
The quick download:
Autonomous IT is the operating model where systems detect, decide, and act so your engineers spend less time fighting fires and more time defining what ‘good’ looks like.
-
It works best when you start with clean, connected signals that link symptoms to service impact, not isolated alerts.
-
The hard part isn’t automation. It’s deciding what to do safely when multiple services and dependencies are involved.
-
Trust comes from control: clear guardrails, approvals for higher-risk actions, audit trails, and rollback paths.
-
The organizations pulling ahead aren’t waiting for perfect conditions. Start with one high-volume workflow, get the guardrails right, and expand from there.
On a typical day, a mid-size enterprise generates tens of thousands of alerts across on-prem infrastructure, multiple clouds, and AI workloads, including every endpoint. Most of them don’t need a human. A few of them do, and telling the difference, fast enough to matter, is where IT teams are losing ground.
Once it reaches end-users, it stops being a technical problem in isolation. It becomes an experience problem, with SLA pressure and real cost attached.
The harder problem is context. User experience, application behavior, and infrastructure signals rarely share context across tools, so cause, impact, and ownership don’t line up fast enough.
Autonomous IT addresses these gaps in IT operations by changing how teams detect, diagnose, and fix issues when the full picture is available, not scattered across disconnected tools. It uses defined intent and policy to guide operational decision-making, then takes action.
This article explains what autonomous IT is, how it differs from automation and AIOps (which heavily relies on artificial intelligence), where it shows up in day-to-day operations, and how to implement it safely with measurable outcomes.
What Is Autonomous IT?
Autonomous IT is an operating model where systems act on defined intent, meaning explicitly configured rules like ‘this service must stay below 200ms p99 latency,’ ‘auto-scale only up to $X per hour,’ or ‘require approval before any action touching the payments tier’ rather than waiting for human intervention to connect the dots and issue instructions.
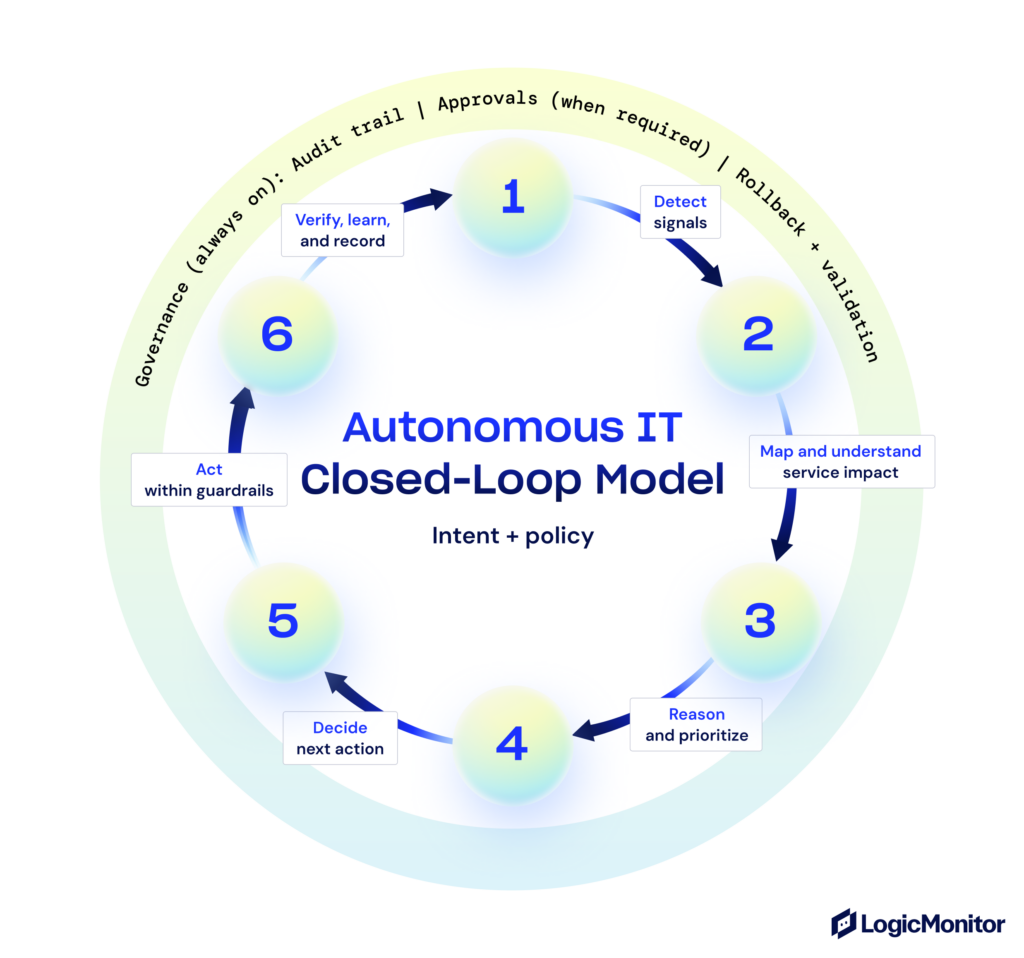
In practice, that looks like this: latency spikes in a customer-facing service, the system correlates it with a deployment that went out 20 minutes ago, maps the blast radius to three downstream dependencies, triggers an approved rollback runbook, and creates a timestamped incident ticket—all before your on-call engineer has finished reading the first alert. People remain accountable, but they spend less time running manual fixes and more time defining intent, setting constraints, approving higher-risk actions, and reviewing outcomes.
