Amazon Redshift is a fast, scalable data warehouse in the cloud that is used to analyze terabytes of data in minutes. Redshift has flexible query options and a simple interface that makes it easy to use for all types of users. With Amazon Redshift, you can quickly scale your storage capacity to keep up with your growing data needs.
It also allows you to run complex analytical queries against large datasets and delivers fast query performance by automatically distributing data and queries across multiple nodes. It allows you to easily load and transform data from multiple sources, such as Amazon DynamoDB, Amazon EMR, Amazon S3, and your transactional databases, into a single data warehouse for analytics.
This data warehousing solution is easy to get started with. It offers a free trial and everything you need to get started, including a preconfigured Amazon Redshift cluster and access to a secure data endpoint. You can also use your existing data warehouses and BI tools with Amazon Redshift.Since Amazon Redshift is a fully managed service requiring no administrative overhead, you can focus on your data analytics workloads instead of managing infrastructure. It takes care of all the tedious tasks involved in setting up and managing a data warehouse, such as provisioning capacity, AWS monitoring and backing up your cluster, and applying patches and upgrades.
Contents
- What is Amazon Redshift?
- Key features of Amazon Redshift
- What is Amazon Redshift used for?
- What type of database is Amazon Redshift?
- What is a relational database management system?
- Is Redshift a SQL database?
- Which SQL does Redshift use?
- Is Redshift OLAP or OLTP
- What’s the difference between Redshift and a traditional database warehouse?
Amazon Redshift architecture
Amazon Redshift’s architecture is designed for high performance and scalability, leveraging massively parallel processing (MPP) and columnar storage. This architecture comprises the following components:
- Leader Node: The leader node receives queries from client applications and parses the SQL commands. It develops an optimal query execution plan, distributing the compiled code to the compute nodes for parallel processing. The leader node aggregates the results from the compute nodes and sends the final result back to the client application.
- Compute Nodes: Compute nodes execute the query segments received from the leader node in parallel. Each compute node has its own CPU, memory, and disk storage, which are divided into slices to handle a portion of the data and workload independently. Data is stored on the compute nodes in a columnar format, allowing for efficient compression and fast retrieval times.
- Node Slices: Compute nodes are partitioned into slices, each with a portion of the node’s memory and disk space. Slices work in parallel to execute the tasks assigned by the compute node, enhancing performance and scalability.
- Internal Network: Amazon Redshift uses a high-bandwidth network for communication between nodes, ensuring fast data transfer and query execution.
Key features of Amazon Redshift
- Columnar Storage: Data is stored in columns rather than rows, which reduces the amount of data read from disk, speeding up query execution. Columnar storage enables high compression rates, reducing storage costs and improving I/O efficiency.
- Massively Parallel Processing (MPP): Queries are executed across multiple compute nodes in parallel, distributing the workload and accelerating processing times. MPP allows Redshift to handle complex queries on large datasets efficiently.
- Data Compression: Redshift uses advanced compression techniques to reduce the size of stored data, minimizing disk I/O and enhancing performance. Automatic compression and encoding selection are based on data patterns, optimizing storage without user intervention.
- Automatic Distribution of Data and Queries: Redshift automatically distributes data and query load across all nodes in the cluster, balancing the workload and optimizing performance. Data distribution styles, such as key, even, and all, can be configured to align with specific use cases and data access patterns.
- Scalability: Redshift clusters can be easily scaled by adding or removing nodes, allowing organizations to adjust resources based on demand. Concurrency scaling enables automatic addition of transient capacity to handle peak workloads without performance degradation.
- Security: Redshift provides robust security features, including data encryption at rest and in transit, network isolation using Amazon VPC, and integration with AWS Identity and Access Management (IAM) for fine-grained access control. AWS Key Management Service (KMS) allows for the management and rotation of encryption keys.
- Integration with AWS Ecosystem: Redshift seamlessly integrates with other AWS services such as S3 for data storage, AWS Glue for data cataloging and ETL, and Amazon QuickSight for business intelligence and visualization. Integration with AWS CloudTrail and AWS CloudWatch provides logging, monitoring, and alerting capabilities.
What is Amazon Redshift used for?
Amazon Redshift is designed to handle large-scale data sets and provides a cost-effective way to store and analyze your data in the cloud. Amazon Redshift is used by businesses of all sizes to power their analytics workloads.
Redshift can be used for various workloads, such as OLAP, data warehousing, business intelligence, and log analysis. Redshift is a fully managed service, so you don’t need to worry about managing the underlying infrastructure. Simply launch an instance and start using it immediately.
Redshift offers many features that make it an attractive data warehousing and analytics option.
- First, it’s fast. Redshift uses columnar storage and parallel query processing to deliver high performance.
- Second, it’s scalable. You can easily scale up or down depending on your needs.
- Third, it’s easy to use. Redshift integrates with many popular data analysis tools, such as Tableau and Amazon QuickSight.
- Finally, it’s cost-effective. With pay-as-you-go pricing, you only pay for the resources you use.
What type of database is Amazon Redshift?
Amazon Redshift is one of the most popular solutions for cloud-based data warehousing solutions. Let’s take a close look at Amazon Redshift and explore what type of database it is.
First, let’s briefly review what a data warehouse is. A data warehouse is a repository for all of an organization’s historical data. This data can come from many sources, including OLTP databases, social media feeds, clickstream data, and more. The goal of a data warehouse is to provide a single place where this data can be stored and analyzed.
Two main databases are commonly used for data warehouses: relational database management systems (RDBMS) and columnar databases. Relational databases, such as MySQL, Oracle, and Microsoft SQL Server, are the most common. They store data in tables, each having a primary key uniquely identifying each row. Columnar databases, such as Amazon Redshift, store data in columns instead of tables. This can provide some performance advantages for certain types of queries.
So, what type of database is Amazon Redshift? It is a relational database management system. This means that it stores data in tables, each table has a primary key, and it is compatible with other RDBMSs. It is an open-source relational database optimized for high performance and analysis of massive datasets.
One of the advantages of Amazon Redshift is that it is fully managed by Amazon (AWS). You don’t have to worry about patching, upgrading, or managing the underlying infrastructure. It is also highly scalable, so you can easily add more capacity as your needs grow.
What is a relational database management system?
A relational database management system (RDBMS) is a program that lets you create, update, and administer a relational database. A relational database is a collection of data that is organized into tables. Tables are similar to folders in a file system, where each table stores a collection of information. You can access data in any order you like in a relational database by using the various SQL commands.
The most popular RDBMS programs are MySQL, Oracle, Microsoft SQL Server, and IBM DB2. These programs use different versions of the SQL programming language to manage data in a relational database.
Relational databases are used in many applications, such as online retail stores, financial institutions, and healthcare organizations. They are also used in research and development environments, where large amounts of data must be stored and accessed quickly.
Relational databases are easy to use and maintain. They are also scalable, which means they can handle a large amount of data without performance issues. However, relational databases are not well suited for certain applications, such as real-time applications or applications requiring complex queries.
NoSQL databases are an alternative to relational databases designed for these applications. NoSQL databases are often faster and more scalable than relational databases, but they are usually more challenging to use and maintain.
Is Redshift an SQL database?
Redshift is a SQL database that was designed by Amazon (AWS) specifically for use with their cloud-based services. It offers many advantages over traditional relational databases, including scalability, performance, and ease of administration.
One of the key features of Redshift is its relational database format, which allows for efficient compression of data and improved query performance. Redshift offers several other features that make it an attractive option for cloud-based applications, including automatic failover and recovery, support for multiple data types, and integration with other AWS.
Because Redshift is based on SQL, it supports all the standard SQL commands: SELECT, UPDATE, DELETE, etc. So you can use Redshift just like any other SQL database.
Redshift also provides some features that are not available in a typical SQL database, such as:
- Automatic compression: This helps to reduce the size of your data and improve performance
- Massively parallel processing (MPP): This allows you to scale your database horizontally by adding more nodes
- User-defined functions (UDFs): These allow you to extend the functionality of Redshift with your own custom code
- Data encryption at rest: This helps to keep your data safe and secure
So, while Redshift is an SQL database, it is a very different database that is optimized for performance and scalability.
Which SQL does Redshift use?
Redshift uses PostgreSQL, specifically a fork known as Postgres 8.0.2. There are a few key reasons for this. First and foremost, Redshift is designed to be compatible with PostgreSQL so that users can easily migrate their data and applications from one database to the other. Additionally, PostgreSQL is a proven and reliable database platform that offers all of the features and performance that Redshift needs. And finally, the team at Amazon Web Services (AWS), who created Redshift, have significant experience working with PostgreSQL.
PostgreSQL is a powerful open-source relational database management system (RDBMS). It has many features make it a great choice for use with Redshift, such as its support for foreign keys, materialized views, and stored procedures. Additionally, the Postgres community is very active and supportive, which means there are always new improvements and enhancements being made to the software.
Redshift employs several techniques to further improve performance in terms of performance, such as distributing data across multiple nodes and using compression to reduce the size of data sets.
Is Redshift OLAP or OLTP
Most are familiar with OLTP (Online Transaction Processing) and OLAP (Online Analytical Processing). Both are essential database technologies that enable organizations to manage their data effectively.
OLTP databases are designed for storing and managing transactional data. This data typically includes customer information, order details, product inventory, etc. An OLTP database focuses on speed and efficiency in processing transactions. To achieve this, OLTP databases typically use normalized data structures and have many indexes to support fast query performance. OLTP is designed for transactional tasks such as updates, inserts, and deletes.
OLAP databases, on the other hand, are designed for analytical processing. This data typically includes historical data such as sales figures, customer demographics, etc. An OLAP database focuses on providing quick and easy access to this data for analysis. To achieve this, OLAP databases typically use denormalized data structures and have a smaller number of indexes. OLAP is best suited for analytical tasks such as data mining and reporting.
Redshift is a powerful data warehouse service that uses OLAP capabilities. However, it is not just a simple OLAP data warehouse. Redshift can scale OLAP operations to very large data sets. In addition, Redshift can be used for both real-time analytics and batch processing.
What’s the difference between Redshift and a traditional database warehouse?
A traditional database warehouse is a centralized repository for all your organization’s data. It’s designed to provide easy access to that data for reporting and analysis. A key advantage of a traditional database warehouse is that it’s highly scalable, so it can easily support the needs of large organizations.
Redshift, on the other hand, is a cloud-based data warehouse service from Amazon. It offers many of the same features as a traditional database warehouse but is significantly cheaper and easier to use. Redshift is ideal for businesses looking for a cost-effective way to store and analyze their data.
So, what’s the difference between Redshift and a traditional database warehouse? Here are some of the key points:
Cost
Redshift is much cheaper than a traditional database warehouse. Its pay-as-you-go pricing means you only ever pay for the resources you use, so there’s no need to make a significant upfront investment.
Ease of use
Redshift is much easier to set up and use than a traditional database warehouse. It can be up and running in just a few minutes, and there’s no need for specialized skills or knowledge.
Flexibility
Redshift is much more flexible than a traditional database warehouse. It allows you to quickly scale up or down as your needs change, so you’re never paying for more than you need.
Performance
Redshift offers excellent performance thanks to its columnar data storage and massively parallel processing architecture. It’s able to handle even the most demanding workloads with ease.
Security
Redshift is just as secure as a traditional database warehouse. All data is encrypted at rest and in transit, so you can be sure that your information is safe and secure.
Amazon Redshift is a powerful tool for data analysis. It’s essential to understand what it is and how it can be used to take advantage of its features. Redshift is a type of Relational Database Management System or RDBMS. This makes it different from traditional databases such as MySQL.
While MySQL is great for online transaction processing (OLTP), Redshift is optimized for Online Analytical Processing (OLAP). This means that it’s better suited for analyzing large amounts of data.
What is Amazon Redshift good for?
The benefits of using Redshift include the following:
- Speed
- Ease of use
- Performance
- Scalability
- Security
- Pricing
- Widely adopted
- Ideal for data lakes
- Columnar storage
- Strong AWS ecosystem
What is Amazon Redshift not so good for?
Drawbacks include:
- It is not 100% managed
- Master Node
- Concurrent execution
- Isn’t a multi-cloud solution
- Choice of keys impacts price and performance
So, what is Amazon Redshift?
