Go behind the upgrade and meet the new Edwin AI agents enabling agentic workflows to see how they’re cut false alerts by 80%
Downtime is more than an inconvenience these days, nor is it solely a problem for the ITOps team. Since every organization is a digital business, downtime can cost millions of dollars per hour, stall innovation, and erode customer trust. Yet most IT teams are still trapped in reactive mode, scrambling across fragmented tools and drowning in alert fatigue.
That model no longer works. The future of IT is about foresight, not firefighting.
That is why we are proud to announce the next chapter of the LogicMonitor Envision platform. Starting today, we are expanding our agentic AI Ops product, Edwin AI, launching LM Uptime and Dynamic Service Insights, and introducing a simplified platform pricing model. And coming in October, we will extend our comprehensive coverage across the modern data center even further with native monitoring for Oracle Cloud Infrastructure (OCI). Together, these innovations redefine what observability means in the AI era, giving enterprises the confidence to anticipate issues, protect margins, and keep their businesses resilient.
What’s New
Expanded Edwin AI (Available Now)
Edwin AI is now more powerful than ever, delivering predictive resilience at scale. Customers are seeing more than 80% fewer false alerts and 67% fewer incidents. The product also automates the first steps of remediation, helping teams shift from reactive operations to proactive resilience and freeing valuable resources for innovation.
LM Uptime and Dynamic Service Insights (GA Today)
With LM Uptime and Dynamic Service Insights, observability goes beyond infrastructure metrics to map performance directly to business services. Whether it is a customer portal, payments flow, or core ERP system, you can now see how underlying infrastructure issues affect business outcomes. This service-level clarity helps maintain SLAs, prevent small anomalies from becoming outages, and protect the customer experience across on-premises, cloud, and edge.
Explore LM Uptime’s web and endpoint monitoring that integrates with services, dashboards, and alerts.
Get the details on why Dynamic Service Insights makes it easier than ever to show IT’s contribution to revenue and resilience.
Oracle Cloud Infrastructure (GA in October)
Our upcoming OCI monitoring release will extend LogicMonitor’s multi-cloud coverage to AWS, Azure, GCP, and now OCI. By bringing OCI telemetry into the same LogicMonitor Envision platform, you gain unified visibility across every major cloud provider. This reduces tool sprawl, simplifies multi-cloud operations, and ensures that every workload can be monitored in context.
Check out OCI monitoring: full visibility for AWS, Azure, GCP, and Oracle Cloud—together in one platform
Simplified Pricing With Hybrid Units
We are introducing a new pricing model designed around flexibility and predictability. Hybrid Units adapt across devices, cloud instances, wireless access points, and PaaS resources. Whether you are shifting workloads to the cloud or expanding wireless infrastructure, you can scale without renegotiating contracts or adding complexity. Packages (Essentials, Advanced, Signature) make it easy to start where you are and grow when you need to.
Learn how Hybrid Units work through flexible, predictable pricing that scales with your hybrid estate.
Why It Matters
- Anticipate, don’t react → Spot emerging failures before they disrupt operations.
- See one truth → Unify metrics across on-premises, cloud, and edge in a single view.
- Move from insight to action → Automate the first steps of remediation to close the gap from anomaly to resolution.
- Turn consumption into renewal → Optimize compute, cooling, and energy to build greener, more sustainable operations.
What’s Next
This announcement builds upon our platform vision and represents another step toward the future of resilient IT. With Edwin AI, LM Uptime, and Dynamic Service Insights available today, simplified pricing to make adoption easier, and OCI support arriving in October, LogicMonitor continues to help enterprises anticipate issues, protect margins, and step confidently into the AI era.
Your front-row seat to resilient IT.
Sign up for our September 24 webinar and get a live demo of what’s new from our experts.
The future of IT operations isn’t about reacting faster but anticipating what’s next. With complex, hybrid environments now the default, we believe our customers deserve clarity, flexibility, and the ability to scale without friction.
That’s why LogicMonitor is introducing new platform pricing. It’s built to simplify how you buy, deploy, and extract value from observability across every layer of your hybrid infrastructure.
Why We’re Evolving Pricing
Customer-first isn’t new for us, it’s who we are. From day one, our pricing has been predictable, transparent, and free from “gotchas” that too often come with enterprise software. No hidden modules, no surprise fees. Just straightforward licensing that grows with you. That commitment isn’t changing.
What is changing is the world our customers operate in. Hybrid environments are now the backbone of modern IT, spanning on-premises data centers, multi-cloud deployments, edge computing, and everything in between. But pricing models in our category haven’t evolved at the same pace, and they’re often fragmented, unpredictable, and hard to scale.
Today, we’re changing that. Our new pricing model is a natural evolution of the principles we’ve always stood for: simplicity, flexibility, and fairness.
In this new model, we’re shifting away from product-by-product licensing to three packages: Essentials, Advanced, and Signature. Each enabled by a flexible Hybrid Unit.
The Power of the Hybrid Unit
The Hybrid Unit is at the core of this change. It’s a single, flexible measure of consumption that adapts to your environment, not the other way around.
One Hybrid Unit can represent:
- one monitored device
- one IaaS instance
- five wireless access points
- or seven PaaS resources
But the real value isn’t in the math, it’s in the freedom it gives you.
- Scenario 1: Shifting from servers to cloud. Imagine you’re running 200 on-prem servers today. Next quarter, half of those workloads move into AWS. With traditional licensing, you’d need to get your purchasing team involved, renegotiate contracts or request budget approval for new SKUs. With Hybrid Units, nothing changes. The same 200 Hybrid Units seamlessly cover your new AWS instances. Procurement isn’t slowed down, and your migration stays on schedule.
- Scenario 2: Scaling modern apps. A development team embraces Kubernetes and rolls out thousands of new containers. Instead of worrying about licensing each PaaS instance, your Hybrid Units absorb that growth. Your team focuses on innovation, not another vendor contract cycle and negotiation to estimate K8s usage multiple years into the future.
- Scenario 3: Growing wireless footprints. Let’s say your campus is expanding, and you’re adding hundreds of new wireless access points. Instead of scrambling to buy a new SKU, your existing Hybrid Units flex to cover them. No disruption, no delays.
In practice, this means less time managing contracts and more time driving innovation. You gain the predictability of a standardized model with the flexibility to adapt as your infrastructure evolves.
The Packages at a Glance
- Essentials: Foundational monitoring and LM Logs, ideal for small to mid-sized teams managing up to 1,000 devices.
- Advanced: Comprehensive hybrid observability, including everything in Essentials, plus LM Uptime, Dynamic Service Insights, and Data Publisher.
- Signature: Full-stack visibility for complex enterprises, with SaaS Monitoring, Cost Optimization, and ServiceNow CMDB integration.
For Advanced and Signature tiers, you can easily move into agentic AIOps and prepare for autonomous IT with Edwin AI, our AI-native event intelligence engine that cuts through noise and accelerates root cause analysis.
And every package makes it easier than ever for IT teams to accelerate their troubleshooting by including LM Logs because context-rich troubleshooting should never be optional.
What This Means for You
Whether you’re running lean or scaling globally, this model is designed to meet you where you are:
- Predict and prevent issues before they hit production with Edwin AI’s proactive intelligence.
- Monitor everything—from data centers to cloud-native apps—in a single, unified platform.
- Save time on procurement and renewals with straightforward packages and consistent unit pricing.
- Scale your coverage without scaling complexity—the Hybrid Unit gives you flexibility across environments.
- Drive ROI from day one with pre-bundled capabilities that reduce MTTR and eliminate tool sprawl.
These new packages aren’t mandatory, they’re an option. For some, Essentials will be a cost-effective way to stay protected. For others, Advanced and Signature will unlock new paths to automation and resilience. But in every case, it’s built around you: your hybrid journey, your scale, and your outcomes.
Looking Ahead
Observability is no longer a niche category. It’s central to how resilient, sustainable, and secure digital infrastructure gets built. With this new pricing model, we’re making it easier for customers to consolidate tools, reduce noise, and get ahead of what’s next.
We’re excited to bring this to market. And as always, we’re building alongside you. Focused together on delivering platform value, unlocking automation, and helping IT teams move with more confidence into the AI-powered future.
Explore our new pricing packages.
