


In the LM Envision platform, anomaly detection for metrics is referred to by the feature name “Dynamic Threshold” rather than the more generic machine learning term “anomaly detection.” Dynamic thresholds allow users to identify and set custom alert thresholds based on observed data points.
Metric thresholds in rules-based systems are effective when the desired outcome is clear. However, static thresholds may not anticipate emerging issues. For example, if the temperature rises in a remote IT center unexpectedly. That’s where dynamic thresholds or anomaly detection plays a crucial role.
One size does not fit all thresholds
Many metrics are hard to define for all instances of a resource type. For example, what constitutes good or average latency on one link may vary from another due to the differing distances between the links. Another example is CPU utilization, which may differ because different applications and services are running. Memory is similar.
This leads to false positives when the threshold is set too low in an attempt to make sure all problems are seen. Setting the threshold too high to reduce false alarms can also cause false negatives. Attempting to optimize thresholds for each resource can be manual, time-consuming, and inaccurate.
Automating the threshold levels
While many conceivable ways exist to automate setting alarm thresholds, machine learning-based anomaly detection has emerged as a good option for many metrics.
Anomaly detection uses machine learning to detect a normal pattern for a metric, automatically learning the varied patterns for different instances of the same resources that may naturally fluctuate. Having learned what is normal, anomaly detection can then determine algorithmically how much deviation from normal represents something compelling to alert. In LM Envision, warnings, errors, and critical alerts can be configured based on variations that are different from normal.
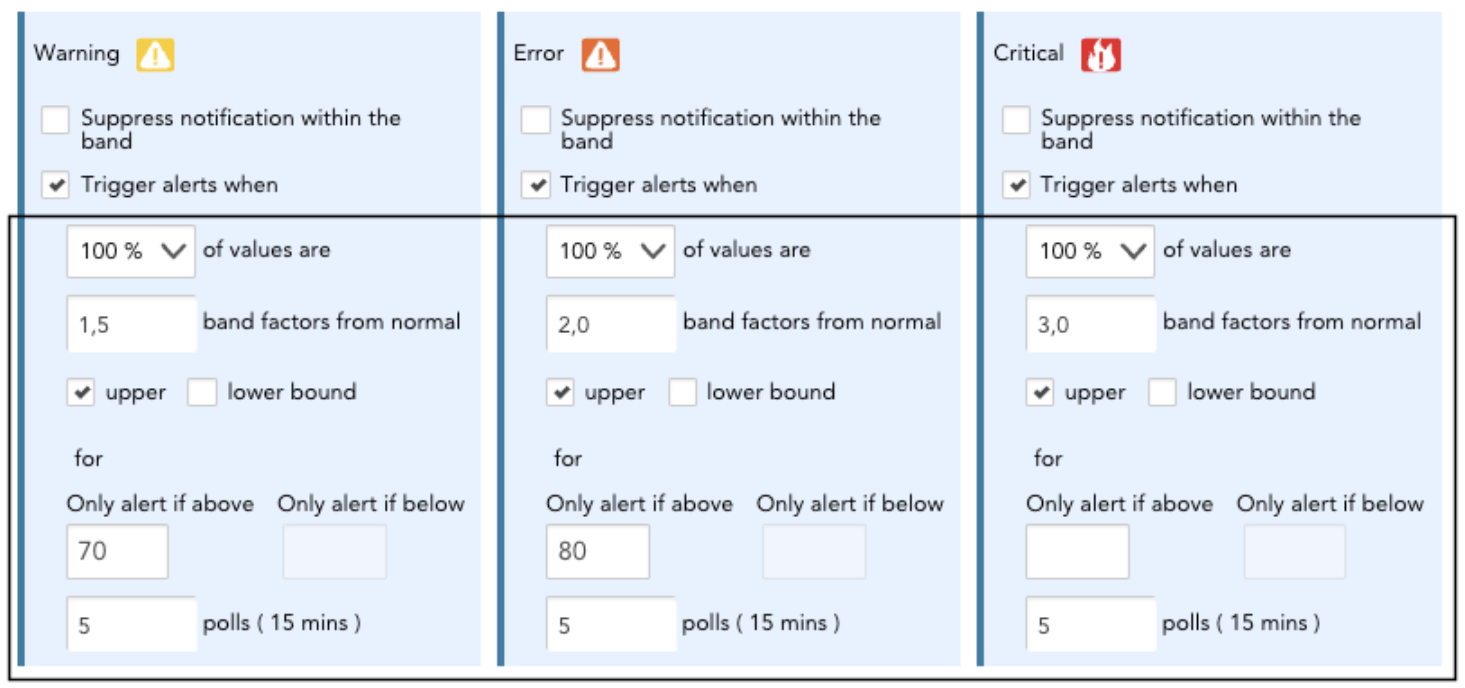
With this approach, operations teams do not have to set threshold levels, and alerting automatically adjusts to what is normal for different resources: better insights and less work.
Use case: An overheating computer room
Problems can arise when deploying IT resources at unstaffed remote locations. If something breaks, the organization must send someone to investigate the issue and resolve or mitigate the problem. Ordering necessary parts can further delay both the diagnosis and the solution.
Many device types provide temperature readings. Anomaly detection can use these readings to determine if the temperature of one or more devices rises above their normal range. This information allows scheduling a maintenance call to the remote location to proactively identify and resolve any issues at the device or room level before major outages occur.
Use case: Optical level degradation
Optical transceivers are examples of components that can fail, causing outages or degraded performance. Many modern devices allow the optical levels of transceivers to be measured. By applying anomaly detection, operations teams can determine when a transceiver is about to fail and take corrective action before the failure occurs.
Use case: CPU utilization signals abnormal load
CPU metrics are available for networking, storage, and server devices. There is no specific “right” level of CPU utilization in all cases. The “normal” level depends on the expected load. Abnormal detection is a better fit for these use cases than static thresholds.
Using static thresholds and anomaly detection or dynamic thresholds together
While anomaly detection for metrics is powerful, it could be better. For example, if a metric level rises slowly, machine learning continuously learns a new “normal” and does not trigger alerts. Anomaly detection and dynamic thresholds are excellent for unexpected and fast changes. However, some customers back them up with a static threshold set at a high level. This way, noise is reduced by using a static threshold to capture high metric levels, avoiding false positives. It also identifies unexpected and significant deviations from normal with dynamic thresholds.
Maximize efficiency by merging anomaly detection with static thresholds
First introduced in 2019, LM Envision’s metric anomaly detection has evolved, including detecting seasonal patterns for better alerting and rate of change. This blog has touched on only some anomaly detection uses, including environmental, performance, and traffic metrics. Any time there are significant false positives or negatives and metrics with no single threshold level for every instance, anomaly detection or dynamic threshold may save time and reduce noise. Combining anomaly detection or dynamic thresholds with static thresholds can also enhance their effectiveness.
