

Happy 4th of July.
In addition to the paddleboarding, lazing on the beach, kitesurfing (if the wind picks up), BBQing with friends, and fireworks that will happen later today (Santa Barbara, where LogicMonitor is based, is a great place to live. Why not move here to work for an awesome company?), I’m taking the day to answer a question some interns had yesterday: What is the difference between a derive datapoint, and a counter datapoint, and when would you use one over the other?
Mr Protocol is glad you asked. (For those of you too young to remember Mr Protocol, or Sun Expert magazine, or even Sun Microsystems…. go find a crusty old sysadmin with beard and suspenders, and ask them.)

Both counters and derives are used to convert samples of raw data into a rate per second. If data is sampled at time 1 with value A, and time 2 with value B, both will store a datapoint whose value is (B – A) / (time 2 – time 1).
e.g. first sample, at 10:03:22 returns 50 things (they could be transactions, bits, sectors, etc). Second sample at 10:06:12 returns 4998 things. Both a counter and a derive will return (4998 – 50)/(10:06:12 – 10:03:22) = 4948/ 170 seconds = 29.1 things per second. Note that it does not matter that the sample times are in anyway regular – they will always convert to per second rates.
So in this simple case derives and counters are exactly the same. The interesting differences happen when the value returned by the second sample is smaller than the value returned by the first sample.
For example, say sample 1, at 10:00:00, returns 4294967295. Sample 2, at 10:01:00, returns 1.
Now, a derive will, just like you learned in 9th grade calculus, return the rate of change, and the rate of change can be negative. So in this case, it will return: (1 – 4294967295)/60 = -71582788.23 things per second.
A counter, on the other hand, assumes that the objects it’s measuring can only increase, and it is aware of the fact that computers often return data in 32 or 64 bit integers. So when a counter sees the above example, it will account for the wrapping of the counter after 32 bits, as it knows that the second sample has to be bigger then the first. So it will return ((2^32 +1) – 4294967295)/60 = 2/60 = 0.03 things per second.
So, very different results between the derive and counter type datapoints in this case.
So, if we know that we are querying data from computers, and computers do in fact use 32 or 64 bit counters, we should always use counter datapoint type over derives, right? Well… No. While counters are great for dealing with counter wraps intelligently, they will sometimes deal with things that are not counter wraps, unintelligently.
e.g. Consider this series of data samples:
10:00:00 536870912
10:01:00 536870940
10:02:00 536870992
10:03:00 34
A counter would interpret the datapoint values as: 0.46 per second; 0.86 per second; 62634938.96 per second (2^32 + 34 – 536870992)/60. Is it likely that the rate really increased by a factor of 100 million? Or is it more likely that the device being measured rebooted, or otherwise had its counters reset to zero? Graphs with counter type datapoints can be subject to incorrect giant spikes when devices are reset, leading the real data to be a flat, undifferentiated line along the zero value of the x-axis.
OK, so then we should always use derive-type datapoints, right?
Well, except as we noted above, derives don’t deal with counter wraps. So in order to not have graphs showing negative values after counter wraps, it is common to set a minimum of zero for the valid values on the datapoint, so anything negative will be discarded. Does that matter? It certainly does with 32 bit counters. If you have a 1 Gigabit per second interface running at 500Mbps, and you are measuring octets per second in or out with a 32 bit counter (which is all you get with SNMP v1) that you sample once per minute, then you will be wrapping your 32 bit counter every 68 seconds or so. So you’ll be discarding every second sample, and your collected data will be spotty, irregular, and not reliable.
So where are we? Where there is the possibility of frequent counter wrapping, a counter datapoint is the best choice. But ensure you set sensible minimum and maximum valid values for the datapoint, to minimize the chance of crazy spikes skewing your data when the datapoint interprets a zero-ing of counters as a counter wrap. This is what we did for all interface datasource in LogicMonitor until recently – defined interface datapoints as counters, with limits to constrain the values to those that were possible with up to 10G interfaces to minimize incorrect spikes.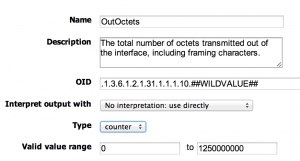
When I wrote this datasource a few years, it made sense. Ten gig ethernet was brand new and rarely deployed, so it was unlikely any customer would hit that limit. Now, however, we have customers aggregating 10G links together to push even higher throughput, so the datasource needed adjusting.
So now the 64 bit interface datasources all use derive type datapoints, not counters, and have no upper limit, so people can pump through 20 Gbps, 200Gbps, or whatever the new technologies bring.
And counter wraps? Well, with 64 bit counters, that’s not really an issue.
So now we have datasources for 32 bit counters still use counter types, with limits set for 10G ethernet. But virtually all equipment now supports snmp v2 or v3, which will automatically be monitored by the 64 bit counters, which have no upper limit. (But may throw away one data sample a year, due to wraps.)
Final word: use derives in almost all cases, unless you are dealing with snmp v1 devices only.
Mr. Protocol refuses to divulge his qualifications and may, in fact, have none whatsoever.