If you’re in IT operations, you’ve likely faced the disconnect firsthand: your dashboards say everything’s green, but your business stakeholders are asking why the website is slow, the customer portal is timing out, or a regional service is underperforming. Your team is usually on top of issues, such as monitoring infrastructure health, resolving alerts, and keeping systems online. But the business isn’t looking at device uptime. They’re thinking in terms of services and outcomes that affect customer experiences and the bottom line.
That’s why we built Dynamic Service Insights (DSI)—one of the latest product enhancements from LogicMonitor that helps ITOps teams think beyond devices and finally connect their work to what the business actually cares about.
What Is Dynamic Service Insights?
Dynamic Service Insights delivers clear, scalable service-level visibility by intelligently grouping infrastructure components using tags and mapping them to the services they support. It helps operations teams shift from traditional, device-centric monitoring to a service-first observability model.
Previously, creating services meant manual setup and constant upkeep. It was difficult to scale services and oversee multiple services at once. Now, rules and tags keep services aligned and updated automatically—no queries, no custom models.
Why It Matters Now
IT teams are thinking about observability beyond whether servers are online. They’re tying infrastructure performance to business impact. Based on customer interactions, we are embarking on this strategic shift in how we think about observability.
CIOs, CTOs, and stakeholders across the enterprise want to know what services are impacted by IT infrastructure, how those issues affect users or revenue, and whether the investment in IT is delivering measurable results.
With DSI, ITOps teams finally have the tools to provide those answers. You can show leadership which services are healthy, which are degraded, and how quickly you’re responding to disruptions. This turns IT from a perceived cost center into a valuable business enabler.
How Dynamic Service Insights Works
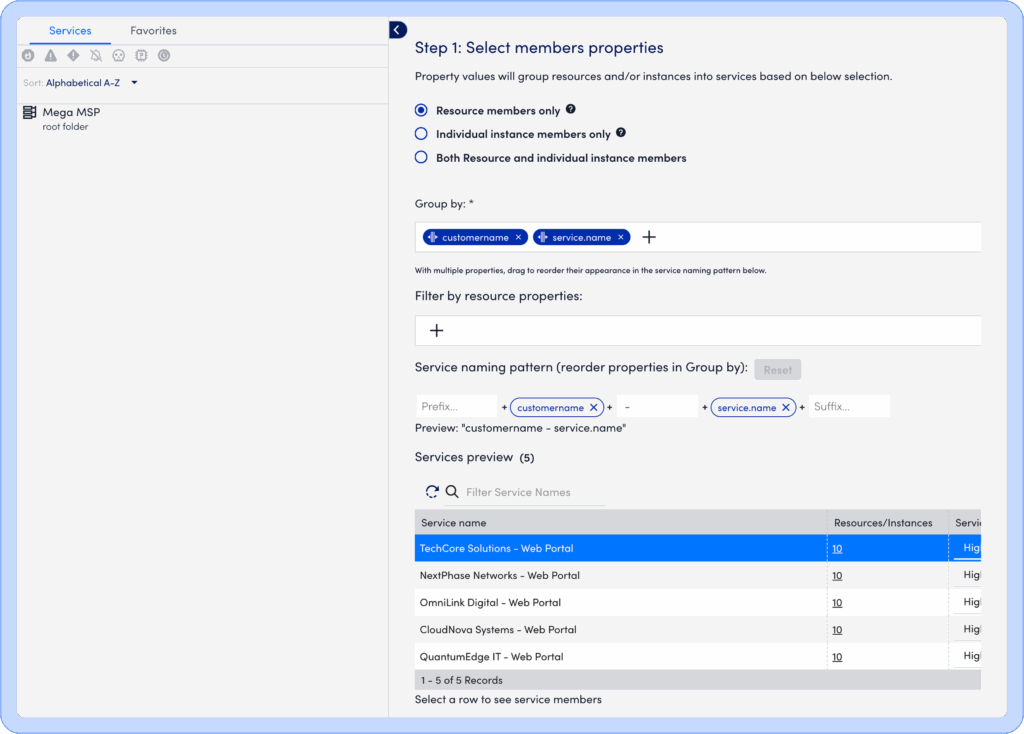
DSI is built on powerful, flexible automation. Service creation is rule-based and tag-driven, making it easy to onboard services at scale. Whether you’re tracking a customer-facing app, a regional compute cluster, or a core backend system, you can define it in seconds using tag properties already in your LogicMonitor Envision environment.
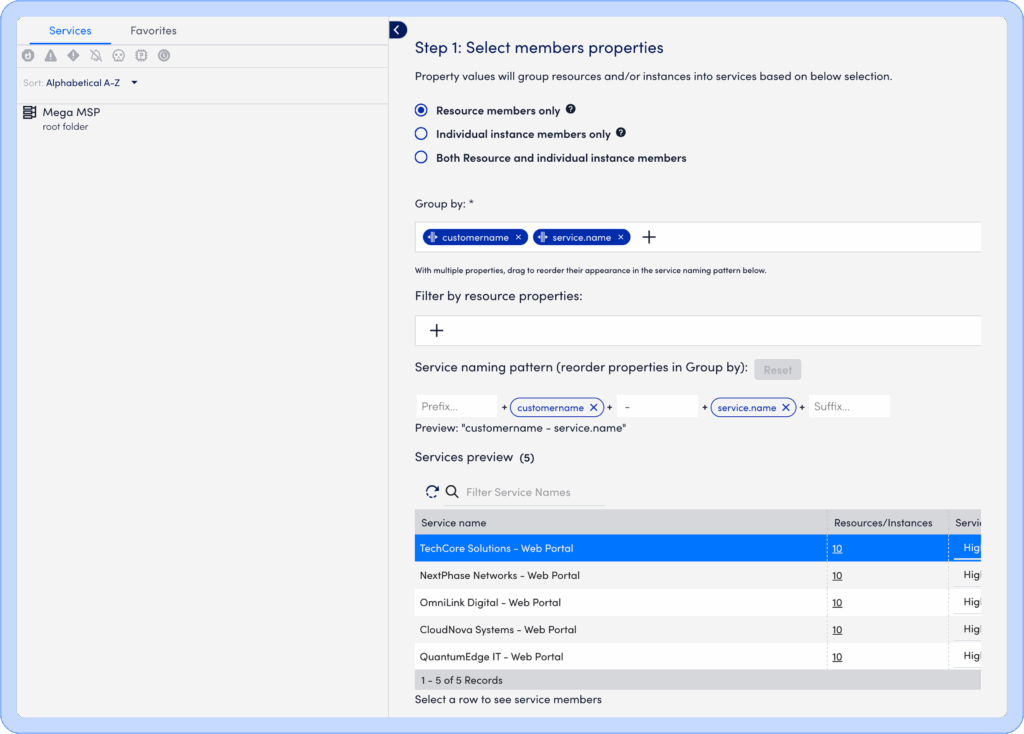
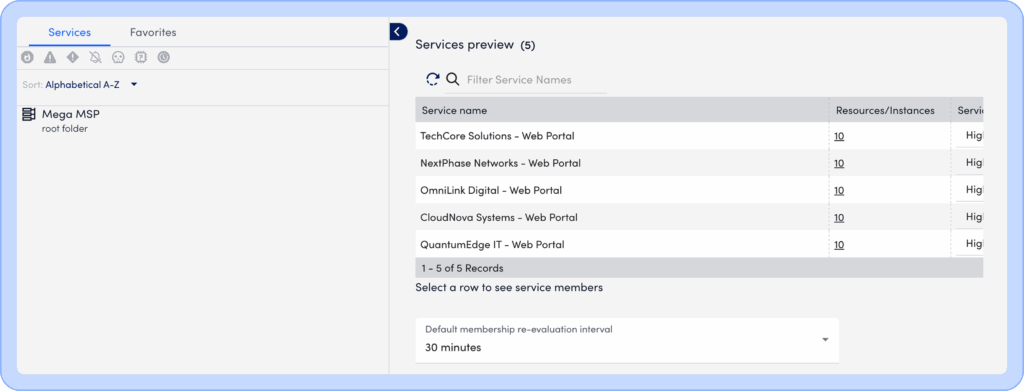
Once defined, DSI automatically selects relevant metrics using intelligent filters and workflows, surfacing key performance indicators that reflect true service health. Each service comes with a configurable dashboard, which can show real-time status, KPI trends, and degradation insights such as the percentage of members down, giving you immediate clarity without additional configuration.
