
In a previous post, I talked about the potential of AIOps and why true AI (Artificial Intelligence) hasn’t had much impact in the monitoring space yet. However, I believe Algorithmic IT Operations can help and will share the path LogicMonitor is taking to get there in this post.
When I ran data centers, the main challenges in monitoring were knowing what data to collect (I learned through hard experience that just collecting metrics like CPU, memory usage and network was not enough to alert about, or troubleshoot, issues); what thresholds to set to be alerted on; and how to store, process, visualize and alert on all the data at scale.
LogicMonitor has done a great job of solving these problems for customers with our hugely scalable TSDB that stores every sample without loss for up to 2 years, our library of over 1,500 monitoring integrations with best practices alert thresholds defined, and so forth. But the problems of monitoring have changed.
No longer is the user experience defined by an application running on a server, or a small set of web servers talking to a database. Nowadays a user’s experience is likely to be dependent on a variety of microservices and applications, distributed among public cloud and private data center environments. (About 90% of cloud apps share data with on-premisess applications.)
So while LogicMonitor can provide unique insight into these hybrid and cloud deployments, and furnish lots of data and practical alerts out of the box, this can lead to over-alerting. An issue in a shared service, or a key network component, can lead to alerts in many dependent applications, which, while all accurately reflecting the state of systems, can slow issue remediation.
Our goal is to make our users better at their jobs; to predict, prevent and resolve IT issues as quickly as possible. To this end, we are working towards hyper-efficient alerting with AIOps. We will be rolling out a series of features to help you get there.
Topology discovery and visualization
Coming soon, LogicMonitor will be able to discover and present topology information automatically — at the network (switch and router) levels, and also application levels (based on traffic flows) both in cloud and data center environments, even extending down into mapping virtual machines to data stores and physical storage resources. This discovered context, where we understand multiple types of relationships and dependencies, is the “model” of your application. This is extremely useful in its own right but is also essential for enabling some of the other AIOps functionality and advanced IT management features described below. So, to be meta, “dependencies” are a dependency for the rest of AIOps.
Service Definition and Monitoring
Administrators will be able to define a service or application as a collection of components (containers, virtual machines, databases, storage arrays, load balancers, etc.) and define SLAs, scheduled downtime, etc. on that service as a whole. Alerts can be set against aggregate metrics of the components of the service (for example, the maximum and average latency of requests served by the containers in the service — even as the containers may scale up and down with load). This allows administrators and developers to manage the service consistently. Importantly, this allows the monitoring system to have context about the service: “Service X consists of these constituent elements” (some of which may be other services). This becomes essential in other features also coming soon. It also allows a significant reduction in alerts, moving towards hyper-efficient alerting. If some percentage of servers in a service is down, but the latency of the service overall is fine, administrators do not need to be concerned or alerted. So escalated alerts can be constrained to only the alerts at the service level that the users care about.
Alert Dependencies
Again, using topology and dependency information, LogicMonitor aims to automatically suppress alerts from dependent systems, highlighting the likely candidates for a true root cause. While it may not be possible to identify a single unique alert of condition as the root, it will be possible to reduce what may otherwise be hundreds of alerts to a few significant candidates.
Anomaly detection and alerting by itself is limited in terms of its function as a useful feature. If CPU load on a virtual machine jumps from 20% to 40%, that may be anomalous, but given that there is still 60% free capacity – there is no impact to users. Very few enterprises have the resources to investigate all such anomalies, so such alerts teach your operations teams to ignore alerts. If your team is short on resources to investigate precursor issues, you may be better off relying on best-practice thresholds (e.g. CPU is greater than 90% for more than 4 minutes, for a simple example). Anomaly detection is also problematic if the issue of dependencies isn’t addressed: if system A depends on system B, and system B starts acting slowly, system A will act anomalously and trigger a useless alert.
However, anomaly detection can be very useful in some cases. Where the topology and dependencies of a service are well understood by the system, unusual behavior in a component that is depended on can be highlighted as a possible root cause, even if it is not in alert. Conversely, components whose metrics are not abnormal can be filtered away from the investigative view, greatly speeding the time to resolution (especially if the metrics may otherwise look unusual though the difference is a normal repeated weekly cycle, for example.)
So where is the “hyper-efficient” part?
There is something really important to observe here. Suppressing alerts triggered by dependencies is very important. It is one the most common requests from our customer base. Alerts triggered by abnormality are also interesting and many vendors are starting to implement them.
