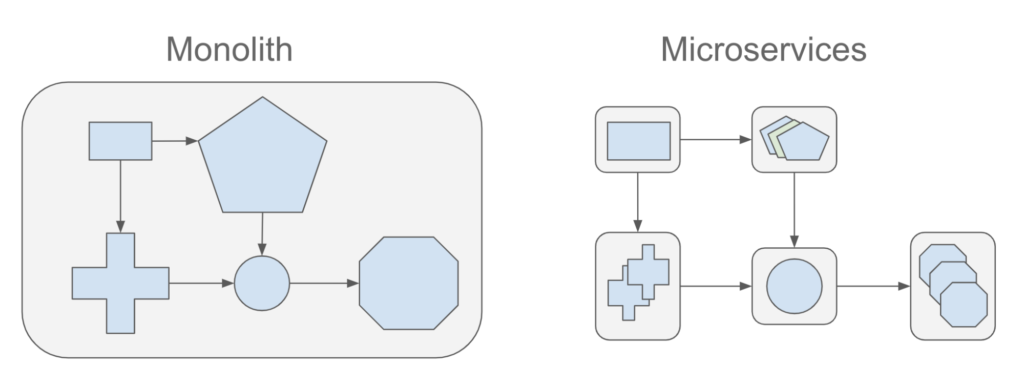
Today, monolithic applications evolve to be too large to deal with as all the functionalities are placed in a single unit. Many enterprises are tasked with breaking them down into microservices architecture.
At LogicMonitor we have a few legacy monolithic services. As business rapidly grew we had to scale up these services, as scaleout was not an option.
Eventually, our biggest pain points became:
The cost of scaling up a service was high.
New features required ML/AI algorithms that were not optimized in Java.
For any new feature, the overhead of QA, deployment, and maintenance was huge.
Onboarding a new engineer was long and painful.
In this article, we will cover the benefits of both Monolith and Microservices, our specific requirements from Microservice, Kafka Microservice communication, and how to distribute data and balance the load.
Monolith vs. Microservices
A monolith application is an application with all the functionalities built in a single unit. Microservice applications are the smaller services that break down the single unit. They run independently and work together. Below are some benefits of both Monolith and Microservices.
Monolith:
As long as the application complexity is not high and fairly static and the number of engineers is “small”, then it is:
Easier to Debug and Test – You can run end-to-end testing much faster.
Simpler to Deploy – There’s only one deployment.
Simpler to Develop – All of the knowledge usually exists in a few key engineers.
Easier to Manage – Logging and performance monitoring are easy to set.
Microservices:
Microservices provide many advantages in building scalable applications and solving complex business problems:
Simple – Each microservice has a very specific job and is not concerned with the jobs of other components.
Performance Optimized – You can isolate hot services and scale them (in/out or up/down) independently of the rest of the applications.
Simple to QA and Test – Each service can be self-testable with well-defined input and output.
Decoupled – Decoupled services are also easier to recompose and reconfigure to serve the purposes of different apps (for example, web clients and public API).
Different Development Stacks – Each service can be implemented with the most suitable development stacks for itself (for example, we are using Python Java and Go).
Better Resilience and Fault Tolerance – Isolated modules will prevent a bug in one module from bringing down the entire service.
Easy to Deploy – The development and deployment time of a microservice is much shorter.
Microservice Requirements
LogicMonitor processes billions of payloads (e.g data points, logs, events, configs) per day. The high-level architecture is a data processing pipeline.
Our requirements for each microservice in the pipeline are:
Each microservice component should be stateless (if needed, the state is kept in datastore, e.g. Redis, Kafka)
Each microservice component should complete its task in X ms
Each microservice is k8s container-based that can dynamically scale out/in
End to End pipeline should be less than X ms
Microservice warm-up time should be less than X ms
Each Microservice is limited by X CPU cores and Y GB Memory
Cost (infrastructure/tools) should be less than $X per year per payload
Today we have microservices implemented in Java, Python, and Go. Each microservice is deployed to Kubernetes clusters and can be automatically scaled out or in using Kubernetes’ Horizontal Pod Autoscaler based on a metric.
For Java, after evaluating multiple microservice frameworks, we decided to use Quarkus in our new Java microservices. Quarkus is a Kubernetes-native Java framework tailored for Java virtual machines (JVMs).
To learn more about why we chose Quarkus, check out our Quarkus vs. Spring blog.