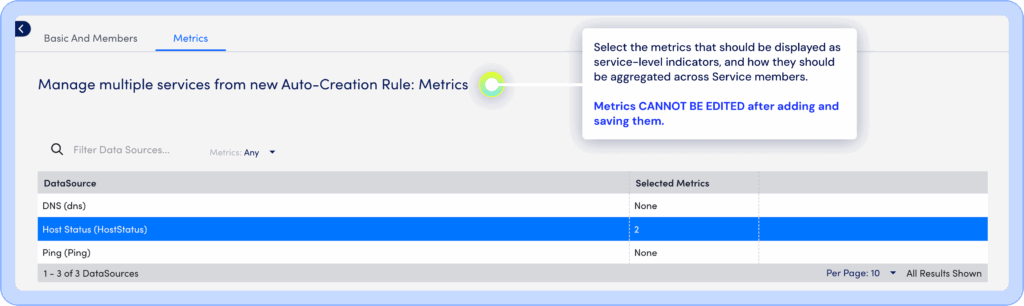
Troubleshooting is faster too with direct drill-down from a high-level service alert into the logs, metrics, and topology for shorter time-to-resolution, and improved root cause analysis.
How We Stack Up Against the Competition
What sets DSI apart from other solutions is its simplicity and speed-to-value. Unlike offerings from Splunk or ScienceLogic, which often require complex modeling or extensive tuning, DSI delivers extensive value with easy configuration and tagging. You don’t need to build custom queries or maintain brittle service models, and it’s ready for any size team.
Pricing and Getting Started
DSI, available in packs of 25 services and included with LogicMonitor Advanced and Signature platform packages, makes it easy to start small—like with an AWS environment, storage layer, or regional cloud deployment—and expand into business-facing services as you see results.
With the right tagging strategy and a few simple rules, you can model your most important services in a matter of minutes, then use those insights to report to leadership, optimize resources, maintain uptime and reduce incident noise.
A New Way to Tell the Story of IT
In a world where IT is increasingly expected to drive business results, DSI helps you make the case. It’s how you show that uptime is measured beyond metrics and 9’s, but with measurable business outcome.
If you’re ready to elevate your monitoring strategy and speak the language of the business, talk to your LogicMonitor team about getting started with DSI today.
Ready to explore Dynamic Service Insights within LogicMonitor Envision?


These days many IT Operations teams have gotten very sophisticated in the ways they talk about availability, SLAs, SLOs (Service Level Objectives), and even more nuanced measures of reliability. But when websites or services go down, even briefly, “uptime” is still the number you’re explaining to execs, customers, or incident review boards.
In reality, keeping a service up is table stakes. It’s the minimum expected from any ops team. But hitting that 99.99% isn’t automatic. That’s why we built LM Uptime: to make it easier than ever before for ITOps to monitor web and endpoints.
What is LM Uptime?
