add resources to optimize the build time of your projects.
Monitoring AWS Services for Business Continuity
AWS Opsworks Stacks
Cloud-based computing usually involves many components, such as load balancer, application servers, databases, etc. AWS OpsWorks Stacks, the original service, provides a simple and flexible way to create and manage stacks and applications. AWS OpsWorks Stacks lets you deploy and monitor applications in your stacks. Through CloudWatch we can get aggregate metrics for a stack, which helps understand the overall health of the resources within the stack & prevent issues. The metrics collected can be broken down into:
- CPU Percentage
- System
- User
- Input/Output Operations
- Memory
- Total
- Cached
- Free
- Buffered
- Average Load
- 1 minute
- 5 minutes
- 15 minutes
- Processes
- Total Active
A stack of the same resource is called a layer. For example, a layer represents a set of EC2 instances that serve a particular purpose, such as serving applications or hosting a database server. These layers can also be monitored within LogicMonitor. With LogicMontor’s robust coverage of AWS, you can also view the individual resource metrics of the layers through the out-of-the-box Datasources of the service.
AWS AppStream 2.0
Amazon AppStream 2.0 allows organizations to manage desktop applications and securely deliver them to any computer. This service helps users run programs that could be resource-intensive on underpowered machines. AppStream is similar to Citrix or Microsoft remote desktop. It becomes essential to monitor the capacity and utilization of the fleets. With a simple dashboard, you can track current and remaining capacity, along with capacity utilization. When an insufficient capacity error happens, LogicMonitor will automatically send an alert.

AWS Connect
Customer service is as crucial as its ever been and people want fast and quality responses. Amazon Connect is an easy to use omnichannel cloud contact center that helps companies provide superior customer service at a lower cost. When utilizing this service, it is beneficial to track the following metrics: status of the service, the volume of calls, quota, and missed calls.
With out-of-the-box alerts for missed calls, misconfigured phone numbers, concurrent calls percentage, and recording upload errors, you can rest assured that you will be on top of any problematic situation.
AWS SageMaker
AWS SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy machine learning models quickly. Users want to monitor this service alongside existing infrastructure to ensure uptime and performance across their entire complex infrastructure, particularly where SageMaker models are being used in production environments. SageMaker Endpoints are discovered as resources in LogicMonitor.
Each endpoint will have its own CPU, memory, and disk utilization metrics. All of which have predefined thresholds for automatic alerts and notifications. LogicMonitor tracks the total invoked HTTP requests and will alert if there are any 5XX errors. You can baseline the latency of the model and the SageMakers overhead. With these baselines, you can be on top of any changes when new models have been deployed or see the difference in latency when doing an A/B deployment.
Conclusion
We recently highlighted our commitment to our AWS partnership, and our developers keep cranking out new AWS monitoring integrations. Here are some previous blogs highlighting AWS analytics services and application development services. All of these new integrations are included with our LM Cloud offering. LogicMonitor will automatically start collecting these metrics if you are an LM Cloud customer and already utilizing any of these Amazon services.
If you have any questions regarding these new monitoring integrations, please reach out or contact your CSM for more information. Or you can try LogicMonitor for free
The workflow of IT teams is ever-changing. Businesses must adapt quickly and use safeguards to prevent operation interruptions.
An IT business continuity program ensures normal business functions after a disaster or other disruptive event. Given society’s dependence on IT for daily needs, making sure that your IT infrastructure and systems operate without disruption is crucial in the face of disaster. Without a plan in place, companies risk financial losses, reputational damage, and long recovery times.
How confident are you that your IT department can maintain continuous uptime and availability during a crisis with minimal disruptions? This guide will help IT operatives identify those solutions as they begin developing or strengthening their IT business continuity plans.
What is an IT business continuity plan and why is it essential?
An IT business continuity plan (IT BCP) is a specialized strategy that makes sure IT systems, infrastructure, and data remain resilient during and after major disruptions like natural disasters or cyberattacks. Unlike general business continuity plans that address broader areas like supply chain management, an IT BCP focuses on keeping an organization’s technical systems safe, including networks, servers, cloud services, and applications.
