Discover how Edwin AI’s 10+ specialized AIOps agents detect, diagnose, and resolve incidents fast — helping IT teams cut MTTR, reduce escalations, and avoid downtime.
System uptime sets the pace of business. When a critical service degrades, the clock is running, and every delay compounds the impact.
While modern monitoring tools can flag the issue in seconds, detection is not resolution. Teams still have to scramble through dashboards, runbooks, and chat threads while your outage drags on. Alerts without action are just more noise.
This is the execution gap—the costly lag between knowing about a problem and actually resolving it. ITOps teams understand that the difference between a 15-minute resolution and a 90-minute one is not only time but also tens of thousands in revenue, missed SLAs, and permanent customer trust loss.
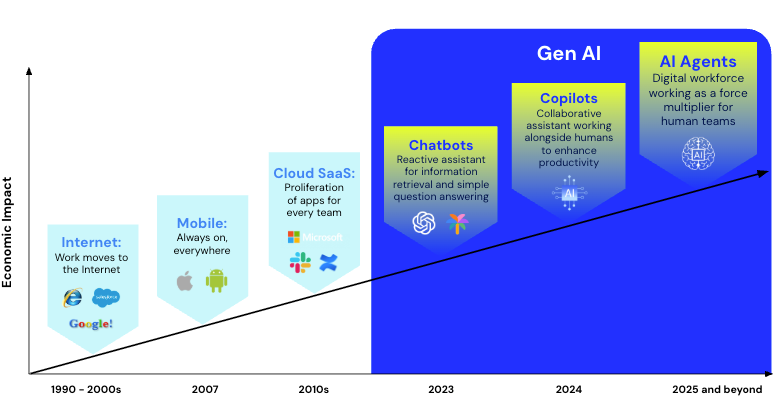
Edwin AI closes the execution gap. While basic monitoring tools stop at surfacing alerts, we’ve spent the last year building something fundamentally different: Agentic AIOps that detects and resolves incidents.
Now, we’re pushing the envelope further. We’re introducing Edwin AI’s growing suite of specialized agents—purpose-built for ITOps teams who know that in production environments, speed changes everything.
TL;DR: LogicMonitor introduces Edwin AI’s next evolution: an orchestrated ecosystem of specialized agents that close the execution gap in IT operations.
Monitoring tells you something’s wrong; observability tells you why; Edwin AI’s agents fix it.
Traditional incident response stops at detection and leaves teams scrambling across tools and silos.
Edwin AI closes the execution gap with 10+ specialized agents that investigate, correlate, recommend, and remediate in seconds.
The results are faster MTTR, fewer escalations, and IT teams operating at a new scale.
The Limitations of Traditional Incident Response
It’s worth starting with how most incident response works today and why many advanced tools are still falling short.
Even high-performing ITOps organizations remain trapped in an outdated operational model. Incident response continues to follow a relay race structure: one tool detects an issue, another analyzes it, and then the “fix” baton gets passed often across teams, tools, and time zones.
The numbers tell the story. Despite most teams having documented processes and automation, incidents still drag on, driving more downtime and higher costs. That’s because while legacy monitoring approaches excel at detection and correlation, they abandon teams at the most critical moment: execution. And the result is a predictable pattern of operational friction:
Runbook hunting: Engineers scramble through wikis, knowledge bases, and shared folders to find the right resolution steps, often under pressure while systems remain down.
Context switching: Teams frantically juggle between dashboards, ITSM tickets, chat threads, and CLI tools, trying to piece together the complete operational picture while the clock ticks.
Manual remediation: Even supposedly “automated” fixes require manual triggers, human validation, and cross-team coordination, introducing delays at the moment speed matters most.
Information silos: Critical context like change data, historical logs, and previous incident resolutions are trapped in separate systems, making root cause analysis slower when every second counts.
This operational fragmentation is systematic delay built into the incident response process:
MTTI (Mean Time to Identify) stretches longer because relevant context isn’t surfaced instantly alongside alerts. Engineers waste time reconstructing the operational narrative instead of focusing on resolution.
MTTR (Mean Time to Resolve) suffers when fixes require coordination across disconnected tools and teams, with no intelligent agent orchestrating the end-to-end process.
Institutional knowledge evaporates when successful fixes live in individual memory or scattered documentation, rather than being actively surfaced by the system when similar conditions arise.
The path from “alert detected” to “problem solved” remains fundamentally broken, and there’s been no automated way to close it.
Learn more on how agentic AIOps automates IT incident response.