LM Uptime integrates web and ping checks directly into LogicMonitor’s unified observability platform, LM Envision, bringing full-stack, platform-native visibility to your web and endpoint monitoring. You can monitor your websites and services–whether external or internal –on your private network, from worldwide locations, and from within your private networks.
Why It Matters Now
Downtime can be a significant financial cost for your organization. It also erodes trust. As your infrastructure grows increasingly complex and more distributed, your critical services span cloud, on-prem, and third-party systems. You need a solution that can verify availability from where it matters most: the user’s point of view.
LM Uptime gives your team the proactive edge. Whether you’re defending uptime, preparing for audits, or responding to incidents, this solution ensures you’re never in the dark when it matters most.
LM Uptime delivers:
- Smarter Monitoring: All datapoints support alerting, with dynamic thresholds, flexible graphing, and full dashboard/widget compatibility.
- Operational Simplicity: Alert routing, group inheritance, and property management now work just like with devices, reducing support burden and setup time.
- Service Integration: Uptime checks can be added to Services, linking performance to business outcomes—something other tools don’t do.
- Future-Readiness: This shift sets the stage for better correlation, reporting, and AI insights across all resources.
How LM Uptime Works
LM Uptime executes checks against your website and services from LogicMonitor’s worldwide resource monitoring locations, delivering an outside-in view of your externally-accessible services. For websites and resources available only within your private networks, LM Uptime runs checks from inside the network using the existing collectors in LogicMonitor.
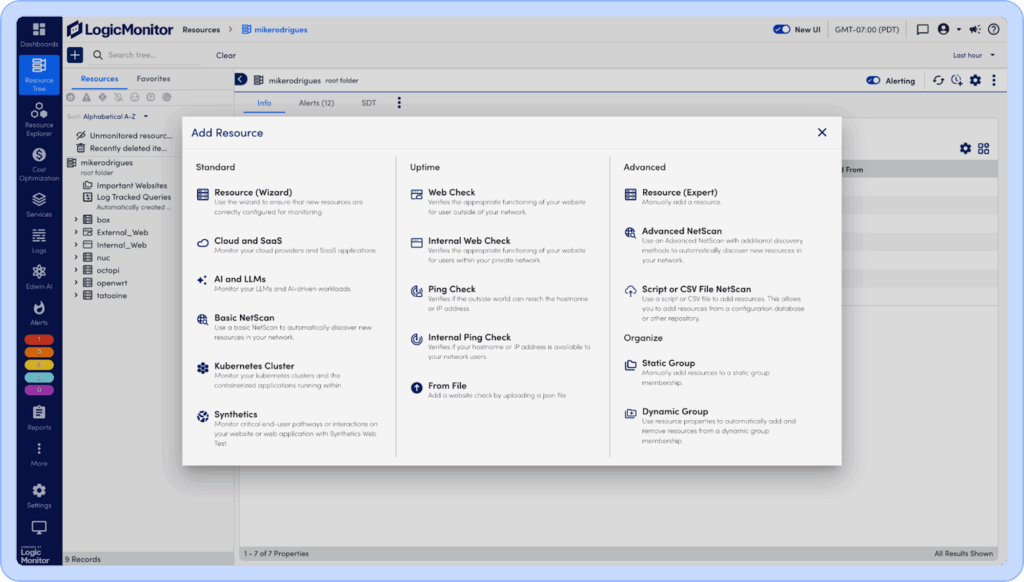
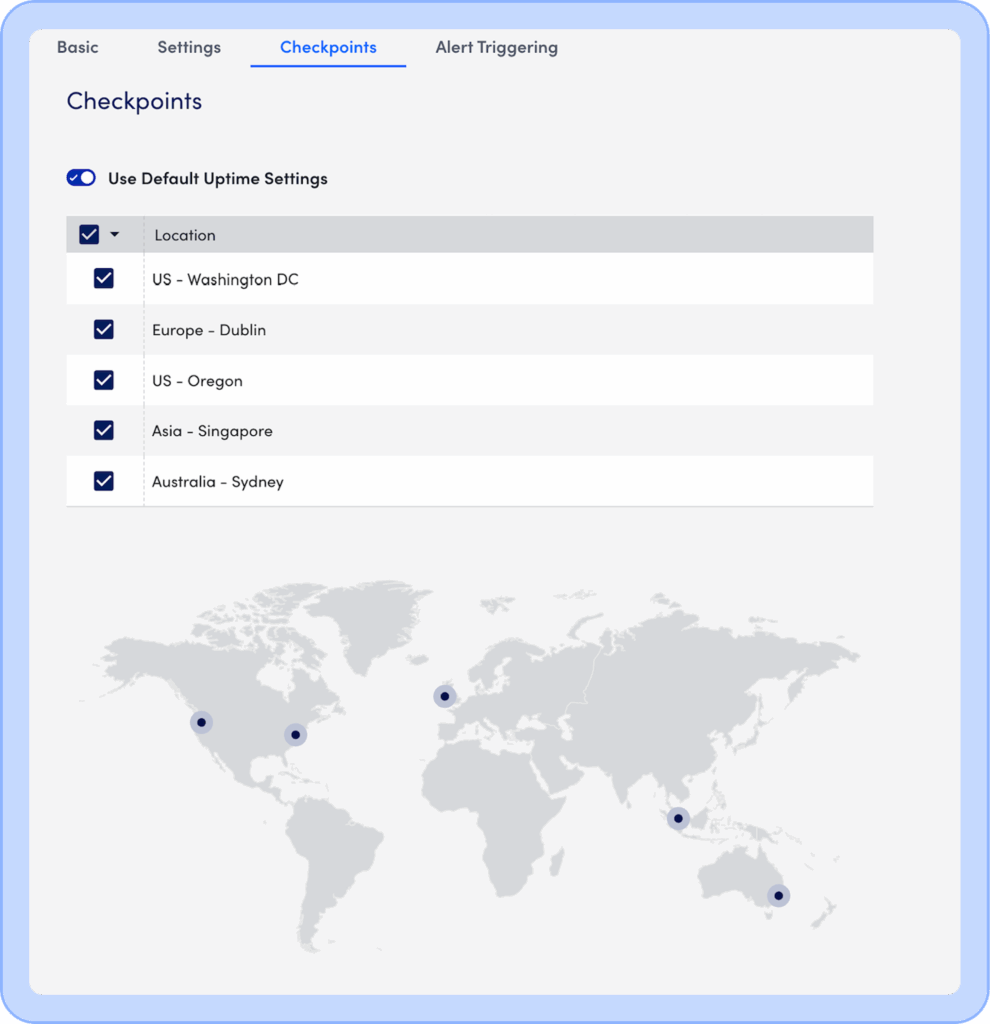
To create an LM Uptime Check, it’s as easy as adding any other resource. Go to the Resource Tree and press the Add Resource (+) button and choose a type of Uptime Check:
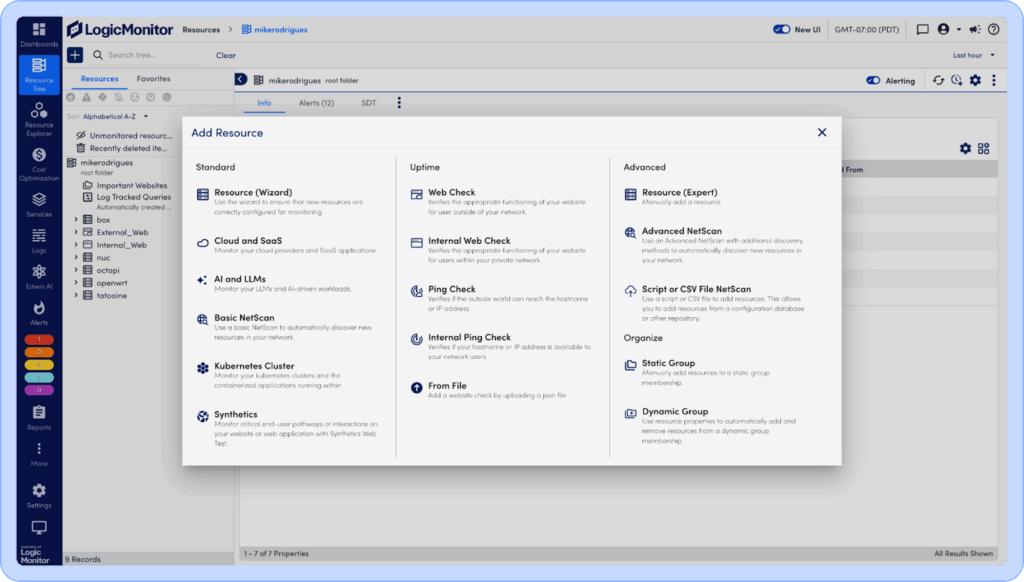
For web and ping checks, you create checks that are executed from outside of your network, and internal checks that are performed from within your private network.
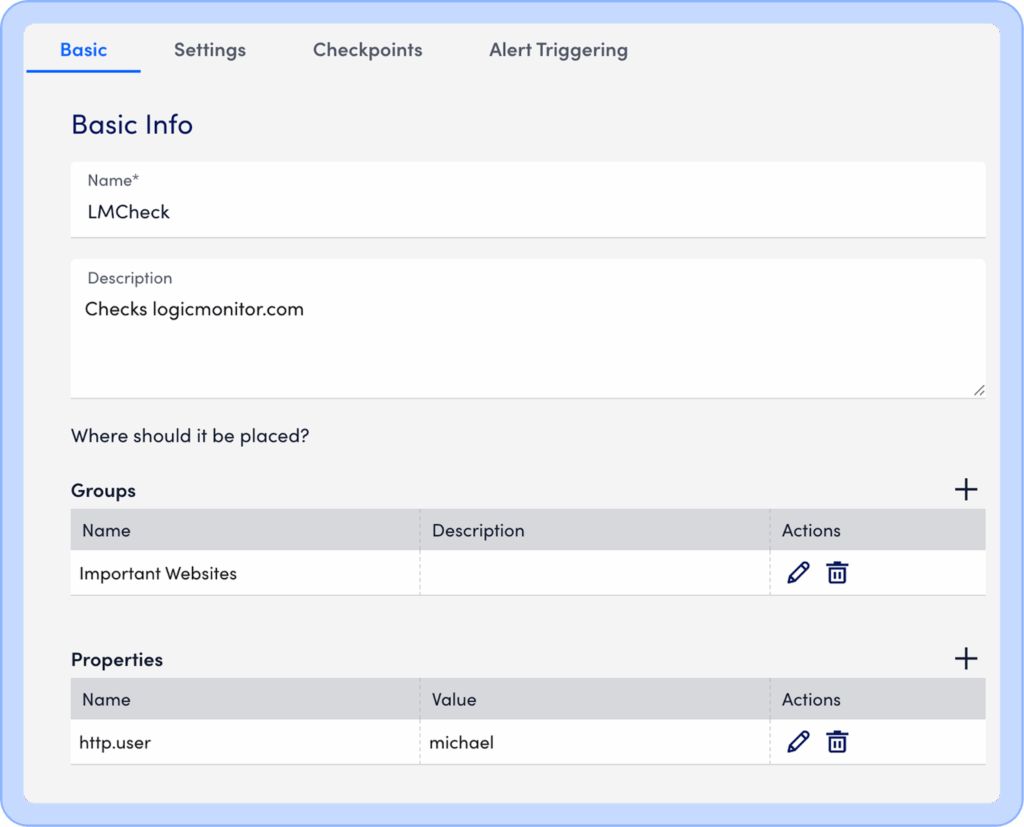
Next set the basic information for the check, including the base URL and paths to check.