Amazon Redshift is a petabyte-scale data warehouse service in the cloud. It’s used for data warehousing, analytics, and reporting. Amazon Redshift is built on PostgreSQL 8.0, so it uses SQL dialect called PostgresSQL. You can also use standard SQL to run queries against all of your data without having to load it into separate tools or frameworks.
As it’s an OLAP database, it’s optimized for analytic queries rather than online transaction processing (OLTP) workloads. The benefits of using Amazon Redshift are that you can get started quickly and easily without having to worry about setting up and managing your own data warehouse infrastructure. The drawback is that it can be expensive if you’re not careful with your usage.
It offers many benefits, such as speed, scalability, performance, and security. However, there are also some drawbacks to using Redshift. For example, it is not 100% managed and the choice of keys can impact price and performance. Nevertheless, Redshift is widely adopted and remains a popular choice for businesses looking for an affordable and scalable data warehouse solution.
To optimize your Amazon Redshift deployment and ensure maximum performance, consider leveraging LogicMonitor’s comprehensive monitoring solutions.
Book a demo with LogicMonitor today to gain enhanced visibility and control over your data warehousing environment, enabling you to make informed decisions and maintain peak operational efficiency.% managed and the choice of keys can impact price and performance. Nevertheless, Redshift is widely adopted and remains a popular choice for businesses looking for an affordable and scalable data warehouse solution.
For businesses and organizations that need reliable, secure servers to host data, applications, or services worldwide, Linux is often the platform of choice. Linux is a popular operating system because it is open-source, highly secure, and offers a lot of customization options, making it ideal for both personal and professional use.
Let’s learn what Linux is and some of the reasons why it’s such a popular option for setting up and maintaining servers, from emerging startups all the way to full enterprise deployments.
What is Linux?
Linux is an open-source operating system based on Unix known for its stability, security, and flexibility. It powers various devices, from personal computers and servers to smartphones. The kernel, the core component, manages hardware resources and facilitates software communication. Users can customize and distribute their own versions, called distributions, like Ubuntu and Fedora. Developers and system administrators favor Linux for its powerful command-line interface and extensive programming support.
Whether running dynamically scaled workloads in the cloud, creating private cloud infrastructure, or deploying bullet-proof web servers, Linux’s flexibility, scalability, and security make it an ideal choice. You can use it to build reliable, high-performance web servers or as the foundation for custom application development environments.
Based on UNIX principles, Linux offers efficient multitasking and supports multiple users, groups, and access control lists (ACLs). Popular distributions include Ubuntu, Suse, and Red Hat Enterprise Linux, which provide extensive software libraries and security features.
Why is Linux so popular?
Linux’s popularity is due to its flexibility and cost-effectiveness. Many companies integrate Linux servers into their IT infrastructure across various environments, such as embedded systems, private clouds, and endpoint devices. Its open-source nature allows developers to customize their operating systems without vendor constraints.
Here are 9 reasons why Linux is a popular choice for servers:
1. Open-source nature and customization flexibility
Linux is open-source and free, allowing users to modify and distribute it as needed. Its flexibility and customization make it an ideal choice for server operational environments. For example, developers can access code repositories, modify source code, and build custom kernel versions.
In addition to adapting the kernel to specific needs, developers have access to a wide variety of software packages available with most Linux distributions. These packages can be used to add additional functionality or security features, such as firewalls or intrusion detection systems (IDS). Additionally, many distributions come with tools such as lshw (list hardware) and lspci (list devices), which allow administrators to view detailed information about the hardware and devices connected to the server.
Linux offers great customization and flexibility, allowing users to adapt solutions to their needs. Additionally, users can optimize Linux to enhance system performance for specific applications, ensuring that the system runs efficiently and effectively.
2. Range of applications and tools
Linux has become a popular choice for servers because its wide range of applications and tools allow users to customize and configure their systems to perform virtually any task. Linux is compatible with various hardware architectures and easily integrates numerous applications and services.
Linux is well-known for its compatibility and integration with various hardware and software platforms. This makes it ideal for server use; you can deploy it in almost any environment. It is also possible to install Linux on multiple hardware types, from laptops to the latest servers.
The most common uses for Linux servers include web hosting, database management, file sharing, game servers, and virtualization—all of which require specific software packages or libraries to run correctly. Fortunately, Linux’s open-source nature makes it easy to find the necessary components for any type of application or use case, reducing the need to purchase expensive commercial software.
In addition to its vast array of applications and tools, Linux offers an impressive range of user-friendly features that make it a great choice for administrators who want to manage their server environment easily. For example, administrators can leverage projects like Terraform or Ansible to manage large numbers of Linux servers or VMs all at once. Rather than logging in to each system and configuring them individually, the Linux ecosystem makes it easy to deploy and configure environments through repeatable, automated actions.
3. Enhanced security
Built from the ground up with security in mind, Linux has numerous features that make it difficult to breach. A critical security feature is access control capability, which allows admins to set permissions and restrictions on user accounts and files. For example, administrators can set read-only or write-only access rights for users to prevent unauthorized programs from executing on their servers.
Additionally, Linux supports multiple authentication methods, such as username/password combinations, smart cards, biometrics, and digital certificates. These methods provide an extra layer of protection by verifying each user’s identity before granting access to data and resources.
The open-source nature of Linux means that anyone can find, report, or fix a security issue. This is in major contrast to proprietary systems like Windows, where you’re mostly at the vendor’s mercy to identify and fix bugs before hackers find them and use them maliciously.
Linux source code is public, meaning anyone can check their developers’ work to see if they left a door open for hackers. Because of this, Linux is generally seen as more secure than Windows and other proprietary operating systems.
Linux stands out for its lower number of security vulnerabilities than other operating systems, making it a preferred choice for many users and organizations seeking a robust and reliable platform. The Linux community and developers are also dedicated to maintaining a secure environment by providing frequent updates and patches. These regular security updates ensure that any emerging threats are quickly addressed, protecting and securing the system.
4. High stability and reliability
Due to its outstanding reliability, Linux can run for extended periods without needing reboots, making it a popular choice for server operating systems. It’s also incredibly secure and stable, making it well-suited for mission-critical tasks. Linux’s robust open-source codebase and highly active development community mean bugs can quickly be identified and patched. Additionally, many available packages make tools easily accessible to complete the tasks at hand.
Long-term support (LTS) versions of Linux distributions allow users to upgrade reliably without worrying about compatibility issues. Many companies provide dedicated LTS versions explicitly designed for use as servers, with guaranteed support and security updates for up to five years or more.
Linux efficiently manages resources, providing stable and consistent performance. Its robust design ensures system resources are utilized optimally, resulting in reliable and smooth operation even under demanding conditions. This consistent performance makes Linux an ideal choice for both servers and desktop environments.
5. Community support and resources
Linux is widely used as a server operating system due to its robust community support and resources. Support includes user forums, online knowledge bases, live chat help desks, and detailed tutorials.
Linux users benefit from the abundance of dedicated forums. They are filled with experienced professionals eager to help those having trouble with setup or have questions regarding configuration options. Many forums offer personalized advice and general information on topics ranging from hardware compatibility to troubleshooting common issues. Community-driven development ensures that Linux receives regular updates and new features, enhancing functionality and security.
6. Cost-effectiveness compared to proprietary software
You can use Linux to run mission-critical applications while still being affordable. In most cases, you can save money on licensing fees because Linux requires fewer resources than other operating systems. Linux is cheaper because there are no license fees unless you’re paying for RHEL or Oracle. However, it’s important to note that it can require more advanced years than other licensed and supported operating systems.
Linux offers a lower total cost of ownership due to reduced software and support costs over time. Its open-source nature eliminates the need for expensive licensing fees, and the robust support from the Linux community minimizes the need for costly external support services.
7. Scalability for handling large amounts of data and traffic
Linux is highly scalable, making it an ideal platform for servers that handle large amounts of data and traffic. It can run hundreds of services simultaneously and can be configured to provide elastic responses that match the user’s demand. This scalability extends to more than hardware—Linux can scale across multiple systems for added efficiency and flexibility. It offers advanced features like virtualization and fault tolerance to ensure business continuity.
Scaling Linux is easy and seamless. It runs exceptionally well on both physical and virtual machines and can easily handle large loads while maintaining availability and uptime. This makes it ideal for applications that require reliability, such as web hosting and database management.
Linux also offers cutting-edge features for developers, like the eBPF virtual machine and io_uring, which allow developers to track kernel events and perform I/O operations more efficiently. Linux’s stability makes it perfectly suited for mission-critical applications when reliability is crucial. Many users rely on eBPF and robust “user mode” protections to ensure errors or failures don’t affect the entire system. Containers and VMs also exist to further isolate what the kernel and userspace cannot isolate.
8. Compatibility with modern DevOps practices and configuration management
Linux is an important part of modern DevOps practices. Many businesses use it to streamline their software development and deployment processes. With containerization technologies like Docker and orchestration tools like Kubernetes, Linux provides a platform for these tools to operate efficiently. Its lightweight and modular architecture allows for continuous integration/continuous deployment (CI/CD) pipelines, enabling rapid development cycles and more efficient management of infrastructure as code (IaC).
Linux’s high compatibility with configuration management tools such as Ansible, Puppet, Chef, and SaltStack ensures efficient and scalable infrastructure management. These tools allow administrators to automate server provisioning, configuration, and management, creating consistency and reducing the potential for human error.
For instance, Ansible uses simple YAML files to describe automation jobs, which you can execute on any Linux machine without requiring a special agent. Puppet provides a more comprehensive framework with a declarative language that allows administrators to define the desired state of their infrastructure.
9. Support for visualization
Linux excels in virtualization, offering various tools and technologies to create and manage virtual environments. Virtualization allows multiple operating systems to run on a single physical machine, optimizing resource utilization and reducing hardware costs. Tools like KVM (Kernel-based Virtual Machine), QEMU, and Xen enable the creation of virtual machines (VMs) with high performance and security.
Linux’s built-in support for these virtualization technologies ensures efficient resource allocation and management, making it a preferred choice for hosting multiple servers on a single physical host. Additionally, Linux containers (LXC) and containerization platforms like Docker offer lightweight alternatives to traditional VMs, providing isolated environments for applications with minimal overhead. This versatility in virtualization supports diverse use cases, from development and testing to production workloads, making Linux an ideal choice for scalable and cost-effective server solutions.
Conclusion
Linux has grown incredibly popular, as evidenced by its widespread use in web hosting services, cloud computing solutions, home routers, IoT devices, TVs, cars, refrigerators, and anything else with a computer that isn’t a Windows or Mac desktop or laptop. Its lightweight design enables it to consume fewer resources while providing powerful performance levels, which are ideal for server tasks like database management or application hosting.
If you’re considering using Linux for your servers, these seven reasons provide a great starting point to help you decide if it’s right for your business. From security and stability to flexibility and affordability, there are many compelling reasons to give Linux a try.