A strong IT BCP is able to:
- Protect mission-critical IT infrastructure: Ensure uninterrupted access to key systems that keep business operations running
- Support operational stability: Minimize downtime and maintain productivity during disruptions
- Prevent financial and reputational risks: Reduce the potential for costly downtime, regulatory fines, and damage to customer trust
IT BCPs protect organizations from risks such as:
- Cyberattacks: Ransomware and data breaches can lock users out of IT systems, causing widespread disruptions and expensive recovery processes.
- Natural disasters: Events like hurricanes or earthquakes can damage data centers, making IT systems inaccessible.
- System failures: Aging hardware, software bugs, or misconfigurations can bring operations to a halt.
An IT BCP also ensures regulatory compliance, such as GDPR, HIPAA, and SOX, which have strict continuity measures. Non-compliance can lead to significant penalties and legal challenges.
For example, the 2024 CrowdStrike outage disrupted 8.5 million Windows devices, causing Fortune 500 companies to collectively incur an estimated $5.4 billion in uninsured damages. This highlights the need for a strong IT BCP to protect systems, maintain compliance, and prevent costly incidents.
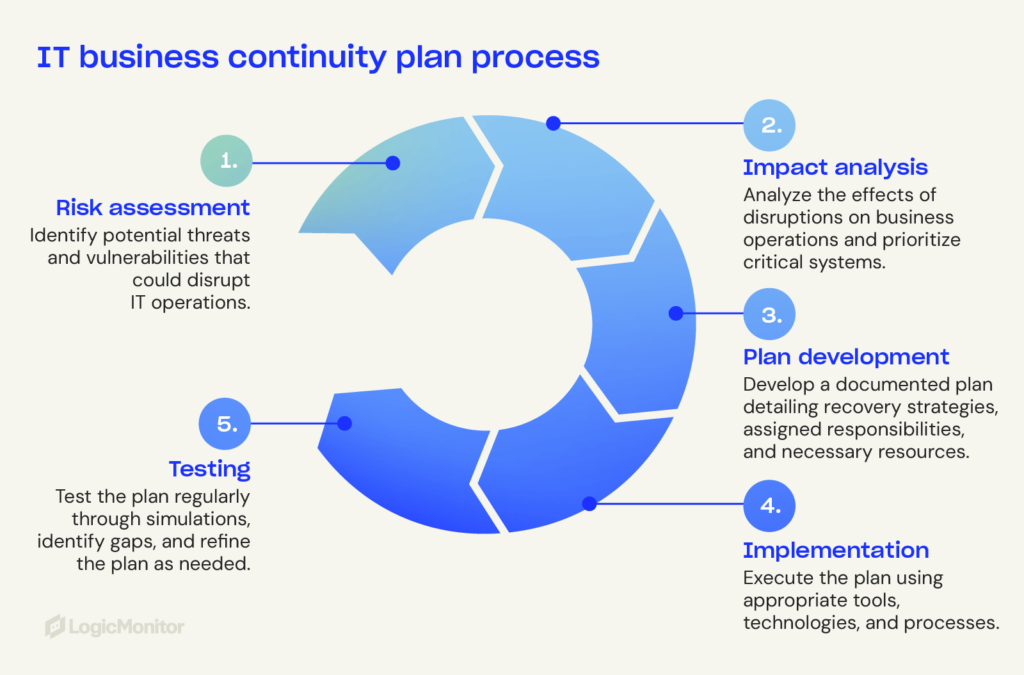
Key IT business continuity plan components
An effective IT BCP focuses on key components that strengthen systems and continue operations during disruptions.
Risk assessment
Audits and risk protocols help organizations anticipate disruptions and allocate resources. Risk assessment identifies vulnerabilities like outdated hardware, weak security, and single points of failure.
Dependency mapping
Dependency mapping identifies relationships between IT systems, applications, and processes. For example, replicating databases is critical if failure disrupts multiple services. Understanding IT interconnections helps organizations identify critical dependencies and blind spots so they can plan recovery procedures.
Backup and disaster recovery
Data backup and recovery are crucial for keeping information safe and quickly resuming operations after a significant disruption. Data recovery best practices include:
- Regular backups: Automate and schedule frequent backups to keep the latest data secure.
- Off-site storage: Use secure cloud solutions or off-site data centers in other locations to prevent data loss in localized disasters.
- Testing recovery plans: Periodically test disaster recovery processes to restore backups quickly and without errors.