Without correlation and causality, observability stops at visibility.
How Autonomous IT Differs from Automation, AIOps, and Self-Healing Operations
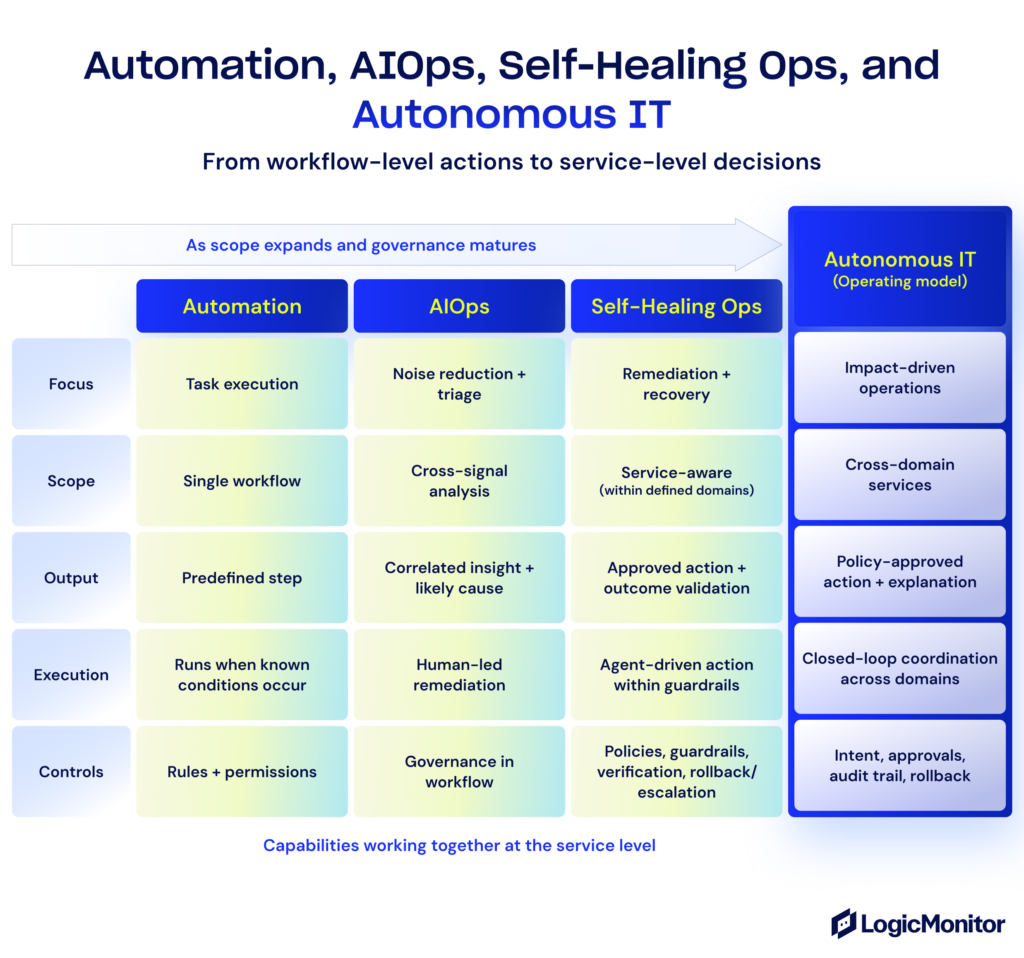
Automation, AIOps, and self-healing operations are enabling capabilities that evolve toward an operating model: Autonomous IT.