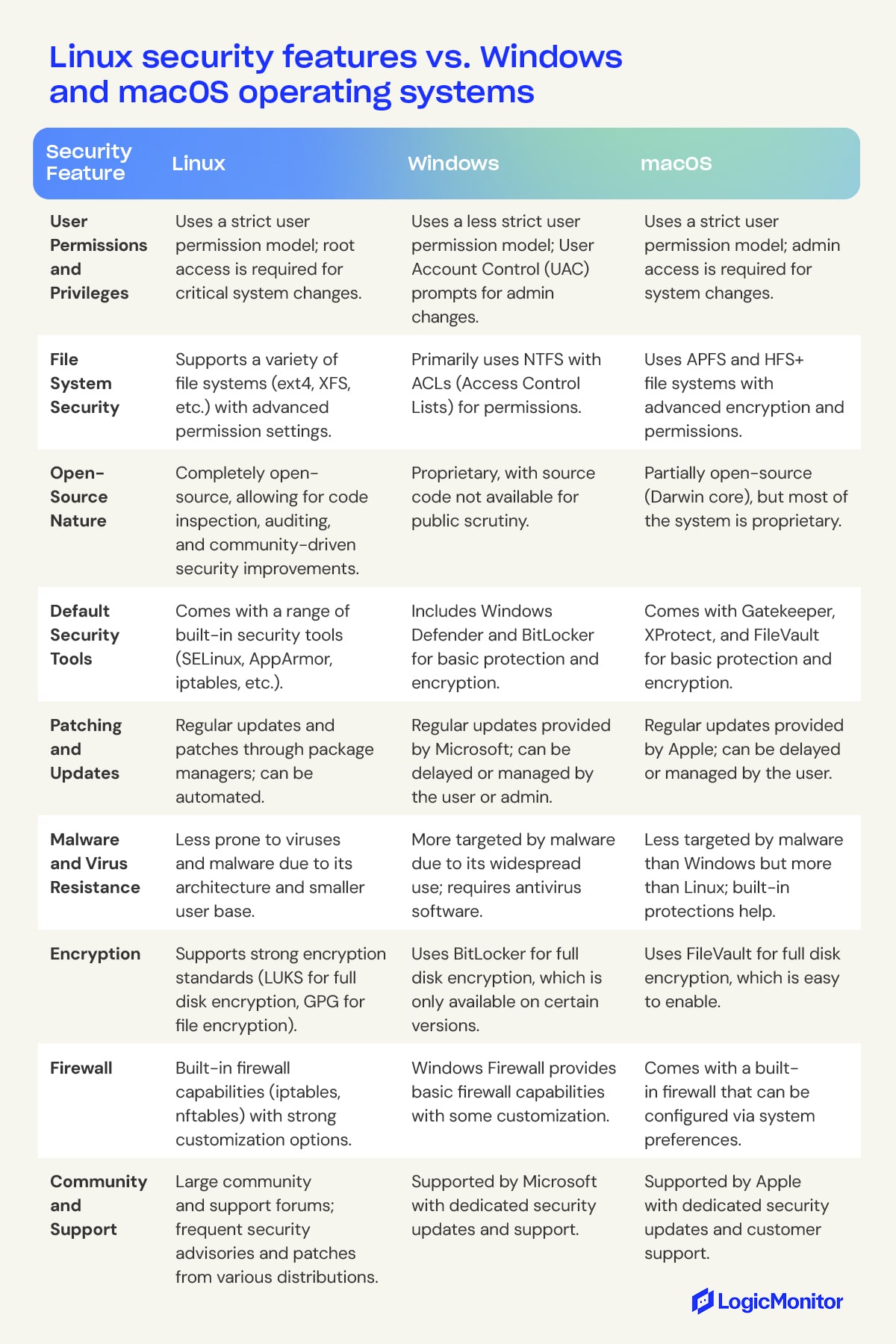
Security features comparison chart
Linux FAQs
How much control do users have over their Linux systems?
Linux gives users a lot of control over their systems. Users can choose how their Linux system looks and works, from the desktop environment to the core system settings. They can also customize security settings, install the software they want, and tweak the system’s performance. Unlike other operating systems with restrictions, Linux lets users manage and modify their systems as they see fit. This flexibility is beneficial for advanced users and IT professionals who need a high level of customization.
How do I troubleshoot and fix boot issues in Linux?
Various factors, such as corrupted boot loader configurations or faulty hardware, can cause boot issues in Linux. Common steps to troubleshoot boot issues include checking the boot loader configuration file (such as GRUB), running filesystem checks using commands like fsck, and examining system logs located in the /var/log directory for errors.
How do I handle file permission and ownership issues in Linux?
File permission and ownership issues can lead to access problems. To troubleshoot, use the ls -l command to check the current permissions and ownership of files and directories. Modify permissions with chmod and change ownership with chown. Ensure that users and groups have access rights to the required files appropriately.
What should I do if my Linux server is running out of memory?
If your Linux server is running out of memory, you can troubleshoot by identifying memory-intensive processes using commands like top, htop, or free. Check for memory leaks or misconfigured applications that consume excessive memory. The Out-Of-Memory (OOM) killer may also come into play, terminating processes to free up memory. Additionally, optimizing your system by adjusting swap space and configuring memory limits for applications can help. Monitoring tools like vmstat and sar provide insights into memory usage patterns. Start monitoring your Linux systems with LogicMonitor and gain valuable insights into their performance.
Contact us today and see how our comprehensive platform can help you optimize your Linux environment. Don’t miss out on this opportunity to take control of your IT operations and stay ahead of the competition with LogicMonitor!
Apache Tomcat, developed by Sun Systems in the late 1990s, is a popular choice for developers who need to build and deploy Java-based web applications. It’s a collaborative platform that, since 2005, has become an accredited top-level Apache project, with highly experienced developers volunteering support and resources for it.
A 2022 survey shows that 48% of developers now utilize Apache Tomcat for deploying Java web applications. But what is the Apache Tomcat server, and how does it work?
What is Apache Tomcat?
Apache Tomcat is a free, open-source Java servlet container. It hosts Java-based web applications, implementing Java Servlet and JavaServer Pages (JSP) specifications. Tomcat provides a robust and scalable environment for dynamic web content, managing Java servlets to process requests and generate responses efficiently.
Servlet containers like Tomcat provide a runtime environment for Java servlets, which extend web server functionality by generating dynamic content and handling web requests. They manage the lifecycle of servlets, ensuring smooth operation by loading and unloading them as needed.
Java servlet containers may be combined with other web servers to provide a more complete runtime environment for deploying Java-based web applications. Apache Tomcat also provides additional services such as security and resource management.
Is Apache Tomcat a web server or an application server? In truth, it’s neither. Web servers deliver static content, such as a home page, an image, or a video. Application servers, conversely, deliver dynamic content, such as personalization of web pages and interactive chat options. Apache Tomcat behaves like an application server because it can deliver highly dynamic content. It can also behave like a standalone web server, but it is actually a Java servlet container. As such, it does not have the features of a full application server and may not support some enterprise-level requirements.
The latest release of Apache Tomcat server is 10.1.25, which was launched on the 14th of June, 2024.
Core Apache Tomcat components
Catalina
The primary component of Apache Tomcat is the servlet container, Catalina. Catalina implements the required specifications for Java servlets and Jakarta Server Pages (JSP, formerly JavaServer Pages) and manages the lifecycle of all the servlets in the container.
Coyote
Coyote is a connector component that supports the HTTP/1.1 protocol. Coyote interprets and processes HTTP requests via processing threads and can create additional threads if traffic increases unexpectedly. The ability to handle requests in this way is what gives Apache Tomcat the ability to be used as a standalone web server.
Jasper 2
Servers need a JSP engine to be JSP compatible. The Apache Tomcat server’s JSP engine is called Jasper 2. It replaces the original Jasper, which was slower and had fewer features. This engine works solely to implement JSP specifications.
Clusters
Another important component in Apache Tomcat server architecture is the cluster. Clusters are groups of Tomcat servers that operate in tandem, creating a single system via careful load balancing to connect servers successfully. Clustering can improve a system’s availability and boost its resilience.
Apache Tomcat request handling

How does Apache Tomcat work?
Now that you know the basic components of Apache Tomcat, let’s take a look at how the server actually works. There are six primary steps in the lifecycle of an HTTP request to Tomcat.
- A client inputs an HTTP request
- This request goes to a web server
- The server forwards this request to the Apache Tomcat container
- The container and relevant connectors decide how to process the request
- The container generates an appropriate response
- The response goes back to the client via the web server
The configuration for how the servlet container responds to requests is held in the server.xml file. Java servlets initialize and execute JSP files if required, and the JSP engine, Jasper, executes the relevant Java code to create the response. The connector, Coyote, sends that response back, allowing the client’s web browser to fully resolve the request.
The end-user experience should be to enter a web address or click a button on a web page and, within a few seconds, get a result that matches their request.
Advantages of using Apache Tomcat
Increased observability
There are numerous advantages to using Apache Tomcat beyond the ability to create a runtime environment for Java web applications and websites. Apache Tomcat tracks all requests and increases observability across systems, although investing in Tomcat monitoring tools is essential for businesses that want to ensure they avoid bottlenecks and latency.
Security features
Tomcat also provides security features, including additional authentication stages and access controls that can be implemented by an administrator. This makes it ideal for organizations that have to be compliant with high standards.
Lightweight and fast
Tomcat is incredibly lightweight and fast. It’s focused on efficiency, so it doesn’t drain network resources. It can start up and shut down fast without impacting other network components.
Customization options
Apache Tomcat server provides several configuration options that allow developers to customize the behavior of the servlet container and associated web applications. Thanks to numerous plugins and modules, developers can use Tomcat however they want and extend its practicability almost indefinitely.
Compatibility
Because Tomcat was developed to implement JSP and Java APIs, it’s compatible with all Java technologies or their Jakarta equivalents. WebSockets, Expression Language, and, of course, Java (or Jakarta) servlets all integrate seamlessly with Tomcat.
Integration with other technologies
Tomcat’s capabilities extend beyond Java technologies to seamlessly integrate with various tools and frameworks, such as:
- Java frameworks: Tomcat integrates smoothly with Java frameworks like Spring and Hibernate, enabling developers to build robust, scalable applications.
- DevOps tools: Tomcat works well with DevOps tools like Jenkins and Docker. Jenkins automates CI/CD pipelines, while Docker facilitates containerization for easier deployment.
- Cloud services: Tomcat integrates with AWS, Azure, and Google Cloud, offering scalable and flexible deployment options.
- Load balancers: Tomcat supports load balancers like Nginx and Apache HTTP Server, ensuring high availability and better performance.
- Monitoring tools: Tomcat can be monitored using tools like LogicMonitor, Nagios, and New Relic, which provide insights into server performance and health.
Open-source and free
One of the biggest advantages for most development teams is that Apache Tomcat is completely open-source and free. There is no charge, ever, for utilizing this platform, and it’s entirely maintained and updated by volunteers. The community surrounding Tomcat is enormous, and so much support is available online for developers utilizing its features.
Disadvantages of using Apache Tomcat
Are there disadvantages to using Apache Tomcat? There can be, depending on your needs.
Limited enterprise-level features
As we mentioned earlier, Tomcat is not a full-featured web server or application server, although it can fulfill many of the same tasks.
Lack of support for EJBs
It doesn’t support some enterprise-level features, such as EJBs (Jakarta Enterprise Beans, formerly Enterprise Java Beans). This can be a significant limitation for organizations that rely on EJBs for developing robust, scalable, and transactional enterprise applications.
Limited Java API support
Tomcat also lacks support for some Java APIs. For comprehensive functionality, developers often need these APIs to handle more complex tasks, which Tomcat alone cannot manage.
Need for full application server
For this level of functionality, developers require a full application server such as RedHat JBoss or Oracle WebLogic. These servers provide the extensive features and support needed for large-scale enterprise applications, which Tomcat alone cannot offer.
Primary Apache Tomcat use cases
Apache Tomcat is one of the most widely utilized platforms for website and web application deployment. One app developer noted that Tomcat helped them reduce their server startup time by 11 seconds per instance compared to alternatives. They also stated that Tomcat helped keep their apps compliant and bug-free without resorting to manual code entry.
E-commerce
Tomcat also helps e-commerce businesses scale rapidly, one example is Walmart. Apache Tomcat empowers the retailer to handle thousands of transactions daily while providing robust, excellent online experiences for their website visitors.
Finance
In the financial industry, Tomcat’s security features and performance capabilities are essential. Banks and financial institutions rely on Tomcat for secure and reliable web application deployment, guaranteeing compliance with stringent regulatory requirements and handling their high volumes of transactions with comfort.
Media and entertainment
Businesses looking to streamline their budget might consider Tomcat instead of a proprietary, chargeable server option. Media companies benefit from Tomcat’s ability to manage high traffic and provide fast, reliable service to users. Weather.com switched to Tomcat and found it could scale up the amount of web traffic it could handle, plus it saved thousands of dollars by making this change.
Development environments
Tomcat is the ideal choice for development environments that already utilize multiple Java-based technologies. The ease of integration can be a big time saver for busy DevOps teams. Switching to Tomcat is as simple as installing the servlet container and copying over any application files into the container’s directory.
Is Apache Tomcat going to be used into the future?
Apache Tomcat server is the go-to servlet container for Java web applications — with good reason. Its lightweight yet robust functionality and ease of configuration make it fast to learn and deploy on your own systems. The sheer volume of support available continues to grow as more developers adopt Tomcat as a major aspect of their app deployment strategies.
It’s safe to say that while Java remains a popular choice for developers, Apache Tomcat will continue to be a top choice for creating runtime environments for Java web applications.
When it comes to tackling big data, three superior technologies stand out: Apache Kafka, Apache Spark, and Apache Hadoop. Each of these solutions offers distinct advantages and weaknesses. Understanding their differences is vital in choosing which technology best fits your project’s needs.
