Artificial intelligence (AI) and machine learning (ML), ever-evolving fields that are subtly and stunningly transforming our world, are now firmly rooted in most aspects of the current tech landscape and business processes. Their growth is exponential, and their effects are largely positive – fostering business endeavors, enhancing our quality of life, and shaping how we live, work, and interact. While some may harbor reservations, the potential of computers to learn, adapt, and drive innovation and efficiency across numerous industries is undeniable.
Among the numerous companies operating in this exciting sphere, Amazon Web Services (AWS) has emerged as a dominant player, offering a suite of powerful, scalable, and user-friendly AI services. Key among these are Amazon SageMaker, Amazon Rekognition, and Amazon Comprehend. These services, due to their capabilities and ease of use, have become quite popular, promising a high level of performance and sophisticated results that can streamline the use of online content.
The beauty of these AWS services is that they offer efficiency without necessitating a large cadre of data and programming professionals within your company. So, whether you’re fearful or fascinated by the rapid progression of AI and ML, the truth remains – they are here to stay.
Before diving into their respective use for your business, it’s crucial to understand the features, benefits, and the broader context in which AI and ML operate. In this blog, we aim to provide an introduction to these three remarkable AWS AI services and their potential offerings to businesses. We’ll delve into the most important details, helping you make an informed decision about their applicability to your needs. Enjoy the journey as we explore the revolution of AI with Amazon’s innovative tools.
Amazon SageMaker
Amazon SageMaker is a fully managed machine learning service provided by AWS public cloud. It simplifies the process of building, training, and deploying ML models at scale. With SageMaker, developers and data scientists can access a comprehensive set of tools and capabilities that accelerate the ML workflow.
Key features
Data preparation is one of SageMaker’s key features. SageMaker provides pre-built algorithms and frameworks for data preprocessing, feature engineering, and data visualization, allowing users to clean and prepare their datasets efficiently.
It also offers model training, which is a service that supports a wide range of ML algorithms, including built-in algorithms and popular frameworks like TensorFlow and PyTorch. SageMaker automatically scales resources to handle large datasets and parallelize training.
With model deployment, SageMaker makes it easy to deploy the model to production. It provides managed hosting, auto-scaling, and real-time inference capabilities, ensuring high availability and low latency.
After deployment, it can also help with model monitoring and management. SageMaker enables monitoring and analysis of deployed models, including real-time predictions, performance metrics, and drift detection. It helps in maintaining model accuracy over time.
SageMaker includes the following technologies:
Amazon Augmented AI – This feature builds workflows that allow humans to review ML predictions.
Batch Transform – You use this aspect to preprocess datasets and to associate input records with inferences.
SageMaker Data Wrangler – Allows you to prepare, import, and analyze data in SageMaker Studio. By integrating Data Wrangler into your ML workflow, you streamline data pre-processing and feature engineering by using minimal or no coding.
SageMaker Edge Manager – Enhances custom models for edge devices and creates fleets and run models that have an efficient runtime.
SageMaker Inference Recommender – This application gives you recommendations on inference instance types and configurations, such as instance count and model optimizations, for your LM models and workloads.
SageMaker Model Building Pipelines – You can build machine learning pipelines that are directly integrated with SageMaker jobs.
SageMaker Mode Registry – Allows versioning, approval workflow, cross-account support, and image tracking.
Other features include SageMaker Studio Notebooks and Amazon EMR, SageMaker Training Compiler, SageMaker Serverless Endpoints, Reinforcement Learning, and more.
Benefits and use cases of SageMaker
Amazon SageMaker has found applications in various domains. For example, with fraud detection, organizations can train models using historical transaction data to identify patterns indicative of fraudulent activities.
SageMaker can also be used to build personalized recommendation systems by analyzing user behavior and preferences, and image classification allows developers to create image classification models for tasks like object recognition and scene understanding.
As one of its biggest benefits, SageMaker offers on-demand scalability, allowing users to handle large datasets and complex ML workloads without worrying about infrastructure provisioning.
SageMaker is also cost-effective, offering a pay-as-you-go pricing model. You’ll only pay for the resources you use, and that helps optimize resource utilization and keep upfront costs lower. There’s also reduced complexity with SageMaker, and as a managed service the ML workflow is simplified. That eliminates the need to set up and manage infrastructure components manually.
Other places where SageMaker can boost productivity include automotive, hospitality, data analytics, retail, electronics, cloud services, healthcare, gaming, and more.
Amazon Rekognition
Amazon Rekognition is a software-as-a-service platform that simplifies adding image and video analysis to applications. It’s easy to use and only requires that you add an image or video to the Amazon Rekognition API for the service to identify people, scenes, activities, etc. The software can also identify inappropriate content as well as analyze and compare faces for various use cases.
Rekognition does not require ML skills to use, and it can analyze any image or video file stored in Amazon S3. The program continually learns from new data, and Amazon constantly adds new features to make it even more effective.
Key features
One of the main key features of Rekognition is object and scene detection through image processing. With this ability, Rekognition can identify and label objects and scenes in images and videos, enabling applications to automatically categorize and tag visual content.
Facial analysis is another key feature, allowing the service to analyze faces within images and video and provide insights such as age range estimation, emotions, gender, and facial landmarks. Coupled with this is text detection. Rekognition can extract text from images and videos, making it useful for tasks like document analysis and optical character recognition (OCR).
Additionally, content moderation offers capabilities for detecting explicit and suggestive content within images and videos, helping in enforcing content guidelines and filtering inappropriate content.
Rekognition includes the following functionalities
Image Moderation – This program identifies offensive and unwanted content, protecting users from problem content in social media, broadcast media, and e-commerce. It gives you control over what images are included in your messaging. This image analysis is essential for protecting your company’s reputation.
Labels/Custom Labels – Rekognition is able to identify thousands of objects, including cars, mobile phones, sporting events, etc. It also offers custom labels that identify objects important to your business operations, such as your company logo on social media and your products in retail stores.
Customizable Audio and Text Moderation – You can create your own list of unacceptable words and phrases with Rekognition’s text detection. This program allows you to convert speech in videos with Amazon Transcribe and then perform text analysis for hate speech or profanities.
Face Analysis – This lets you detect faces in images and videos and identifies key characteristics, including gender, age, facial hair, glasses, etc.
Face Search – Rekognition also lets you identify specific faces in photos or videos by using your own database of face images.
Safety Checks – Uses your in-house cameras and sensors to verify workers are wearing required safety gear such as masks, helmets, and gloves.
Use cases and benefits of Rekognition
Amazon Rekognition, a powerful image, and video analysis service by AWS, offers a multitude of benefits and use cases across various industries. Leveraging the power of deep learning models, Rekognition can analyze and process large volumes of visual data with high accuracy and efficiency. Its applications are diverse and far-reaching.
In the realm of security and surveillance, Rekognition shines in real-time video footage analysis. It detects, tracks, and records objects, faces, and activities, proving indispensable for maintaining safety and preventing security breaches. Law enforcement agencies utilize its image and facial recognition capabilities to more accurately and easily identify crime suspects, enhancing public and home security.
The service also excels in media analysis, enabling automatic tagging and categorization of visual content. This enhances content search, organization, and recommendation, ultimately improving company efficiency and profitability. Its use is not limited to security and media industries. In the field of autonomous driving, auto manufacturers utilize Rekognition to improve self-driving car navigation, making these vehicles a safer and more practical travel option.
Amazon Rekognition has also made significant strides in enhancing human-computer interaction. By identifying consumer retail preferences or providing safer and faster banking services, Rekognition has improved customer satisfaction with computer-based services.
One of the most impactful uses of Rekognition is in medical imaging. By increasing the speed and accuracy of diagnoses, it has the potential to improve cure rates and life expectancy, bringing significant benefits to patients.
User verification is another area where Rekognition excels. Comparing captured facial features in images or videos against stored profiles, enables applications to verify user identities effectively.
A standout benefit of Amazon Rekognition is its ease of integration. With simple SDKs and APIs, it can be seamlessly integrated into workflows and applications. Furthermore, its high scalability allows it to handle vast volumes of images and videos, processing large amounts of data quickly.
Amazon Rekognition is continuously being improved by AWS, ensuring the highest levels of accuracy and performance in tasks involving image and video analysis. Satisfied users of this service include prominent companies like Smug Mug, ZOZO, Mobisocial, and Artfinder, testifying to its efficacy and broad applicability.
Amazon Comprehend
Amazon Comprehend is a natural language processing (NLP) service that helps uncover insights and relationships within text data. It uses advanced ML techniques for text analysis and provides valuable information, enabling organizations to extract meaning and gain actionable insights from their textual data.
Amazon Comprehend is natural language processing (NLP) software that uses machine learning to analyze the content of documents. It can recognize key phrases, language, attitudes, and entities to garner insights about the document.
Amazon Comprehend allows you to develop new products by better understanding these documents, particularly their structure. For instance, you can search social networks for product mentions or simply scan for key phrases.
Amazon Comprehend can analyze documents in multiple languages and accepts UTF-8 text documents as input. No ML experience is necessary to use this software.
Key Features
Sentiment analysis is one of the key features of this service. Comprehend can determine the sentiment (positive, negative, neutral) expressed in a piece of text, making it useful for analyzing customer feedback and social media posts. The service also offers entity recognition, which can identify and categorize entities such as people, organizations, locations, and dates within the text, aiding in information extraction and organization.
Another key feature of Sentiment is language detection. This service can automatically detect the language of a given text, allowing applications to handle multilingual content effectively. With keyphrase extraction as a part of its text analysis capabilities, Comprehend can extract important keywords and phrases from the text, enabling applications to understand the main topics and themes within a document.
Functionalities of Comprehend
Custom Entity Recognition – This feature allows for Amazon Comprehend customization tailored to identify specific terms of your choice. AutoML lets the software learn from a few examples, such as SSNs or policy numbers. Then it is able to recognize these terms from text blocks in PDFs, Microsoft Word docs, etc.
Entity Recognition – This API identifies the automatically categorized entities, such as “people,” that appear in the designated text.
Sentiment Analysis – This aspect identifies and returns the overall “sentiment” or tone of a text. The label may be “positive,” “ negative,” “ neutral,” or “mixed.”
PII Identification and Redaction – Comprehend can find and remove personally identifiable information (PII). This process works for support tickets, product reviews, customer emails, and more. Again, no ML experience is required to use this feature of Comprehend.
Language Detection – It can automatically identify over 100 languages in various text forms.
Syntax Analysis – The software can analyze text to define word boundaries, parts of speech, etc., and provide a confidence score.
Other features include Topic Modeling, Events Detection, Keyphrase Extraction, and Custom Classification.
Use cases and benefits
Amazon Comprehend has been utilized in various domains for tasks including social media analysis. It can analyze social media feeds to understand customer opinions, sentiment trends, and emerging topics. It also works with document classification and enables automated classification of documents based on their content, improving search and organization capabilities.
Through the voice of the customer benefit, Comprehend helps in analyzing customer reviews, surveys, and support tickets, allowing organizations to gain insights into customer preferences and pain points.
Easy-to-use APIs are another significant benefit, as Comprehend provides simple APIs that allow developers to integrate NLP capabilities into their applications with minimal effort. The service also supports several languages, allowing organizations to analyze text in multiple languages and handle global content effectively.
Customizability rounds out the list of big benefits. Comprehend allows users to train custom models with their own data, tailoring the service to specific industry domains and use cases.
Some of the use cases for Comprehend include:
- Analytics of Customer Sentiment – You can use customer feedback to determine whether customers are positive, negative, neutral, etc.
- Data Management and Knowledge Discovery – You are able to analyze multiple documents and automatically organize them by topic. This process then lets you personalize content for your customers.
- Semantic Search – Your search engine can index key phrases, sentiments, and entities, which means the focus is on article intent and context instead of keywords.
How the Three Services Compare
Amazon SageMaker is a comprehensive platform for building, training, and deploying machine learning models. It offers a wide range of tools and services, including data preparation, model training, hyperparameter tuning, and model hosting.
On the other hand, Amazon Rekognition is a deep learning-based image and video analysis service. It provides capabilities for object and scene detection, facial analysis, content moderation, and text recognition.
Amazon Comprehend focuses on natural language processing (NLP) tasks. It offers pre-trained models for key NLP tasks like sentiment analysis, entity recognition, topic modeling, and language detection.
