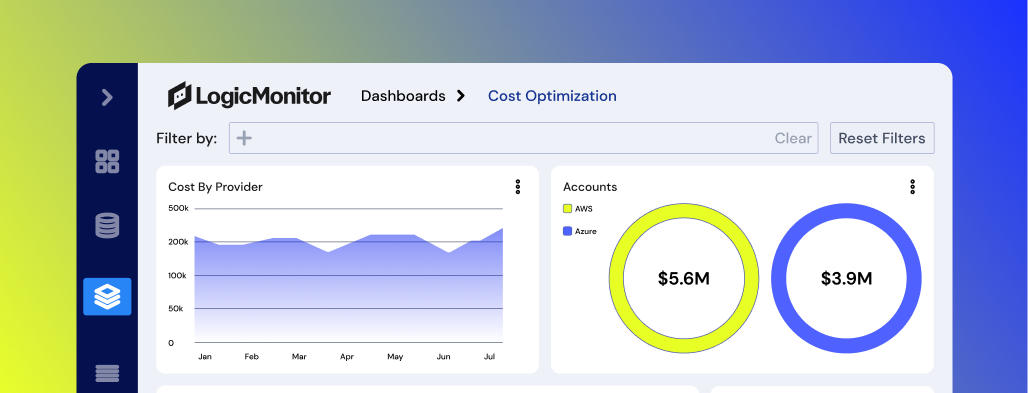
Hybrid Observability for Research & Education
Education IT Monitoring: Unified, Intelligent, Resilient
Keep learning environments accessible and secure across campus, cloud, and remote systems, so students, faculty, and staff can stay connected without interruption.