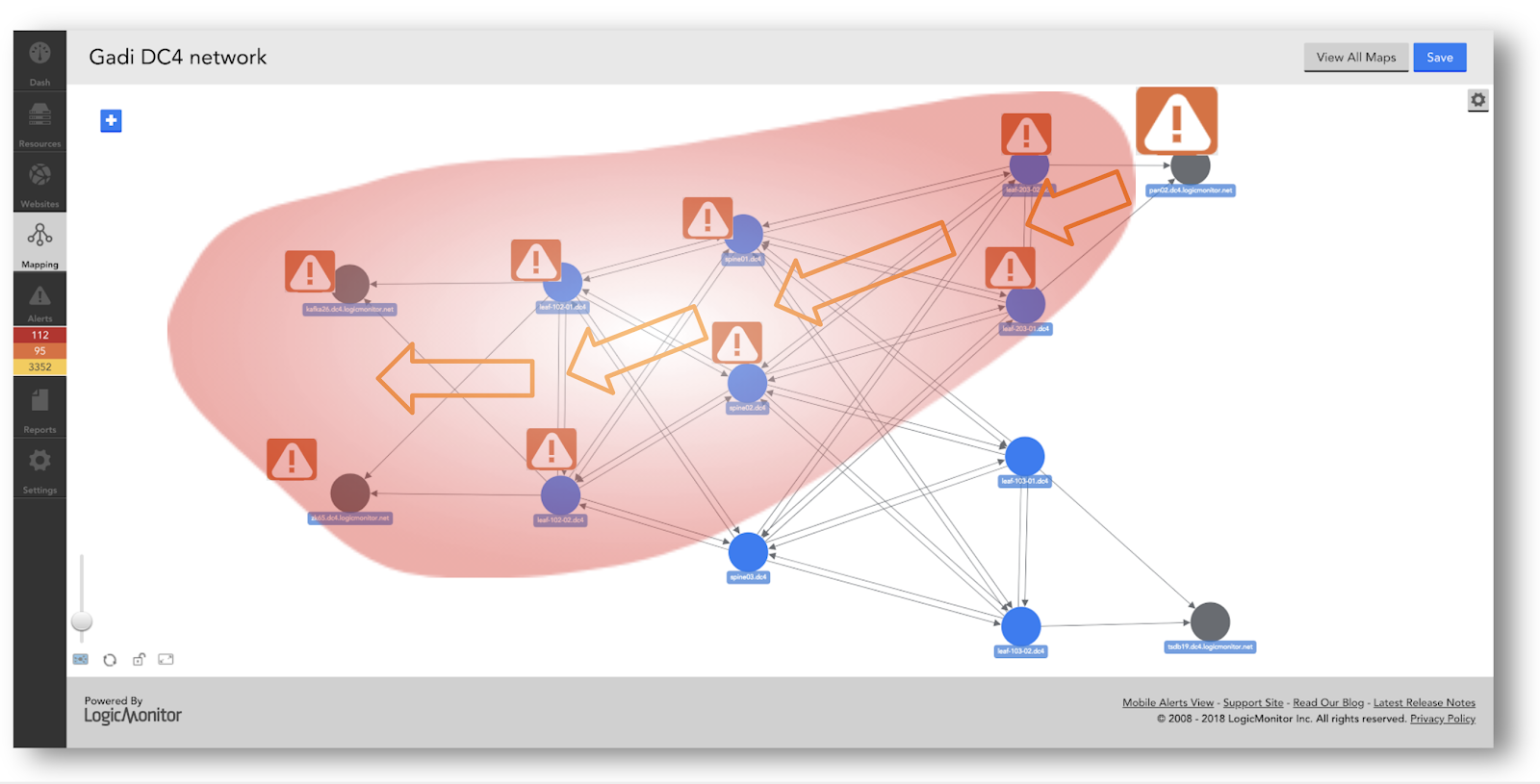
HOWEVER… this is what the world of alerts looks like:
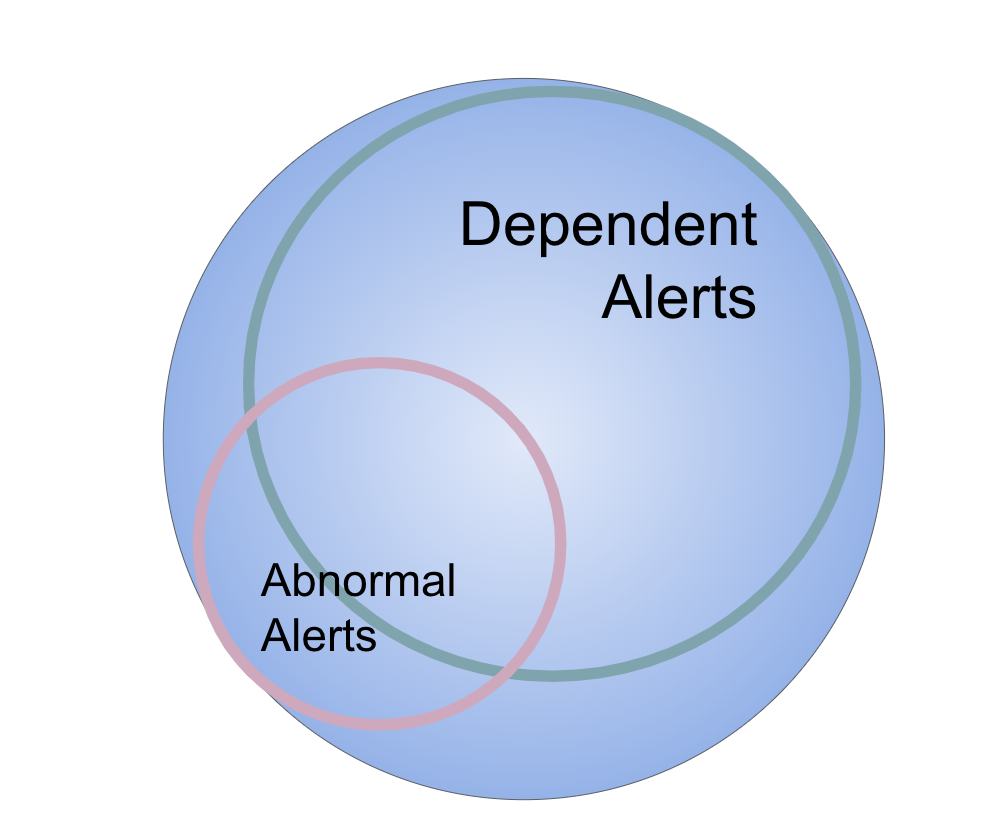
When an alert happens as a result of dependency, it will also trigger abnormality alerts. So there is a large overlap that needs to be addressed. We believe that understanding and managing the dependency-driven alerts is something that you have to do first. Vendors that do not do that will generate a massive amount of false positive abnormality alerts (!). Only when done together can a system really reduce the noise and give you interesting alerts that are
either the cause of a dependent alert or an abnormality alert that is a real abnormality. LogicMonitor will use topological dependency information to suppress abnormality alerts that are triggered by a system that is a dependency going into alert.
Cost optimization
With the ever-expanding range of options that public cloud providers are rolling out, it is easy to waste resources (which translates to wasting money). There are the obvious cases, like unattached storage volumes that are still being paid for. Compute instances that have been idle for months. Overprovisioned storage or compute. But even if your operations staff correctly sized resources when they deployed an application, things change – both the usage of the application over time, and also the instance and storage types available to run it on. By using models that show expected usage, including taking into account seasonality and periodicity, and combining that with a constant update of the cloud providers’ offerings, AIOps will automatically recommend the optimum resources for an application. That can be integrated with provisioning tools to automate the reconfiguration. An alert that warns you of dramatically increased costs due to a change, or to dramatic opportunities to save, is not one you should be waiting until the end of the month to receive when most billing optimization processes are run.
Correlation
