Why Teams Are Looking for a SolarWinds Alternative
Evaluating a SolarWinds alternative rarely starts with one event. It begins when legacy monitoring no longer matches how hybrid incidents unfold across cloud, SaaS, and internet dependencies. Explore the operational and architectural reasons teams are moving toward modern observability.
Modern hybrid infrastructure has outgrown the limits of legacy, module-based monitoring.
Managing separate modules for network, server, and applications creates a “care-and-feeding” burden that distracts teams from actual incident response.
Legacy tools often surface symptoms within your own infrastructure but remain blind to external SaaS, CDN, and Internet dependencies.
Between supply-chain security concerns and shifts in vendor direction, IT leaders are prioritizing platforms built on a foundational SaaS architecture.
Evaluate alternatives based on their ability to unify disparate signals into a single source of truth rather than simply adding more point tools.
Teams rarely start evaluating a SolarWinds alternative because of one event. More often, the search starts when the platform no longer matches how incidents actually happen across hybrid infrastructure, applications, SaaS services, and Internet dependencies.
For many organizations, that reassessment has been building for years. Fragmented visibility, alert volume, and blind spots create daily operational friction across cloud environments and external dependencies that teams don’t fully control. While the Turn/River acquisition of SolarWinds in early 2025 gave some customers another reason to examine vendor direction, the instinct to look for an alternative was already there.
And according to the 2026 Observability & AI Outlook, 67% of IT leaders are likely to switch observability platforms within the next two years. The more useful question isn’t just why teams are watching SolarWinds now, but why so many had already reached the point where they were open to replacing it.
Why SolarWinds Customers Are Reassessing Their Options
Recent changes in SolarWinds’ pricing, licensing, and broader vendor direction have given some customers a reason to reassess their options. In public customer forums, some users have described steep renewal increases, including one THWACK post that cited a quote at 225% of the previous renewal, while SolarWinds’ own product-specific terms address scenarios where legacy perpetual on-prem products are being converted to subscription. For teams that rely on monitoring every day, those kinds of changes can be enough to prompt a broader evaluation of whether the platform still fits their operational and business requirements.
That doesn’t mean every evaluation starts with pricing or licensing alone. For many teams, those changes simply create a natural moment to step back and ask whether their current approach still fits the way they operate. In many cases, the reassessment is less about any single business event and more about whether the platform continues to deliver the visibility, usability, and long-term operational fit teams need.
Why Teams Started Looking for a SolarWinds Alternative Before the Acquisition
Many legacy, module-based monitoring environments create growing overhead over time. Separate tools for network monitoring, server monitoring, flow analysis, and configuration management give teams a broken view of the environment and force them to constantly jump between tools.
As monitoring estates sprawl across products and teams, the care-and-feeding burden compounds. The problem isn’t just the number of components; it’s that teams spend more time managing the monitoring environment itself while working harder to understand what’s happening during an incident. The search for an alternative began with this daily experience of operating a stack that had become harder to manage and harder to trust under pressure.
Trust Concerns Added to an Existing Operational Problem
The 2020 SolarWinds supply-chain breach made trust concerns worse. Many IT and security leaders have spent the years since reassessing how deeply embedded their infrastructure management software is and how it’s governed. CISA’s original security advisories on the breach forced a global conversation about the risks of deeply embedded management code.
Once teams begin asking whether the platform is still the right fit for their operations, they usually don’t separate trust questions from architecture questions. For some organizations, the issue is governance; for others, it’s resiliency. For many, it’s both. The demand for an alternative isn’t only about product capability—it’s about whether the platform still feels like the right long-term tool to rely on.
How Legacy Monitoring Creates Operational Drag
Organizations managing tool sprawl across infrastructure, application performance, logs, and user experience products face fragmented visibility and slower incident response. This matches the experience of using legacy environments: a collection of modules with a front-end layer that’s supposed to unify them but rarely does in practice.