Bridging this execution gap demands systems that can work at the speed, scale, and precision of modern production environments. Copilots and chatbots can assist, but they wait for a prompt and stop short of execution. AI agents are different. They stay inside the incident context, share information with other agents, and act without constant human direction.
AI agents offer:
Continuous context awareness: Agents aren’t starting from scratch every time you ask for help; they already have the incident history, related metrics, logs, and changes in view.
Coordinated problem-solving: Agents can delegate to each other. For example, one agent pulls metrics while another finds related changes, and a third recommends the fix.
Execution: Agents can run automation, roll back the bad deploy, or restart a service.
Ambient operation: Agents can act before you ask, detecting early signals and kicking off diagnostics or mitigations.
Together, these abilities turn agents from passive helpers into an active, coordinated workforce, shortening the path from detection to resolution.
Introducing Edwin AI’s Agent Ecosystem: Specialized Skills for Complex Environments
With this launch, Edwin AI evolves from a single autonomous IT operations agent into an ecosystem of specialized AI agents, each designed to master a specific stage of the incident lifecycle.
These agents work in concert, sharing context and orchestrating actions, so IT teams can go from alert to resolution without the bottlenecks of manual triage, fragmented tooling, or knowledge silos.
Here’s a quick run through of all Edwin AI’s agents:
Event Intelligence Agents
ITOps Agent: Interacts via natural language to answer, investigate, and guide triage, troubleshooting, and remediation.
Insights Agent: Provides context-rich responses grounded in Edwin AI’s insight and alert data.
ITSM Agents
Similar Incidents Agent:Learns from past resolution notes to accelerate diagnosis and recommend proven resolutions.
Change Records Agent: Highlights recent deployments, configuration updates, or infrastructure changes that may relate to current incidents.
Knowledge Base (KB) Agents
Public Knowledge Agent: Searches public docs, vendor portals, and internal knowledge for matching solutions.
Private Knowledge Agent: Analyzes your organization’s internal knowledge to surface relevant guidance without switching context.
Telemetry Agents
Metrics Agent: Surfaces key metrics in real-time, detecting patterns, deviations from normal behavior and enabling performance insights.
Logs Anomaly Agent: Automatically identifies unusual log entries associated with alerts to help pinpoint root cause faster.
On-Call Agents
On-Call Agent: Taps into past collaboration threads and incident escalations from Slack, Teams, and PagerDuty to provide contextual guidance, recommended actions, and SME routing.
In-Chat Agent: Ability to engage with Edwin AI directly from Slack and Microsoft Teams.
Data Visualization Agents
Charts Agent: Generates visualizations on Edwin data from natural language queries, including insights, alerts, and events.
Automation Agents
Generate Automation Agent: Creates automations to remediate incidents.
Discover & Execute Automation Agent: Identifies and acts on existing automation to resolve issues.
Alongside this agent ecosystem, Edwin AI continues to provide core capabilities like AI-generated alert summaries, root cause analysis, and remediation recommendations. These skills complement the specialized agents and ensure every stage of incident response is covered.
How Edwin AI’s Agents Work Together
Most AI in IT operations is still single-purpose: one model answers questions, another plots charts, another runs automation. Individually, Edwin AI’s agents bring deep expertise to specific parts of the incident lifecycle. But their real strength comes from working together.
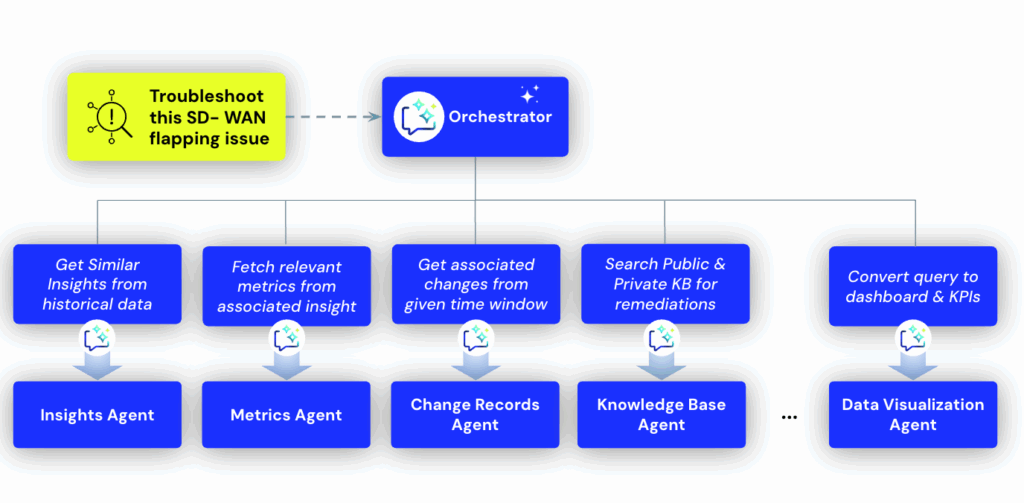
To offer an example: At the core of Edwin AI is the Orchestrator Agent, the brain that coordinates specialized agents.
