A step-by-step look at how Edwin AI uses native LogicMonitor logs, topology, and context to turn root cause analysis from alert-driven inference into evidence-backed investigation.
Explains why alert-only and LLM-driven root cause analysis (RCA) fails to establish causality
Shows how logs change RCA when they’re scoped by configuration items and time window
Walks through Edwin AI’s logs-in-RCA pipeline using a real VPN incident example
Demonstrates how RCA extends into ongoing AI investigation, not a static answer
Connects evidence-backed RCA to real operational outcomes and autonomous IT readiness
Most root cause analysis today starts with alerts and ends with explanations that sound reasonable but can’t be verified. An alert is fed into a language model, and the output looks like an answer. It often isn’t. The explanation isn’t tied to the underlying system behavior, so engineers still have to validate it themselves.
Often, that validation happens in logs. Logs can contain the details that show exactly what changed, or what failed, and when it happened. Without them, RCA depends on inference. With them, it rests on evidence. Edwin AI is built around that reality. It uses logs as a core input to analysis, not a follow-up step, so conclusions are based on what systems recorded—not on what a model inferred from alerts alone.
The problem with root cause analysis today
The problem with root cause analysis today isn’t a lack of data. It’s where analysis stops.
Most RCA workflows are designed to explain why an alert is fired. They work backward from metrics and thresholds to produce a likely cause. That approach can describe system behavior at a high level, but it does not establish causality. It doesn’t show what changed, what failed first, or how failures propagated through the system.
That gap pushes real analysis elsewhere. Engineers leave the RCA view and turn to logs because logs are one of the only places where systems record what actually occurred. Configuration updates, retries, errors, and time-ordered execution all live there. The work required to review and understand logs is manual and slow, especially during active incidents.
In short, the issue is that logs are disconnected from the RCA workflow. Logs are searched without clear scope, often across too many components and too much time. Engineers spend effort narrowing the problem before they can even begin to reason about the cause.
As long as logs remain outside the core analysis path, RCA remains an explanation that still needs to be proven. Any approach that aims to improve RCA has to start by treating logs as primary evidence and by constraining them with context before conclusions are drawn.
How logs change the quality of root cause analysis
Logs improve root cause analysis by capturing system behavior before and at the point of failure—providing a baseline, highlighting changes, and exposing the error patterns behind the issue. They record state changes, execution paths, and configuration actions as they occur. That level of detail is what allows an incident to be reconstructed, not inferred.
Used correctly, logs shift RCA from describing outcomes to establishing cause. They make it possible to determine which component failed first, how other components responded, and whether the failure aligned with a change in configuration or execution. This is information alerts and metrics do not contain.
As often is the case, the problem is scale. Production systems generate far more log data than can be examined during an incident. When logs are accessed without constraints, teams spend time reducing scope before they can analyze anything. Broad searches obscure signals, while narrow ones risk omitting key information.
Most tools stop at recording logs. They make logs available but leave investigators to decide what matters and how to interpret it. Logs only raise the quality of RCA when they are limited to the relevant components, bounded by the incident window, and reduced to meaningful patterns. Without that discipline, logs add effort without increasing clarity.
Logs don’t help unless they’re targeted, clustered, and interpreted in context
Logs don’t improve RCA by default. Unfiltered, they introduce more work at the point where teams have the least time. During an incident, raw logs are repetitive, loosely structured, and hard to interpret in sequence. Reading them line by line—by a person or a model—doesn’t produce clarity.
What makes logs useful is constraint. Logs need to be tied to the specific components involved, limited to the time window that matters, and reduced to patterns that reflect real changes in system behavior. Without that framing, logs are just more records.
Most approaches break down because they treat logs as a general-purpose data source and leave the hard decisions—scope, relevance, correlation—to the operator. The result is either overcollection or missed signals.
Edwin AI is built around a different assumption: logs only matter in context. Alert data and topology are used to determine which configuration items are in play, which dependencies are affected, and which logs are relevant to the incident. Those logs are then grouped and reduced so analysis is based on real signals with the objective of surfacing the log evidence that explains what actually happened.