Failover systems
Failover systems maintain operations by automatically switching to backups during hardware or software failures. Examples of failover systems include:
- Additional servers or storage systems for critical applications
- Secondary internet connections for minimal disruptions during outages
- Load balancers to distribute traffic evenly so there’s no single point of failure
Communication plans
Effective communication allows organizations to respond to an IT crisis. Strong IT BCPs include:
- Crisis roles: Assign clear responsibilities to team members during disruptions.
- Stakeholder communication: Prepare email templates, internal communication playbooks, and chat channels to quickly inform stakeholders, customers, and employees.
- Incident reporting tools: For real-time updates and task tracking, use centralized platforms like Slack, Microsoft Teams, or ServiceNow.
Continuous monitoring and testing
Tools that provide real-time insights and proactive alerts on system performance will find potential disruptions before they escalate. Routine simulation drills prepare employees for worst-case scenarios.
Cybersecurity measures
The rise in cyberattacks makes strong cybersecurity key to an IT BCP. Multi-factor authentication, firewalls, and endpoint protections guard systems against breaches, while incident response plans minimize attack damage.
Steps to develop an IT business continuity plan
Protect critical systems and ensure fast disruption recovery with these steps.
1. Assess risks and conduct a business impact analysis
Conduct a business impact analysis (BIA) to evaluate how potential IT risks can affect your operations, finances, and reputation. Key BIA activities include:
- Identifying single points of failure in systems or networks
- Evaluating the impact of downtime on various business functions
- Quantifying the costs of outages to justify investments in continuity plans
Example: A financial services firm simulates a Distributed Denial-of-Service (DDoS) attack on its customer portal and identifies that its firewall rules need adjustment to prevent prolonged outages.
2. Define critical IT assets and prioritize systems
Not all IT systems and assets are equally important. Identify and prioritize systems that are vital in maintaining key business operations, including:
- Core infrastructure components like servers, cloud platforms, and networks
- Applications that support customer transactions or internal workflows
- Databases that hold sensitive or important operational information
Example: A retail company classifies its payment processing systems as a Tier 1 priority, ensuring that redundant servers and cloud-based failovers are always operational.
3. Develop a recovery strategy
Establish clear recovery time objectives (RTO) and recovery point objectives (RPO) to guide your strategy:
- RTO: Defines the maximum acceptable downtime for restoring systems or services
- RPO: Specifies the acceptable amount of data loss measured in seconds, minutes, or hours
Example: A healthcare provider sets an RTO of 15 minutes for its electronic medical records system and configures AWS cross-region replication for failover.
4. Obtain necessary tools
Equip your organization with tools that support continuity and recovery efforts, including:
- Monitoring platforms: Provide real-time insights into system health and performance
- Data backup solutions: Ensure secure storage and rapid data restoration
- Failover mechanisms: Automate transitions to backup systems during outages
- Communication tools: Facilitate seamless crisis coordination across teams
Example: A logistics company integrates Prometheus monitoring with an auto-remediation tool that reboots faulty servers when CPU spikes exceed a threshold.
Hypothetical case study: IT BCP in action
Scenario
An e-commerce company faces a ransomware attack that encrypts critical customer data.
Pre-BCP implementation challenges
- Single data center with no geo-redundancy.
- No air-gapped or immutable backups, making ransomware recovery difficult.
- No automated failover system, leading to prolonged downtime.
Post-BCP implementation
- Risk Assessment: The company identifies ransomware as a high-priority risk.
- System Prioritization: Customer databases and payment gateways are flagged as mission-critical.
Recovery strategy
- Immutable backups stored in AWS Glacier with multi-factor authentication.
- Cloud-based disaster recovery ensures failover to a secondary data center.
Monitoring and response
- AI-based anomaly detection alerts IT teams about unusual encryption activities.
- Automated playbooks in ServiceNow isolate infected systems within 10 seconds of detection.
Outcome
The company recovers operations within 30 minutes, preventing major revenue loss and reputational damage.
IT business continuity tools and technologies
Building an effective IT BCP requires advanced tools and technologies that ensure stability.