Automation executes predefined workflows. When a known condition occurs, a workflow runs. This works well for repeatable procedures, but it doesn’t decide between competing actions when multiple services are affected or when the situation changes mid-incident.
AIOps shortens analysis by applying machine learning to reduce noise and correlate signals across telemetry. It can speed triage and surface likely causes, but humans typically choose and execute the remediation steps.
Self-healing operations are the remediation layer, powered by AI agents, that starts to close the loop. It selects from approved corrective actions based on context, executes within defined guardrails, and validates outcomes—with rollback or escalation when conditions don’t improve.
Autonomous IT is the operating model that emerges when automation, AIOps, and self-healing operate together at the service level. It uses intent and policy to decide what to do, coordinates actions across infrastructure, applications, and services, and records what it did and why, so teams can trust, govern, and continuously improve autonomous behavior.
The Evolution: From Automation to Autonomy
IT operations moved from manual work to scripted automation because environments grew beyond what humans could manage by hand. Automation helped teams respond faster and more consistently, but it struggled when architectures became more dynamic, and incidents started spanning multiple services and dependencies.
As observability matured, teams gained more telemetry, but many still had to do the hard part manually: correlating what’s related, identifying what changed, and deciding what action to take. Autonomous IT builds on that foundation by combining context, reasoning, and policy-driven execution so systems can prioritize impact and carry out approved actions.
Key Features and Capabilities of Autonomous IT
Autonomous IT works when three things come together: the system can understand what’s happening, it can take action, and it can do both within clear controls.
Context and intelligence start with end-to-end visibility—no blind spots from user experience to application services to the infrastructure and dependencies underneath. The goal is not more dashboards. The goal is correlated context that links symptoms to likely causes and shows which services and users are affected. Predictive analytics and real-time anomaly detection add another layer by surfacing patterns that tend to lead to incidents, giving teams time to act before impact spreads.
Action and execution cover the mechanics of doing the work. That includes self-healing and auto-remediation for bounded incident types, plus dynamic resource provisioning where scaling or capacity adjustments follow defined rules. The point is to execute the same approved steps consistently and execute them faster than any manual process allows.
Control and governance are what make autonomous action usable in production. Autonomous systems need policies that define what actions are allowed, what requires approval, what must be logged, and what needs rollback and verification, often integrating with IT Service Management. They also need to fit into existing workflows through integrations with systems like ITSM, CI/CD, and ChatOps, so actions and decisions stay visible and auditable.
Benefits of Autonomous IT
Autonomous IT improves operations by reducing time spent on manual triage and routine remediation, especially during high-volume alert periods, helping teams optimize their workflows. When systems can correlate signals, prioritize impact, and carry out approved actions, teams spend less time jumping between tools and more time resolving the underlying issue.
It also improves reliability by shrinking the time between detection and corrective action, leading to faster response times. Earlier detection, clearer prioritization, and consistent remediation reduce the chance that issues escalate into user-facing incidents, negatively impacting customer experience, or spread across dependent services.
For many organizations, the third benefit is efficiency. Autonomous operations reduce repetitive work, and support growth without requiring a proportional increase in on-call burden.
Challenges and Considerations
Trust is the real blocker. Before most engineering teams will hand off remediation to an autonomous system, they need to be able to interrogate it: What signals fired? What did the system conclude from them? What action did it choose, and why that one over the alternatives? Explainability isn’t a nice-to-have. It’s what separates a system your team will actually rely on from one that gets bypassed the first time it does something unexpected. Building that trust takes time and requires that the system show its reasoning consistently, not just when things go right.
Autonomous IT also depends on data that is consistent and connected. If telemetry is incomplete, noisy, or split across tools that don’t share context, you create blind spots and autonomous decisions become less reliable and harder to validate.
Finally, autonomy changes how work gets done. Engineers spend less time executing fixes and more time defining policies, maintaining runbooks, improving instrumentation, and reviewing outcomes. That shift requires process changes and skills development, not just new tooling.
Real-World Applications and Use Cases
Autonomous IT tends to show up first in workflows that are repetitive, time-sensitive, and easy to govern. Teams usually start by reducing manual steps in incident response and ITSM workflows before expanding into automated remediation.