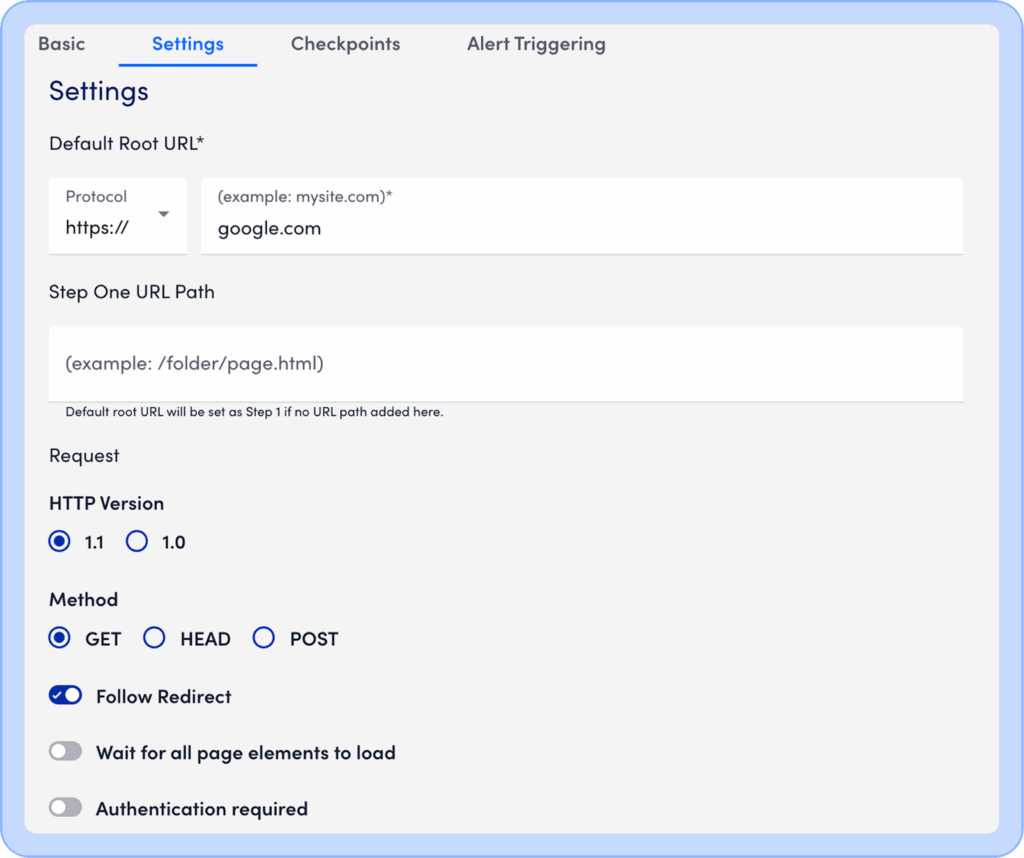
Add steps to the check
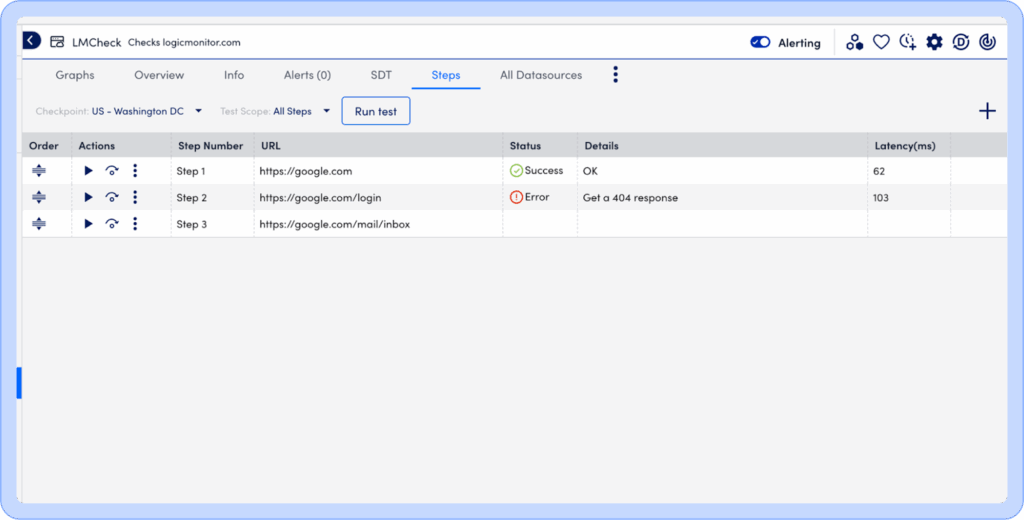
Then pick the locations and the trigger conditions:
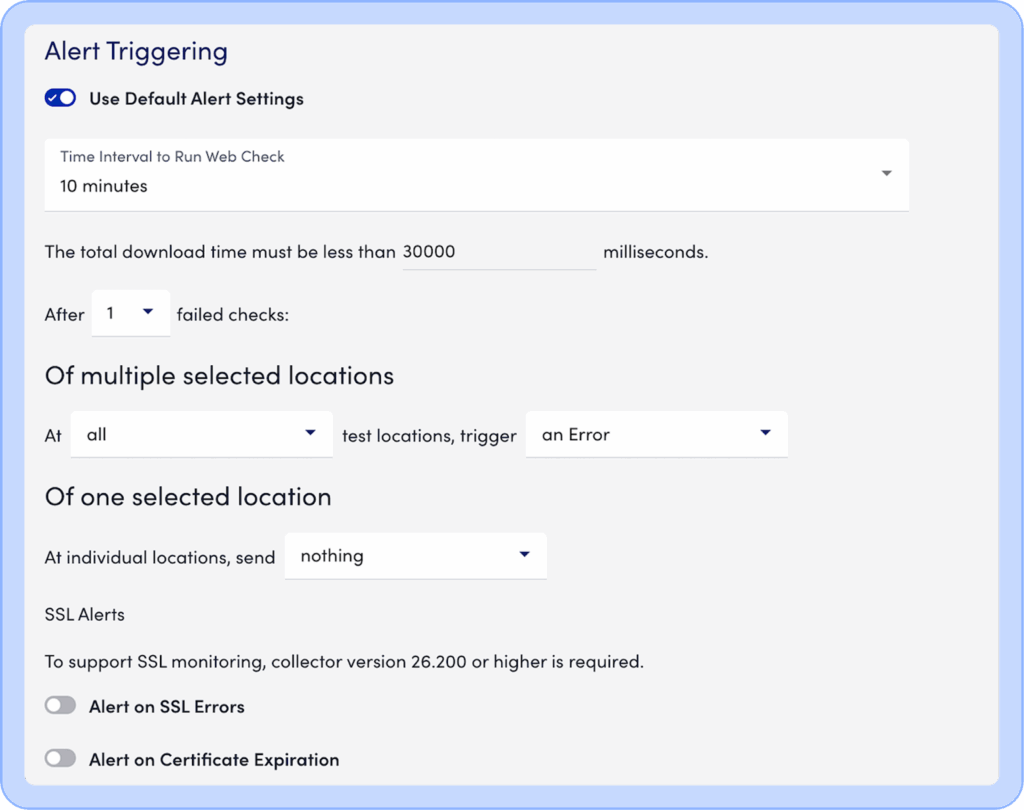
Once these are set up, you will be able to visualize and monitor your websites as resources, which gives you:
- More flexible alert tuning across a wider set of datapoints
- Same property system as Resources
- Static & Dynamic Grouping with all your other Resources
- Dashboard widgets that weren’t compatible with legacy websites
- Ability to include in Resource Reports
- Native service integration with websites as members of Service Insights
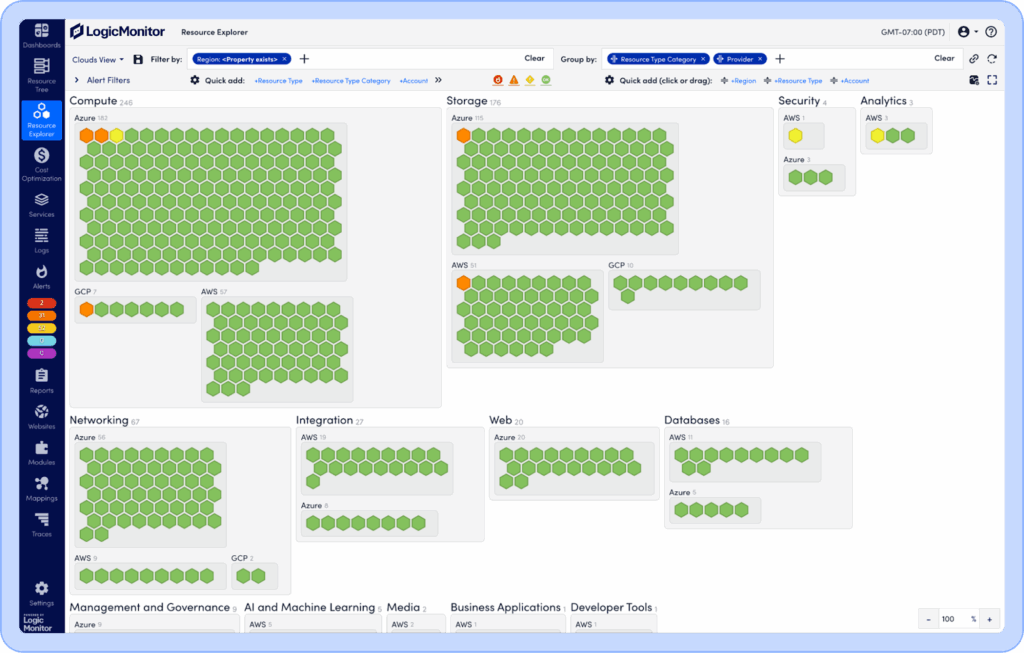
See the state of all of your resources, including websites, together in the Resource Explorer
How We Stack Up Against the Competition
What sets LM Uptime apart from other web monitoring tools is its simplicity to set up and use as well as the end-to-end visibility and value it returns by monitoring websites and all of the resources on which they depend on a single platform. Since LM Uptime is part of LM Envision, you can monitor web, infrastructure, cloud, and network resources without switching between tools. You get a single observability platform with a unified interface.
Pricing and Getting Started
LM Uptime is included in LogicMonitor Advanced and Signature platform packages, and also available as a standalone product.
Start monitoring your web sites and services with your hybrid infrastructure now

System uptime sets the pace of business. When a critical service degrades, the clock is running, and every delay compounds the impact.