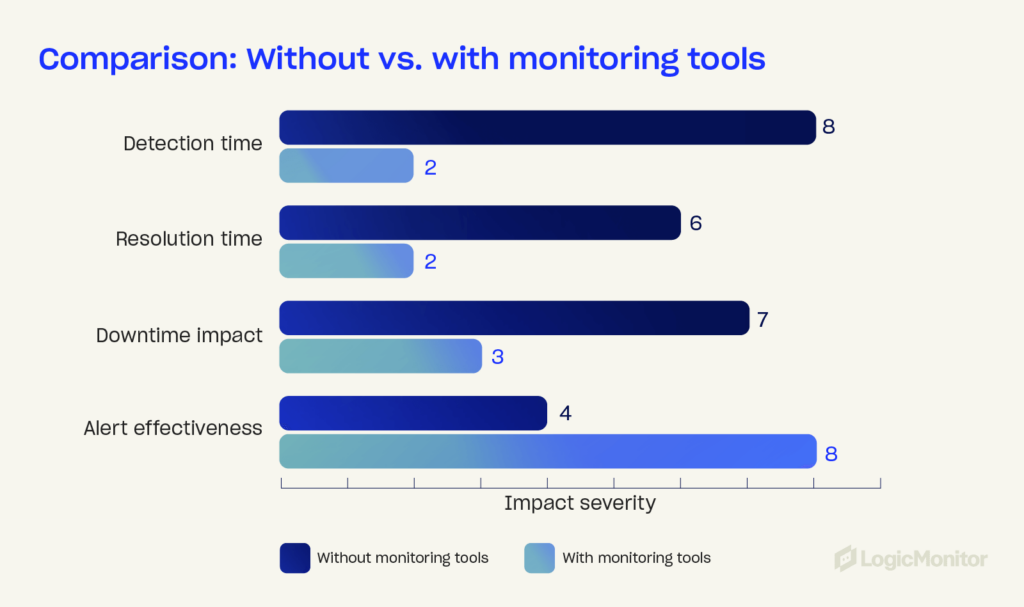
Monitoring systems
Modern infrastructure monitoring platforms are vital for detecting and eliminating disruptions. Tools such as AIOps-powered solutions offer:
- Real-time insights into system performance, helping teams to identify and resolve issues quickly
- Root-cause analysis (RCA) to determine why harmful events occur, improving response times
- Anomaly detection to catch irregular activities or performance bottlenecks and correct them
Cloud-based backup and disaster recovery
Cloud solutions offer flexibility and scalability for IT continuity planning. Key benefits include:
- Secure data backups: Backups stored in other geographic locations protect against localized disasters.
- Rapid disaster recovery: Multi-cloud strategies can restore systems quickly.
- Remote accessibility: Employees and IT teams can access critical resources anywhere, speeding up recovery times.
Failover and resource scaling automation tools
Automation streamlines recovery processes and ensures IT infrastructure stays agile during crises. Examples include:
- Automated failover systems: Switch operations to backup servers or connections during outages.
- Resource scaling: Adjust server capacity and network bandwidth to meet changing demands.
- Load balancing: Distribute traffic to prevent overloading and single points of failure.
Cybersecurity solutions to protect IT systems
Robust cybersecurity is essential to IT continuity. Protect your systems with:
- Multi-factor authentication (MFA) to secure user access
- Firewalls and endpoint protection to defend against threats
- Incident response plans to minimize the impact of breaches or ransomware attacks
Common IT business continuity planning challenges
Even well-designed IT BCPs face obstacles. Understanding these common pitfalls will help you proactively address vulnerabilities and maintain operational strength.
Lack of testing and updates
Outdated or untested IT BCPs risk gaps or ineffective processes during a crisis. Regular updates will help you adapt to threats.
Third-party dependencies
Modern IT systems rely heavily on external services like cloud providers, data centers, and software vendors. Failing to account for these dependencies can lead to significant disruptions during third-party outages or delays.
Human error
Even the most advanced IT systems require human intervention during a crisis. Human factors, such as unclear communication protocols and insufficient training, can compromise the execution of an IT BCP. Strategies for reducing human error include:
- Training and refreshers: Make sure employees are familiar with their responsibilities in your IT BCP during a crisis. Include role-specific training and regular simulations to reinforce their knowledge.
- Documentation: Develop quick-reference guides and checklists for team members to easily access during an incident.