Edwin’s AI Investigation now incorporates LM Logs
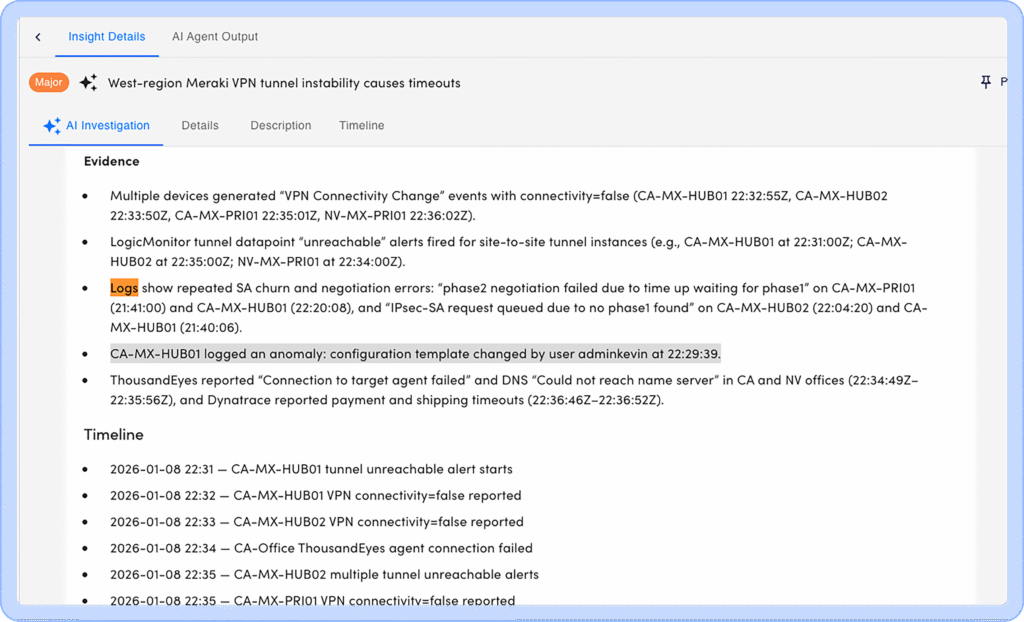
Edwin AI’s approach to root cause analysis is deliberately sequential. Each step narrows the problem space before any conclusions are drawn, so logs are used as evidence—not as raw input for speculation. To make this concrete, consider a real incident involving widespread VPN instability across a west-region network.
Step 1: Analyze alert data (context first)
RCA starts with alerts. In our example, we’re referring to alerts reported site-to-site VPN connectivity drops across multiple Meraki MX appliances, triggering regional site outages and downstream application timeouts.
Alerts such as these establish the scope of impact, the affected region, and the initial blast radius. At this stage, large language models (LLMs) are used to frame investigative direction—not to assert cause from the jump. The goal is to understand where to look, not why it happened.
Step 2: Identify configuration items (CIs)
After alerts define the scope, the next step is narrowing it. Edwin AI maps alerts to the specific systems involved so the investigation focuses on what could actually be responsible.
In our VPN incident example, alerts showed connectivity failures across multiple sites. That signal was broad. Using LogicMonitor’s topology and CMDB context, Edwin identified the configuration items that participate in site-to-site VPN traffic: regional MX hubs, branch devices, and the services that depend on those tunnels. Systems outside that path were excluded from analysis.
This step matters because RCA breaks down when everything is treated as relevant. Without a clear set of configuration items, teams pull logs from too many places and spend time eliminating false leads. By tying alerts to known infrastructure, services, and dependencies, Edwin defines what belongs in the investigation and what does not. That focus is what makes the next steps—log retrieval and analysis—practical instead of exhaustive.
Step 3: Fetch logs per CI during the incident window
Once the relevant systems are identified, Edwin AI retrieves logs only from those configuration items and only for the time period that matters. This step locks the investigation to a specific set of records instead of opening a broad search.
In our example, Edwin pulled logs from the identified MX hubs and peer devices during the window when tunnels began failing. Logs outside that window were excluded. Logs from unrelated devices were never queried. The result was a dataset aligned to the incident, not the environment as a whole.
This constraint is what makes logs usable during RCA. When time and scope are defined first, logs become evidence tied to a specific failure. Without those boundaries, teams spend their effort narrowing searches rather than understanding cause.
Step 4: Cluster and summarize logs
At this point, Edwin AI has a bounded set of logs. The next job is to make them usable. Raw logs are repetitive. The same failure can generate hundreds of near-identical lines across multiple devices. Reading them directly—by a person or an LLM—wastes time and still misses relationships.
Edwin groups similar entries, collapses duplicates, and pulls forward anomalies and high-signal errors. In our VPN incident, that reduction surfaced two signals that mattered and that were easy to miss in raw output: a configuration template change on a central MX hub (from prod-network v13 to v14.1) logged shortly before the instability began, and a cluster of IPSec negotiation failures across multiple devices during the same window, including phase 2 failures and messages indicating missing or delayed phase 1 security associations.
Edwin doesn’t hand an LLM a pile of raw logs. It produces structured summaries that preserve the facts—what changed, when it changed, and what errors followed—so reasoning happens on evidence instead of noise.
Step 5: Run root cause analysis across alerts, logs, and context
Only once alerts, logs, and system relationships are aligned does Edwin AI run root cause analysis. At this point, the investigation is no longer searching for clues. The evidence is already in view.
In the VPN incident, Edwin evaluated three inputs together: the alert pattern showing when and where connectivity degraded, the clustered log signals showing IPSec negotiation failures, and the configuration change recorded on the central MX hub. The timing and scope lined up. The configuration template update preceded the failures and affected the devices participating in the impacted tunnels.