SageMaker, Rekognition, and Comprehend Complement One Another
| Feature | Amazon SageMaker | Amazon Rekognition | Amazon Comprehend |
| Machine Learning | Provides a fully-managed ML development platform for building, training, and deploying models. | Offers image and video analysis capabilities, such as object detection, facial analysis, and content moderation. | Utilizes natural language processing (NLP) techniques to extract insights from text, including sentiment analysis, entity recognition, and topic modeling. |
| Custom Models | Enables developers to create and train custom ML models using popular frameworks and libraries. | Supports custom model training and integration with SageMaker for more specialized image analysis tasks. | Allows training custom models for NLP tasks like entity recognition and sentiment analysis using custom training data. |
| Pre-built Models | Provides a wide range of pre-built algorithms and models, including popular ML models for various tasks. | Offers pre-trained models for common image analysis tasks, such as face recognition and celebrity recognition. | Provides pre-trained models for NLP tasks, such as language detection, keyphrase extraction, and document classification. |
| Data Labeling | Supports data labeling workflows to annotate and prepare training data for ML models. | Offers an integrated data labeling service for tasks like object detection and image classification. | Provides a custom entity recognition annotation tool to label text data for training NLP models. |
| Real-time Analysis | Allows real-time deployment of ML models to process incoming data and generate predictions. | Enables real-time image and video analysis for applications like video surveillance and content moderation. | Provides real-time text analysis capabilities for applications like social media monitoring and customer support chatbots. |
| Integration | Seamlessly integrates with other AWS services, such as Amazon S3 for data storage and AWS Lambda for serverless computing. | Can be integrated with other AWS services like Amazon S3 and AWS Lambda for scalable image and video analysis workflows. | Integrates with AWS services like Amazon S3 and AWS Lambda to process text data and trigger automated actions. |
| Scalability | Offers automatic scaling and resource provisioning to handle large-scale ML workloads. | Provides scalable image and video analysis capabilities to handle large volumes of media data. | Supports scalable NLP processing to analyze large amounts of text data efficiently. |
| Industry-specific Solutions | Offers industry-specific solutions through SageMaker built-in algorithms and frameworks. | Provides industry-specific image analysis solutions, such as face comparison for identity verification and text detection for document processing. | Offers industry-specific NLP solutions, such as medical entity extraction for healthcare and sentiment analysis for customer feedback analysis. |
The power of SageMaker, Rekognition, and Comprehend combined
Your company needs the power of predictive analytics, something that is simplified by using SageMaker. With this service, you can harness the power of ML in much less time and with little difficulty. But predictive analytics alone cannot accomplish what your company needs.
By adding Amazon Rekognition, you get the power of image and video analysis which quickly identifies entities and objects and also screens for profanity and other troublesome features. And while it can analyze video text, you need Comprehend to tackle the majority of needed text analysis.
By combining all three software services, you get the comprehensive analysis you need to produce effective, meaningful online content.
The Bottom Line on SageMaker, Rekognition, and Comprehend
Whether it’s building and deploying ML models, analyzing images and videos, or extracting insights from text, Amazon SageMaker, Amazon Rekognition, and Amazon Comprehend are scalable and cost-effective solutions for a wide range of applications. By leveraging these services, businesses can unlock the potential of AI and drive innovation in their respective industries.
Amazon Web Services (AWS) Direct Connect is a system that connects your business to an AWS service without using mainstream internet. Implementing this system into your company means any information transferred over the internet will use a private, secure network.
AWS Direct Connect designs virtual interfaces that are directly connected to public AWS service. It makes the transfer of information quicker and more streamlined for your company. When using hybrid networking, which most companies use, this connection can be either public, private, or both.
There are several requirements to use AWS Direct Connect, but the main requirements are that your network should already have an AWS Direct Connect location and that your business collaborates with an AWS Direct Connect partner. From there, installing this service should be straightforward.
This service contains two main parts: the connection and virtual systems. The connection part of AWS Direct Connect is where the network connection is created. The virtual system opens up access between your business and an AWS system.
Implementing AWS Direct Connect can increase profits, bandwidth, and productivity for your business.
Understanding/Importance of Hybrid Cloud Networking
A Hybrid Cloud Network enables data transfer between a company’s IT sector and a cloud network. Company data is moved throughout these environments. It is interlinked through connections such as AWS Direct Connect. Hybrid Cloud Networking is an excellent option for any business.
It facilitates a fast-moving digital business transformation. These cloud services are agile and change with your business as it grows.
Implementing a hybrid cloud service will benefit your business because you can use both public and private clouds. This cloud service allows applications to work together across boundaries, cloud instances, and architectures.
It also uses the existing architecture in a data center. Hybrid Cloud Networking is easily scalable for high amounts of data and large workloads. It can distribute sensitive information in the private cloud and use the public cloud to run operations. It is an excellent option for a fast-paced business.
Explanation of How AWS Direct Connect Facilitates Hybrid Cloud Networking
AWS Direct Connect enables hybrid cloud connectivity by allowing companies to expand and transfer their infrastructures to the cloud. It provides a high-bandwidth, low-latency connection that is suited to a hybrid cloud network that contains big data analytics. It will unify your networks through an AWS Direct Connect connection, and you can utilize hybrid applications without sacrificing performance or security.
AWS Direct Connect gives your business a private connection that lets you receive up to 100 Gbps speeds. It provides a reliable service 24 hours a day so your company has no downtime.
Businesses can extend their existing network if they need a more significant space to complete their operations efficiently. By managing large datasets, it can achieve smooth data transfers for analysis or a backing-up process. AWS Direct Connect improves and streamlines your hybrid cloud operations and network performance so that you can always rely on high-quality service for your business.
Benefits of AWS Direct Connect
AWS Direct Connect provides businesses with a quick, secure way to connect with AWS. There are many excellent reasons why you should implement AWS Direct Connect in your company.
Performance
AWS Direct Connect is a dedicated connection from AWS to your business, so reliable performance is almost guaranteed. The data being moved throughout the network is isolated from the other internet traffic, making it faster and more efficient. AWS Direct Connect will expand or decrease as your company does, so you can scale up operations as needed.
Cost-Efficiency
While there is an initial investment for this system, the cost of the network access can vary, but overall is relatively low. Any information or data is changed at a lower rate when compared to standard bandwidth. So, for large data transfers, there is a significant cost reduction.
Security
The AWS Direct Connect connection is a dedicated connection between AWS and your business. This means that within this connection, it has a high level of security, reducing the probability of a cyber-attack or a data breach. Also, if you want to increase that security, you can add on additional services such as encryption services.
Low Latency
One of the primary benefits of AWS Direct Connect is that it contains low-latency connections. Low-latency connections mean that your business can access its information quickly and efficiently. Having this feature is especially important for applications that require real-time data processing. Also, large companies will benefit from this feature as they process and analyze high amounts of information daily.
AWS Direct Connect is a high-speed, dedicated connection between your business and an AWS location. It reduces your company’s overhead, giving you a streamlined and effective service that can be used in conjunction with hybrid cloud networking.
If you want to begin your journey with AWS Direct Connect or learn more about Hybrid Cloud Networking, contact LogicMonitor today.
Why Should I Get AWS Certifications?
If you’re interested in cloud computing, AWS certifications are one of the most rewarding paths to a dynamic career. As a worldwide leader in cloud infrastructure service, Amazon prepares certified experts who are highly sought after by IT organizations around the world.
Did you know that 94% of organizations use a cloud service and 30% of their IT budgets are allocated to cloud computing? Getting an AWS certificate is an opportunity to enhance your cloud computing skills, start a lucrative career, and get some of the highest-paid jobs in the IT industry.
In this blog we will cover:
- What Are the AWS Certifications?
- Certified Cloud Practitioner
- Certified Solutions Architect – Associate
- Certified Solutions Architect – Professional
- Certified SysOps Administrator – Associate
- Certified Developer – Associate
- Certified DevOps Engineer – Professional
- Certified Security – Specialty
- Certified Database – Specialty
- Certified Machine Learning – Specialty
- Certified Data Analytics – Specialty
- Certified Advanced Networking – Specialty
- What Are the Differences Between the Professional and Associate Certifications?
- How Do the Specialty Certifications Differ From the Others?
- What Are the Overall Benefits of AWS Certifications?
- How To Prepare For Each Certification?
What Are the AWS Certifications?
Offered by Amazon Web Services, the 12 certifications are one of the most in-demand cloud computing qualifications in the IT industry. Based on Amazon’s cloud service platform, each certificate demonstrates a shared understanding of the platform, best practices, and terminology.
To get certified, you must pass a multiple-choice exam based on real-life scenarios. A firm knowledge of the exam content, hands-on experience, and prior IT experience can increase your chances of passing the test. Based on a candidate’s skills and experience, industry veterans often divide these certifications into four distinct categories: practitioner, associate, professional, and specialty certificates.
Here is a brief overview of each certification:
Certified Cloud Practitioner
The AWS Certified Cloud Practioner is a foundation-level certificate that tests your overall knowledge of the Amazon cloud. Most individuals use it as a stepping stone to more advanced certifications.
Prerequisites
Anyone can take the exam, however, prior knowledge of IT and various types of cloud platforms should help. Candidates who have at least six months of experience in a field related to Amazon cloud will likely feel more comfortable.
Content
The following are some of the major topics covered in the exam:
- Value of the shared responsibility model.
- The best practices, costs, billing, and economics of the AWS infrastructure.
- Description of concepts such as storage, network, and database.
The Exam
There are 65 multiple-choice and multiple-response questions on the exam, and you’ve got 90 minutes to attempt those. Results are reported in the range between 100 and 1000. Anyone who scores at least 700 is certified.
Here is the breakdown of questions:
- 26% – Cloud Concepts
- 25% – Security and Compliance
- 33% – Technology
- 16% – Billing and Pricing
The cost of the exam is $100. You can also take a practice exam.
Certified Solutions Architect – Associate
The AWS Certified Solutions Architect – Associate certification will test your knowledge of building and deploying robust applications on the cloud. This license is suitable for someone in a solutions architect role.
Prerequisites
It is an associate-level course that demands at least one year of experience working with some sort of cloud infrastructure.
Content
The exam mainly tests your ability to:
- Define a solution for customers based on Amazon’s architectural design principles.
- Provide directions to an organization on how to implement a reliable architecture based on best practices.
The Exam
The exam consists of 65 multiple-choice and multiple-response questions. You have 130 minutes to complete the exam. The maximum score is 1000 but you need 720 to pass the test.
Here is a breakdown of the content:
- 30% – Design Resilient Architectures
- 28% – Design High-Performing Architectures
- 24% – Design Secure Applications and Architectures
- 18% – Design Cost-Optimized Architectures
You need to pay $150 to take the exam. A mock test is also offered at an additional price.
Certified Solutions Architect – Professional
The AWS Certified Solutions Architect – Professional certification is recommended for individuals who perform a solutions architect role. You’re tested for advanced technical skills in designing distributed applications.
Prerequisites
There is are prerequisites to take the exam. However, two years of prior experience on the Amazon platform is highly recommended before attempting this test.
Content
You should have the knowledge and the ability to:
- Design and deploy scalable applications.
- Migrate multi-tier applications on the Amazon platform.
- Implement cost control strategies.
The Exam
The professional-level exam consists of 75 questions that should be completed within three hours. To pass, candidates must score at least 750 out of a maximum of 1000 points.
The exam consists of five domains:
- 12.5% – Design for Organizational Complexity
- 31% – Design for New Solutions
- 15% – Migration Planning
- 12.5% – Cost Control
- 29% – Continuous Improvement for Existing Solutions
The exam fee is $300. You can also take a practice exam for $40.
Certified SysOps Administrator – Associate
The AWS Certified SysOps Administrator – Associate certification checks your knowledge of administrating, managing, and operating the Amazon cloud platform and related applications.
Prerequisites
This is an associate-level course without any prerequisites. It is more suitable for individuals who have some experience in managing Amazon web services.
Content
The exam will test your knowledge of:
- Operating and maintaining the infrastructure.
- Implementing security control and troubleshooting the system.
- Applying networking concepts and implementing architectural requirements.
- Identifying incidents and performing disaster recovery procedures.
The Exam
The exam consists of 65 multiple-choice and multiple-response questions. You have 130 minutes to complete the exam. Candidates must score at least 720 to complete certification requirements.
Following is a list of main content domains and their weightage in the exam:
- 20% – Monitoring, Logging, and Remediation
- 16% – Reliability and Business Continuity
- 18% – Deployment, Provisioning, and Automation
- 16% – Security and Compliance
- 18% – Networking and Content Delivery
- 12% – Cost and Performance Optimization
The total cost of the exam is $150. You can also take a practice test.
Certified Developer – Associate
The AWS Certified Developer – Associate certificate is geared towards developers. The exam checks candidate’s ability to develop, deploy, and troubleshoot Amazon cloud-based applications.
Prerequisites
There are no official requirements or preconditions. However, you may feel more comfortable if you have at least one year of prior experience working with Amazon-based applications. In-depth knowledge of at least one high-level programming language is also useful.
Content
During the exam, you are tested for your ability to:
- Demonstrate knowledge of Amazon cloud infrastructure and related applications.
- Develop, deploy and debug applications.
- Understand cloud-native applications to write codes.
The Exam
The exam consists of 65 multiple-choice and multiple-response questions. You have 130 minutes to score at least 720 to pass the test.
Here is an overview of test domains and their respective weightage:
- 22% – Deployment
- 26% – Security
- 30% – Development with AWS Services
- 10% – Refactoring
- 12% – Monitoring and Troubleshooting
The exam fee is $150. To prepare for the exam, you may also take a practice test, which costs $20.