- Communication protocols: Establish clear communication channels and use tools like incident response platforms to provide real-time updates and coordinate teams.
- Post-incident reviews: After each drill or real-world incident, evaluate team performance and identify areas for improvement.
Budget constraints
Financial limitations can keep organizations from creating effective continuity measures, like failover systems, backup solutions, or regular testing protocols. To address budget constraints:
- Invest in critical areas with the highest potential impact
- Explore cost-effective solutions, like open-source tools or scalable cloud platforms
- Quantify potential losses resulting from downtime
Complex multi-cloud and hybrid environments
As organizations adopt hybrid and multi-cloud systems, uninterrupted operations become a challenge. Issues like inconsistent configurations and siloed data can prolong disruptions and slow recovery. Regular audits, dependency mapping, and unified monitoring tools simplify crisis management and strengthen continuity.
Lack of executive buy-in
Without support from leadership, BCP efforts can lack funding, strategic alignment, or organizational priority. Secure executive support by:
- Demonstrating the ROI of continuity planning
- Presenting real-world examples of downtime costs and successful recoveries
- Highlighting compliance obligations
Best practices for maintaining IT business continuity
A strong IT BCP requires ongoing effort to remain effective against evolving threats. These practices ensure your plan stays effective during any crisis.
Test and refine
Regular tests can identify weaknesses in your IT BCP. Continuously improve processes to align with your current infrastructure and objectives. Testing methods include:
- Tabletop exercises: Simulate hypothetical scenarios to review decision-making and coordination
- Live drills: Engage teams in real-time responses to assess readiness and identify bottlenecks
- Post-test reviews: Use results to refine workflows and address gaps
Train staff on their crisis roles
Regular training with clear responsibilities ensures team members understand their duties and can act quickly during disruptions.
- Provide training for IT, operations, and leadership teams
- Develop playbooks or quick-reference guides for crisis scenarios
- Regularly update and refresh knowledge to account for staff turnover
Use RTO and RPO metrics to measure success
Set measurable goals to evaluate your strategy’s effectiveness. Track performance against these benchmarks to ensure your plan meets its objectives:
- Recovery Time Objective (RTO): Define how quickly IT systems must be restored after a disruption to minimize downtime.
- Recovery Point Objective (RPO): Specify the maximum acceptable data loss, measured in time, to guide backup frequency.
Collaborate with cross-functional teams
An effective IT BCP must align with organizational goals. By working with teams across departments, you can:
- Ensure all relevant teams understand your IT BCP
- Identify dependencies between IT systems and other functions
- Develop response strategies that integrate with company-wide plans
Leverage technology to automate processes
Automation enhances the speed and efficiency of IT continuity efforts. Tools like monitoring platforms, automated failover systems, and AI-driven analytics reduce manual workloads and allow proactive problem-solving.
Continuously monitor and assess risks
The threat landscape is constantly evolving. Regular risk assessments and real-time monitoring help identify emerging weaknesses before they escalate into major problems.
Emerging Trends in IT Business Continuity Planning
Key trends shaping IT BCP include:
1. AI and Machine Learning
- Predictive Analytics: Identifies potential failures before they occur.
- Automated Incident Response: Triggers failovers and restores backups autonomously.
- AI-Based Risk Assessments: Continuously refines risk models.
2. Cloud-Native Solutions
- Scalability & Redundancy: Cloud solutions offer flexibility and geographic backups.
- Faster Recovery: Minimized downtime with rapid disaster recovery.
3. Compliance and Regulations
Stricter standards like GDPR, CCPA, and supply chain mandates require robust continuity plans.
4. Zero Trust Architecture
Emphasizes restricted access, continuous authentication, and network segmentation to combat cyber threats.
5. Automated Disaster Recovery
- Self-Healing Systems: Auto-reconfigures after failures.
- Blockchain: Ensures data integrity.
- AI Compliance Monitoring: Tracks and reports in real time.
Final thoughts: Strengthening IT resilience
An effective IT BCP is a strategic investment in your organization’s future. Identifying weaknesses, prioritizing critical systems, and using proactive measures reduce risks and maintain operations during disruptions.
Continuity planning isn’t a one-time task, however. As challenges like cyberattacks, regulatory changes, and shifting business needs evolve, an effective plan must adapt. Regular updates, testing, and cross-functional collaboration ensure your plan grows with your organization.