Service desk automation is a common early use case. Imagine a cloud provider degrades in one region. Your monitoring fires 400 alerts in 90 seconds. Without an autonomous IT operating model, that’s a human triaging noise. With it, related alerts are grouped, an incident is opened with context already populated, and the ticket stays updated as conditions change and closes when the issue clears. Less ticket mechanics, better incident records.
Automated incident response focuses on shortening the time spent correlating symptoms and deciding what to do first. Think of the last time you had three dashboards open, a Slack thread running, and weren’t sure yet whether the database was the cause or a casualty. That’s the gap this closes.
As organizations mature, they often expand autonomy into bounded remediation workflows and routine maintenance tasks—certificate rotation, disk cleanup, scheduled restarts, patching—where the actions are well understood, low risk, and easy to validate and roll back.
See how Edwin AI supports incident investigation and knowledge capture across the incident lifecycle.
Steps to Implement Autonomous IT
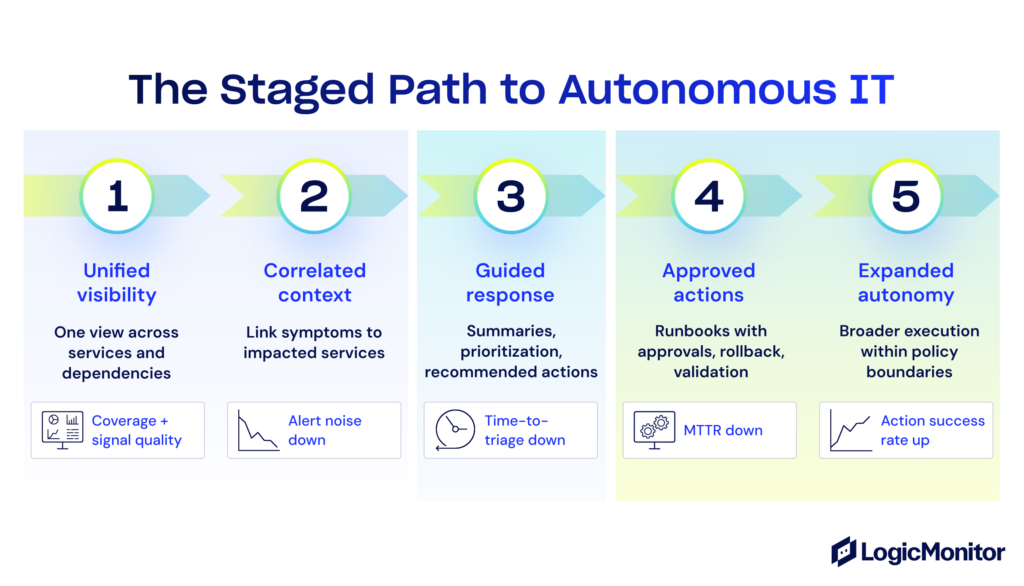
Start by mapping the services that matter most and the signals that indicate service impact. Then focus on improving data quality and correlation so incidents can be understood in context, not as isolated alerts.
Define intent and guardrails early. That includes service priorities, SLO targets, cost limits, risk policies, and approval requirements, along with clear boundaries for what the system can execute automatically.
Begin with low-risk, repeatable actions. Start with recommendations and ticket enrichment, expand into approved runbooks for specific incident types, and add verification and rollback steps as execution grows.
Integrate autonomy into the workflows your teams already use, including ITSM, change management, and chat-based collaboration, enabling better orchestration.
Measure results, then expand scope. Use operational metrics to validate impact, and widen autonomy only when the system is consistently making correct, explainable decisions inside the rules you set.
The Future of Autonomous IT
As autonomous IT matures, the practical demand on engineering teams shifts. Less time executing known fixes, more time deciding which fixes should be automated in the first place and making sure the policies, runbooks, and telemetry quality are good enough to support that.
The teams that will get the most out of this aren’t necessarily the ones with the most sophisticated tooling. They’re the ones who’ve done the unglamorous work: cleaning up alert noise, documenting remediation steps, defining what ‘good’ actually looks like for each service. That’s what autonomous systems run on.
That shift also changes what skills matter. The engineers who thrive in autonomous IT environments won’t be the ones who can manually trace a cascading failure across five services fastest, though that skill still has value during the transition. They’ll be the ones who can design policies that hold up under conditions nobody anticipated, audit autonomous decisions for drift and bias, and know when to tighten guardrails and when to expand them. AI governance, cross-domain integration, and exception management are becoming core competencies, not specializations.