Understanding Kafka
Apache Kafka is a reliable, open-source distributed streaming platform that creates real-time data pipelines and applications. Due to its exceptional scalability, high throughput capabilities, and low latency processing speed, this powerful technology has become the go-to standard for large-scale messaging systems utilized by some of the biggest tech companies in the world, such as Amazon, Netflix, and Uber.
“Kafka’s real-time data streaming transforms how businesses handle large-scale messaging, ensuring instant insights and seamless operations.”
Use cases
Kafka is used for a variety of use cases, including:
- Streamlining massive data streams from numerous providers and real-time data pipelines, enabling immediate access to vital insights
- Aggregating and analyzing logs from web servers, databases, Internet of Things (IoT) devices, and more, enabling IT professionals to have a better understanding of their systems
- Fabricating real-time streaming applications, such as those pertaining to fraud recognition and peculiarity identification
Advantages
Kafka provides many advantages compared to traditional messaging systems:
- High throughput and scalability: Kafka is an incredibly powerful tool that allows for the processing of millions of messages per second with a cluster spanning thousands of brokers.
- Low latency: Kafka guarantees instant message delivery.
- Fault tolerance: Kafka is designed to be reliable, with automated replication and failover capabilities that ensure its uninterrupted operation.
Challenges
Although Kafta provides many advantages, there are some challenges:
- Managing offsets: Tracking message offsets to ensure data consistency can be complex, especially with multiple consumers.
- Handling large volumes: While Kafka is designed for high throughput, managing and scaling large data streams requires careful planning and resource allocation.
- Complex configuration: Setting up and configuring Kafka to optimize performance and ensure fault tolerance involves significant expertise and effort.
Real-world examples
Many businesses are utilizing Kafta to streamline their processes, including:
- Netflix uses Kafka for messaging and data processing in real-time. Through Kafka’s robust and durable messaging system, Netflix’s microservices can efficiently communicate with each other.
- Uber’s tech stack includes Kafta, which processes trillions of messages and acts as the foundation for batch and real-time systems.
Understanding Spark
Apache Spark is an open-source distributed processing framework that processes large data sets at lightning speed. Featuring an optimized engine for in-memory computation, it dramatically reduces the time needed to analyze real-time or streaming data by creating direct access points known as Resilient Distributed Datasets (RDDs).
Use cases
Apache Spark can be used in a variety of situations, including:
- Streaming data: Spark can rapidly process streaming data from sources such as weblogs, sensors, social media feeds, etc.
- Extract, Transform, Load (ETL): Apache Spark is often used in larger ETL pipelines. It can read and transform data from multiple sources into formats suitable for downstream analytics.
- Data enrichment: Spark can quickly enrich records with external data sources such as address databases or customer segmentation databases.
Advantages
Spark offers several advantages over other distributed processing frameworks:
- It’s one of the most advanced analytics solutions on the market. This opens up a world of possibilities for data analysis, from machine learning models and real-time predictive analytics to interactive visualizations and data mining techniques.
- Spark’s dynamic nature allows you to tailor its use case according to your specific needs and requirements, making it an essential component of any modern analytics stack.
- In addition, Spark’s impressive speed enables efficient processing of large datasets in a fraction of the time required by traditional MapReduce systems, providing insights quickly and cost-effectively.
Challenges
Like any platform, Spark also has challenges to deal with:
- Memory management: Spark’s in-memory processing requires substantial memory resources, which can be challenging to manage, especially with large datasets.
- Resource allocation: Efficiently allocating resources in a cluster environment to avoid performance bottlenecks can be complex.
- Cluster management: Managing a Spark cluster involves monitoring resource usage and performance tuning to ensure optimal operation.
Real-world examples
Spark is popular with numerous organizations around the world, including:
- Alibaba uses Spark to analyze hundreds of petabytes of data to improve its recommendation systems.
- NASA has used Spark to develop its high-performance big data analytics framework, Earth Data Analytic Services (EDAS).
Understanding Hadoop
Apache Hadoop is a powerful, open-source framework that makes it simple to store and effectively manage vast amounts of data. It enables distributed processing of large data sets across clusters of computers using simple programming models, providing scalability up to petabytes of data. By utilizing a clustered environment, it allows for faster analysis and improved efficiency when compared to traditional single-node architectures.
Use cases
Hadoop is widely used in many industries for a variety of applications:
- In security and law enforcement, Hadoop can be used to analyze large volumes of data, such as surveillance imagery or recorded conversations, in order to detect patterns or anomalies.
- In customer requirements understanding, Hadoop can enable companies to gain insights into the wants and needs of their customers by analyzing historical purchase data.
- For cities and countries, Hadoop can help improve infrastructure planning and development by providing a better understanding of population distributions, traffic flows, and other key metrics.
Advantages
When compared to traditional storage and processing infrastructures, Hadoop offers a variety of advantages that make it the perfect choice for data-driven businesses:
- Cost-effectiveness is one of the main benefits of utilizing Hadoop, as it removes the need for pricey equipment investments to store and manage large datasets.
- Furthermore, Hadoop’s horizontal scalability across multiple nodes is unrivaled, offering unparalleled flexibility and potential for growth.
- Given its distributed nature, Hadoop provides faster performance with less downtime due to its fault tolerance capabilities.
Challenges
To gain the many advantages, Hadoop has a few potential challenges to overcome:
- Complex setup: Setting up a Hadoop cluster involves configuring numerous components (HDFS, MapReduce, YARN), which can be time-consuming and require specialized knowledge.
- Maintenance: Maintaining a Hadoop cluster requires ongoing management to handle data replication, job scheduling, and fault tolerance.
- Resource intensive: Hadoop’s distributed framework is resource-intensive, necessitating substantial hardware and network infrastructure to achieve optimal performance.
Real-world examples
Hadoop has been adopted by many well-known businesses, including:
- Bank of America has utilized Hadoop to manage and analyze the mass amounts of data it generates from customers and transactions.
- LinkedIn uses Hadoop for batch processing to store and process all member activity data. This can then be used to provide insights and better personalized content recommendations.
Comparison of Kafka vs. Spark vs. Hadoop
Kafka and Spark are both stream-processing frameworks designed to process data in real time. They share many features, such as fault tolerance, scalability, high throughput/low latency message delivery, automatic offset management, and integration with multiple languages.
However, there are some key differences between them. Kafka focuses on messaging (publishing/subscribing), while Spark focuses more on data processing with support for batch processing and SQL queries. Kafka is designed to process data from multiple sources, whereas Spark is designed to process data from only one source.
Hadoop, on the other hand, is a distributed framework that can store and process large amounts of data across clusters of commodity hardware. It provides support for batch processing and SQL queries but lacks the real-time processing capabilities provided by Kafka and Spark.
In terms of use cases, Kafka can be used for building distributed streaming applications that rely on message queues, such as event logging systems, monitoring and alerting services, etc. Spark can be used for building real-time streaming applications that process data in near real time, such as financial fraud detection and clickstream analysis. Hadoop can be used for batch processing of large datasets that are not suitable for real-time processing, such as log analysis or business intelligence.
Choosing the right tool for different scenarios
When choosing between Kafka vs. Spark vs. Hadoop, it is important to consider the specific needs of your application. If you need the power to process streams in real time, then Kafka or Spark will be your best bet. Big data processing is much more consistent with Hadoop’s batch mode capabilities. And if SQL queries are necessary along with streaming and/or batch options, then Spark should be your go-to choice.
Each of the three technologies has unique strengths and weaknesses, so consider your development requirements before adding the next technology to your tech stack.
To help you make an informed decision, here are the key differences between these powerful data processing platforms:
Kafka vs Spark
Kafka and Spark are leading data processing platforms with distinct purposes. Kafka excels in real-time data streaming, enabling multiple client applications to publish and subscribe to real-time data with high scalability and low latency. Spark, on the other hand, specializes in large-scale data processing, efficiently handling big data through batch processing and in-memory computation for rapid analytics.
Hadoop vs Kafka
Hadoop and Kafka are robust data platforms designed for different purposes. Hadoop is optimized for batch processing and large-scale data storage, leveraging a distributed framework to manage vast datasets. Kafka, on the other hand, excels in real-time data streaming, enabling multiple client applications to publish and subscribe to real-time data with high scalability and low latency.
Spark vs Hadoop
Hadoop and Spark are powerful data processing frameworks with distinct strengths. Hadoop excels in batch processing and large-scale data storage, using a distributed framework to handle extensive datasets efficiently. Spark, on the other hand, specializes in in-memory data processing, providing fast analytics and real-time data processing capabilities.
Whether you need real-time data streaming, fast in-memory processing, or scalable batch processing, understanding the advantages and challenges of Kafka, Spark, and Hadoop will help you make the best decision for your organization.
Don’t hesitate to reach out to our experts at LogicMonitor to ensure you leverage the most suitable technology for your needs.
Modern businesses are constantly looking for more efficiency and better performance in their daily operations. This is why embracing cloud computing has become necessary for many businesses. However, while there are numerous benefits to utilizing cloud technology, obstacles can get in the way.
Managing a cloud environment can quickly overwhelm organizations with new complexities. Internal teams need to invest substantial time and effort in regularly checking and monitoring cloud services, identifying and resolving issues, and ensuring optimal system performance.
This is where the power of serverless computing becomes evident. By using platforms like Amazon Web Services (AWS) Lambda, businesses can free themselves from worrying about the technical aspects of their cloud applications. This allows them to prioritize the excellence of their products and ensure a seamless experience for their customers without any unnecessary distractions.
What is Serverless Computing, and Why is it Important?
Serverless computing is an innovative cloud computing execution model that relieves developers from the burden of server management. This doesn’t mean that there are no servers involved. Rather, the server and infrastructure responsibilities are shifted from the developer to the cloud provider. Developers can focus solely on writing code while the cloud provider automatically scales the application, allocates resources, and manages server infrastructure.
The Importance of Serverless Computing
So why is serverless computing gaining such traction? Here are a few reasons:
- Focus on Core Product: Serverless computing allows developers to concentrate on their main product instead of managing and operating servers or runtimes in the cloud or on-premises. This can lead to more efficient coding, faster time to market, and better use of resources.
- Cost-Effective: With serverless computing, you only pay for the computing time you consume. There is no charge when your code is not running. This can result in significant cost savings compared to the traditional model of reserving a fixed amount of bandwidth or number of servers.
- Scalability: Serverless computing is designed to scale automatically. The system accommodates larger loads by simply running the function on multiple instances. This means businesses can grow and adapt quickly to changes without worrying about capacity planning.
- Reduced Latency: Serverless computing can reduce latency by allowing you to run code closer to the end user. You don’t have to send requests to a home server; instead, you can deploy functions in multiple geographic locations.
What is AWS Lambda?
Lambda is a serverless computing service that allows developers to run their code without having to provision or manage servers.
The service operates based on event-driven programming, executing functions in response to specific events. These events can range from changes in data within AWS services, updates from DynamoDB tables, and custom events from applications to HTTP requests from APIs.
AWS Lambda’s key features include:
- Autoscaling: AWS Lambda automatically scales your functions in response to the workload.
- Versioning and Aliasing: You can deploy different versions of your functions and use aliases for production, staging, and testing.
- Security: AWS Lambda ensures your code is always secure and encrypted.
How Does AWS Lambda Work?
AWS Lambda operates on an event-driven model. Essentially, developers write code for a Lambda function, which is a self-contained piece of logic, and then set up specific events to trigger the execution of that function.
The events that can trigger a Lambda function are incredibly diverse. They can be anything from a user clicking on a website, a change in data within an AWS S3 bucket, or updates from a DynamoDB table to an HTTP request from a mobile app using Amazon API Gateway. AWS Lambda can also poll resources in other services that do not inherently generate events.
When one of these triggering events occurs, AWS Lambda executes the function. Each function includes your runtime specifications (like Node.js or Python), the function code, and any associated dependencies. The code runs in a stateless compute container that AWS Lambda itself completely manages. This means that AWS Lambda takes care of all the capacity, scaling, patching, and administration of the infrastructure, allowing developers to focus solely on their code.
Lambda functions are stateless, with no affinity to the underlying infrastructure. This enables AWS Lambda to rapidly launch as many copies of the function as needed to scale to the rate of incoming events.