While modern monitoring tools can flag the issue in seconds, detection is not resolution. Teams still have to scramble through dashboards, runbooks, and chat threads while your outage drags on. Alerts without action are just more noise.
This is the execution gap—the costly lag between knowing about a problem and actually resolving it. ITOps teams understand that the difference between a 15-minute resolution and a 90-minute one is not only time but also tens of thousands in revenue, missed SLAs, and permanent customer trust loss.
Edwin AI closes the execution gap. While basic monitoring tools stop at surfacing alerts, we’ve spent the last year building something fundamentally different: Agentic AIOps that detects and resolves incidents.
Now, we’re pushing the envelope further. We’re introducing Edwin AI’s growing suite of specialized agents—purpose-built for ITOps teams who know that in production environments, speed changes everything.
TL;DR: LogicMonitor introduces Edwin AI’s next evolution: an orchestrated ecosystem of specialized agents that close the execution gap in IT operations.
-
Monitoring tells you something’s wrong; observability tells you why; Edwin AI’s agents fix it.
-
Traditional incident response stops at detection and leaves teams scrambling across tools and silos.
-
Edwin AI closes the execution gap with 10+ specialized agents that investigate, correlate, recommend, and remediate in seconds.
-
The results are faster MTTR, fewer escalations, and IT teams operating at a new scale.
The Limitations of Traditional Incident Response
It’s worth starting with how most incident response works today and why many advanced tools are still falling short.
Even high-performing ITOps organizations remain trapped in an outdated operational model. Incident response continues to follow a relay race structure: one tool detects an issue, another analyzes it, and then the “fix” baton gets passed often across teams, tools, and time zones.
The numbers tell the story. Despite most teams having documented processes and automation, incidents still drag on, driving more downtime and higher costs. That’s because while legacy monitoring approaches excel at detection and correlation, they abandon teams at the most critical moment: execution. And the result is a predictable pattern of operational friction:
- Runbook hunting: Engineers scramble through wikis, knowledge bases, and shared folders to find the right resolution steps, often under pressure while systems remain down.
- Context switching: Teams frantically juggle between dashboards, ITSM tickets, chat threads, and CLI tools, trying to piece together the complete operational picture while the clock ticks.
- Manual remediation: Even supposedly “automated” fixes require manual triggers, human validation, and cross-team coordination, introducing delays at the moment speed matters most.
- Information silos: Critical context like change data, historical logs, and previous incident resolutions are trapped in separate systems, making root cause analysis slower when every second counts.
This operational fragmentation is systematic delay built into the incident response process:
- MTTI (Mean Time to Identify) stretches longer because relevant context isn’t surfaced instantly alongside alerts. Engineers waste time reconstructing the operational narrative instead of focusing on resolution.
- MTTR (Mean Time to Resolve) suffers when fixes require coordination across disconnected tools and teams, with no intelligent agent orchestrating the end-to-end process.
- Institutional knowledge evaporates when successful fixes live in individual memory or scattered documentation, rather than being actively surfaced by the system when similar conditions arise.
The path from “alert detected” to “problem solved” remains fundamentally broken, and there’s been no automated way to close it.
Learn more on how agentic AIOps automates IT incident response.
Why AI Agents are the Solution
Bridging this execution gap demands systems that can work at the speed, scale, and precision of modern production environments. Copilots and chatbots can assist, but they wait for a prompt and stop short of execution. AI agents are different. They stay inside the incident context, share information with other agents, and act without constant human direction.
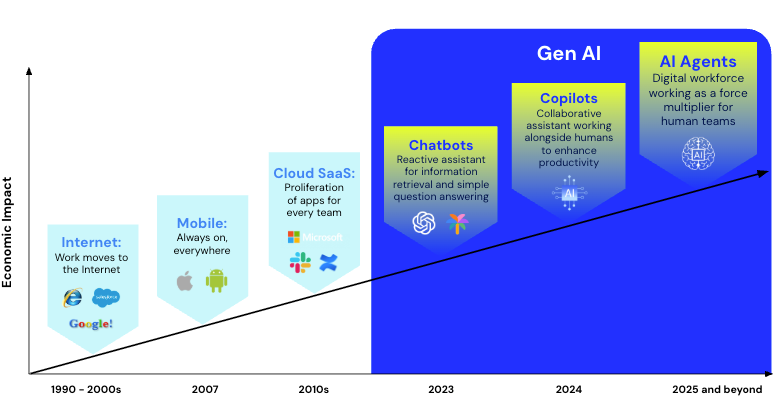
AI agents offer:
- Continuous context awareness: Agents aren’t starting from scratch every time you ask for help; they already have the incident history, related metrics, logs, and changes in view.
- Coordinated problem-solving: Agents can delegate to each other. For example, one agent pulls metrics while another finds related changes, and a third recommends the fix.
- Execution: Agents can run automation, roll back the bad deploy, or restart a service.
- Ambient operation: Agents can act before you ask, detecting early signals and kicking off diagnostics or mitigations.
Together, these abilities turn agents from passive helpers into an active, coordinated workforce, shortening the path from detection to resolution.
Introducing Edwin AI’s Agent Ecosystem: Specialized Skills for Complex Environments
With this launch, Edwin AI evolves from a single autonomous IT operations agent into an ecosystem of specialized AI agents, each designed to master a specific stage of the incident lifecycle.
These agents work in concert, sharing context and orchestrating actions, so IT teams can go from alert to resolution without the bottlenecks of manual triage, fragmented tooling, or knowledge silos.
Here’s a quick run through of all Edwin AI’s agents:
Event Intelligence Agents
- ITOps Agent: Interacts via natural language to answer, investigate, and guide triage, troubleshooting, and remediation.
- Insights Agent: Provides context-rich responses grounded in Edwin AI’s insight and alert data.
ITSM Agents
- Similar Incidents Agent: Learns from past resolution notes to accelerate diagnosis and recommend proven resolutions.
- Change Records Agent: Highlights recent deployments, configuration updates, or infrastructure changes that may relate to current incidents.
Knowledge Base (KB) Agents
- Public Knowledge Agent: Searches public docs, vendor portals, and internal knowledge for matching solutions.
- Private Knowledge Agent: Analyzes your organization’s internal knowledge to surface relevant guidance without switching context.
Telemetry Agents
- Metrics Agent: Surfaces key metrics in real-time, detecting patterns, deviations from normal behavior and enabling performance insights.
- Logs Anomaly Agent: Automatically identifies unusual log entries associated with alerts to help pinpoint root cause faster.
On-Call Agents
- On-Call Agent: Taps into past collaboration threads and incident escalations from Slack, Teams, and PagerDuty to provide contextual guidance, recommended actions, and SME routing.
- In-Chat Agent: Ability to engage with Edwin AI directly from Slack and Microsoft Teams.
Data Visualization Agents
- Charts Agent: Generates visualizations on Edwin data from natural language queries, including insights, alerts, and events.
Automation Agents
- Generate Automation Agent: Creates automations to remediate incidents.
- Discover & Execute Automation Agent: Identifies and acts on existing automation to resolve issues.
Alongside this agent ecosystem, Edwin AI continues to provide core capabilities like AI-generated alert summaries, root cause analysis, and remediation recommendations. These skills complement the specialized agents and ensure every stage of incident response is covered.
How Edwin AI’s Agents Work Together
Most AI in IT operations is still single-purpose: one model answers questions, another plots charts, another runs automation. Individually, Edwin AI’s agents bring deep expertise to specific parts of the incident lifecycle. But their real strength comes from working together.
To offer an example: At the core of Edwin AI is the Orchestrator Agent, the brain that coordinates specialized agents.
- It receives an incident as context.
- It decides which agents should be called, in what order, and with what parameters.
- It aggregates outputs, evaluates results, and determines the next best step.
When an alert comes in from a critical database service:
- Event Intelligence Agents generate the AI Title, Summary, and RCA.
- Change Records Agent checks for recent deployments to that service.
- Metrics Agent surfaces the CPU and I/O spikes that preceded the alert.
- Generate Automation Agent creates a playbook to roll back the change.
- Execute Automation Agent runs the rollback automatically.
- Post Mortem Document Agent compiles a report—all without an engineer leaving Edwin.