Certified DevOps Engineer – Professional
The AWS Certified DevOps Engineer – Professional certification is mainly intended for individuals who can manage continuous delivery systems according to the best practices of the Amazon cloud infrastructure.
Prerequisites
You’re likely to feel comfortable taking the exam if you’ve at least two years of experience in the development of Amazon cloud-based services. Strong knowledge of at least one programming language is highly recommended as well.
Content
The exam will validate your ability to:
- Implement, manage, and automate various methodologies, continuous delivery systems, security control, and governance processes.
- Define, deploy, and implement systems that are scalable and self-healing.
- Design and maintain tools to automate the entire process.
The Exam
Candidates have up to three hours to attempt a mix of 75 multiple-choice and multiple-response questions. You’ll need to score at least 750 to pass the exam.
The exam’s content is divided into the following six modules:
- 22% – SDLC Automation
- 19% – Configuration Management and Infrastructure as Code
- 15% – Monitoring and Logging
- 10% – Policies and Standards Automation
- 18% – Incident and Event Response
- 16% – High Availability, Fault Tolerance, and Disaster Recovery
There is a $300 fee to take the exam. You may also take a practice test.
Certified Security – Specialty
The AWS Certified Security – Specialty certificate will test your ability to secure and troubleshoot the Amazon web services platform.
Prerequisites
Before attempting the exam, it’s recommended to get at least two years of work experience with the Amazon cloud infrastructure. Most candidates also have extensive IT experience.
Content
Exam topics mainly focus on:
- Understanding of specialized data classifications, data encryption methods, and secure Internet protocols.
- Knowledge and deployment experience of using security services related to the Amazon platform.
- Decision-making ability regarding cost, security, and deployment complexity of the platform.
The Exam
This is a multiple-choice or multiple-response-based exam constituting 65 questions. You have 170 minutes to get at least 750 points out of a maximum of 1000 points.
Following are the five test domains and their respective weightage:
- 12% – Incident Response
- 20% – Logging and Monitoring
- 26% – Infrastructure Security
- 20% – Identity and Access Management
- 22% – Data Protection
The exam costs $300. Candidates also have the option to take a practice test by paying an additional fee of $40.
Certified Database – Specialty
The AWS Certified Database – Specialty certification validates experience in a range of AWS database services. The license ensures that you’re able to build and manage a reliable database for your organization.
Prerequisites
This is an advanced level certification, which is suitable for candidates who have at least two years of experience working in the relevant field. Since you’re expected to perform a database-focused role, it’s recommended to get plenty of experience with database technologies before attempting this exam.
Content
Candidates are tested for:
- Knowledge of key features of Amazon cloud-based database services.
- The ability to design and recommend changes to the existing database.
The Exam
The exam has 65 multiple-choice and multiple-response questions. You will have three hours to complete the test. The minimum passing score is 750 out of 1000.
Major topics covered by the exam are:
- 26% – Workload-Specific Database Design
- 20% – Deployment and Migration
- 18% – Management and Operations
- 18% – Monitoring and Troubleshooting
- 18% – Database Security
You will need to pay $300 to take the exam. To prepare, you can take a practice test before the exam.
Certified Machine Learning – Specialty
The AWS Certified Machine Learning – Specialty certification is intended for individuals who want to implement machine learning solutions to businesses.
Prerequisites
There are no prerequisites to take the exam. An ideal candidate would have one to two years of experience in machine learning and the Amazon cloud platform. In-depth knowledge of data science is a plus.
Content
The certification ensures that you’re proficient in:
- Understanding AWS service in the context of a machine learning environment.
- Designing scalable ML solutions for organizations.
- Justifying your ML approach to a business problem.
The Exam
The exam consists of 65 questions that are either multiple-choice or multiple-response. You have 180 minutes to achieve a passing score of 750.
Here is a breakdown of four test domains:
- 20% – Data Engineering
- 24% – Exploratory Data Analysis
- 36% – Modeling
- 20% – Machine Learning Implementation and Operations
The exam fee is $300. To test your knowledge, you can also take a practice exam, which costs $40.
Certified Data Analytics – Specialty
The AWS Certified Data Analytics – Specialty certificate validates your proficiency in using the Amazon cloud computing services to build and maintain analytics solutions.
Prerequisites
Candidates can attempt the exam comfortably if they have at least five years of experience with data analytics technologies. Ideally, you should also have a minimum of two years of experience with Amazon cloud infrastructure.
Content
The content of the exam mainly tests your knowledge in:
- Understanding and defining Amazon data analytics services.
- Explaining how data analytics fits in the life cycle of a specific project.
The Exam
You have 180 minutes to attempt a mix of 65 multiple-choice and multiple-response questions. The passing score on this exam is 750.
The exam consists of five domains:
- 18% – Collection
- 22% – Storage and Data Management
- 24% – Processing
- 18% – Analysis and Visualization
- 18% – Security
It costs $300 to sit in the exam. Candidates may also take a practice test to prepare for the certification.
Certified Advanced Networking – Specialty
The AWS Certified Advanced Networking – Specialty certification checks your ability to perform complex networking tasks using a variety of Amazon cloud-based solutions.
Prerequisites
While prior certification is not required, it’s recommended that you hold at least one of the associate-level certificates. Prior hands-on experience and extensive knowledge of implementing network solutions are advised.
Content
The exam validates your ability to:
- Understand advanced concepts related to most types of networking.
- Design, maintain, and automate the Amazon cloud-based network architecture.
The Exam
You have 170 minutes to attempt 65 multiple-choice or multiple-response questions.
There is no pass or fail. Unlike other such exams, your answers are scored against a minimum standard established by professionals.
Following is a list of the main content domains and their weightings:
- 23% – Design and Implement Hybrid IT Network Architectures at Scale
- 29% – Design and Implement Networks
- 8% – Automate Tasks
- 15% – Configure Network Integration with Application Services
- 12% – Design and Implement for Security and Compliance
- 13% – Manage, Optimize, and Troubleshoot the Network
Candidates must pay $300 to take the exam.
What Are the Differences Between the Professional and Associate Certifications?
Associate certifications are often seen as a stepping stone towards professional certifications. Under certain circumstances, you may be able to pass an associate-level exam after reading the content, but a professional-level certificate requires deep knowledge and work experience dealing with the Amazon cloud infrastructure.
Before attempting the professional-level exam, it’s normal for individuals to have at least one associate-level certificate and at least two years of experience. This experience is necessary because the scope and the depth of knowledge are much extensive compared to the associate certifications.
How Do the Specialty Certifications Differ From the Others?
Specialty certifications test a candidate’s knowledge of specific subjects. While they are somewhat similar in scope to professional certification, the content focuses heavily on a particular specialty such as networking, data analytics, databases, security, and machine learning.
Specialty certifications are often regarded as top-level certifications because you will likely need at least two to five years of experience before attempting the test. Due to the expertise required to take the exam, it’s recommended to pass the relevant AWS foundation and associate-level certificates before applying for specialty certifications.
What Are the Overall Benefits of AWS Certifications?
The certifications offer bright career prospects, recognition, and typically a higher paycheck. Amazon is a market leader in cloud technology and it will continue to dominate the landscape. Pursuing a certificate related to the Amazon cloud platform gives you the option of a variety of career opportunities in both the public and the private sectors.
You may gain appreciation and acknowledgment from your peers and industry experts and invitations to regional appreciation summits and events will allow you to expand your professional network. Credentials also look good on the resume.
Regarding salary increments, various surveys indicate that certification improves your salary by almost 15% to 25%. Getting certified also opens various opportunities to supplement your income through freelancing and third-party contracts.
How To Prepare For Each Certification?
You can’t walk into an examination center and expect to breeze through the test. Therefore, it’s important to give yourself ample time to prepare for the exam. Try to get hands-on experience by registering for training labs. The live environment offers real-world scenarios, which is a great starting point for the test.
You can also study FAQ and Whitepapers on the official website and learn test-taking strategies from third-party websites. After you’re ready, register for a practice test on the official website.
Here are some general steps to help you prepare for AWS certifications:
Review the exam guide: AWS provides exam guides for each certification, which outline the exam’s objectives, format, and recommended preparation resources. Review the exam guide thoroughly to understand what you need to learn for the exam.
Take training courses: AWS offers various training courses and workshops for each certification. These courses cover the exam’s topics and provide hands-on practice with AWS services. You can take courses in person, online, or self-paced. Additional resources include: the AWS partner network, AWS in-person events, third party training providers, and the AWS online community.
Use practice exams: Practice exams help you assess your readiness for the exam and familiarize yourself with the exam format. AWS offers official practice exams for each certification, or you can use third-party practice exams.
Join study groups or forums: Join study groups or online forums to connect with other candidates preparing for the same certification. You can share study resources, ask questions, and discuss challenging topics.
Review AWS documentation and whitepapers: AWS provides comprehensive documentation and whitepapers that cover each service’s features, best practices, and use cases. Review these resources to gain a deeper understanding of AWS services and concepts.
Once you feel confident in your knowledge and skills, schedule the exam. This will give you a deadline to work towards and help you stay focused on your preparation.
Whether you’re a cloud architect, developer, security professional, or data analyst, there’s an AWS certification that can help you stand out in your field and demonstrate your proficiency with AWS services. With the growing demand for cloud skills in the job market, earning an AWS certification can also help you advance your career and increase your earning potential.
Originally published April 29, 2021. Updated March 2023
At LogicMonitor, ingesting and processing time series metric data is arguably the most critical portion of our AI-powered hybrid observability platform. In order to fully prepare for growth, scale, and fault-tolerance, we have evolved what we refer to as our Metrics Processing Pipeline from a monolith to a microservice-driven architecture. We previously detailed our evolutionary journey in a series of articles:
However, the further we ventured into our evolution from a monolith system into a distributed microservice and message-driven architecture, new problems arose. In this article, we will detail one such problem and how we architected the solution.
Our Kafka-based Microservices architecture and scaling challenges
Using Quarkus and Kubernetes to consume from Kafka
First, let’s consider a high-level partial architectural overview. After ingesting time series metric data, the data eventually makes its way onto a Kafka topic where it is consumed and processed by a microservice. This runs on Kubernetes and was written using the Quarkus framework. We run multiple instances of this microservice, and they join the same Kafka consumer group. The partitions of the Kafka topic are assigned to the consumers in the group, and when the service scales out, more instances are created and join the consumer group. The partition assignments will be rebalanced among the consumers, and each instance gets one or more partitions to work on.
This microservice is a highly compute-intensive application, and we leverage the Kubernetes Horizontal Pod Autoscaler (HPA) to automatically scale instances of the application based on cpu utilization metrics.
At LogicMonitor, we support multiple different datapoint metric types for the time series data we ingest. After collecting the data from the source, we need to have some additional processing of the raw data in order to produce the actual value of a datapoint as dictated by its metric type. As a requirement of this processing, we need to cache some prior existing data for each datapoint as we process incoming messages from Kafka. For more details about how we use Kafka in this way, check out this article.
Stateful Kubernetes Microservice Scaling Challenges
Now, we arrive at the crux of the problem. In order to maximize our scalability and throughput, we’ve built a multi-instance message-consuming application, which scales in and out based on computational load. Additionally, the membership of Kafka consumer group is extremely dynamic in nature, where various partitions can move over from one consumer to another in the same group.
However, as we mentioned above, each datapoint we process has some state associated with it – the cached existing data. Thus, a Kubernetes pod getting killed due to a scale-down event is not a loss-less incident. Now we lose the context associated with the data points that this pod was processing. Similarly, a Kafka partition reassignment is also not a loss-less incident. The new consumer that gets a partition either doesn’t have the context of the data points in the partition, or it has older, out-dated context.
Whenever this loss of context occurs, we experience ephemeral inconsistencies with our metrics processing. We need to address this loss of context that occurs due to a Kubernetes pod shutdown or Kafka partition reassignment.
Cost-Performance considerations for choosing a distributed cache
At first glance, it would seem like there is an obvious solution for this: replace the in-memory cache we have been using to save the context with a distributed cache of some sort. However, there are other factors which make that solution more complicated:
- Speed – Due to the sheer volume of data that LogicMonitor ingests, our metrics processing pipeline relies on speed. If we introduce a distributed cache for every single raw metrics message evaluation, we are replacing a very cheap in-memory lookup with a lookup to an external system over the network. There’s a high probability that such a lookup will negatively affect the speed of the pipeline.
- Cost – There is a high volume of processed messages , so calling to a distributed cache for each message has non-trivial cost implications. For example, the cache will require sufficient resource allocation to handle such frequent traffic, and the additional required network bandwidth will also have cost implications.
- Nature of the data being cached – In order to store context associated with the data points, we built an in-house data structure specifically for metrics processing purposes. Initial investigation into various caching systems indicated that none of them offer a direct alternative, and instead we will have to massage/modify the data in order to store them in an external cache. However, if we need to serialize/deserialize the data every time for each write/read,the overall processing speed will diminish.