The organizational implication is real, too, and CIOs are increasingly recognizing its importance. Teams will need people who sit at the intersection of operations and policy—reviewing what the system did, asking whether it should have done it, and feeding that back into better runbooks and tighter intent definitions. That’s a different job than what most ITOps roles look like today, and organizations that start building for it now will be better positioned than those treating it as a future problem.
The Bottom Line
Autonomous IT is a practical response to a real operational problem: too much telemetry, too many alerts, and not enough time to connect cause to impact before users feel it. The move is toward an operating model that catches issues earlier and automatically resolves some problems under defined policies.
The most practical path is staged adoption. Start with better context and workflow integration, then expand into low-risk automation with clear guardrails, auditability, and rollback. Measure outcomes, refine policies, and grow autonomy only where it improves reliability and reduces operational effort. The organizations pulling ahead aren’t waiting for perfect conditions. They’re starting with what they have, learning fast, and expanding from there.
See Where Observability and AI Are Headed in 2026
Download the report to see what IT leaders are prioritizing next, plus the benchmarks you can use to shape your autonomous IT roadmap.
FAQs
What is the difference between automation, AIOps, and autonomous IT?
Automation executes predefined tasks, AIOps analyzes data and suggests actions, while autonomous IT can reason and act across systems using intent and policies—reducing manual intervention.
How does autonomous IT reduce manual workload for IT teams?
Autonomous IT reduces manual workload by automating high-volume operational steps such as alert correlation, incident enrichment, ticket updates, and repeatable remediation runbooks to streamline operations. It cuts time spent switching between tools and assembling context during incidents, so engineers spend more time on reliability improvements and prevention.
What guardrails are in place to ensure autonomous IT actions are safe and compliant?
Autonomous IT guardrails include policy-based permissions, approval workflows for higher-risk actions, role-based access controls, audit logging, change record integration, and rollback plus verification steps. These controls ensure autonomous actions follow governance requirements and can be reviewed and reversed when needed.
Can autonomous IT integrate with my existing ITSM and monitoring tools?
Yes. Autonomous IT is designed to integrate with existing ITSM, change management, and monitoring tools so actions remain visible, auditable, and aligned to operational workflows. Common integration points include incident creation and updates, change approvals, notifications, and linking correlated evidence to tickets.
What are the first steps to adopting autonomous IT in my organization?
The first steps to adopting autonomous IT are: identify a high-volume workflow (incident triage or ticket handling), improve telemetry quality and correlation, define intent and policy guardrails, start with low-risk recommendations and ticket enrichment, then expand to approved automated runbooks with rollback and verification.
How does autonomous IT improve incident response and reduce downtime?
Autonomous IT improves incident response by reducing time-to-triage and time-to-diagnose through correlation, impact prioritization, and consistent incident summaries. It reduces downtime and prevents outages by enabling earlier detection and faster, policy-approved remediation for repeatable incident types.
Will autonomous IT replace IT jobs?
Autonomous IT will reduce or eliminate many repetitive L1 tasks, including manual triage, ticket handling, and runbook execution. IT teams will still need humans to define intent, set policies, oversee autonomous actions, validate outcomes, and handle edge cases. The skills that become more valuable are policy design, AI governance, exception management, and cross-domain integration—competencies that sit at the intersection of operations and oversight, not the execution layer that autonomous systems are taking over.
What types of IT tasks are best suited for autonomous IT today?
Tasks best suited for autonomous IT today are bounded, repeatable workflows with clear success criteria and safe rollback. Common examples include ticket creation and updates, incident enrichment and routing, alert correlation, guided triage for recurring patterns, and automated remediation runbooks for known failure modes.
How does LogicMonitor support autonomous IT?
LogicMonitor supports autonomous IT by focusing on outcomes that enable autonomy: reducing alert noise, improving incident context, accelerating investigation, and supporting guided remediation within existing workflows. LogicMonitor positions Edwin AI as an AI capability for incident triage, root cause analysis support, and operational guidance aligned to governance.
What are the most common challenges when implementing autonomous IT?
The most common challenges when implementing autonomous IT start with trust. Engineers won’t hand off remediation to a system they can’t interrogate. Teams need to understand what signals fired, what the system concluded, and why it chose a specific action. Beyond trust, the next barriers are telemetry quality and fragmentation: autonomous decisions are only as reliable as the data underneath them, and most environments have incomplete, noisy, or siloed observability. Integration gaps across tools, governance requirements for approvals and access control, and the process and skills changes needed to move from manual execution to policy-driven operations round out the most common implementation hurdles.