After the execution of the function, AWS Lambda automatically monitors metrics through Amazon CloudWatch. It provides real-time metrics such as total requests, error rates, and function-level concurrency usage, enabling you to track the health of your Lambda functions.
AWS Lambda’s Role in Serverless Architecture
AWS Lambda plays a pivotal role in serverless architecture. This architecture model has transformed how developers build and run applications, largely due to services like AWS Lambda.
Serverless architecture refers to applications that significantly depend on third-party services (known as Backend as a Service or “BaaS”) or on custom code that’s run in ephemeral containers (Function as a Service or “FaaS”). AWS Lambda falls into the latter category.
AWS Lambda eliminates the need for developers to manage servers in a serverless architecture. Instead, developers can focus on writing code while AWS handles all the underlying infrastructure.
One of the key benefits of AWS Lambda in serverless architecture is automatic scaling. AWS Lambda can handle a few requests per day to thousands per second. It automatically scales the application in response to the incoming request traffic, relieving the developer from the task of capacity planning.
Another benefit is cost efficiency. With AWS Lambda, you are only billed for your computing time. There is no charge when your code isn’t running. This contrasts with traditional cloud models, where you pay for provisioned capacity, whether or not you utilize it.
What is AWS CloudWatch
CloudWatch is a monitoring and observability service available through AWS. It is designed to provide comprehensive visibility into your applications, systems, and services that run on AWS and on-premises servers.
CloudWatch consolidates logs, metrics, and events to provide a comprehensive overview of your AWS resources, applications, and services. With this unified view, you can seamlessly monitor and respond to environmental changes, ultimately enhancing system-wide performance and optimizing resources.
A key feature of CloudWatch is its ability to set high-resolution alarms, query log data, and take automated actions, all within the same console. This means you can gain system-wide visibility into resource utilization, application performance, and operational health, enabling you to react promptly to keep your applications running smoothly.
How Lambda and CloudWatch Work Together
AWS Lambda and CloudWatch work closely to provide visibility into your functions’ performance.
CloudWatch offers valuable insights into the performance of your functions, including execution frequency, request latency, error rates, memory usage, throttling occurrences, and other essential metrics. It allows you to create dynamic dashboards that display these metrics over time and trigger alarms when specific thresholds are exceeded.
AWS Lambda also writes log information into CloudWatch Logs, providing visibility into the execution of your functions. These logs are stored and monitored independently from the underlying infrastructure, so you can access them even if a function fails or is terminated. This simplifies debugging.
By combining the power of CloudWatch with AWS Lambda, developers can gain comprehensive visibility into their serverless application’s performance and quickly identify and respond to any issues that may arise.
A Better Way to Monitor Lambda
While CloudWatch is a useful tool for monitoring Lambda functions, it can sometimes lack in-depth insights and contextual information, which can hinder troubleshooting efficiency.
LogicMonitor is an advanced monitoring platform that integrates with your AWS services. It provides a detailed analysis of the performance of your Lambda functions. With its ability to monitor and manage various IT infrastructures, LogicMonitor ensures a seamless user experience, overseeing servers, storage, networks, and applications without requiring your direct involvement.
So whether you’re using Lambda functions to power a serverless application or as part of your overall IT infrastructure, LogicMonitor can provide comprehensive monitoring for all your cloud services and give you the extra detail you need to maximize performance and optimize your cost savings.
Automation has been a bit of a buzzword in the IT community in the last few years. Companies around the world are looking for ways to scale and automate routine tasks so they can focus on more strategic initiatives. But “automation” is a word that can cover a lot of workflows and can mean something different to every team.
What do we mean when we talk about automation here at LogicMonitor?
Generally, I like to divide LogicMonitor’s automation capabilities into a few different buckets: we use it for provisioning, workflow orchestration, and event-driven automation. In this blog, we’ll take a look at what tools we have available at LogicMonitor to support each category and where you can start introducing automation into your environment.
Resource provisioning with Hashicorp Terraform
The first step in any automation journey is automating infrastructure creation. Usually this is done by adopting a practice known as Infrastructure as Code (IaC). IaC has been around for years. It is a methodology that essentially creates something like a recipe for your infrastructure. IaC helps you set the definitions as a file for whatever you are trying to deploy, making it repeatable, version-able, and shareable. It establishes the file and avoids human error by creating infrastructure exactly the way you want it, when you want it. It is fast, low risk (because it can be peer reviewed), and allows teams to focus on other, more interesting tasks.
LogicMonitor has native support for two IaC tools out of the box: Redhat Ansible and Hashicorp Terraform. Both of these collections were initially created by our internal team for monitoring our own environment. But now it is, and will continue to be, an open source offering from LogicMonitor at no extra cost to our customers. These collections are now maintained, fully supported, and will continue to be updated by our teams. First, let’s discuss Hashicorp Terraform.
Hashicorp Terraform
LogicMonitor’s Terraform collection is intended to be used during resource provisioning. As folks use Terraform to create their infrastructure, we want to make it easy to add the new resources to LogicMonitor so they are monitored from the beginning. We wanted the experience to be repeatable. For example, if you are a MSP onboarding a new customer, why not use Terraform to replicate the onboarding experience for all of your customers? For enterprises, as teams grow and as your business scales, using Terraform will save you time and money and simplify your team’s ability to monitor resources in LogicMonitor.
Our Terraform Provider has a strong emphasis on resource and device provisioning, and we are constantly updating it. Last year, we added AWS account onboarding, and we recently started adding support for Azure cloud account onboarding.
Managing resources with Redhat Ansible
Now that the resources are provisioned, how are you going to manage them? Routine maintenance is a large part of our IT lives, from keeping things up to date at a scheduled maintenance pace, to troubleshooting on the fly to help diagnose common problems.
We use Ansible here at LogicMonitor for a lot of our workflow orchestration work. As maintenance or upgrades happen, why not communicate to your monitoring platform that work is being done? Schedule downtime with LogicMonitor as part of your Ansible playbook using our LogicMonitor Module. Maybe as part of your remediation playbooks you want to modify a collector group or get information from any of your monitored objects. That is all possible with our certified collection.
Onboarding new customers or setting up a new section of your LogicMonitor environment? We make all of that easy with our Ansible modules, allowing you to create alert rules, escalation chains, and device groups. If you use Ansible in your environment to deploy new infrastructure, our Ansible collection will also give you the opportunity to add these new devices to LogicMonitor for day-one monitoring.
We are always updating and enhancing these collections. If there is something that you would like to see added to these collections, please reach out and file a feedback ticket. We want to understand how you are using our collections today and how you want to use them in the future!
Event-driven automation with Stackstorm
This is the most exciting frontier of our automation journey here at LogicMonitor. This type of automation has a few names that you may have heard of: event-driven or alert-driven automation, “if this, then that” (IFTT) automation, or a self-healing enterprise. The fundamental idea behind this type of automation is that an automated action is taken based off of an event that has occurred. In the case of LogicMonitor, it would mean an alert is generated, triggering another action. The alert details are processed following a set of rules, and an automation is triggered to remediate the cause of the alert.
Imagine the following scenario: You have a windows server that is running out of disk space, and you’re getting alerts about an almost full disk. Traditionally, a tech would see the alert in LogicMonitor (or it would be routed via one of our integrations to a ticketing system), the tech would examine the alert and gather the appropriate information from LogicMonitor (what device is having the issue), VPN into the internal network, and open a remote session with the server. Maybe the tech has a playbook they call to clear common temp files, maybe it is a script, or maybe the tech has to manually do it. The tech finds the files and deletes them, logs out of the system, updating the ticket or worklog, and confirms the alert. In its entirety, this process, though a relatively simple task, takes significant time and resources.
Now imagine the above scenario happened at 1 A.M., routing to an on-call engineer, waking them up. Time is precious, so why not automate these simpler tasks and allow the tech to focus on things that they find interesting or challenging (or let them sleep as low effort, on-call alerts are resolved on their own)?
With event-driven automation, when simple alerts occur, an automation tool processes the alert payload and matches it against a set of rules and triggers that playbook to clear those temp files and resolve the alert.
Our primary offering into event-driven automation is with Stackstorm, an open source event-driven automation tool that is sponsored by the Linux Foundation. The Stackstorm Exchange allows a level of plug-and-play within your environment to not only receive or act within LogicMonitor but to take action in any other environments you may have. Stackstorm has a very robust engine and can handle any type of workflow, whether a simple task or a complicated upgrade plan.
Looking ahead with Event-Driven Ansible
Our Ansible and Terraform collections have a lot of overlap to support teams who may prefer one over the other (or teams that use both), and the same is true with event-driven automation. An exciting development in the market is the entrance of a new offering from Red Hat Ansible called Event-Driven Ansible.
The LogicMonitor team has been working with and experimenting with Event-Driven Ansible when it was released into developer preview late last year. As a Red Hat partner, we are working diligently on building a community source that will plug into Event-Driven Ansible to make it easier for our customers to start experimenting with it. To learn more about Event-Driven Ansible check out https://www.ansible.com/use-cases/event-driven-automation.
If you would like to learn more about our future work with Event-Driven Ansible or are interested in participating in a beta with us before release, please fill out a form to get started!
ESXi clusters involve a combination of ESXi hosts, VMware services, and vCenter to optimize load balancing, availability, and resource management for virtual machines (VMs). These clusters feature a vCenter server that centralizes the management process to facilitate shared resources that drive higher availability, scalability, and load-balancing capabilities.
Unpacking the components of ESXi clusters
An ESXi cluster contains a synergy of components responsible for pooling the shared resources required for powering VMs while minimizing downtime. An ESXi cluster typically contains the following core components:
ESXi hosts
These physical servers each host their own ESXi hypervisor, a type-1 hypervisor that contains the various VMs. A host’s resources are utilized only for the VMs and services that are currently running on them. Through additional processes such as vSphere HA and vMotion, virtual machines can be automatically moved between hosts based on optimal resource allocation, ensuring high availability.
ESXi clusters also allow you to cluster your networking and include things like distributed virtual switches, which allows you to set up a single (or multiple) switches that are shared by all of the ESXi hosts.
Virtual machines
VMs play a critical role in ESXi clusters, serving multiple functions that include consolidating servers, maintaining high availability, and providing disaster recovery under emergency situations.
Specifically, VMware ESXi runs on top of hardware without requiring manual operating system installations. The process enables VMs to share physical hardware resources like CPU, memory, network, and storage while maintaining isolation. ESXi cluster’s advanced configuration can outperform traditionally hosted hypervisors. These can help enhance overall cost-effectiveness and performance.
A Virtual Center, or vCenter, is the centralized management platform for ESXi hosts, VMs, and services. vCenter is the brain behind everything: it provides all of the tools for enabling and configuring high availability and load balancing. It also allows you to configure shared storage such as setting up iSCSI drives and datastores, and it allows you to configure virtual networks that all ESXi hosts communicate with.
Shared storage
The shared storage component of ESXi clusters enables multiple hosts and serves to access a VM when required. A well-established connection between shared storage and ESXI hosts provides VMs with high availability across various scenarios, which is crucial for complex enterprise infrastructures with multiple users.
Popular examples of shared storage used in ESXi clusters include Network File Systems, Storage Area Networks (SANs), Virtual SANs, and datastores.
Enterprise managers should choose the most suitable shared storage type according to cost-effectiveness and specific system performance requirements. For example, managers may choose SANs with dedicated networks to support workload-intensive databases or high-traffic web applications.
Unpacking the advantages of ESXi clusters
Essentially, ESXi clusters optimize complex enterprise systems by providing the technical capabilities of running multiple applications through VMs, overcoming the limitations of a single hosted server. These can establish a wide array of system improvements, mainly through high availability and optimal load balancing. An additional benefit of ESXi clustering is that vCenter provides a centralized location for managing all ESX hosts and VMs.
High availability
ESXi clusters offer failover capabilities by tapping on High Availability (HA) clusters. There are two different HA systems that run in vCenter, but they are not related. The HA that we are interested in is the vSphere HA. vSphere HA provides HA for the VMs and relies on primary and secondary hosts, as well as admission control.
The most important thing about admission control is that it ensures that there are enough resources reserved for virtual machine recovery in the event of a failure. There are several different policies that can be used in order to determine how the ESXi hosts’ resources are split up.