Using Redis to preserve scalable microservice’s state
Balancing state storage between distributed and in-memory cache
The natural solution is a middle ground between in-memory cache and external distributed cache. We continue to store the contextual data in memory. There are two scenarios which cause the loss of this data:
- the container is shut down by Kubernetes (due to scale down event or deployment)
- partition rebalancing is triggered in the Kafka consumer group
If we can detect when these two events occur and trigger a persistence of the contextual data to an external distributed cache, we should be able to save the “state.” Subsequently, when we’re looking up contextual data, if we do not find it present in the in-memory cache, we can look it up from the external cache and if found, insert it back into the in-memory cache, thus restoring the “state.”
We can lose context without incurring too much overhead by saving the contextual data into an external distributed persistent cache during container shutdown and partition rebalancing, we avoid losing the contextual data. By only looking up the contextual data from the external cache (if it’s not found in the in-memory cache), we avoid incurring too much increased overhead.

Why we chose AWS ElastiCache Redis
We chose Cluster-mode AWS ElastiCache Redis as our distributed cache. Here are a few of the main reasons:
- We need to quickly look up contextual data for one specific datasource instance. So, a key-value based data store like Redis is ideal.
- Redis has exceptional write and access times, which meets our requirement to be able to quickly dump and read back the contextual data.
- We want the contextual data that we’re backing up to be resilient. AWS ElasticCache for Redis in cluster-mode provides the flexibility that we’re looking for by distributing the data across multiple shards and also providing replication
- As the LogicMonitor platform grows, we want to use a distributed caching that can scale horizontally. AWS ElastiCache Redis provides non-disruptive horizontal scaling for Redis clusters.
Leveraging Quarkus shutdown hooks, Kafka listeners, and Redisson
Here is how we implemented our solution:
- We used the Redisson as Redis client
- We used Quarkus framework’s shutdown hook to listen for Kubernetes container shutdown and trigger the backup of contextual data
- We used the Kafka ConsumerRebalanceListener to listen for Kafka consumer rebalance events and trigger backup of contextual data for the partitions which were revoked in the event

- We implemented our own in-house serialization and deserialization logic geared towards quickly writing cached data in-memory to Redis and quickly reading backed-up data from Redis
- In order to speed up the data backup, we parallelized the process
- When reading back persisted data from Redis, we implemented a check to ensure that we were not reading outdated information from Redis. If the data didn’t pass this check, it was discarded.
Using Compression and TTL to optimize Redis memory usage
- In order to minimize Redis cluster memory requirement and network I/O, we used the lz4 compression algorithm to compress the context data before we saved it onto Redis. On the other end, we use Redisson’s compression capabilities to simultaneously decompress the data after fetching it.
- The contextual data that we save to Redis does not need to stay on Redis for long periods of time, as the contextual data is only relevant for the next few polling intervals of the associated LogicMonitor datasources. To further optimize our Redis Cluster memory usage, we set a TTL (time-to-live) value for each contextual data we save to Redis, based on the collection interval of the associated LM datasource. This allows automatic freeing up of Redis memory once the data is no longer needed
- Once we’ve backed up contextual data to Redis, we invalidate and remove the data from the local in-memory cache. This has the following advantages:
- ensures that when contextual data is backed up to Redis, it is no longer backed up again in the future. This also ensures that only the latest contextual data is present in Redis
- ensures that the in-app cache no longer contains unnecessary and potentially contextual data
- frees up in-app memory
Summary
LogicMonitor continues to migrate our monolithic services to microservices to improve how we develop, deploy, and maintain our services. Check back for more articles about our experience during the journey.
A couple of weeks ago, I had the opportunity to attend AWS re:invent, one of the biggest cloud industry events of the year. An event so massive and big that only AWS can pull it off – 50,000 people marching across half a dozen of the finest hotels on the Las Vegas strip. The expo hall alone would have taken more than a couple of days to cover all the vendor booths spread across the expansive Venetian convention center. As I clocked an average of 20K steps every day between various breakout sessions, the expo hall, networking and having some fun, let me share a few of my observations from the event.

Being there among the 50K attendees, I could truly appreciate the cloud ecosystem that has developed over the last decade or more. Every vendor there was solving one or more key challenges related to a specific aspect of the cloud. And these challenges exist regardless of what cloud you may use. The expo hall itself was divided into many sections of vendors under categories like “Analytics,” “Security,” “Data Management,” etc.

We had some really good traffic at the LogicMonitor booth in the expo hall. When I spent some time at the booth talking with the attendees who were interested in our comprehensive observability platform, LM Envision, I heard a few comments that were remarkably similar to what we have heard from other enterprises outside of the event too. The challenges the attendees were talking about were no longer the old “we are struggling to adopt the cloud” or “we are migrating our on-prem data centers to the cloud.” They were talking about more modern use cases and a newer set of challenges that were more relevant to today’s hybrid and multi-cloud realities.
Three observations from an Observability standpoint
- Multi-cloud is real but wasn’t spoken about – Since this was an AWS event, you could clearly see and hear the “hybrid cloud” messages everywhere, but you couldn’t see the “multi-cloud” messages anywhere. But, the reality is that most enterprises today have at least 3-4 cloud implementations. IT leaders who spoke to me were truly struggling with wanting a cloud-neutral / vendor-agnostic observability platform that can look across multiple clouds and truly assess what is going on across their entire cloud landscape.
- Tool sprawl is still a major challenge for IT leaders – A senior IT leader at a major medical device manufacturer visited our booth. He shared that he had two of our competitor products already. When I inquired further, he explained that his company does a lot of M&A every year and as a result, their IT organization ends up supporting redundant IT tools and struggles with visibility and costs. He said he has at least six other monitoring tools in addition to the two he named! The solution he was looking for was a single platform that could replace multiple such tools that weren’t quite helping his team anyway.
- OpenTelemetry and related standards are a huge enabler for Observability – This was a validation I acquired as I was attending multiple breakout sessions as well as from conversations with other peers at the conference. In order for enterprises to be observable, the IT team can enable capturing metrics, logs, and traces from all corners of their IT infrastructure. However, to truly understand issues happening within their applications, the Dev/DevOps teams need to start instrumenting their code to enable advanced troubleshooting and reduce debugging time. OpenTelemetry and related open standards enable you to avoid vendor lock-in by making sure that your instrumentation code will work with any observability tool that supports such open standards effectively. LogicMonitor is proud not only to support these standards but also to remain an active contributor to such open standards.
The entire event was full of such wonderful learnings, validations and epiphanies. I had a wonderful time connecting with old friends as well as making a ton of new friends.
As we look ahead to 2023, we are excited about the partnership with AWS and all the wonderful things we can do together in this ever-opportunistic space.
Amazon Web Services (AWS) products can feel countless, and at LogicMonitor, we are working tirelessly to bring monitoring support to as many of them as possible. With so many products and tools already on your plate, we want to make sure that monitoring is not a hassle, but rather a trusted companion.
AWS provides tools that help with application management, machine learning, end-user computing, and much more. While the list of tools AWS offers continues to grow, LogicMonitor consolidates data from these services and empowers users to monitor them side by side with the rest of their infrastructure, whether it’s in the cloud or on-premises. See how LogicMonitor uses tools from analytics and services for business continuity.
Jump to:
- Monitoring AWS Analytics
- AWS Athena
- AWS Glue
- Monitoring AWS Application-Related Services
- Document DB
- RDS Service Limits
- MQ
- Codebuild
- Monitoring AWS Services For Business Continuity
- AWS Opsworks Stacks
- AWS AppStream 2.0
- AWS Connect
- AWS SageMaker
Monitoring AWS Analytics

AWS Athena
Amazon Athena is an interactive query service that analyzes data stored in Amazon Simple Storage Service (S3) using standard SQL. By monitoring Athena, we give users insight into failed queries and long-running queries. This allows them to catch issues sooner and resolve them faster, thus maximizing uptime and performance.
The data is collected into two query types: Data Definition Language (DDL) and Data Manipulation Language (DML). Each extracted metric is identified by the state of the query: canceled, failed, and succeeded. With that indicator, you can focus your attention on the metrics that are relevant to your task. You can also create a dashboard specifically for failed queries, which is useful for troubleshooting, and another dashboard for successful queries, which will help you come up with acceptable baselines for more accurate thresholds. While troubleshooting, you want to track the execution time. By bringing all the time metrics such as query queue, query planning, engine execution, and service processing into one place, you can quickly identify bottlenecks or the place where things break down. Once you feel like you are in a steady-state and things are running smoothly, make sure to go back and set suitable thresholds for the time metrics. With this, along with our dynamic thresholds feature, you can rest assured that you will only get notified when it matters.
AWS Glue
AWS Glue is a fully managed extract, transform, and load (ETL) service that helps customers prepare and load their data for analytics. The service automatically detects an enterprise’s structured or unstructured data when it is stored within other AWS services, such as data lakes in Amazon Simple Storage Service (S3), data warehouses in Amazon Redshift, and other databases that are part of the Amazon Relational Database Service. All of these can be monitored by LogicMonitor. The only objects from AWS Glue with measurable data are the Jobs, so this DataSource discovers the jobs automatically.
To accurately monitor Jobs, we need to keep track of executors, stages, and tasks.
The number of actively running job executors, “active executors”, can be helpful to identify any delays due to straggler scenarios. Keep an eye on active executors and the max executors metrics to know when it is time to provision more data processing units (DPUs). Make sure to create an alert and warnings for active executors metric as it approaches the max executors value.
As your job goes through different stages, it is helpful to have the completed stages metric on a dashboard to monitor the progress. If you notice that some stages are taking too long, you can correlate the CPU load, memory, and elapsed time metrics to triage the issue and potentially add more resources. Or you can repartition the load to lower the elapsed time. If there is any parallelism within your stages, it is essential to track the completed task and failed tasks. Depending on the workflow of the job, you need to set an appropriate threshold for failed tasks. These failed tasks can help determine abnormalities within the data, cluster, or script.
Monitoring AWS Application-Related Services
Document DB* (Database)
Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. Our users already monitor traditional MongoDB workloads, and with this DataSource, they can now monitor AWS DocumentDB workloads within LogicMonitor’s platform. For organizations that are planning to migrate from a traditional MongoDB environment to DocumentDB, LogicMonitor will provide metrics to closely monitor the transition and alert if there are any hiccups.
Keep the clusters healthy by monitoring the CPU, memory, network activity, database connections, and IOPS metrics. In the case of a node going down, you can monitor the replication lag metric (instanceReplicaLag). There is a chance that if the lag is too high, then your data is at risk of not correctly syncing, so make sure to keep an eye on this metric.
It is crucial to keep backups either via the retention period or snapshots, but it is also essential to know how much storage space these backup are using. Overlooking storage in a cloud environment can create massive headaches, so keep track of the larger backup files to make sure you stay within the storage budget. By tracking these metrics, backupRetentionPeriodStorageUsed, and snapshotStorageUsed, you’ll be able to see any unexpected spikes and take action immediately.
RDS Service Limits* (Database)
LogicMonitor already has RDS specific Datasources that will handle useful monitoring metrics. This new enhancement is adding unique metrics to monitor the RDS service limits. Amazon sets service limits on the number of RDS resources that can be created by an AWS account. A few of these resources include the number of database clusters, instances, parameters, snapshots, and allocated storage. With this data, you can be on top of the limits/quotas Amazon has on your RDS resources. You won’t get caught off guard and will be able to respond accordingly when critical resources are closing in on the quota.
MQ (Application Integration)
Frequently, users will have complex services that may partially rely on MQ and partially on other infrastructure running elsewhere, either on-premise or Cloud. Centralized monitoring in LogicMonitor equips them with more visibility so they can proactively prevent issues with these complex services in hybrid environments. Amazon MQ is a managed message broker service for Apache ActiveMQ. LM provides visibility into these managed brokers so that application teams can maximize uptime and performance with metrics such as message counts, CPU, memory, storage, and network utilization.

For active/standby deployments, LogicMonitor has a DataSource specifically for the standby resources. Separating the active and standby metrics allows for more clarity and keeps the data consistent.
Codebuild (Developer Tools)
AWS CodeBuild is a fully managed continuous integration service that compiles source code, runs tests, and produces software packages that are ready to deploy. You can monitor the build projects to ensure builds are running successfully and at the right time. It is ultimately giving you the information to optimize performance and uptime alongside your infrastructure data.
Application development teams need to be aware when builds fail. This DataSource has predefined thresholds that will automatically trigger notifications in the case of a failed build. Builds need to happen promptly, and with the breakdown of build time, you can pinpoint the step in the build that is causing delays and possibly add resources to optimize the build time of your projects.