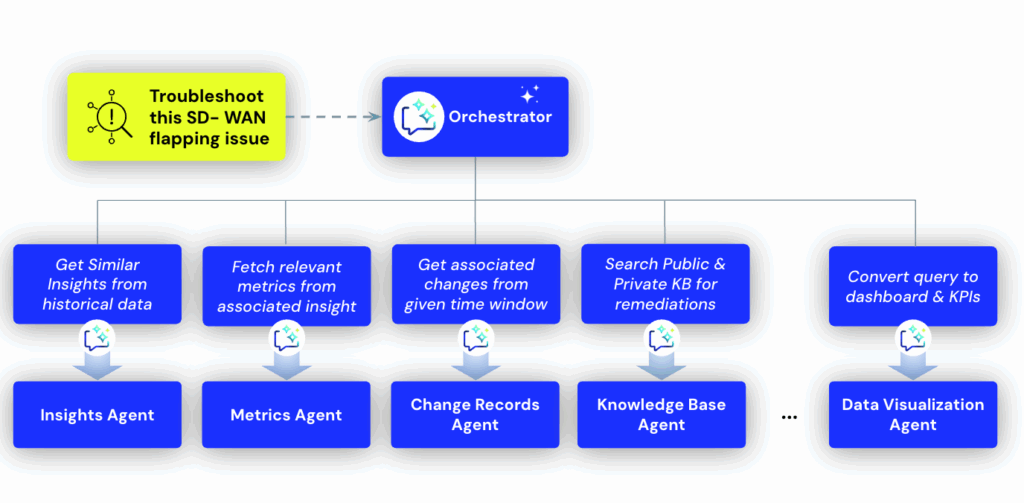
Dive deeper into Edwin AI’s agentic architecture.
Edwin AI: AI Agent’s Real-World Use Cases
Edwin AI’s specialized agents are already reshaping how IT operations teams detect, diagnose, and resolve incidents.
From early access customers to in-house testing, the results point to one clear outcome: lower MTTR, fewer escalations, and engineers freed from repetitive firefighting.
1. Instant, Context-Rich Triage
Before: L1 engineers spend the first 15-20 minutes of an incident stuck piecing together what happened from scattered dashboards, ticket notes, and monitoring alerts.
After: By generating an AI title, summary, root cause analysis, and impact analysis in seconds, Edwin AI provides a clear, natural-language brief that keeps everyone—from on-call SREs to executive stakeholders—aligned on the same actionable picture.
“The Edwin AI Agent is very helpful for L1 engineers. It gives them a starting point for triage and helps surface relevant information faster—ultimately helping them prioritize, escalate, and resolve faster.” — Early Access Participant
2. Faster Root Cause Identification
Before: Engineers manually dig through logs, cross-reference with recent change requests, and search internal KBs.
After: Metrics Agent, Logs Anomaly Agent, Change Records Agent, and Similar Incidents Agent run in parallel—correlating anomalies, recent changes, and historical fixes in seconds.
3. Knowledge That Finds You
Before: Critical fixes live buried in Confluence, runbooks, or vendor portals.
After: Private Knowledge and Public Knowledge Agents retrieve relevant resolution steps automatically—no hunting, no browser tabs, no stale answers. Engineers act with confidence, knowing recommendations are sourced from their own institutional knowledge or the most trusted vendor docs.
4. Automated Remediation Execution
Before: Even “routine” fixes required a human to trigger automation, validate the result, and update the ticket.
After: Automation Agents identify the right fix and take action by rolling back bad deployments, restarting failed services, or applying known patches without delay.
5. Consistent Post-Incident Documentation
Before: Post-mortems were rushed, inconsistent, and sometimes skipped entirely under workload pressure.
After: Post Mortem Document Agent auto-compiles incident details, RCA, remediations, timelines, and outcomes into a standardized format—preserving institutional memory and improving future readiness.
From AI as an Assistant to AI as a Teammate
AIOps was never meant to stop at detection and correlation. The original promise was autonomous, self-healing IT—systems that could not only find problems but fix them. Until now, the technology and orchestration simply weren’t mature enough to deliver.
Agentic AIOps fulfills that promise. Where copilots and chatbots once offered guidance but left execution to humans, agents now investigate, correlate, recommend, and act while humans provide oversight and judgment.
This means IT teams are operating at a fundamentally different scale. One engineer can oversee the work of what is, in effect, an entire AI-powered operations crew.
Edwin AI is leading this shift. Built from the ground up to unify observability, event intelligence, and automation under one intelligent system, Edwin applies specialized agents across every phase of the incident lifecycle without losing context.
See Edwin AI’s Agents in Action
Your next major incident is not a question of if, but when. The difference between a quick, contained resolution and a prolonged outage can come down to how fast you can bridge the execution gap.
It’s time to take the next step: Book a live demo and watch how Edwin AI’s agent ecosystem takes you from alert to resolution in a fraction of the time.


Solution brief
Connect Infrastructure and Business Impact with Dynamic Service Insights
Dynamic Service Insights from LogicMonitor helps operations teams align infrastructure and cloud performance with the real impact on business services. Native to the LogicMonitor Envision platform, Dynamic Service Insights gives ITOps and NetOps complete visibility to correlate health metrics with business-critical services. With automated service creation, intuitive KPI views, and real-time drill-downs, organizations can accelerate root cause analysis and maintain service reliability across hybrid environments.

Read the solution brief
Whitepaper
Connect IT to Business Impact with Dynamic Service Insights: A Guide for Modern ITOps Leaders
ITOps teams aren’t just supporting the business—they are the business. But too often, infrastructure metrics are lost in translation. Dashboards say green. The business says, “Why is checkout slow?”
It’s time for a new kind of observability—one that tells the story the business needs to hear.
Connect IT to Business Impact: A Guide for Modern ITOps Leaders,is a whitepaper built for teams that are ready to elevate monitoring from infrastructure health to business value. Inside, you’ll learn how forward-looking ITOps teams are:
- Replacing static service maps with scalable, rule-based service visibility
- Automatically surfacing the metrics that matter for business-critical services
- Accelerating root cause analysis with contextual drill-downs and service hierarchies
- Showing leadership clear, outcome-based dashboards that drive credibility and trust
As an ITOps leader, you’ll gain:
- A roadmap to shift from device-centric to service-first observability
- Real-world examples of how teams use Dynamic Service Insights to prevent revenue-impacting incidents
- Tactical guidance on setting up services, tagging strategies, and service health KPIs
- A smarter way to communicate IT’s value without extra tooling or manual overhead

Start telling a better story with your data and see how you can connect IT performance to business impact.
If you’re running Oracle Cloud Infrastructure (OCI) alongside AWS, Azure, or on-prem systems, you’ve probably been managing OCI through separate tools. Native support for Oracle Cloud Infrastructure in LogicMonitor Envision will be generally available in October, bringing unified observability to another major cloud platform.
Why OCI support matters now
The surge in AI adoption, compliance-driven cloud expansion, and diverse hybrid strategies has made Oracle Cloud a growing part of many customers’ infrastructure mix. OCI’s appeal spans cost advantages for specific workloads, deep integration with existing Oracle investments, and flexible hybrid options like Oracle Cloud@Customer (OC3).
ITOps leaders have traditionally found it challenging to monitor OCI in context with the rest of the stack. Historically, teams have had to juggle fragmented tools, leaving blind spots around the health, performance, and availability of OCI resources. These gaps not only slow down incident resolution but also complicate SLA compliance, cross-cloud optimization, and security governance.
CloudOps and DevOps teams need better visibility into the health, performance, and availability of important OCI resources that underpin mission-critical applications. LogicMonitor’s new Oracle Cloud monitoring coverage closes that gap with native support for core OCI services, including:
- OCI Compute: Monitor your virtual machines and bare metal instances
- Block Storage: Track performance and capacity across storage volumes
- Object Storage: Get visibility into your storage that powers data lakes and backups
- Oracle Autonomous Database: See the performance of cloud databases
This Phase 1 release focuses on the foundation that most enterprise workloads depend on—the core services where performance issues can materially impact your applications and users. Future releases will include additional services for a greater breadth of monitoring coverage.
Built for modern Cloud Operations teams
Multi-cloud platform teams will be able to onboard OCI the same way they handle other cloud providers. You’ll get guided setup, pre-built dashboards, and intelligent alerting that understands OCI’s unique characteristics.