Optimal load balancing
The distributed load balancer (DRS) utility of ESXi clusters automatically balances host workloads by assessing the resource demands of their VMs. As such, you can expect optimized resource management for maintaining critical enterprise workloads.
Setting up ESXi clusters
The first step involved in setting up ESXi clusters is choosing between scale-out and scale-up strategies. A scale-out configuration involves fewer ESXi hosts per cluster but often ends up with more configured clusters. You can set up a scale-out cluster by adding more nodes to a cluster, which increases performance through a distributed system.
Alternatively, a scale-up configuration features more hosts but a significantly lower number of overall clusters. You can prepare a scale-up cluster by adding resources like CPU and networks to a single node, improving its performance and capacity.
Once you have decided on the cluster type, you can start creating your layout with the following steps:
- Use the VMware ESXi installer to upload ESXi on each physical server within your system.
- Establish the vCenter Server that serves as the centralized management touchpoint for your clusters.
- Log into vSphere Web Client to configure the host network arrangements.
- Create your cluster in the vCenter Server and designate it to a host. You’ll also need to make the necessary configurations for each cluster. These include sorting through functions like admission controls for determining the resources required to run a VM.
- Set up the appropriate shared storage type for your clusters based on system needs.
- Plan your VMs and link them to hosts based on system requirements, such as resource availability.
Additionally, it is important to keep ESXi clusters consistently monitored and managed via the vCenter Server. The centralized management platform offers a comprehensive view of your cluster status, through insightful metrics like CPU performance and network latency. You’ll also want to make sure that the vCenter version you plan to install supports the version of the ESX on the hosts. The detailed vCenter Server reports help guide the necessary tasks for keeping systems at top performance.
Managing ESXi clusters
You can modify an existing ESXi cluster according to your enterprise needs by adding servers or VMs for scaling system performance. These configurations and changes take place via the centralized vCenter Server.
For adding hosts
You will need to ensure that each host runs a version of ESXi that is supported by the chosen vCenter distribution. Also, they should not feature a manual vSAN configuration or networking configuration.
You can add an ESXi server by accessing the vSphere Client (Desktop) or vSphere Web Client through the vCenter Server. Select a cluster within the datacenter, where you can add and make configurations to its existing lists of hosts. You’ll have the opportunity to view a host summary before completing the process, which offers important details of added hosts and technical warnings.
For adding VMs
Similarly, you can add VMs utilizing the vSphere client. Navigate to your target cluster, select New Virtual Machines in the action drop bar, and follow the prompts from the Virtual Machine wizard for configuring the new VM. You will also need to allocate the resource/hardware settings for your VM and the shared storage system. Similar to adding hosts, you’ll receive a detailed summary of your new VM before you proceed to complete the process. A new VM can be created directly in the cluster or can be assigned directly to a certain host. If an ESXi host is part of a cluster, all of its VMs will be part of the cluster.
The resource pool
Clusters also have an additional level of organization called a resource pool. This is what lets you fine tune how resources are allocated to different groups of VMs. For instance, if there are production critical VMs, we can ensure that they have more CPU/mem allocated than the rest of the VMs.
At LogicMonitor, we help companies transform what’s next to deliver extraordinary employee and customer experiences. Want to learn more? Let’s chat.
The IT services industry has continued to grow in the backdrop of high demand for innovative solutions across all industries. Global spending surpassed $1.3 trillion in 2022. Managed services account for much of this spending with managed service providers (MSP) at the heart of the impressive growth.
MSPs make up the largest part of the IT service industry, delivering an extensive host of IT solutions from data storage, Networks and Infrastructure, security, Software as a Service (SaaS), communication services, support, and other essential business solutions. But in today’s fast-paced business environment, client demands change rapidly and MSPs have to adapt quickly to these changing market needs.
MSPs struggle to offer multiple IT Services, and this causes challenges in meeting clientele’s requirements. To overcome this challenge, IT service providers now heavily rely on Remote Monitoring Management (RMM) tools. With RMM, MSPs seamlessly manage clients’ needs remotely and resolve any issues.
While RMM solutions can ease most of the challenges in your MSP, they come with multiple challenges. If you want to move to the next level of IT service management, optimize your systems to overcome myriad challenges with RMM solutions such as inability to scale, weak automation protocol, weak reporting, and complexity of the technology. This post explores how you can leverage unique solutions to go beyond RMM and towards IT service management (ITSM).
How MSPs Are Currently Using RMM
As a managed service provider (MSP), you have a daunting task on your hands to meet diverse clientele needs. Your clientele probably spans multiple industries across different time zones. With a clientele base this wide, you would have to devote a lot of resources to guarantee reliable service delivery.
The traditional break-fix model that MSPs relied on no longer works. You can’t have someone physically visiting your clients’ offices to sort out technical hitches. This is where a dedicated Remote Monitoring Management (RMM) tool. RMM software is integral to network management and asset monitoring by MSPs. Your team gets tools that allow visibility over connected endpoints (client’s devices/networks). With RMM solutions, you can effectively monitor everything that happens on your managed networks and consider the action to improve network performance.
A dedicated Remote Monitoring Management (RMM) tool helps your company standardize connected IT assets and ensure optimal performance. Your IT experts can remotely check on the connected IT assets and evaluate their performance against the standards.
Two of the biggest complaints against MSPs have always been poor response time and downtime. With the best RMM solutions, your IT professionals can now monitor systems, track issues, allocate tasks, and automate maintenance jobs. With this efficient technology, you have all assets under your watch in your control. You gain insight into how your managed networks and assets perform, and carry out maintenance work remotely.
For managed IT service providers, RMM software is a godsend in improving the customer experience. It’s easier to maintain the best SLA levels through ongoing remote maintenance of managed networks. More importantly, MSPs can meet the stringent compliance standards in the industry through improved network performance, remote monitoring, and network security.
With the agents installed on the client’s system, your MSP has real-time data on which to base its decision. Reporting and analytics are two of the major benefits of leveraging RMM solutions. Ultimately, the constant stream of data helps to:
- Reduce downtime: You can foresee emerging problems and resolve them remotely, which improves customer satisfaction levels.
- Respond faster: With real-time monitoring, any issue that emerges on a clients’ website receives immediate attention for resolution.
- Leverage automation benefits: You can automate updates, maintenance works, and other tasks under the managed service agreement, such as creating system restore points, deleting temporary files or internet history, device reboot/shutdown, disk check, and running scripts.
- Enhance productivity: Your team also has more time on its hands to improve your services now that RMM continuously monitors the client’s systems. This boosts productivity levels in your company.
- Reduce costs: Your MSP enjoys the cost-cutting benefits that come with remote management of clients’ systems. Your IT experts can resolve issues remotely without leaving the office.
How MSPs Are Currently Using ITSM
With IT service management (ITSM), an organization can leverage the complete range of benefits from information technology. This is a popular concept in managed IT services, with the principal goal being to deliver maximum value to the IT services consumer.
The key players in ITSM are the MSP, end users (employees and customers using), and IT services offered by the MSP (from applications, hardware, and infrastructure), quality factors, and the costs. Managed services providers (MSPs) work with clients to deliver a host of IT solutions to meet the needs of such clients through a mix of IT solutions, people, and processes.
Unfortunately, MSPs still consider ITSM basic IT support, which means these service providers don’t harness the full potential of this IT concept. If you embrace ITSM in your organization, you have your IT teams overseeing all IT assets from laptops and servers to software applications.
ITSM doesn’t just focus on the final delivery of the IT services but spans the life-cycle of an IT service. An MSP works with the client from the conceptualization of the strategy, design, transition up to the launch/live operation of the service and maintenance.
Why Should MSPs Focus On Moving Past RMM to ITSM?
Unlike RMM, ITSM goes beyond detecting and resolving day-to-day issues on a client’s system. As an MSP, your IT team is integral in service delivery and handles end-to-end management of these IT services. You can leverage different ITSM tools to manage such services effectively.
While most MSPs are comfortable using RMM for enhanced service delivery, ITMS can make life easier for your IT team with structured delivery and documentation. If you implement ITSM for your managed services company, you streamline operations and save on costs with predictable operations.
Another way MSPs are leveraging ITSM is in decision-making. One of the most challenging roles of an IT manager is to make decisions on the fly. Implementing ITSM gives the team actionable IT insights into your operations. You have more control over your organization which helps in better decision making.
There’s a need for the next-gen MSP to move from RMM to ITSM. Some benefits for this shift include:
- Efficiency and productivity gains with defined roles and responsibilities.
- Benefits that come with a structured approach to service management.
- Aligning IT with your MSP’s business objectives/priorities.
- Helping to standardize service delivery.
- Help MSP set and meet realistic expectations for service.
- Facilitating cross-department collaboration.
- Faster response to major IT incidences.
- Building an empowered IT team.
- Improved service delivery.
- Reduced IT costs.
- Reduced regulatory and security risks.
- Increased profitability.
- Higher customer satisfaction.
- Reduced incident life cycles.
- Improved compliance and reduce risk through compliance in IT service design, delivery, and management.
- Reduced downtime because of more efficient alerting with ITSM.
How To Improve ITSM
For a managed services provider, ITSM is essential in the highly competitive industry. You can leverage the best ITSM tools to improve productivity, deliver higher quality services, and much more. For this reason, continuously improve your ITSM strategy.
Below are some ideas you can integrate into your system for better IT service management:
- Setting clear and achievable short and long-term goals: Use the SMART model (Specific, Measurable, Actionable, Relevant, and Time-Bound) when you come up with goals to make it easier to assess progress
- Assess the current situation and needs/ITSM maturity level: Don’t implement any changes for the sake of it but carry out an audit to identify weaknesses you can eliminate. This ensures you invest in appropriate ITSM solutions.
- Establish clear KPIs: The KPIs and metrics help you track the ITMS performance. They include the number of incidents, customer satisfaction score (CSAT), first contact resolution (FCR) rate, average incident resolution time, and the number of service requests.
- Strategize on winning upper management support: Executive agreement eases the update of your MSP’s ITSM capabilities.
- Consider the options to implement ITSM changes: Brainstorm with the team to identify the best techniques to update your ITSM operations. ITIL is one of the trusted frameworks for ITSM best practices, but you can look at alternatives. Make sure you bring everyone on board through training before you implement any changes to ITSM.
- Automation: In today’s fast-paced business environment, automation comes handy if you wish to improve ITSM in your MSP. With the right automation tools, you boost efficiency and help cut costs of any ITSM changes. Automation also reduces the risk of errors, improved predictability, productivity, and reliability, while enhancing customer experience.
- Choose the right ITSM software: To get the most of ITSM, choose the right software to suit your company. Go for a single ITSM software that helps manage everything from one place.
- Incremental changes: Any changes to ITSM require time and a continual service improvement (CSI) approach. Track and measure the progress as you implement the changes to avoid disruptive action that might ruin customer satisfaction.
How To Reduce Costs With ITSM
One of the main advantages of the ITSM platform is the reduction of IT costs. Most businesses that would like to harness the immense benefits of IT solutions can’t because of the associated high costs. With ITSM, organizations can now take their operations to another level by integrating a whole range of IT solutions.
With the competitive nature of the IT industry, MSPs have to identify innovative solutions to cut costs. ITSM helps in cost reduction through higher employee productivity, streamlined business processes, and reduced cost of IT systems.
Some tactics that can help reduce costs with ITSM include:
- Shifting to the cloud: This saves on capital expenditures for equipment such as servers and network equipment. You only pay monthly operating expenses.
- Implementing agile practices: MSPs have to move from the traditional organizational structure and embrace agile collaborative practices. The shift to agile can cut costs through faster fixes and reduced failure rates.
- Automation: Automated managed IT solutions guarantee better service delivery and cut costs on repetitive tasks. From job scheduling to clients’ system monitoring, automated IT service management can help cut costs of operations.
- Use of contractors: Your company can streamline its ITSM platform by recruiting external contractors for service delivery when you need specific tasks done.
- Optimization: By optimizing your ITSM system to reduce downtime, which can eat into your bottom line.
Automating With ITSM To Save Time
MSPs face an enormous challenge in service delivery, and this is where ITSM automation comes in handy. By automating business processes, you improve service delivery, cut costs and more importantly, save time. Time is an invaluable asset in the IT service industry and can make or break your organization.
Automating with ITSM streamlines repetitive tasks from your operations and eliminates redundancy. Automating these functions also enhances the quality of service and boosts the customer experience.