Monitoring AWS Services for Business Continuity
AWS Opsworks Stacks
Cloud-based computing usually involves many components, such as load balancer, application servers, databases, etc. AWS OpsWorks Stacks, the original service, provides a simple and flexible way to create and manage stacks and applications. AWS OpsWorks Stacks lets you deploy and monitor applications in your stacks. Through CloudWatch we can get aggregate metrics for a stack, which helps understand the overall health of the resources within the stack & prevent issues. The metrics collected can be broken down into:
- CPU Percentage
- System
- User
- Input/Output Operations
- Memory
- Total
- Cached
- Free
- Buffered
- Average Load
- 1 minute
- 5 minutes
- 15 minutes
- Processes
- Total Active
A stack of the same resource is called a layer. For example, a layer represents a set of EC2 instances that serve a particular purpose, such as serving applications or hosting a database server. These layers can also be monitored within LogicMonitor. With LogicMontor’s robust coverage of AWS, you can also view the individual resource metrics of the layers through the out-of-the-box Datasources of the service.
AWS AppStream 2.0
Amazon AppStream 2.0 allows organizations to manage desktop applications and securely deliver them to any computer. This service helps users run programs that could be resource-intensive on underpowered machines. AppStream is similar to Citrix or Microsoft remote desktop. It becomes essential to monitor the capacity and utilization of the fleets. With a simple dashboard, you can track current and remaining capacity, along with capacity utilization. When an insufficient capacity error happens, LogicMonitor will automatically send an alert.

AWS Connect
Customer service is as crucial as its ever been and people want fast and quality responses. Amazon Connect is an easy to use omnichannel cloud contact center that helps companies provide superior customer service at a lower cost. When utilizing this service, it is beneficial to track the following metrics: status of the service, the volume of calls, quota, and missed calls.
With out-of-the-box alerts for missed calls, misconfigured phone numbers, concurrent calls percentage, and recording upload errors, you can rest assured that you will be on top of any problematic situation.
AWS SageMaker
AWS SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy machine learning models quickly. Users want to monitor this service alongside existing infrastructure to ensure uptime and performance across their entire complex infrastructure, particularly where SageMaker models are being used in production environments. SageMaker Endpoints are discovered as resources in LogicMonitor.
Each endpoint will have its own CPU, memory, and disk utilization metrics. All of which have predefined thresholds for automatic alerts and notifications. LogicMonitor tracks the total invoked HTTP requests and will alert if there are any 5XX errors. You can baseline the latency of the model and the SageMakers overhead. With these baselines, you can be on top of any changes when new models have been deployed or see the difference in latency when doing an A/B deployment.
Conclusion
We recently highlighted our commitment to our AWS partnership, and our developers keep cranking out new AWS monitoring integrations. Here are some previous blogs highlighting AWS analytics services and application development services. All of these new integrations are included with our LM Cloud offering. LogicMonitor will automatically start collecting these metrics if you are an LM Cloud customer and already utilizing any of these Amazon services.
If you have any questions regarding these new monitoring integrations, please reach out or contact your CSM for more information. Or you can try LogicMonitor for free
Working remotely has become the norm globally for businesses, specifically in regards to IT. Many companies have offices spread throughout the world, decentralized employees or contractors, or simply have a flexible work from home (WFH) policy.
Remote work is an aspect of digital transformation that is often left out of conversations when it comes to ensuring business continuity and driving growth, despite research indicating that everything will continue to push towards hybrid work environments. This is especially true in terms of monitoring the infrastructure that makes working from home possible because many of our WFH capabilities rely on third-party, cloud-based solutions and services that we don’t control.
Regardless, having the right infrastructure monitoring in place will propel decisive action during critical moments, maintain business continuity and productivity, and ultimately, deliver a consistent customer experience.
Best Practices to Ensure WFH Infrastructure Reliability
Create An Action Plan
Every solution will be put under performance strain during peak periods. While working remotely or managing remote team members, a service interruption of one of your third-party services can cause a domino effect, knocking down any chance you have of being productive. But you don’t need to have blind trust in your vendors and risk a negative impact on your team. An action plan is the best way to ensure business continuity and reduce loss in productivity. An ounce of prevention is worth a pound of cure, and taking brief time to outline redundancies, backups, and steps for mitigating issues will go a long way if something happens.
Identify Business-Critical Tools and Services
For most businesses working remotely, communication solutions and services are paramount for success. Whether this is a video conferencing tool (e.g., Zoom, Google Meet, Slack, etc.), VoIP provider, or other collaboration applications (e.g., Office 365), you should start by understanding what services your business relies on to get work done. Create a list ranking the most important tools in your tech stack and work on steps that can be taken to ensure uptime.
Monitor Tool Availability
Your teams need to know when their applications and tools are going to be accessible so they can plan accordingly. It should not be up to each individual team member to check the status of these third-party tools and communicate their temporary inability to work. Utilize a centralized platform showing the availability of your business-critical tools and services, so you can effectively communicate any interruptions and help set expectations for your business.
Take Swift Action and Communicate
We’ve all experienced losing time when our video conferencing service is experiencing issues. This could be a problem due to the high bandwidth utilization on your company’s VPN, or it could be an outage at a third-party provider. Regardless of the issue, communicating this information widely, thanks to centralized monitoring, allows your team to save valuable time.
If you have a meeting scheduled for 3:30 PM, but the video conferencing service you use is having issues at 3:20 PM, you can quickly notify everyone to use a different conferencing service or reschedule the meeting.
Manage VPNs For Decentralized Access
For many employees working from home, VPN availability is required to access specific tools or portals such as an internal intranet or GitHub. If your VPN is down or lagging, engineers may not be able to connect to the servers to fix critical issues right away.
Engineering teams aren’t the only ones who rely on VPNs. By monitoring VPNs and logging historical trending data, you’ll be able to assess if non-VPN essential employees are lowering bandwidth efficiency for your on-call or international teams. If that is the case, then there are measures you can take on your VPNs, whether you use Palo Alto, AWS, Azure, GCP, or others.
Monitor Bandwidths
Are you finding that there is high bandwidth utilization through a tool every day between 2:00 PM and 5:00 PM? Understanding bandwidth allocation and utilization might be the root cause of why something is freezing. For distributed teams, the solution can be as simple as allocating resources more during certain parts of the day than others. Monitoring and logging bandwidth data across your tech stack can help you find these trends easily.
LogicMonitor and Work From Home Infrastructure Monitoring
LogicMonitor’s remote monitoring solutions can help businesses avoid at-home frustration and take third-party application availability into their own hands. LogicMonitor has always focused on extensibility, fast ROI, and contextual intelligence. Our SaaS, agentless platform offers out-of-the-box DataSources and dashboard widgets to provide visibility into critical work-from-home solutions. Our intelligent monitoring helps ensure that your remote workforce is driving business performance and maintaining your customer experience.
LogicMonitor offers pre-configured dashboards that show performance and health in real-time for:
SaaS Applications (e.g. Zoom, Office 365, Slack)
Voice-Over-Network (e.g. Cisco VoIP)
Virtual Desktop Infrastructure (e.g. Citrix Virtual Apps & Desktops, VMware Horizon)
Virtual Private Networks (e.g. Palo Alto VPN, AWS VPN, Azure Virtual Network Gateway, GCP VPN Gateway, Pulse Secure)






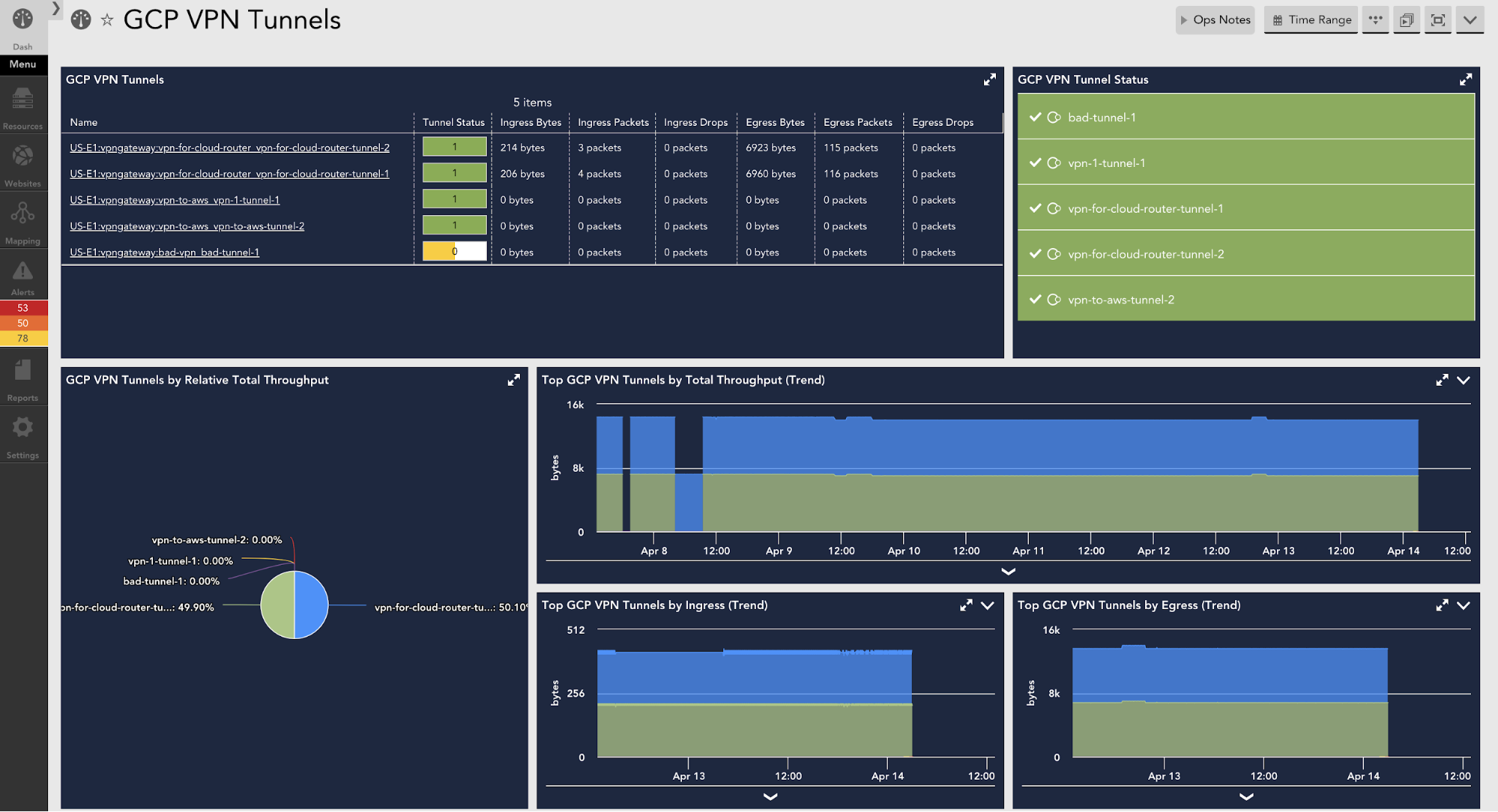
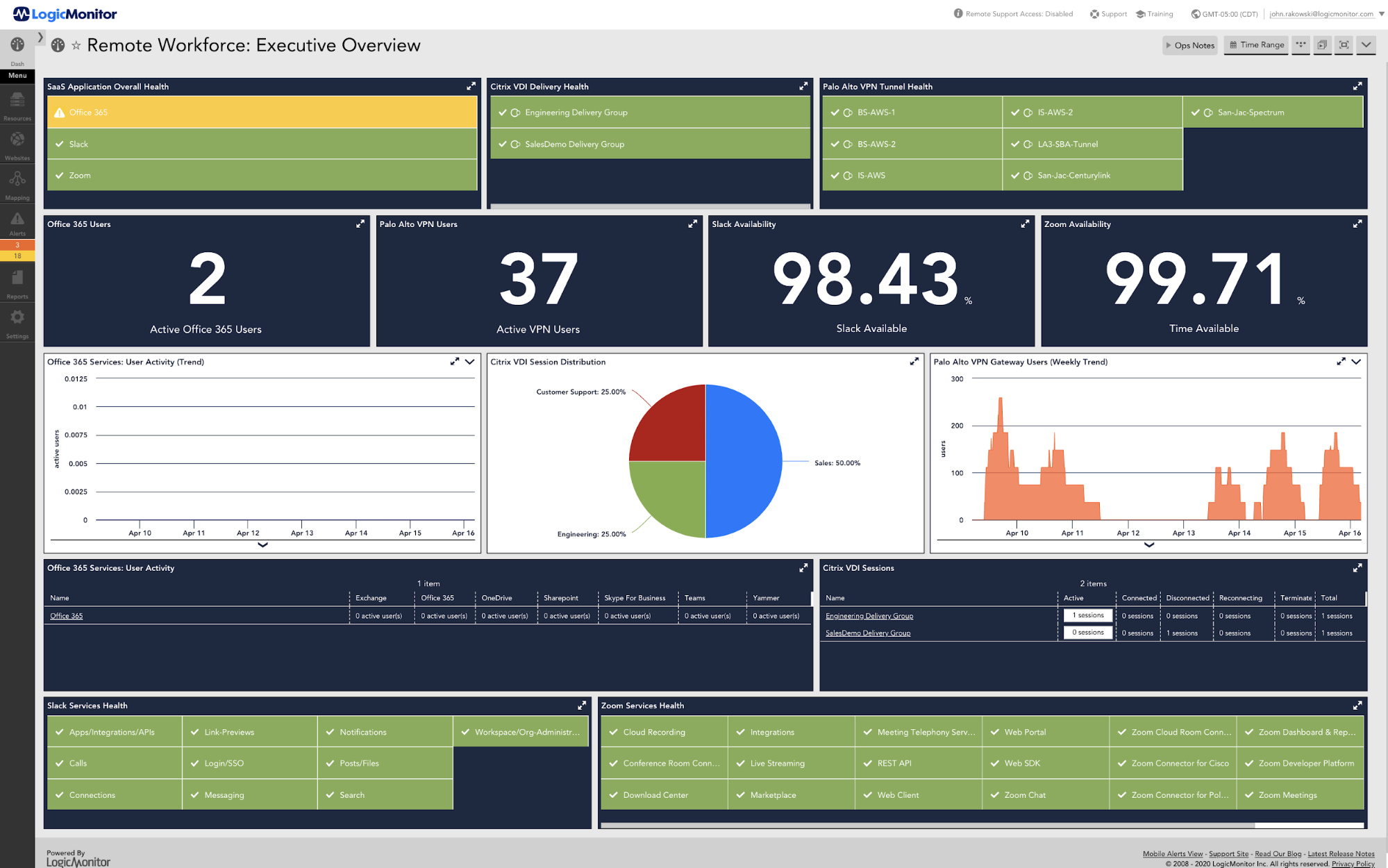
We also make it easy to roll up technical WFH performance metrics into an overall executive dashboard, providing the ability to understand, in real-time, how your remote workforce is driving productivity.