It receives an incident as context.
It decides which agents should be called, in what order, and with what parameters.
It aggregates outputs, evaluates results, and determines the next best step.
When an alert comes in from a critical database service:
Event Intelligence Agents generate the AI Title, Summary, and RCA.
Change Records Agent checks for recent deployments to that service.
Metrics Agent surfaces the CPU and I/O spikes that preceded the alert.
Generate Automation Agent creates a playbook to roll back the change.
Execute Automation Agent runs the rollback automatically.
Post Mortem Document Agent compiles a report—all without an engineer leaving Edwin.
Edwin AI’s specialized agents are already reshaping how IT operations teams detect, diagnose, and resolve incidents.
From early access customers to in-house testing, the results point to one clear outcome: lower MTTR, fewer escalations, and engineers freed from repetitive firefighting.
1. Instant, Context-Rich Triage
Before: L1 engineers spend the first 15-20 minutes of an incident stuck piecing together what happened from scattered dashboards, ticket notes, and monitoring alerts.
After: By generating an AI title, summary, root cause analysis, and impact analysis in seconds, Edwin AI provides a clear, natural-language brief that keeps everyone—from on-call SREs to executive stakeholders—aligned on the same actionable picture.
“The Edwin AI Agent is very helpful for L1 engineers. It gives them a starting point for triage and helps surface relevant information faster—ultimately helping them prioritize, escalate, and resolve faster.” — Early Access Participant
2. Faster Root Cause Identification
Before: Engineers manually dig through logs, cross-reference with recent change requests, and search internal KBs.
After: Metrics Agent, Logs Anomaly Agent, Change Records Agent, and Similar Incidents Agent run in parallel—correlating anomalies, recent changes, and historical fixes in seconds.
3. Knowledge That Finds You
Before: Critical fixes live buried in Confluence, runbooks, or vendor portals.
After: Private Knowledge and Public Knowledge Agents retrieve relevant resolution steps automatically—no hunting, no browser tabs, no stale answers. Engineers act with confidence, knowing recommendations are sourced from their own institutional knowledge or the most trusted vendor docs.
4. Automated Remediation Execution
Before: Even “routine” fixes required a human to trigger automation, validate the result, and update the ticket.
After: Automation Agents identify the right fix and take action by rolling back bad deployments, restarting failed services, or applying known patches without delay.
5. Consistent Post-Incident Documentation
Before: Post-mortems were rushed, inconsistent, and sometimes skipped entirely under workload pressure.
After: Post Mortem Document Agent auto-compiles incident details, RCA, remediations, timelines, and outcomes into a standardized format—preserving institutional memory and improving future readiness.
From AI as an Assistant to AI as a Teammate
AIOps was never meant to stop at detection and correlation. The original promise was autonomous, self-healing IT—systems that could not only find problems but fix them. Until now, the technology and orchestration simply weren’t mature enough to deliver.
Agentic AIOps fulfills that promise. Where copilots and chatbots once offered guidance but left execution to humans, agents now investigate, correlate, recommend, and act while humans provide oversight and judgment.
This means IT teams are operating at a fundamentally different scale. One engineer can oversee the work of what is, in effect, an entire AI-powered operations crew.
Edwin AI is leading this shift. Built from the ground up to unify observability, event intelligence, and automation under one intelligent system, Edwin applies specialized agents across every phase of the incident lifecycle without losing context.
See Edwin AI’s Agents in Action
Your next major incident is not a question of if, but when. The difference between a quick, contained resolution and a prolonged outage can come down to how fast you can bridge the execution gap.
It’s time to take the next step: Book a live demo and watch how Edwin AI’s agent ecosystem takes you from alert to resolution in a fraction of the time.
Margo Poda leads content strategy for Edwin AI at LogicMonitor. With a background in both enterprise tech and AI startups, she focuses on making complex topics clear, relevant, and worth reading—especially in a space where too much content sounds the same. She’s not here to hype AI; she’s here to help people understand what it can actually do.
Disclaimer: The views expressed on this blog are those of the author and do not necessarily reflect the views of LogicMonitor or its affiliates.