Cloud infrastructure engineers gain the visibility they need without adding another tool to their stack. OCI metrics flow into the same dashboards where you’re already tracking AWS, Azure, GCP, and on-prem performance. This includes Resource Explorer, where teams can quickly spot performance issues at the resource level.
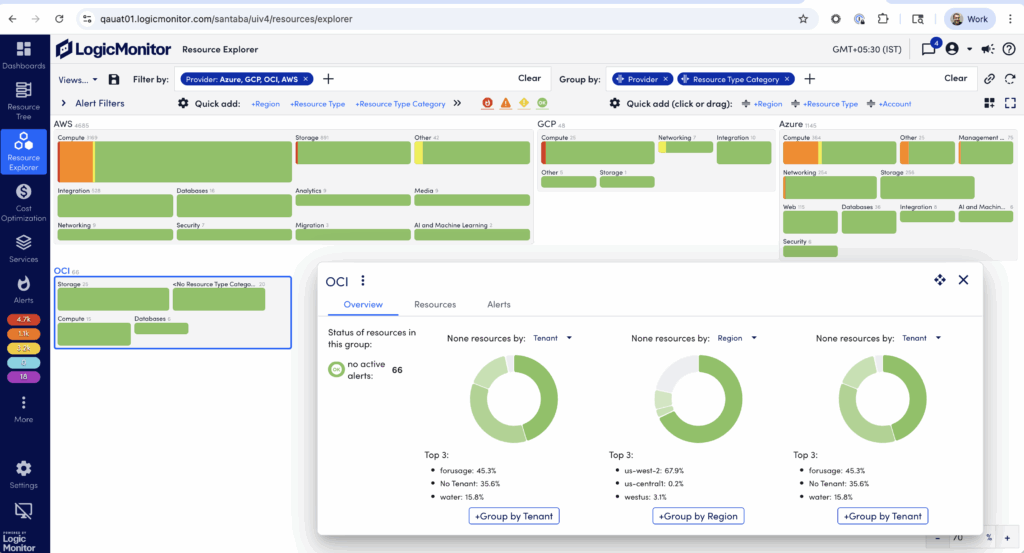
Compliance-driven organizations can securely monitor OCI data using LogicMonitor’s Credential Vault and Role-Based Access Control (RBAC), staying aligned with regulatory and privacy requirements.
The results are outcomes that directly impact your operations:
- Faster onboarding of OCI services
- Lower monitoring tool sprawl, reduced costs, and improved operational efficiency
- Improved SLAs through proactive alerting and automation
- Greater control over hybrid cloud costs and resource visibility
True multi-cloud observability
With Oracle Cloud included, LogicMonitor empowers teams to monitor infrastructure across more cloud resources, including OCI, AWS, Azure, and GCP in one place. Here’s what that means in practice.
With the latest enhancements, LM Envision supports:
- Over 70 AWS cloud services
- Over 60 Azure cloud services
- Roughly 20% of GCP’s cloud services
- Plus core OCI services that handle critical enterprise workloads
Our investment in deeper cloud integrations means you get:
- Automated discovery of OCI resources
- Performance tracking and alerting for mission-critical services
- Seamless hybrid visibility across private data centers, edge devices, private cloud (including OC3!), and public cloud
With OCI, we’re doubling down on breadth, depth, and usability. This puts LogicMonitor in a league of its own, especially for organizations requiring unified visibility across all cloud and on-prem environments.
But we’re not stopping here. OCI support is part of a broader roadmap that includes AI-focused services, GPU monitoring, and PaaS extensions, keeping pace with rapidly evolving enterprise needs.
How it works
This rollout is powered by updates to the LogicMonitor Cloud Collector to support OCI’s APIs and credential frameworks. To support our MSP customers, we’ve ensured OCI integrations work within parent-child portal models, respecting scoped credential inheritance and enterprise-grade access management.
Note: Cross-portal summaries and dashboards are not part of the initial MVP but are on the roadmap.
Getting started
Whether you’re already running OCI workloads or evaluating Oracle Cloud for future projects, unified observability removes a significant operational barrier. You can make cloud platform decisions based on technical requirements and business needs rather than monitoring tool limitations.
Oracle Cloud monitoring will be generally available starting in October for all LogicMonitor customers. Check our updated documentation for onboarding guides and credential setup.
Ready to explore OCI monitoring with LogicMonitor?
SAP, one of the world’s leading enterprise software companies, is on a mission to continuously improve its internal network infrastructure to support its global operations.
As the company rolled out a large-scale migration to software-defined networking (SDN), the Office Network Technologies department recognised the need to modernise its monitoring tools.
The existing monitoring approach, built around multiple vendor solutions and managed outside the team, left SAP’s internal Office Network teams feeling disconnected and reactive. According to Bernd Fritzsche, Service Owner for Office Network Monitoring at SAP, it left the team without the flexibility and control needed to operate this service.
Why SAP Chose LogicMonitor
The team conducted a thorough vendor evaluation, reviewing 12-15 vendors and running a detailed test phase with four. The selection process was methodical. SAP applied a weighted scoring matrix across defined test scenarios for onboarding, alerting, reporting, and customisation.
“LogicMonitor was the clear winner,” said Bernd Fritzsche, Service Owner for Office Network Monitoring at SAP. “It’s a pure SaaS solution, which was a key factor. We don’t have the capacity to run and maintain extensive on-prem systems. We needed to focus on visibility and performance, not infrastructure upkeep.”
Results: Greater Agility, Simpler Operations
With the LogicMonitor Envision platform in place, SAP’s internal network team now has unified visibility into core office network infrastructure, including switches, routers and firewalls. LogicMonitor has replaced multiple legacy tools and brought SAP’s monitoring strategy under one more sophisticated observability umbrella. Previously, separate tools were used for NetFlow, syslog, and device monitoring. LogicMonitor unified these into a single GUI, reducing tool sprawl and improving consistency across teams.
The initiative impacted multiple global teams across SAP’s internal infrastructure operations, including wireless, LAN, WAN, and firewall specialists. Adjacent departments such as authentication, email hosting, and web services are under evaluation to also be onboarded.
As the UK’s fourth-largest automotive retailer, Vertu Motors places customer experience at the center of its 198 dealerships. Representing world-leading brands like Ford, BMW, Toyota, and Mercedes-Benz, they aim to provide a seamless journey from online browsing to in-showroom visits. However, meeting the expectations of today’s tech-savvy car buyers requires more than just a wide selection of exceptional vehicles. It demands a robust, adaptable technology ecosystem that enhances both operations and customer satisfaction.
The Need for More Than Traditional Monitoring
Vertu’s rapid business growth and transition to a hybrid IT model, which included a significant migration to AWS cloud services, introduced operational complexity that their legacy monitoring tools could no longer manage effectively. As digital services became more integral to their sales and operations workflows, gaps in visibility began to hinder performance optimization and impact the customer experience.
These challenges stemmed from:
● Lack of visibility into cloud performance, creating gaps in their monitoring strategy
● Difficulty pinpointing root causes as systems interacted unpredictably
● Lengthy troubleshooting sessions and reactive firefighting that consumed valuable time and resources
● Unpredictable tool loads due to AWS’s dynamic nature and fluctuating customer demand that their existing tools couldn’t effectively monitor
The Solution: Hybrid Observability for a Modern Enterprise
Immediate value and streamlined deployment
LogicMonitor Envision provided actionable insights quickly, giving Vertu a comprehensive view of their IT operations within days of implementation. The platform’s rapid time-to-value ensured actionable insights were immediately available.
Proactive issue detection and resolution
LM Envision uncovered hidden issues that had gone undetected. Critical problems, such as unpredictable load spikes that would have impacted thousands of customers, were proactively identified and resolved. This prevented potential disruptions and improved overall system stability.
Data-driven optimization and resource allocation
LM Envision’s detailed insights empowered Vertu to make informed decisions about vital machine performance metrics such as CPU performance, memory consumption and IOPS, allowing them to optimize AWS resources and find the ideal balance between performance and cost.
The Future of Automotive: Powered by LogicMonitor Envision
Looking ahead, the Vertu group plans to further enhance the customer and employee experience. They intend to leverage LM Envision’s data-driven insights to fuel innovation and streamline processes across their network of dealerships.
Vertu Motors plc is committed to solidifying its leadership in automotive retail by continually improving service offerings and customer experience. With a goal to set new industry benchmarks for customer loyalty, they’re building on an impressive 97% recommendation score.