In addition, the Remote Session feature provides a secure way to remotely access monitored devices. Remote sessions are enabled via the use of Apache Guacamole, a clientless remote desktop gateway that requires no plugins or client software.
We hope these dashboards and tips help you monitor your infrastructure with ease while working remotely. If you are already a customer, you can check out our library of dashboards here. If you are new to LogicMonitor, you can try our platform for free.
Updated October 2022. Originally posted April 2020.
How we upgrade 10,000+ containers with zero downtime!
Managing Kubernetes version upgrades can be a formidable undertaking. API versions are graduated, new features are added and existing behaviors are deprecated. Version upgrades may also impact applications needed by the Kubernetes platform; affecting services like pod networking or DNS resolution. At LogicMonitor, we ensure our Kubernetes version upgrades are successful through a process designed to instill collaboration and due diligence in a repeatable fashion. Let’s jump into our Kubernetes upgrade best practices!
The Breakdown:
We run managed AWS EKS clusters in our environment. EKS clusters have a control plane managed by AWS and when a Kubernetes version upgrade is initiated, AWS upgrades the control plane components on our behalf. Our workload consists of a mixture of management and self-management node groups. During a Kubernetes version upgrade, AWS triggers an instance refresh on our managed node groups. To upgrade our self managed node groups, we trigger the instance refresh. To ensure nodes are cordoned off and gracefully drain of pods, we run a tool called the aws-node-termination-handler. As nodes running the prior version of Kubernetes are drained and terminated, new instances take their place, running the upgraded Kubernetes version. During this process thousands of containers are recreated across our global infrastructure. This recreation occurs at a rate which does not impact the uptime, accessibility or performance of any of our applications. We upgrade Kubernetes clusters with zero downtime or impact to our production workloads!

Datapoints we’ve found especially useful when monitoring Kubernetes version upgrading:
- Auto Scaling Group Metrics
- Desired Instance Count
- Max Size
- Min Size
- Total Nodes
- Cluster Autoscaler Metrics
- Number of Unscheduled Pods
- Number of Evicted Pods
- Number of Node in Unready State
- Number of Node Not Started
- Number of Node in Ready State
The Team
Our version upgrades are performed by a team of three engineers who play specific roles during the process described below. Ops(New), Ops(Lead) & Ops(Sr):
Operator (On-boarding) Ops(New)
This operator is new to the cycle of Kubernetes upgrades. As a new member of the team, their main goal is to familiarize themselves with the upgrade process as a whole; studying past upgrades, learning the process and supporting the current upgrade efforts. In this role, the operator will perform upgrades on both a production and non-production cluster under the guidance of the operator responsible for research and development Ops(Lead).
Core Duties
- Responsible for executing processes on development/pre-production cluster
- Responsible for executing processes on a production cluster
Operator (Lead) Ops(Lead)
This operator is the lead engineer during the upgrade cycle. They are responsible for researching changes, upgrading any critical components, determining a course of action for breaking changes, and scheduling all cluster upgrades. A considerable amount of time is dedicated to planning the proposed changes by this engineer. This operator also acts as a liaison between different stakeholders. This involves communicating important dates, interesting findings or feature deprecations. Ops(Lead) coordinates knowledge transfers sessions between the Ops(New) and Ops(Sr) as needed. In the previous cycle this operator participated as Ops(New) and has experience executing the upgrade process on both development and production clusters.
Core Duties
- This operator in the previous cycle was Ops(New), leveraging that experience, Ops(Lead) is expected to have an understanding of the execution tasks.
- Responsible for executing processes on development/pre-production clusters
- Responsible for executing processes on production clusters
- Responsible for core research of version upgrade changes
- Responsible for coordinating associated work between Ops(New) and Ops(Sr)
Operator (Senior): Ops(Sr)
This operator previously participated in the last two upgrade cycles. This engineer serves as a knowledge resource for both Ops(Lead) and Ops(On-boarding).
Core Duties
- This operator in the previous cycle was Ops(Lead), leveraging that experience, the Ops(Snr) serves as a mentor to the Ops(Lead) and Ops(On-boarding).
- Responsible for assisting with executing processes on production clusters.
The Process

Research: The lead operator starts the cycle by investigating changes between the current version and the proposed version we would like to upgrade to. During this phase of work, the lead operator shares findings, road-blockers, and items of interest with the core team. To assist the lead operator several resources were gathered over the course of previous upgrade cycles to help determine what Kubernetes components have changed in the release we plan to run. The lead operator uses these resources to answer the following questions;
- Questions
- Were any APIs graduated/deprecated that we should be concerned about?
- Are there any features enabled by default that we should be concerned about or can leverage in our Kubernetes implementation?
- What components currently running in our cluster will be impacted by the Kubernetes version upgrade ?
- Resources
Critical Components: We deem several components in our clusters as critical to the operations of Kubernetes, each of these components has recommended versions to run on specific Kubernetes versions. Research is done to verify we can run the supported version.
We define these services as critical to our clusters viability
- DNS
- Pod Networking
- Cluster Ingress
- Cluster Autoscaling
Infrastructure Development and Rollout: Once the resource portion is concluded the lead operator generates a series of pull requests to alter the infrastructure which supports our Kubernetes clusters. These pull requests are approved per our internal guidelines.
Rollout:
- Communication: During each rollout, a communication thread is created to provide team members updates on the progress of each process executed during the upgrade. In the event that an issue occurs these communication threads can be used for further investigation.
- Pre-Production: The rollout begins to our pre-production clusters. This gives the lead operator an opportunity to vet the changes and determine a course of action if a component is found in an unhealthy state. The on-boarding engineer is expected to shadow the lead engineer during these pre-production rollouts and is expected to execute the rollout on a pre-production cluster under the supervision of the lead operator.
- Production: Our production clusters are updated over the course of two maintenance periods. Traditionally, changes of this nature are done during a scheduled maintenance window due to the potential impact to our customers if something were to occur. All operators participate in the rollout of our production clusters; monitoring, overseeing and communicating updates as the rollout progresses.Once all nodes are on the new Kubernetes version, each operator performs a series of health checks to ensure each cluster is in a fully functioning state.
In conclusion, our upgrade process consists of identifying changes to critical Kubernetes components, determining their impact to our environment and creating a course of action when breaking changes are identified. Once we’re ready to implement a version upgrade, we trigger an instance refresh to our various node groups, which causes nodes to be cordoned off and gracefully drained of pods prior to termination. The team responsible for managing the upgrade process consists of 3 different roles which are cycled through by each on-boarded engineer. Kubernetes is an important part of our infrastructure, and the process we’ve designed at LogicMonitor allows us to upgrade Kubernetes versions without impacting the uptime of our services.
Load balancers are critical components in AWS systems, and selecting the most suitable option might prove confusing for some users. Choosing the right option enables users to distribute various tasks across resources, resulting in an optimized process. Operating a network without load balancers may result in significant delays in web services during a spike in user requests.
The modern digital age has led to a significant increase in user requests from social media use and IoT operations, increasing the importance of load balancers as critical components in web traffic management.
Essentially, a suitable load balancer serves as the gatekeeper or contact point between client devices and backend servers, driving application responsiveness, scalability, and availability while reducing the risk of traffic overload (i.e., increased fault tolerance).
Load balancers follow a preset algorithm with varying complexities, determining request distribution across servers. The most widely used algorithms include round-robin, hashing methods, least response time, and custom loads.
Understanding ALBs (Application Load Balancers)
ALBs operate from the application layer or the seventh layer of the OSI (Open Systems Interconnections) model, which drives communications among multiple systems. An ALB receives the request and evaluates listener (a process that checks for connection requests) rules through prioritized order, essentially routing requests based on content to a specific subgroup.
Users can choose to route the algorithm of listener rules specifically to different target groups. Additionally, system administrators can conveniently add or remove target groups according to the changing priorities and demands of a project or organization without causing disruptions to the overall requests received by the application.
Users can combine ALB with various other AWS services to optimize the availability and scalability of applications. These services may include AWS Certificate Manager, Amazon EC2, Amazon Route 53, AWS WAF, and Amazon CloudWatch.
For instance, Amazon CloudWatch offers users real-time application monitoring capabilities, providing quick error detection and troubleshooting in response to system anomalies or performance delays. With Amazon Route 53, users can create an alias record, listing multiple IP addresses for responding to DNS requests, an effective web solution for managing geographically distributed servers.
How ALB Works
ALB primarily distributes network load in a public cloud to optimize availability and stability. The ALB monitors the health of applications within the seventh layer of the OSI model and will specifically route traffic to healthy registered targets.
Specifically, ALB assesses data packets identified with HTTP and HTTPS headers, providing developers with detailed reports of each check that zooms in on the specific code and HTTP-related errors encountered.
AWS users can apply ALB through internal load balancing in front of AWS EC2 instances, applications (through Rest API), or containers. Multiple services in a complex environment may share a single ALB load balancer through path-based routings, such as routing it to different server clusters based on application needs. Users can route up to 10 applications behind a single ALB.
Core Concepts of ALB
ALB includes various components that users should familiarize themselves with for optimized network configuration. These include rules, targets, priorities, and conditions. The rules of ALB set the desired action that matches a client’s request by fulfilling a specific condition or path pattern. An ALB determines the sequence of rules fulfillment based on priority, according to numerical values in ascending order.
Understanding ELBs (Elastic Load Balancers)
Introduced by AWS in 2009, the ELB, also known as the classic load balancer, is a software-based load balance that automates the traffic distribution process across multiple targets. These targets may include containers and IP addresses.
The ELB operates from the fourth layer (i.e., the transport layer) of the OSI model and transfers requests based on the applied protocol of TCP or IP and links with a similar backend target. For instance, when an ELB receives a client request from a TCP port, it routes the request based on the rules pre-configured during a load balancer setup.
The classic load balancer serves various functions to provide application stacks with added security, easier management, and reliability.
Specifically, ELB provides web networks with functions that include:
- User verification with a public key
- Centralized administration of SSL certificates
- Traffic distribution among registered and healthy instances
- Support for IPv4 and IPv6
ELB provides a single entry point for users of EC2 instances, efficiently distributing traffic across available targets. With configured health checks, ELBs can closely monitor the health of each registered target and limit traffic distribution to healthy locations, improving fault tolerance.
How ELB Works
Usually, with classic load balancers, users register instances directly with the load balancer when creating a load balancer node within an enabled availability zone (AZ).
Having multiple servers behind AZs within a region improves the availability of networks, enabling the ELB to reroute traffic to available AZs during inaccessibility. ELB routes traffic evenly among AZs during default configurations. However, the default setting could lead to overload/load imbalance if servers are not responding to the requests.
The activation of cross-zone load balancing enables each balancer node to distribute traffic across registered targets across all enabled AZs. Alternatively, disabling cross-zone load balancing limits each balancer node to distributing traffic to its specific AZ. As such, cross-zone load balancing mitigates the risks of potential load imbalances.
Comparing ALB vs. ELB
ALBs and ELBs share several core functions and capabilities despite their specialized features. For starters, they feature high availability and scalability, and users can choose to add or remove resources when required without disrupting the overall request flow from applications. ALB and ELB support primary functions that include:
- Sticky sessions — the system assigns an attribute to users via cookies and IP tracking.