You can also make faster transitions in your business in case of changes when you automate ITSM functions. Other benefits include:
- Easier employee onboarding.
- Automated workflows.
- Faster system updates.
- Automated ticketing for faster resolution of issues by the IT desk.
Automation enables organizations to streamline IT processes, reduce costs, and improve service delivery. By automating routine tasks such as software updates, patching, and backup, IT teams can focus on higher-value activities that require more specialized skills.
Automation can also help to reduce errors and improve consistency, which can increase efficiency and reduce downtime. In addition, automation can provide real-time monitoring and analytics that enable IT teams to proactively identify and address issues before they become critical.
Use ITSM to elevate customer service
ITSM helps MSPs deliver better customer service in several ways:
- Clear service level agreements (SLAs): ITSM involves establishing clear SLAs with clients that specify the level of service they can expect. This can help to manage client expectations and ensure that MSPs are delivering services that meet or exceed those expectations. SLAs can cover response times, uptime guarantees, and other metrics that are important to clients.
- Proactive service management: ITSM is designed to be proactive, rather than reactive. By proactively monitoring IT infrastructure and identifying potential issues before they become critical, MSPs can prevent service disruptions and minimize downtime. This helps to ensure that clients are always able to access the IT services they need.
- Consistent service delivery: Consistency is key with ITSM, which creates a standardized model for service delivery. This helps to ensure that all clients receive the same level of service, regardless of their size or complexity. Consistent service delivery makes the difference in trust building with clients and improving overall experience. Big or small, everyone wants to feel that expert attention to detail
- Communication and reporting: This can include regular performance reports, incident notifications, and other updates as defined by each customer. Effective communication and reporting can help to build trust and confidence with clients, demonstrating that MSPs are actively managing their IT services.
- Continuous service improvement: ITSM involves a continuous improvement mindset, where MSPs are always looking for ways to improve their services. This can include gathering client feedback, monitoring performance metrics, and implementing process improvements. By continuously improving their services, MSPs can stay ahead of the curve and deliver even better service to their clients over time.
By establishing clear SLAs, being proactive, delivering consistent service, communicating effectively, and continuously improving services, MSPs can differentiate themselves in a competitive market and build long-term client relationships based on trust and reliability.
Advanced Security With ITSM Function
ITSM promotes collaboration between IT and security systems. When these two components work together, there’s improved security through automatized alerts, identifying potential risks, faster resolution of security threats. All these give your clients peace of mind.
The IT service industry is volatile and fast-paced, with innovations and solutions emerging every day. To survive in such a turbulent business landscape, your managed services company must adapt fast and embrace the latest solutions. While RMM solutions have served MSPs for a long time, the next-gen MSP has to embrace IT service management (ITSM) solutions to survive. ITSM guarantees better service delivery, reliability, higher productivity, advanced security, cost reduction, and other benefits that give your MSP a competitive edge.
Originally published June 10, 2021. Updated March 2023.
In modern application development and architecture, there has been a big push from monolithic, large applications that can do everything a product would need, to many smaller services that have a specific purpose. This onset has brought on the age of microservice frameworks (micro-frameworks), with the goal of making it easier to prototype, build, and design applications in this paradigm. Both Quarkus and Spring are big contenders vying for the spotlight when it comes to accomplishing your goals as a microservice application developer, but which should you pick?
What is Quarkus?
Quarkus is a Kubernetes-Native Java framework tailored for GraalVM and HotSpot, crafted from best-of-breed Java libraries and standards. The goal of Quarkus is to make Java a leading platform in Kubernetes and serverless environments. It also offers developers a unified reactive and imperative programming model to optimally address a wider range of distributed application architectures.
Some notable features of Quarkus include:
- Live coding: Quarkus offers a development mode that enables live coding, allowing developers to make changes to their code and see the results instantly without having to restart the application. This feature significantly speeds up the development process.
- Unified configuration: Quarkus provides a centralized configuration system, making it easy to manage and organize configuration properties across the application.
- Reactive programming: Quarkus supports reactive programming with Vert.x, a toolkit for building high-performance, event-driven applications. This feature allows developers to create responsive and resilient systems capable of handling large amounts of concurrent connections.
- Extensibility: Quarkus has a vast ecosystem of extensions, making it simple to integrate with various technologies, libraries, and frameworks, such as RESTEasy, Hibernate, and Apache Camel.
- Native image generation: Quarkus supports generating native executables with GraalVM, resulting in faster startup times and lower memory usage compared to traditional Java applications.
What is Spring Boot?
Spring Boot is an open-source Java-based framework used to create a micro-service. It was developed by the Pivotal Team and is used to build stand-alone and production-ready spring applications. It’s a commonly chosen application framework for a MicroServices architecture.
Here are some notable features of Spring Boot:
- Autoconfiguration: Spring Boot automatically configures your application based on the dependencies you include, reducing the amount of manual configuration required. This feature streamlines the development process and helps developers focus on writing code rather than dealing with configuration files.
- Embedded servers: Spring Boot applications can be packaged with embedded web servers like Tomcat, Jetty, or Undertow, eliminating the need to deploy your application to an external server. This feature simplifies the deployment process and makes it easier to create self-contained applications.
- Starter dependencies: Spring Boot offers a set of pre-configured “starter” dependencies that allow developers to quickly add and configure common functionality, such as web services, data access, and security. These starter dependencies help reduce boilerplate code and ensure consistent configurations across projects.
- Actuator: The Spring Boot Actuator module provides built-in production-ready features like health checks, metrics, and application information, making it easier to monitor and manage your application in production environments.
- YAML configuration: In addition to traditional Java properties files, Spring Boot supports YAML-based configuration files. This feature offers a more human-readable and concise syntax for configuring your application.
LogicMonitor Microservice Technology Stack
LogicMonitor’s Metric Pipeline (where we built out a proof-of-concept of Quarkus in our environment) is deployed on the following technology stack:
- Java 11 (corretto, cuz licenses)
- Kafka (Managed in AWS MSK)
- Kubernetes
- Nginx (ingress controller within Kubernetes)

Why Move From Spring Boot to Quarkus?
Our legacy pipeline was based on Spring and Tomcat. There were a couple of things about this framework choice that we didn’t like when we inherited its maintenance and deployment, including:
- Memory and CPU consumption: For the operations being performed, an inordinate amount of resources were being utilized outside of the application’s main purpose by the framework of Spring and Tomcat.
- Warmup time: The spring application could take anywhere from 10-20 seconds to start up, at which point the application could then start to warm up.
- Less code: As developers, we all hate boilerplate code. ‘Nuf said.
- Testing: Quarkus makes it really easy to write both unit and integration tests. Just slap a @QuarkusTest annotation on there and it will actually spin up the whole application in order to run your test.
- Scale-out (horizontal) vs. Scale-up (vertical): The smaller each application could be (resource-wise), the more we could add. Horizontal Scalability for the win.
- Learning curve: Quarkus’ docs online were very straightforward and easy to absorb.
How Did We Choose Quarkus Over Other Java Microframeworks?
In addition to Quarkus, we explored two other Java Micro-Frameworks: Helidon.io and MicroNaut.
Micronaut
Micronaut was probably the most comparable with Quarkus. The declarative nature of the framework was very similar and it had out of the box support for technologies we use heavily here:
- Kafka
- Docker / Kubernetes
- APIs
- Relational / Non-Relational databases
- Gradle
The main reason we didn’t end up with Micronaut was that it was not based on the eclipse microprofile framework, but something homegrown. We felt that since Quarkus was backed by Redhat and was based on microprofile, it had a better situation regarding community support and documentation
Helidon.io
Helidon was also one of the top contenders. It’s API framework was based on JAX-RS, and in general, we felt that it still required way too much boilerplate to get things up and running. It had a lot of similar technologies supported but it wasn’t as well integrated.
What We Learned
When we set out to build a POC of one of the applications in the pipeline, we set up an internal document laying out the success criteria:

APIs were very easy to design and implement. We went with Quarkus’ rest-easy implementation and found it to be both RFC compliant and similar to the JERSEY framework we were already familiar with in other applications in our infrastructure. We weren’t able to use their built-in authentication implementation, however, due to some backward compatibility issues with how the existing application authenticated requests (based on a homegrown request header token).

Kubernetes Support
One of the things we really liked about the Quarkus framework was how easy it was to set up the Kubernetes Liveness/Readiness probes. All we had to do was add a dependency (smallrye-health), enable a configuration, and we had a kafka liveness/readiness probe ready to go. Adding our own health check to make sure our application was configured correctly was as easy as annotating a class, and implementing a simple interface. Then, probes were available at the “/health” (gets both liveness and readiness check results), “health/live”, and “health/ready” endpoints.
CDI Bean Injection
In addition to the probes, we also really liked the CDI bean injection. We found this to be more easily conceptualized than Spring’s DI implementation, and it enabled us to build a lot quicker than normal. One thing to note though, is that in order to expose metrics, those metrics must be exposed from a class with a bean-defining annotation. This is part of how microprofile works, more on metrics later.
Configuration
In terms of configuration, Quarkus has support for profiles and configuration from multiple sources. At LogicMonitor, we use a central configuration service, so we ended up setting System Properties based on an eagerly-instantiated bean which polled that service for its configuration settings. We didn’t have a huge use case for the @ConfigProperty annotation because we want most of our configurations to be easily changed at runtime, and those are usually defined on a bean’s instance variables. Most of the beans in our POC app were @ApplicationScoped, so that would have required the config values to be static.
Quarkus Kafka Limitations
Quarkus has support for Kafka through the SmallRye Reactive Messaging framework. We had a good experience with this framework for our Kafka Producer, but not our Kafka Consumer application. The Kafka Producer is fairly easy to set up for imperative usage in this guide. There are a couple of things to be careful of with here regarding default configuration values of the producer that caused a bunch of issues for us (and a few hours of troubleshooting headache):
- Overflow Strategy: By default, the producer’s overflow strategy is that of a small memory buffer. The Kafka Emitter will wait for a signal from the Kafka consumer (reactive messaging) to know that a given message will be processed correctly. This is bad news though, if your Kafka consumer is in a different application, unable to send any signal to the Emitter. So, we set this strategy to NONE. The risk here is that we don’t have anything within the application to know if the Kafka consumer is keeping up or not. But we solved this by using the Kafka client JMX metrics directly in our monitoring solution.

- WaitForWriteCompletion (see configuration section here): By default, the producer was waiting for an ack from Kafka that the message was accepted correctly and fully even if acks was set to 0. By default, this config value is true, so we had to set it to false in order to keep up with the volume of data we were processing.
When it came to the Kafka Consumer we also ran into a fair bit of trouble in two main areas:
- Auto Commit: by default, the Quarkus consumer was committing to Kafka after every message was received, causing a big pile-up in consumer lag.
- Single-Threaded Consumer: this caused us to actually avoid using the Quarkus Kafka consumer for metrics processing. After lots of troubleshooting hours and headaches, our team found that not only was it single-threaded, it was processing messages serially. It just couldn’t keep up with our volume, so we ended up building a Kafka consumer based on the Apache Kafka Java SDK directly so that we could have multiple consumer threads per application container. We did, however, keep the Quarkus Kafka consumer for another use case we had that had a much lower volume of messages, simply because of the ease of use to configure it:

- Other “gotchas” with the Quarkus Kafka Consumer include:
- You have to be very careful to return a completedFuture, otherwise, we found that the reactive framework took way too long to process each message, sometimes hanging indefinitely.
- Exceptions thrown in the @Incoming method aren’t handled gracefully either (the consumer will stop), so be sure to be careful here too.
- The Reactive Messaging Framework’s channel implementation doesn’t allow consumption of topics based on a pattern (i.e. only a single topic can be consumed from per channel)

Quarkus played very nicely with our existing Java monitoring via JMX (all the garbage collection, heap, threads, uptime DataSources applied, and gathered data automatically). It also allowed us to define our own application metrics easily. In my opinion, this was one of the biggest benefits of the app: using microprofile metrics. We were able to both time and count operations through a simple annotation, that instantly makes those metrics available from a “/metrics/application” endpoint:

The @Timed Annotation gives you tons of information: min, max, mean, throughput, percentiles). This screenshot also shows the fault tolerancy feature too (which exposes its own metrics by the way). That along with the scheduled tasks was a nice treat to discover (sidenote: we discovered that the initial delay of the scheduler was not configurable, so we put in a feature request, and it was fixed within two weeks!). Okay, back to metrics:
Gauges and Counters, super easy too:

Logging in Quarkus is done via JBoss, and once we added a logging.properties file we were able to tune things no problem.