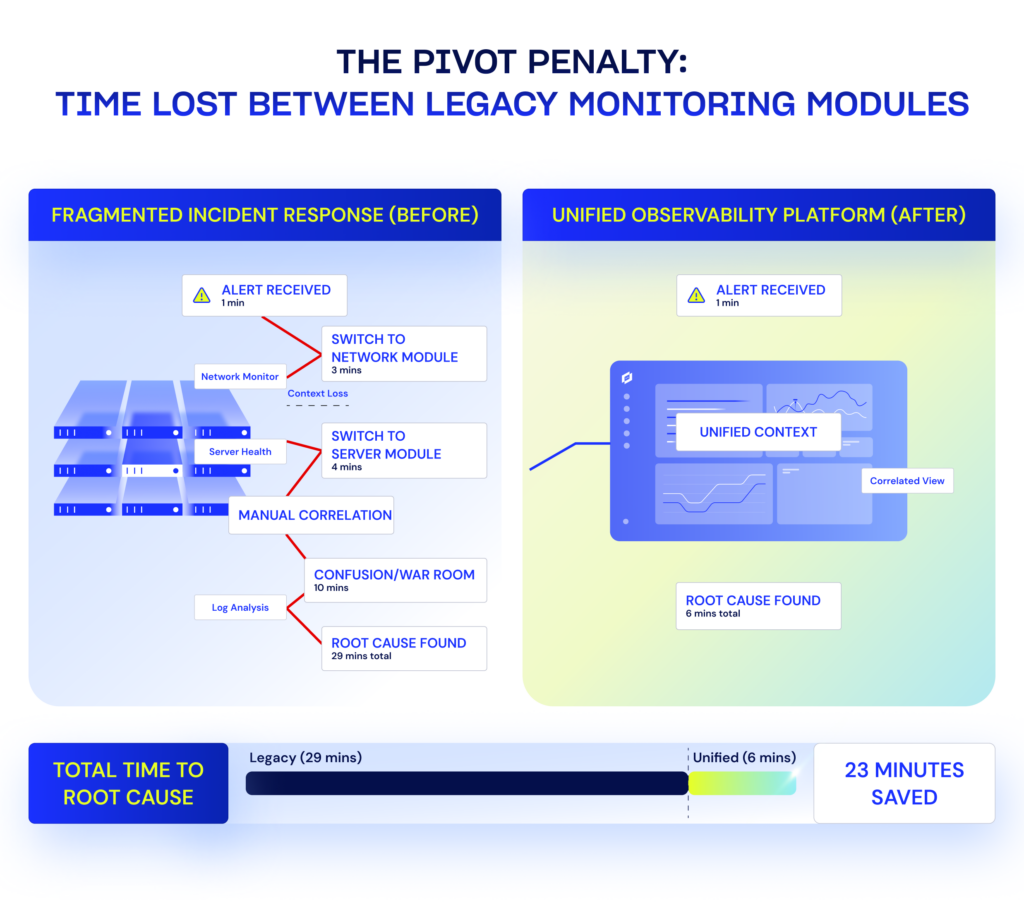
Manual correlation is the hidden tax of a legacy monitoring stack. While siloed modules (NPM, SAM, VMAN) require teams to manually bridge context gaps, a unified architecture correlates signals at the source, cutting the “Pivot Penalty” out of incident response.
That’s where the extra work starts. Teams switch between views and compare signals across tools, spending time aligning context that should already be connected. Maintenance overhead rises at the same time incident response gets harder. This burden comes from assembling coverage through acquisition instead of designing it as a unified platform—limitations that become even more obvious in modern, hybrid environments.
The problem becomes more obvious in hybrid environments, especially when teams are responsible for a mix of on-prem infrastructure and fast-changing public cloud services. What worked in a more static environment often becomes harder to manage when visibility has to extend across data centers, AWS, Azure, and the services that connect them.
Legacy monitoring models often struggle to keep pace with cloud change, while stronger alternatives make hybrid coverage easier through native integrations, automatic discovery, and a more unified operating model. As environments become more distributed, teams need cloud coverage that is easier to deploy, easier to maintain, and better at keeping pace with change. Native cloud integrations, automatic discovery, and unified visibility across on-prem and cloud resources make it easier to understand what is happening without adding more tools or more manual overhead.
For many teams, that’s what turns monitoring gaps into an operational issue. The challenge is not just seeing more infrastructure. It is being able to follow issues across hybrid environments in one place, with enough context to investigate quickly and enough flexibility to scale as the environment changes.
The Real Problem Is Bigger Than the Tool
At this point, many teams shift the conversation. They stop asking whether they need a few more features and start asking whether the architecture behind the platform is creating the problem. They move toward asking how much work the platform creates when something breaks.
Instead of adding another point tool to close another gap, buyers begin looking for a platform that can connect infrastructure, application, and Internet signals in one place to reduce manual correlation. Real-world transitions, like Coca-Cola Consolidated, show that moving to a unified platform can help teams resolve complex issues 30 minutes faster. This explains why some teams outgrow legacy monitoring in stages: first the platform becomes harder to manage, then incidents become harder to explain, and eventually the cost of keeping the current model outweighs the cost of changing it.
What Teams Should Look for in a SolarWinds Alternative
For many organizations, the better alternative isn’t another collection of overlapping tools. It’s a unified observability platform that can connect visibility, intelligence, and controlled automated action across the full path from user to code.
That means asking harder questions about architecture, extra admin work, and how incidents are handled in practice. The goal is to find a platform that can connect disparate signals, reduce manual correlation, and support hybrid operations without adding more administrative weight.
The Right SolarWinds Alternative Should Reduce Work, Not Add to It
The strongest reason teams switch isn’t novelty; it’s relief. They want a platform that makes monitoring easier to operate, incidents easier to investigate, and visibility easier to trust across a complex environment. The real standard for an alternative is not whether it replaces every legacy module one for one, but whether it reduces the extra work that made teams start looking in the first place.
Stop managing monitoring modules and start seeing your entire hybrid stack in one place.
Watch a demo to see how a SaaS-native platform reduces administrative weight and speeds up incident response.