- SSL termination — decrypting encrypted traffic before distribution to registered targets.
- Idle session terminations — the load balancer automatically closes a session after a pre-configured period of inactivity.
- Connection draining — a feature that enables users to safely remove instances without prematurely terminating client connections.
- Health checks — providing health checks to identify anomalies in instances for further action.
The Differences Between ALB and ELB
In 2016 AWS improved its original ELB program with ALB, which provides users with additional features and enhanced functions.
For instance, while ELB enables users to add and remove listeners according to changing priorities, the ALB provides the extra feature of viewing and editing listener routing rules. As such, users can conveniently direct routes to a predefined target group.
ALB also rectifies some of the limitations of ELB, which include:
- The unsupported function of forwarding traffic to more than one port per instance
- Incompatibilities with EKS servers that run on Fargate
- Incapabilities of delivering traffic to IP addresses, which prevents traffic to targets outside AWS
- Lack of support for WebSockets and HTTP/2
- Serves only one permitted domain name
One of the most significant differences between ALB and ELB lies in the system of their routing process. While ELB only routes traffic based on routing number, ALB facilitates context-driven routing based on multiple references, including query string perimeter, source IP, port number, hostname, and path.
Additionally, ALB supports Server Name Indication (SNI), enabling it to bypass the conventional limitations of the ELB in serving a single domain name. ALB offers users native HTTP/2 and WebSocket support via multiple requests delivered through a single connection.
ALB Provides Built-in Capabilities
ELB only allows routing via a single port, while ALB supports distribution through multiple ports and lambda functions. Lambda functions enable users to manage and run various functions, build websites through serverless coding, and create customized ALB targets through serverless methods.
ALB offloads and optimizes server functions by performing advanced tasks directly from its program, including a preconfigured redirection or fixed response and user authentication through LDAP, Microsoft AD, and Google. The added load balancer function enables applications to focus on their business logic for increased performance.
Other notable built-in ALB capabilities include:
- Container-based application support, enabling a single instance to host multiple containers listening for network traffic behind the same target group.
- The capabilities of performing fine-grained health checks at the port level. Specifically, ALB has console support for filtering by tags, resource, and resource-based permissions, so users can use IAM policies to implement the fine-grain controls.
- Providing detailed access logs stored securely in a compressed format.
Access Logs
ALB’s access logs include a detailed breakdown of information that consists of the original HTTP response and response_processing_time, which determines the time required to transfer a client request, request type, and time stamps.
Summary of ALB vs. ELB
Users might find it advantageous to apply ALB in balancing a load of HTTP/HTTPs web traffic with a specific path or host-based routing that drives context-driven requests. These will help expedite processes in complex environments, such as the microservice landscape.
While the ALB might seem like a complete upgrade of the classic ELB, each load balancing solution has its recommended uses. For instance, ALB functions better for content-based routing, especially in response to modern trends like the rise of microservices that require the rapid and reliable distribution of complex applications.
Users who operate from a network with carefully defined load balancers for each server with direct links between URLs and services will likely find it more cost-effective and practical to apply the classic ELB in handling their traffic needs.
Also, users with old AWS accounts need to note that ELB is the only load balancer that works on EC2-Classic and supports application-defined sticky session cookies. However, ELB/classic load balancer users should note that AWS has not released new updates for the program and will retire the EC2-Classic by August 15, 2022, so users should consider a systematic migration to a VPC, which avoids interrupting their existing workload.
What to Expect With Efficient Load Balancing
Upgrading from a classic load balancer can bring users a wide range of benefits that optimize the overall performance of their networks.
Reinforced Security
Modern load balancers are compatible with the VPC, which supports multiple security features such as SSL/TLS decryption and user verification. System administrators will have the option of establishing private connections through AWS PrivateLink between the VPC and load balancers through a VPC endpoint, enabling secure offline traffic distributions.
Additionally, modern load balancers continue to include more TLS policies, such as ELB Security Policy FS 2018 06, that control TLS and cipher suites. These implementations will optimize forward secrecy (i.e., safeguarding the security of session keys) across application load balancing.
Unmatched Availability
Users can expect uninterrupted traffic across multiple healthy targets throughout multiple AZs, keeping requests and data running with optimized efficiency.
Newfound Versatility
Modern load balancing enables users to function across AWS and on-premise systems via a single load balancer. System administrators will face less friction in managing, migrating, or transferring control (i.e., failover) to on-premise resources when required.
Greater Flexibility
Updated load balancing enables users to autoscale effectively according to varying application workloads. Additionally, users can host multiple applications from a single instance while maintaining individual security groups for optimized communication between applications.
Closing Thoughts
AWS continues to expand its load-balancing options, giving users greater flexibility in distributing their traffic for efficient server functions. The company launched its Network Load Balancer (NLB) in 2017, aimed at handling millions of requests per second. NLB provides users with a wide range of traffic management improvements, including long-running connections that power demanding IoT, gaming, messaging applications, and failover support.
System developers have also created specialized services to manage authentication, authorization, and accounting through AAA computer security solutions for reduced cost, improved scalability, and optimized efficiency.
With similar fees for each load balancing solution, the price point would rarely serve as a factor in deciding on the best fit. Ultimately, the chosen load balancing method depends on the underlying location where a workload functions. However, the complete progression toward ALB use seems clear within the horizon.
Overall, AWS’s load balancers integrate seamlessly with the rest of its services. Choosing the most suitable loader ultimately depends on the complexity of existing network infrastructure, environment, and demands.
Sign up to access comprehensive monitoring and alerts across AWS networks across unlimited devices.
Life before containerization was a sore spot for developers. The satisfaction of writing code was constantly overshadowed by the frustration of attempting to force code into production. For many, deployments meant hours of reconfiguring libraries and dependencies for each environment. It was a tedious process prone to error, and it led to a lot of rework.
Today, developers can deploy code using new technology such as cloud computing, containers, and container orchestration. This guide discusses each of these technologies. It will also answer the question: “What are the differences between Elastic Beanstalk, EKS, ECS, EC2, Lambda, and Fargate?”
Contents
- AWS Cloud Computing Concepts
- Elastic Beanstalk
- Elastic Kubernetes Service (EKS)
- Elastic Container Service (ECS)
- Elastic Compute Cloud (EC2)
- Lambda
- Fargate
- Comparing Services
AWS Cloud Computing Concepts
Cloud computing refers to accessing IT resources over the internet. Resources include things such as servers, storage, deployment tools, and applications. The AWS term for cloud computing is “compute,” which refers to virtual servers where developers place their code. In AWS, developers choose the specifications for their server, such as:
- Operating system
- CPU
- Memory
- Storage
Cloud computing offers several benefits, including:
- Cost Savings: Companies won’t need to purchase servers to run their applications.
- Time Savings: Developers don’t need to worry about managing the servers. The cloud computing vendor handles all maintenance tasks.
- Security: The cloud vendor implements and manages all security tasks for the resources.
- Scalability: Resources are accessed on demand. If the developer needs more resources, the cloud computing platform can automatically allocate whatever is required.
- Flexibility: Developers can choose configuration options best suited to their needs.
- Reliability: Computing vendors provide an availability guarantee (usually 99.99%) to ensure applications are always available.
Containerization
Containerization refers to a process of packaging code into a deployable unit. This unit is called a container, and it holds everything needed to run that code. From the application’s code to the dependencies and OS libraries, each unit contains everything the developer needs to run their application. The most widely known container technology is Docker, an open-source tool with broad community support. The benefits of containerization include:
Easier Application Deployment
Application deployment is one of the most basic yet effective benefits. With containers, developers have a much easier time deploying their applications because what once took hours now takes minutes. In addition, developers can use containers to isolate applications without having to worry about them affecting other applications on the host server.
Better Resource Utilization
App containers allow for greater resource utilization. One of the main reasons people deploy containers is because it enables them to use fewer physical machines. If someone has many applications running on a single machine, they will often find that it results in the under-utilization of one or more applications.
Containerization helps deal with this problem by allowing developers to create an isolated environment for each application. This approach ensures that each app has the resources to run effectively without impacting others on the same host. It also reduces the chance of introducing malicious code into production.
Improved Performance
Containers provide a lightweight abstraction layer, allowing developers to change the application code without affecting the underlying operating system. Plus, the isolation attributes for applications in a container ensure that the performance of one container won’t affect another.
Application Isolation
One of the most significant benefits of app containerization is that it provides a way to isolate applications. This is especially important when hosting multiple applications on the same server.
Containerization also simplifies deployment and updates by making them atomic. With containers, developers can update an application without breaking other applications on the same server. Containers also allow developers to deploy an updated version and roll it back if necessary. As a result, developers can quickly deploy and update their applications and then scale them without downtime or unexpected issues.
Increased Security
Since containers isolate applications from one another and the host system, vulnerabilities in one application won’t affect other apps running on the same host. If developers find a vulnerability, they can address it without impacting other applications or users on the same server.
Container Images
Images are templates used to create containers, and they are made from the command line or through a configuration file. The file is a plain text file that contains a list of instructions for creating an image. The file’s instructions can be simple, such as pulling an image from the registry and running it, or they can be complex, such as installing dependencies and then running a process.
Images and containers also work together because a container is what runs the image. Although images can exist without containers, a container requires an image to run. Putting it all together, the process for getting an image to a container and running the application is as follows:
- The developer codes the application.
- The developer creates an image (template) of the application.
- The containerization platform creates the container by following the instructions in the configuration file.
- The containerization platform launches the container.
- The platform starts the container to run the application.
Container Orchestration
As applications grow, so does the number of containers. Manual management of a large number of containers is nearly impossible, so container orchestration can step in to automate this process. The most widely known container orchestration tool is Kubernetes. Amazon offers services to run Kubernetes, which we’ll discuss later in the article. Docker also provides orchestration via what is known as Docker Swarm.
How Does Containerization Work?
The first step in the process is creating a configuration file. The file outlines how to configure the application. For instance, it specifies where to pull images, how to establish networking between containers, and how much storage to allocate to the application. Once the developer completes the configuration file, they deploy the container by itself or in clusters. Once deployed, the orchestration tool takes over managing the container.
After container deployment, the orchestration tool reads the instructions in the configuration file. Based on this information, it applies the appropriate settings and determines which cluster to place the container. From there, the tool manages all of the below tasks:
- Provisioning containers
- Configuring applications
- Deployment
- Scaling
- Lifecycle management
- Managing redundancy and availability
- Allocating resources
- Load balancing
- Service discovery
- Health monitoring of containers
Now, we move to a discussion of the differences between Elastic Beanstalk, EKS, ECS, EC2, Lambda, and Fargate.
Elastic Beanstalk
Continuing from the discussion above, Elastic Beanstalk takes simplification one step further. Traditionally, web deployment also required a series of manual steps to provision servers, configure the environment, set up databases, and configure services to communicate with one another. Elastic Beanstalk eliminates all of those tasks.
Elastic Beanstalk handles deploying web applications and services developed with Java, .NET, PHP, Node.js, Python, Ruby, Go, and Docker on servers such as Apache, Nginx, Passenger, and IIS.
The service automatically provisions servers, compute resources, databases, etc., and deploys the code. That way, developers can focus on coding rather than spending countless hours configuring the environment.
Elastic Beanstalk Architecture
When deploying an app on Elastic Beanstalk, the service creates the following:
- Elastic Beanstalk Environment: This is the runtime environment for the application. The service automatically creates a URL for access to the application and a CNAME.
- EC2 Instances: These are the compute nodes for the application.
- Autoscaling Group: It handles scaling the compute nodes. Although the autoscaling group handles provisioning, developers can configure how many to establish. They can also specify when autoscaling can start.
- Elastic Load Balancer: It distributes web requests across the compute nodes.
- Security Groups: Specifies what network traffic is allowed in and out of the application.
- Host Manager: The host manager is a service on each compute node that monitors the node for performance issues.
Worker Environment
When web requests take too long to process, performance suffers. Elastic Beanstalk creates a background process that handles requests to avoid overloading the server. Worker Environments, a separate set of compute resources, process longer running tasks to ensure the resources serving the website can continue to respond quickly.
Elastic Kubernetes Service (EKS)
Containerization eliminates a tremendous burden from the developers. However, there’s an additional challenge they face: provisioning, scaling, configuring, and deploying containers. Depending on the size of the application, manually handling these tasks is overwhelming. The solution? Container orchestration.
Amazon EKS is a managed Kubernetes service that helps developers easily deploy, maintain, and scale containerized applications at a massive scale. Amazon EKS replaces the need for manual configuration and management of the Kubernetes components, simplifying cluster operations.
What Is Kubernetes?
Kubernetes is an open-source containerization platform that automatically handles all tasks associated with managing containers at scale. Kubernetes is also known as K8s, and it does the following:
- Service Discovery: Kubernetes exposes containers to accept requests via Domain Name Service (DNS) or an IP address.