How to Distribute Data and Balance the Load
We have implemented microservices to process and analyze the data points that are monitored by LogicMonitor. Each microservice performs a certain task on the incoming data.
After evaluating a few technologies, we decided to use Kafka as the communication mechanism between the microservices. Kafka is a distributed streaming message platform that can be used to publish and subscribe to streaming messages. Kafka provides a fast, scalable, and durable message platform for our large amount of streaming data.
How to Partition Kafka Topics
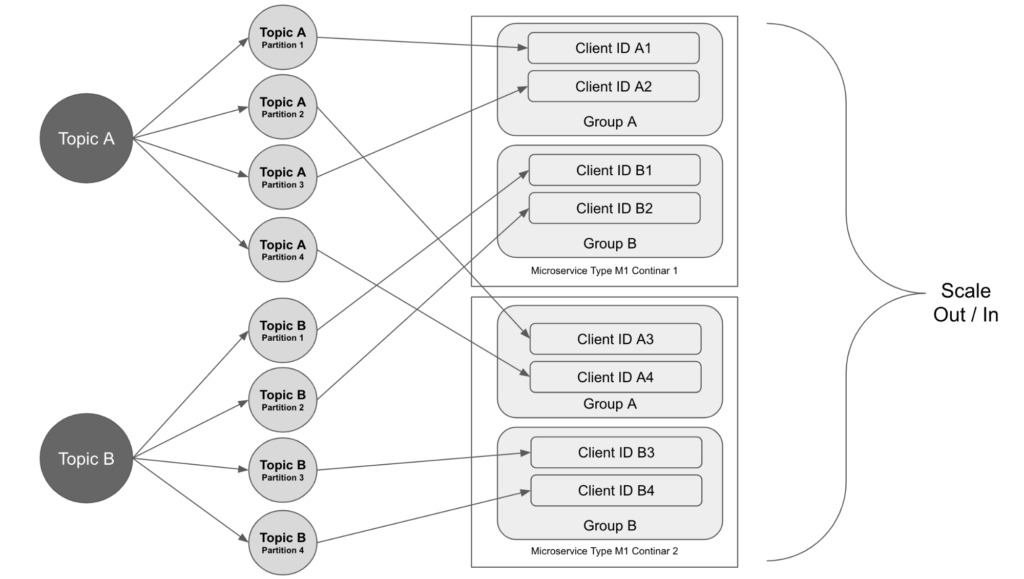
Our microservices use Kafka topics to communicate. Each microservice gets data messages from some Kafka topics and publishes the processing results to some other topics.
Each Kafka topic is divided into partitions. The microservice that consumes the data from the topic has multiple instances running and they are joining the same consumer group. The partitions are assigned to the consumers in the group. When the service scales out, more instances are created and join the consumer group. The partition assignments will be rebalanced among the consumers. Each instance gets one or more partitions to work on.
In this case, the total number of partitions decides the maximum number of instances that the microservice can scale up to. When configuring the partitions of a topic, we should consider how many instances of the microservice that will be needed to process the volume of the data.
Distribute and Balance the Data
When a microservice publishes a data message to a partition of a Kafka topic, the partition can be decided randomly or based on a partitioning algorithm based on the message’s key.
We chose to use some internal ID as the message key so that the time-series data messages from the same device can arrive at the same partition in order and processed in the order.
The data on a topic across the multiple partitions sometimes can be out of balance. In our case, some data messages require more processing time than others and some partitions have more such messages than the other partitions. This leads to some microservice instances falling behind. To solve this problem, we separated the data messages to different topics based on their complexity and configure the consumer groups differently. This allows us to scale in and out services more efficiently.
Where to Keep the Microservice State
Some of our microservices are stateful, which makes it challenging to scale. To solve this problem, we use Redis Cluster to keep the states.
Redis Cluster is a distributed implementation of multiple Redis nodes which provides a fast in-memory data store. It allows us to store and load the algorithm models fast and can scale-out if needed.
Summary
Migrating Monolith to microservices is a journey that in some cases can take a few years.
At LogicMonitor we started this journey two years ago. The return on the investment is not arguable. The benefits include but are not limited to:
The productivity of the development is increased and the technical debt is reduced.
The services are more resilient and perform better.
The continuous deployment is easier and there is no downtime of the services.
It’s easier and more efficient to scale the services.
Disclaimer: The views expressed on this blog are those of the author and do not necessarily reflect the views of LogicMonitor or its affiliates.