The result was a ranked conclusion that pointed to the configuration change as the most likely cause, supported by log evidence and system context. The output did not rely on inference alone. It showed what changed, when it changed, and how systems responded.
This is the difference between an explanation and a conclusion. Root cause analysis works when conclusions are tied back to recorded system behavior and validated across context, rather than inferred from alerts in isolation.
When root cause analysis becomes AI investigation
In Edwin AI, logs don’t stop mattering once a root cause is identified. The same log evidence that supports the initial analysis continues to shape how the incident is understood and resolved.
Because logs are already constrained by system, dependency, and time window, they can be reused without restarting the investigation. They support clear incident summaries, allow conclusions to be checked against recorded behavior, and inform remediation steps based on what actually failed. RCA is no longer a single answer frozen in time. It becomes an investigation that can be revisited as conditions change or new questions arise.
This changes how teams work with incidents. Summaries reflect recorded system behavior rather than interpretation. Validation is tied to the same evidence used to identify the cause. Remediation guidance is based on observed failure patterns, not generic recommendations.
The result is a single, consistent account of the incident—grounded in alerts and logs—that teams can query directly. Engineers can follow up, verify assumptions, or explore alternatives without repeating earlier work or switching tools. Logs move from being a one-time reference to an ongoing source of understanding.
Why RCA improves when Edwin AI and LogicMonitor work together
On its own, Edwin AI can analyze patterns and propose causes. On its own, LogicMonitor can collect detailed telemetry. The limitation shows up at the boundary between the two.
Without direct access to logs, Edwin has to infer causes from alerts and metrics. That inference can narrow possibilities, but it can’t confirm what actually happened inside the system. The result is analysis that still needs validation.
Without Edwin, LogicMonitor logs provide that validation—but at a cost. Engineers have to leave the incident view, search across logs manually, filter repeated messages, and correlate activity across components. That work takes time, demands experience, and varies widely depending on who is on call.
Together, Edwin AI and LogicMonitor remove that friction.
Because Edwin has native access to LogicMonitor telemetry, log retrieval is scoped by default. Logs are pulled only for the configuration items involved and only for the incident window. Engineers aren’t searching across the environment or guessing which data matters. The investigation stays tied to the incident from start to finish.
This also reduces context switching. Engineers don’t move between an RCA view, a log search interface, and topology maps just to verify conclusions. The same log evidence that supports the analysis is available in Edwin, and when incidents flow into ITSM tools, that evidence-backed RCA moves with them. Teams can review root cause directly in the incident record without leaving their workflow.
This is what “better together” actually means here. Not a loose integration. Not an LLM layered on top of alerts, but a shared data foundation with reasoning built into it. So all analysis is grounded in telemetry and delivered where operational work already happens.
The operational impact of log-driven RCA
When RCA is built on logs and stays tied to the incident, teams stop circling the same questions. Decisions stick because they’re based on recorded behavior, not interpretation. MTTR improves because uncertainty is resolved early, not because people move faster under pressure.
The workflow also collapses. Engineers don’t jump between alerts, log search, topology views, and incident records to confirm what happened. The analysis stays with the incident as it moves from detection to resolution, so context doesn’t degrade during handoffs.
This reduces reliance on individual judgment. When RCA is grounded in logs, outcomes don’t depend on who is on call or who remembers a similar incident. Investigations follow the same structure and can be reviewed later without reconstructing the path taken.
Post-incident work changes as well. Teams don’t rebuild timelines or argue about causes after the fact. The evidence is already attached to the incident. Escalations are cleaner. Follow-on work starts with shared context. Trust increases because conclusions are traceable to system data, not hidden reasoning.
Logs are a foundation for autonomous IT operations
Logs give root cause analysis what it has lacked: a record of what actually happened. When RCA is anchored in logs, conclusions are based on system behavior, not interpretation. Investigations become repeatable, easier to validate, and easier to trust.
That structure matters beyond diagnosis. When logs are consistently scoped, reduced, and tied to outcomes, they stop being a one-time reference. They support pattern detection, allow conclusions to be checked automatically, and create the conditions for remediation to be validated rather than assumed. Over time, the same data becomes training input for agents, feedback for decisions, and control signals for action.
None of this works if reasoning is separated from telemetry. Autonomous operations require AI to operate on native system data, not abstractions layered on top.
If you want to see how Edwin AI uses LogicMonitor logs to deliver evidence-backed RCA—and how that same approach supports ongoing AI investigation and autonomy—request a demo. We’ll show how investigation changes when AI is built on recorded system behavior instead of inference.
By Margo Poda
Sr. Content Marketing Manager, AI
Margo Poda leads content strategy for Edwin AI at LogicMonitor. With a background in both enterprise tech and AI startups, she focuses on making complex topics clear, relevant, and worth reading—especially in a space where too much content sounds the same. She’s not here to hype AI; she’s here to help people understand what it can actually do.
Disclaimer: The views expressed on this blog are those of the author and do not necessarily reflect the views of LogicMonitor or its affiliates.