Quarkus Performance – A Huge Improvement
- CPU: After deploying, we found that Quarkus used about 15% of the CPU from the previous Spring/Tomcat solution. We were able to really scale down one of the POC application’s resource requests/limits in kubernetes (about 200 cores worth across our infrastructure’s kubernetes worker nodes)
- Memory: We also saw that Quarkus used about 12% of the memory from before, so we could scale down a bunch here too (~500 GB of memory reduction across the infrastructure in this application alone)
- Startup – From 15 seconds before, we are now seeing an average of two seconds, 85% faster than before
Conclusion
At the end of our POC and deployment across our infrastructure, we ended up with both explicit and implicit improvements from resource utilization to ease of programming in the framework. So far, we are sticking with Quarkus!
About LogicMonitor
LogicMonitor is the only fully automated, cloud-based infrastructure monitoring platform for enterprise IT and managed service providers. Gain full-stack visibility for networks, cloud, servers, and more within one unified view.
The Cisco Networking portfolio is an essential part of your IT support services. These networks can provide your company with the necessary efficiency, security, and productivity, so you can securely connect your team, customers, and assets.
What are the top on-prem Cisco networks?
In IT infrastructure, on-premises describes hardware and software that are hosted on-site. On-premise IT infrastructure and platforms support 38% of all workloads. It also helps 43% of enterprise workloads. These on-prem Cisco networks are dedicated, reliable, and private.
What are the top cloud-based Cisco networks?
Cloud-based Cisco networks describe a scenario where you host your IT assets at a remote data center or a public cloud platform. Cloud adoption is rising, with 85% of businesses expected to use a cloud-based application by 2025. Unfortunately, only 3% of companies have developed advanced cloud strategies. They need to take the necessary step to make these networks scalable and successful.
Here are a few of the top cloud-based Cisco networks:
- ACI
- Catalyst
- CSR
- Nexus
Catalyst
Cisco’s Catalyst switches offer network switches, wireless access points, and wireless network adapters. Your network devices should be compatible with these switches to ensure secure and consistent up-time. With the deployment of these Catalyst switches, you can inspire and drive digital transformation within your organization. Let’s consider what Catalyst is and what it does.
What is it?
Catalyst offers a variety of network interfaces, including Ethernet switches. They also offer access points, wireless controllers, and wireless network adapters.
What does it do?
A Cisco Catalyst access switch combines wired and wireless connectivity, so you can enforce your security protocols and simplify network management. Catalyst switches help drive digital transformation by better controlling access and traffic.
Cisco’s Catalyst was designed primarily for campus networks’ core/distribution layers and is great for small businesses. It’s also designed to handle more customizable, large-scale scenarios. For example, Cisco Campus LAN Catalyst switches are often used to create thorough network coverage, even in demanding hybrid environments.
You can filter by levels and handle loops in unmatched Syslog information. It is also possible to troubleshoot faults early by using detailed SNMP traps. This unit allows you to route as well as switch. The larger Catalyst switches combine high-speed routing with high-density ports.
More info on Cisco Catalyst:
ASA (Adaptive Security Appliance)
Cisco’s ASAs (adaptive security appliances) serve various security needs. Technology-driven businesses need ASA, so Cisco has spent time and money developing its ASA devices. Developed over the last 15 years, ASA solutions include basic firewall, VPN, and antivirus capabilities.
What is it?
Cisco’s ASA offers enterprise-class firewall capabilities for ASA devices in various form factors. You can tap into the antivirus, firewall, intrusion prevention, and virtual private networks. Additionally, ASA software delivers comprehensive security solutions. You can easily integrate with other critical security technologies to support better cybersecurity for data centers and corporate networks.
What does it do?
There is still a lot of use for Cisco ASA today. While it had some of the same features as PIX, the enterprise-class features make ASA solutions easier to use and understand for corporate users. You can use ASA as a proactive threat defense to stop network attacks before they spread through the network. They seamlessly integrate with other corporate security measures to deliver the next-level cybersecurity measures you need.
Cisco ASA supports a highly secure remote access solution, so you can access data and network resources from any device on your corporate networks no matter where you are. It’s also widely used and supported. More than one million Cisco ASA security appliances are used in enterprise environments globally.
More info on Cisco ASA:
- https://logicmonitor.com/integrations/cisco-asa-firewall
- https://logicmonitor.com/support/monitoring/networking-firewalls/cisco-asaasr
ISR (Integrated Service Router)
Cisco is a market leader in the networking equipment market, with a wide range of routers and switches. Regardless of the size of your business, you’ll benefit from Cisco’s integrated services routers (ISRs). With the recent advancement in technology, ISR capabilities have become increasingly important. For military operations, in particular, accurate ISR data is crucial.
With Integrated Service Router (ISR) routers, you can connect your branch offices reliably and securely. You can also perform multimedia and mobile tasks with the ISRs. Here’s what it is and how it works.
What is it?
Cisco’s integrated services routers (ISRs) offer affordable, reliable branch office connectivity. ISRs enable cloud computing, mobile connectivity, multimedia performance, and secure networking. They’re powerful devices on a single platform.
ISRs allow you to access multiple clouds. They support advanced security and wireless capabilities. Integrated Services Routers (ISRs) from Cisco meet the high-performance standards you need. But they’re also easy to deploy, use, and manage. You can connect to the Metro Ethernet, Internet, and wireless LANs in a highly secure way.
What does it do?
Hardware calls an integrated service routine (ISR) when an interrupt occurs. ISRs examine those interrupts so you can determine how to handle them. Then, execute the handling and return the logical interrupt values. The ISR returns a value to the kernel when the interrupt is resolved.
ICM (Intelligent Contact Management)
Cisco’s unified communications products are built on unified ICM. The unified ICM (intelligent contact management) is an open standards-based solution. With intelligent routing and computer telephony integration (CTI), you can use the easy-to-use interface to manage your contacts. Here’s what it is and how it works.
What is it?
Cisco’s Unified Intelligent Contact Management Platform enables the enterprise-wide coordination of your contacts across multiple channels and networks. It doesn’t matter where they’re located in relation to your contact center.
You can route and manage inbound and outbound voice, web collaboration, e-mail, and chat. With Unified ICM, you can manage routing, queues, monitors, and faults using open standards. You can integrate network-to-desktop telephony, manage multi-channel contacts, and route contacts. With that level of integration and transparency, you can see how much easier it is to manage your contacts.
What does it do?
Cisco’s Unified ICM supports the integration of voice applications with Internet applications. You and your team can access real-time chat. ICM supports a range of communication options, including email and other collaboration channels on the Web. A single team member can handle multiple interchanges simultaneously, so you can better support your staff and customers’ needs. With ICM, you can communicate more efficiently with your customers regardless of their preferred channel or platform.
ITM allows you to pre-route contact center calls through your carriers’ intelligent networks so you can better monitor and adjust to accommodate your resource availability and activity levels. Then, you can use the data to compile a comprehensive profile for each customer and further segment and target those customers.
Meraki
Meraki is part of Cisco’s networking services. It simplifies securing locations and optimizing IT experiences so you can more quickly and easily connect IoT. Cisco Meraki is the leader in cloud-controlled Wi-Fi, routing, and security.
What is it?
You can manage all of Cisco’s Meraki network devices with the Meraki cloud solution. Meraki supports centralized management. The Meraki cloud solution offers a simple and secure way to manage all Meraki network devices.
What does it do?
Cloud computing is the core of Meraki management solutions. Cisco’s Meraki devices support highly reliable multi-tenant servers. These servers are strategically distributed worldwide at Meraki data centers. Those data center servers consist of powerful computers which host dozens of separate user accounts.
Multi-tenant servers offer shared computing resources, making it easy to share equally among users. Meraki is committed to ensuring the security of your data through robust apps and insights. To ensure heightened security, Meraki restricts access based on account authentication.
More info on Cisco Meraki:
- https://logicmonitor.com/integrations/meraki
- https://logicmonitor.com/support/monitoring/networking-firewalls/cisco-meraki-monitoring
Nexus
Originating in 2008, Cisco’s Nexus switches connect your servers to storage and network resources in support of your hybrid cloud network. Additionally, they eliminated the need for parallel storage or computational networks. Here’s what Nexus products are and what they do.
What is it?
Cisco’s Nexus products include enterprise mobility management (EMM) security and offers security cameras, switching, and wireless solutions. You can manage all of the Cisco Nexus products from across the cloud and data centers in one place.
What does it do?
Cisco’s Nexus switches provide software-defined networking (SDN) solutions. With the Nexus switches, you can connect and manage data center resources.
UC (Unified Communications)
Cloud-based and on-premises UC solutions are available. Unified communication (UC) apps for businesses do not compromise security. UC supports the seamless integration of collaboration and communication tools.
What is it?
UC collaboration tools are used to support working together. Use IP telephony, videoconferencing, voice mail, or mobile collaboration with UC. You could also use desktop sharing and instant messaging.
What does it do?
You and your team can collaborate more effectively with Cisco’s unified communications solutions. That also means you can collaborate and access the UCS anywhere from any device. They use APIs to integrate messaging and chat with your phone system and conferencing solutions so you can better support real-time business communication.
More info on Cisco UC:
- https://logicmonitor.com/resource/monitoring-cisco-unified-communications
- https://logicmonitor.com/integrations/cisco-unified-communications-manager-voip
UCS (Unified Computing System)
Since 2009, Cisco Systems has been manufacturing its Unified Computing System (UCS). This consists of management software, server hardware, switching fabrics, and virtualization support. A Cisco UCS combines computing, networking, virtualization, and data storage components.
What is it?
Unified Computing System (UCS) by Cisco Systems is a collection of products:
- Computing hardware,
- Virtualization support,
- Switching fabric, and
- Management software
Using these products, you can integrate a data center’s components into one scalable system.
What does it do?
You can create a more cost-effective and efficient solution to help enterprises monitor devices and automate operations, all while managing data. UCS supports a centrally managed data center architecture for your company. Cisco’s new UCS C-Series rack servers have set many world records in industry-standard benchmarks for integer and java server performance. With Cisco UCS servers, your workloads should run faster. Cisco boasts an 86% reduction in cabling, faster provisioning, and a 40% cost reduction.
More info on Cisco UCS:
UC Virtual Machines
Cisco’s UC Virtual Machines allow you to create new network services. You can also deploy them anywhere at any time. It’s fast and reliable, taking minutes instead of days. You can also scale your network services up or down quickly to match the demand of your customers and internal requirements. Let’s further consider what the UC virtual machines are and what they do.
What is it?
A virtualized server (or virtualization host) shares network and storage hardware. They’re shareable between multiple application virtual machines (VMs). You run several operating systems with UC virtual machines on a single physical computer so you can save physical space, time, and money.
You can easily migrate to a new operating system while supporting legacy applications. The most critical advantage of Cisco’s UC Virtual Machines is that you can better support disaster recovery.
What does it do?
A virtual network function (VNF) is a service that can be created and deployed automatically. You can then manage your infrastructure remotely. With UC virtual machines, you can scale and manage your resources to better accommodate your company’s changing needs both now and in the future.
Umbrella
More than 24,000 global organizations rely on Cisco Umbrella. It’s at the core of Cisco’s Secure Access Service Edge (SASE) architecture. Here’s what it is and what it does.
What is it?
With Cisco Umbrella, you can connect cloud access security brokers (CASBs) with firewalls. You can also access threat intelligence and web gateways to protect your organization.
Umbrella enables these connected solutions through a single, cloud-delivered service and dashboard. Doing so can significantly reduce the cost of deployment, configuration, and integration.
What does it do?
Cisco Umbrella protects your mobile users. You’re also able to improve incident response and expose Shadow IT. With Cisco Umbrella, you can deploy threat enforcement to protect your users no matter where they’re located.
Next step: select the right Cisco solutions
This guide to on-prem and cloud-based Cisco networks offer an overview of the tools you need to succeed. Cisco Networking portfolio offers all the solutions that will support your security, communications, and storage requirements. Explore these options and determine which will best sync with your business requirements.