- Load Balancing: When container resource demand is too high, Kubernetes routes requests to other available containers.
- Storage Orchestration: As storage needs grow, K8s mounts additional storage to handle the workload.
- Self-Healing: If a container fails, Kubernetes can remove it from service and replace it with a new one.
- Secrets Management: The tool stores and manages passwords, tokens, and SSH keys.
EKS Architecture
The Amazon EKS infrastructure comprises several components that interact to perform container orchestration. Specifically, EKS architecture consists of:
Master Nodes
The master nodes are responsible for several tasks, including scheduling containers on worker nodes based on resource availability and CPU/memory limits.
EKS Control Plane
The control plane manages Kubernetes resources and schedules work to run on worker nodes. It includes the API Server, which handles communication with clients (e.g., kubectl), and an API server process that runs one or more controller-type operations in a loop to supervise work.
EKS Worker Nodes
Worker nodes run on EC2 instances in a VPC. A cluster is a group of worker nodes that run the application’s containers, while the control plane manages and orchestrates work between worker nodes. Organizations can deploy EKS for one application, or they can use one cluster to run multiple applications.
Worker nodes run on EC2 instances in the company’s virtual private cloud to execute the code in the containers. These nodes consist of a Kubelet Service and the Kube-proxy Service.
- Kubelet Service: The Kubelet Service runs on the cluster and handles communication between clusters. It waits to receive instructions from the API server and executes those instructions.
- Kube-proxy Service: The Kube-proxy Service establishes and configures communication between services within the cluster.
EKS VPC: Virtual Private Cloud
This is a service to secure network communication for the clusters. Developers use the tool to run production-grade applications within a VPC environment.
Elastic Container Service (ECS)
ECS is an AWS proprietary container orchestration service. It is a fully managed service for running Docker containers on AWS, and it integrates with other AWS services, such as Amazon EC2, Amazon S3, and Elastic Load Balancing. Although ECS is similar to EKS, ECS does not automate the entire process.
ECS Architecture
The main components of ECS are:
Containers
ECS containers are pre-configured Linux or Windows server images with the necessary software to run the application. They include the operating system, middleware (e.g., Apache, MySQL), and the application itself (e.g., WordPress, Node.js). You can utilize your own containers that have been uploaded to AWS’s Elastic Container Registry.
Container Agent
An ECS Container Agent is a daemon process that runs on the EC2 instance and communicates with the ECS service. It does this by using the AWS CLI to send API requests and Docker commands. To use an ECS Container Service, a user needs to have at least one container agent running on an EC2 instance in the VPC. This agent communicates with the ECS service by calling the AWS API and Docker commands to deploy and manage containers.
Task Definition
An ECS task is a pairing of container image(s) and configurations. These are what run on the cluster.
ECS Cluster
An ECS cluster is a group of EC2 instances that run containers. ECS automatically distributes containers among the available EC2 instances in the cluster. ECS can scale up or down as needed. When creating a new Docker container, the developer can specify CPU share weight and a memory weight. The CPU share weight determines how much CPU capacity each container can consume relative to other containers running on the same node. The higher the value, the more CPU resources will be allocated to this container when it runs on an EC2 instance in the cluster.
Task Definition File
Setting up an application on ECS requires a task definition file. The file is a JSON file that specifies up to 10 container definitions that make up the application. Task definitions outline various items, such as which ports to open, which storage devices to use, and specify Access Management (IAM) roles.
Task Scheduler
The ECS Task Scheduler handles scheduling tasks on containers. Developers can set up the ECS Task Scheduler to run a task at a specific time or after a given interval.
Elastic Compute Cloud (EC2)
EC2 provides various on-demand computing resources such as servers, storage, and databases that help someone build powerful applications and websites.
EC2 Architecture
The EC2 architecture consists of the following components:
Amazon Machine Image (AMI)
An AMI is a snapshot of a computer’s state that can be replicated over and over allowing you to deploy identical virtual machines.
EC2 Location
An AWS EC2 location is a geographic area that contains the compute, storage, and networking resources. The list of available locations varies by AWS product line. For example, regions in North America include the US East Coast (us-east-1), US West Coast (us-west-1), Canada (ca-central-1), and Brazil (sa-east-1).
Availability Zones are separate locations within a region that are well networked and help provide enhanced reliability of services that span more than one availability zone.
What Type of Storage Does EC2 Support?
EBS – Elastic Block Storage
These are volumes that exist outside of the EC2 instance itself, allowing them to be attached to different instances easily. They persist beyond the lifecycle of the EC2 instance, but as far as the instance is concerned, it seems like a physically attached drive. You can attach more than one EBS volume to a single EC2 instance.
EC2 Instance Store
This is a storage volume physically connected to the EC2 instance. It is used as temporary storage and it cannot be attached to other instances and the data will be erased upon the instance being stopped, hibernated, or terminated.
Lambda
AWS Lambda is a serverless computing platform that runs code in response to events. It was one of the first major services that Amazon Web Services (AWS) introduced to let developers build applications without any installation or up-front configuration of virtual machines.
How Does Lambda Work?
When a function is created, Lambda packages it into a new container and executes that container on an AWS cluster. AWS allocates the necessary RAM and CPU capacity. Because Lambda is a managed service, developers do not get the opportunity to make configuration changes. The tradeoff means developers save time on operational tasks. Additional benefits are:
Security and Compliance
AWS Lambda offers the most security and compliance of any serverless computing platform. It meets regulatory compliance standards like PCI, HIPAA, SOC2, and ISO 27001. Lambda also encrypts all data in transit and at rest with SSL/TLS certificates.
Scalability
The service scales applications without downtime or performance degradation by automatically managing all servers and hardware. With Lambda, a company will only pay for the resources used when the function runs.
Cost Efficiency
Cost efficiency is one of the most significant benefits of AWS Lambda because the platform only charges for the computing power the application uses. So if it’s not being used, Lambda won’t charge anything. This flexibility makes it a great option for startups or businesses with limited budgets.
Leveraging Existing Code
In some cases, existing code can be used as is, such as a flask application, with very little adaptation.
Lambda also lets you create layers, which are often dependencies, assets, libraries, or other common components that can be accessed by the Lambda function to which they are attached.
Lambda Architecture
The Lambda architecture has three main components: triggers, the function itself, and destinations.
Triggers
Event producers are the events that trigger a Lambda function. For example, if a developer wants to create a function to handle changes in an Amazon DynamoDB table, they’d specify that in the function configuration.
There are many triggers provided by AWS, like the DynamoDB example above. Other common triggers would include handling requests to an API Gateway, an item being uploaded to an S3 bucket, and more. A Lambda function can have multiple triggers.
Lambda Functions
Lambda functions are pieces of code that can be registered to execute or respond to an event. AWS Lambda manages, monitors, and scales the code execution across multiple servers. Developers can write these functions in any programming language and make use of additional AWS services such as Amazon S3, Amazon DynamoDB, and more.
AWS Lambda operates on a pay-per-use basis, with a free tier that offers 1 million requests per month. Developers only pay for what they use instead of purchasing capacity upfront. This pay-per-use setup supports scalability without paying for unused capacity.
Destinations
When execution of a Lambda function completes, it can send the output to a destination. As of now, there are four pre-defined destinations:
- An SNS topic
- An SQL queue
- Another Lambda Function
- An EventBridge Event bus
Discussing each of those in detail is beyond the scope of this article.
Packaging Functions
If the code and its dependencies is sized at 10MB or over Lambda functions need to be packaged before they can run.
There are two types of packages that Lambda accepts, .zip archives and container images.
.zip archives can be uploaded in the Lambda console. Container Images must be uploaded to Amazon Elastic Container Registry.
Execution Model
When a function executes, the AWS container that runs it starts automatically. Once the code executes, the container shuts down after a few minutes. This functionality makes functions stateless, meaning they don’t retain any information about the request once it shuts down. One notable exception is the /tmp directory, the state of which is maintained until the container shuts down.
Use Cases for AWS Lambda
Despite its simplicity, Lambda is a versatile tool that can handle a variety of tasks. Using Lambda for these items keeps the developer from having to focus on administrative items. The tool also automates many processes for an application that a developer would normally need to write code for. A few cases are:
Processing Uploads
When the application uses S3 as the storage system, there’s no need to run a program on an EC2 instance to process objects. Instead, a Lambda event can watch for new files and either process them or pass them on to another Lambda function for further processing. The service can even pass S3 object keys from one Lambda function to another as part of a workflow. For example, the developer may want to create an object in one region and then move it to another.
Handling External Service Calls
Lambda is a perfect fit for working with external services. For example, an application can use it to call an external API, generate a PDF file from an Excel spreadsheet, or send an email. Another example is sending requests for credit reports or inventory updates. By using a function, the application can continue with other tasks while it waits for a response. This design prevents external calls from slowing down the application.
Automated Backups and Batch Jobs
Scheduled tasks and jobs are a perfect fit for Lambda. For example, instead of keeping an EC2 instance running 24/7, Lambda can perform the backups at a specified time. The service could be used to also generate reports and execute batch jobs.
Real-Time Log Analysis
A Lambda function could evaluate log files as the application writes each event. In addition, it can search for events or log entries as they occur and send appropriate notifications.
Automated File Synchronization
Lambda is a good choice for synchronizing repositories with other remote locations. With this approach, developers can use a Lambda function to schedule file synchronization without needing to create a separate server and process.
Fargate
AWS Fargate is a deployment option of ECS and EKS and doesn’t require managing servers or clusters. With Fargate, users simply define the number of containers and how much CPU and memory each container should have.
AWS Fargate Architecture
Fargate’s architecture consists of clusters, task definitions, and tasks. Their functions are as follows.
Clusters
AWS Fargate Clusters are a cluster of servers that run containers. When developers launch a task, AWS provisions the appropriate number of servers to run the container. Developers can also customize Docker images with software or configuration changes before launching them as a task on Fargate. Then, AWS manages the cluster for the user, making it easy to scale up or down as needed.
Task Definitions
Task definitions are JavaScript Object Notation (JSON) files that specify the Docker images, CPU requirements, and memory requirements for each task. They also include metadata about the task, such as environment variables and driver type.
Tasks
A task represents an instance of a task definition. After creating the task definition file, the developer specifies the number of tasks to run in the cluster.
What Are the Benefits of Fargate?
Fargate is easy to use. Deploying an application involves three steps:
- Configure the app’s environment.
- Describe the desired state of the app.
- Launch the app.
AWS Fargate supports containers based on Docker, AWS ECS Container Agent, AWS ECS Task Definition, or Amazon EC2 Container Service templates. The service automatically scales up or down without needing any changes to the codebase. Fargate has many benefits, which include:
- An easy, scalable, and reliable service
- No server management required
- No time spent on capacity planning
- Scale seamlessly with no downtime
- Pay-as-you-go pricing model
- A low latency service, making it ideal for data processing applications
- Integration with Amazon ECS, making it easier for companies to use both services in tandem
Comparing Services
The beauty of AWS is the flexibility it offers developers thanks to multiple options for containerization, orchestration, and deployment. Developers can choose which solution best meets their needs.
However, with so many options, it can be difficult to know which option to use. Here are a few tips on how to decide between a few of these services.
Elastic Beanstalk vs ECS
Elastic Beanstalk and ECS are both containerization platforms, but the degree of control available is one key difference between them. With Beanstalk, the developer doesn’t need to worry about provisioning, configuring, or deploying resources. They simply upload their application image and let Elastic Beanstalk take care of the rest. ECS, on the other hand, provides more control over the environment.
Which Option Is Best?
ECS gives developers fine-grained control over the application architecture. Elastic Beanstalk is best when someone wishes to use containers but wants the simplicity of deploying apps by uploading an image.
ECS vs EC2
AWS ECS is a container orchestration service that makes deploying and scaling containerized workloads easier. The Elastic Container Service supports Amazon Fargate launch types. With AWS EC2, users don’t have to configure or manage their container management as AWS runs and manages containers in a cloud cluster.
Example Scenario: Moving From ECS to EKS
There may be times when a developer wants to migrate from one service to another. One example might be migrating from ECS to EKS. Why would they want to do this? As we mentioned, ECS is proprietary to AWS, with much of the configuration tied to AWS. EKS runs Kubernetes, which is open source and has a large development community. ECS only runs on AWS, whereas K8s (that runs on EKS) can run on AWS or another cloud provider.
Transitioning to EKS gives developers more flexibility to move cloud providers. It is possible to move existing workloads running on ECS to EKS without downtime by following these steps:
- Export the ECS cluster to an Amazon S3 bucket using the ecs-to-eks tool.
- Create a new EKS cluster using the AWS CLI, specifying the exported JSON as an input parameter.
- Use kubectl to connect to the new EKS cluster and use a simple script to load the exported containers from S3 into the new cluster.
- Start scaling applications with AWS elbv2 update-load-balancers command and aws eks update-app command or use AWS CloudFormation templates for this purpose (see an example here).
- Once the user has successfully deployed the application on EKS, they can delete the old ECS cluster (if desired).