Ultimately, an effective IT BCP supports business success by protecting revenue, maintaining customer trust, and enabling operational stability. Taking these steps will prepare your organization to navigate future challenges confidently.
Maintaining business continuity is both more difficult and more important than ever in the era of COVID-19. Typically, IT departments evolve their approaches and technologies over time to meet the needs of customers. But that approach may soon be outdated thanks to the global pandemic.
To dig deeper into how IT departments are able to quickly adapt and evolve in times of crisis, LogicMonitor commissioned a research study of 500 IT decision-makers from across North America, the United Kingdom, Australia, and New Zealand.
According to LogicMonitor CEO and President Kevin McGibben, “Maintaining business continuity is both more difficult and more important than ever in the era of COVID-19. IT teams are being asked to do whatever it takes — from accelerating digital transformation plans to expanding cloud services — to keep people connected and businesses running as many offices and storefronts pause in-person operations. The time is now for modern enterprises to build automation into their IT systems and shift workloads to the cloud to safeguard IT resiliency.”
LogicMonitor’s new research data reveals that CIOs, CTOs, and their teams are leaning into AIOps, automation, cloud, and intelligent infrastructure monitoring to weather the storm and ensure business continuity for their customers.
1. IT Teams Lack Confidence in Their Infrastructure’s Resilience
Having a business continuity plan is necessary to ensure that companies can perform their normal business functions even in the midst of a crisis. Our study found that 86% of companies had a business continuity plan in place before COVID-19, but only 35% of respondents felt very confident in their plan. Many companies and their IT personnel were not prepared to transition to and support a fully remote business model and workforce.
IT decision-makers also expressed overall reservations about their IT infrastructure’s resilience in the face of a crisis. Globally, only 36% of IT decision-makers feel that their infrastructure is very prepared to withstand a crisis. During a crisis when people must work remotely or where the office cannot be accessed in a reasonable timeframe, IT leaders are most concerned about the following:
- Dealing with internet outages or other technical issues remotely
- Network strain from having too many individuals logging in remotely
- VPN issues
- Not being able to access hardware
- Teleconference software security issues
However, most IT decision-makers have a plan to address these fears. Leaders around the world are investing in productivity tools and expanding the use of cloud-based solutions and platforms to maintain business continuity and serve customers during the global pandemic.

2. COVID-19 Is Dramatically Accelerating Cloud Adoption
As a result of newly distributed and remote workforces, many organizations are also initiating or accelerating shifts to the cloud. LogicMonitor has helped modern enterprises shift from on-premises to the cloud for years, but due to remote work orders departments are further accelerating their migration to the cloud.
Before COVID-19, IT professionals said 65% of their workload was in the cloud. However, just six months later, IT professionals expect that 78% of workloads will reside in the cloud by 2025 due in part to the global pandemic.

3. IT Leaders Are Embracing Automation
Automation is a top priority for many businesses as part of their larger digital transformation initiatives. In the first half of 2020, the benefits of IT automation have become increasingly clear. 50% of IT leaders who have a “great deal of automation” within their IT department also say they’re very confident in their ability to maintain continuous uptime and availability during a crisis.

Many IT leaders view the automation of certain IT tasks or alerts as a business enabler that allows them to operate more efficiently and focus on innovation, rather than keeping the lights on. In our study, 74% of IT leaders state that they employ intelligent systems like artificial intelligence and machine learning to provide insight into the performance of their IT infrastructure. And 93% of IT leaders say automation is worthwhile because it allows IT leaders and their teams to focus on more strategic tasks and initiatives.
Some IT decision-makers do have concerns about automation and machine learning. The potential for a high upfront time investment in order to get everything working properly tops that list of concerns, according to the survey results. Automation is also perceived by some as a threat to job retention. However, others view automation as a positive thing when faced with the spectre of pandemic-related layoffs or budget cuts. 72% of IT leaders believe that the automation of IT tasks would enable their department to operate effectively in the case of staff reduction.
The time is now for modern enterprises to build automation into their IT systems and shift workloads to the cloud to safeguard IT resiliency. For three recommendations on how to adapt to best handle the new era of remote work, download the full Evolution of IT report today.