When troubleshooting a system or service, it is often useful to know if there were other systems that were behaving in a similar manner. LogicMonitor aims to be able to show metrics on other, topologically related systems that were correlated with the metric in alert, which may be causative. This is another feature that depends on topology information. In an account monitoring tens of thousands of devices, there is almost guaranteed to be a non-causative, but strongly correlated, metric on some random system. Limiting the metrics scanned for correlation to those that are topologically related means that the results are likely to be interesting correlations, rather than merely spurious. (Spurious correlations is a great site, allowing you to discover interesting facts like “People who died by falling out of their bed” correlates with “the number of Lawyers in DC”). Another factor to note is that unless the set of metrics to be correlated is limited by topology data, there is no way to perform multivariate correlation in a timely manner at scale. The combinatorial set is too large to process in anything close to real time, even for Big Data technologies.
Holistic Monitoring
Using information from integration with other systems — Kubernetes, cost systems, GCP, or CI/CD systems, for example — LogicMonitor will be able to infer greater significance in changes in behavior. For example, if an application service has different performance characteristics after some containers are destroyed and new ones are deployed as part of a software release — that can be highlighted and brought to the developer’s attention. (“The new release of software requires 90% more database queries than the prior release. This will cost an additional $20,000 per year to maintain the same level of performance in AWS.”)
This is a foreshadowing of some of the AIOps features that LogicMonitor is actively working on to release soon. The intent here is to give you a preview of where we are headed and convey that some of these AIOps features are intertwined. Releasing just one feature (e.g. anomaly detection) without a plan for a strategic AIOps rollout could end up leading your teams into a worse situation. So while this may mean some of our AIOps features take a bit longer than we will like, it will be worth the wait! Looking forward to the first half of 2019.