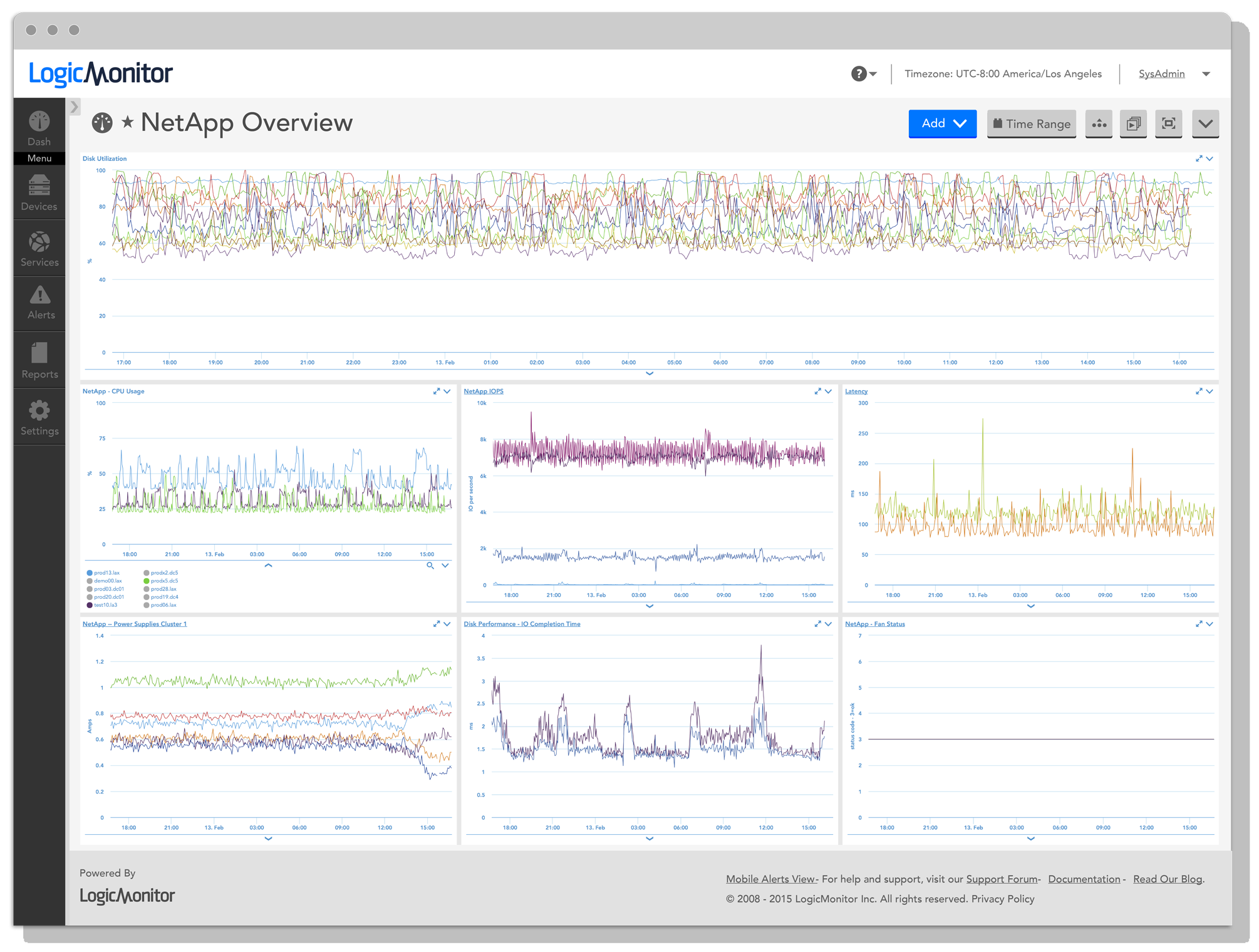
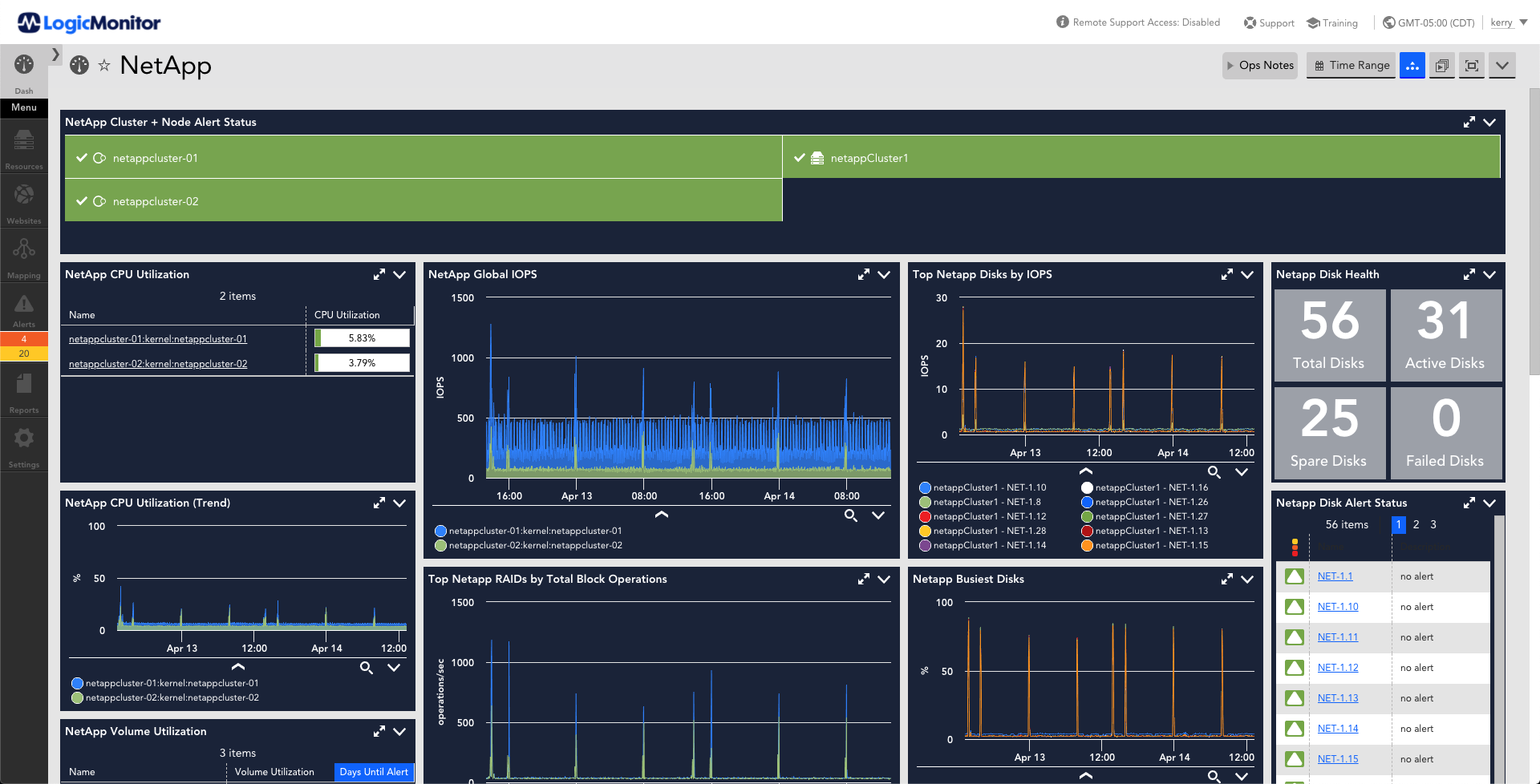
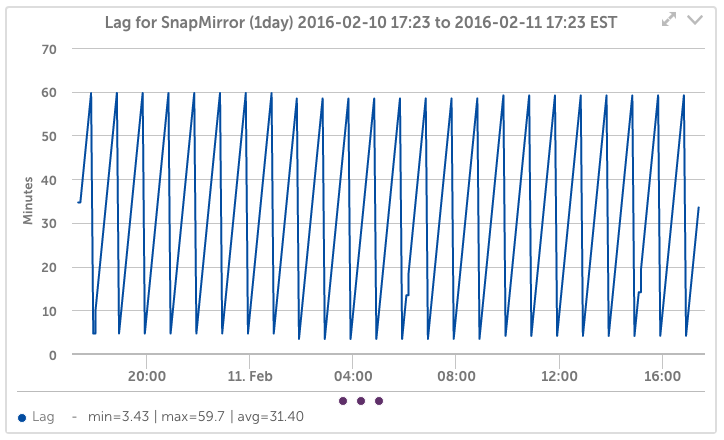
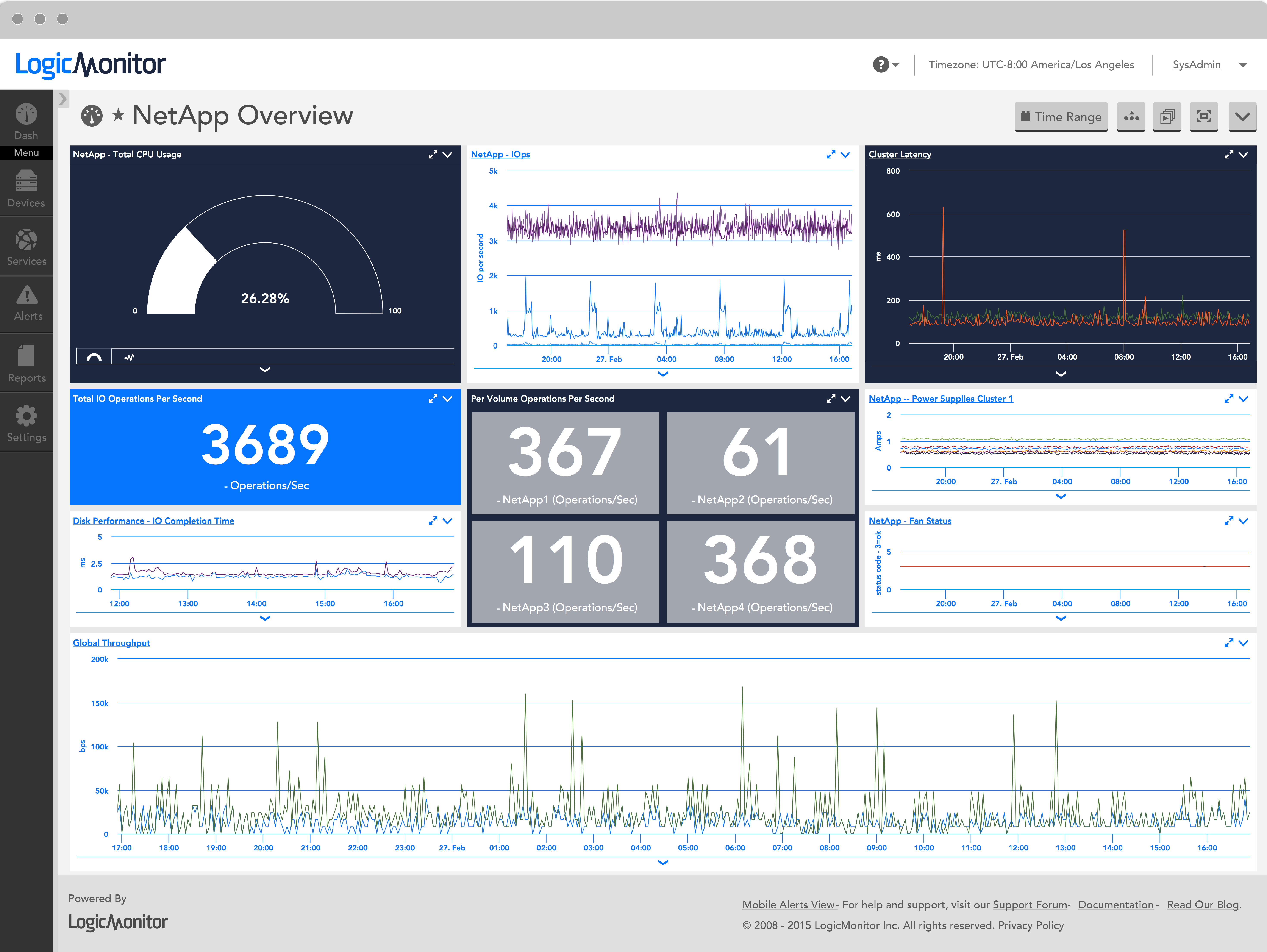
Skip the hours of work manually configuring and maintaining other NetApp monitoring systems. With no configuration work, you will have NetApp performance trend graphs and alerts on:
- Every active interface
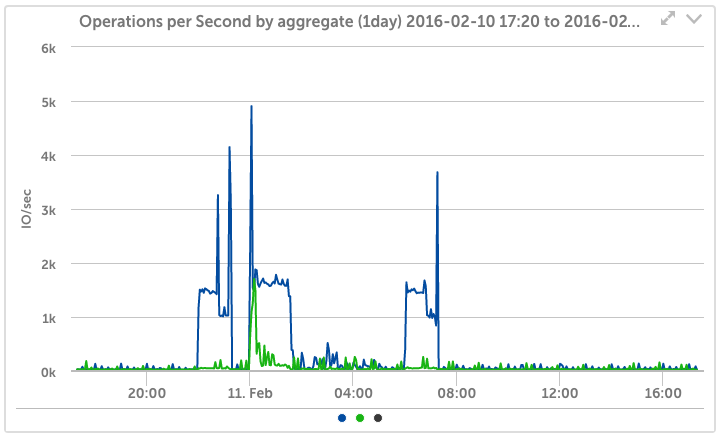
- Total CPU usage, disk activity, IO per second, cache age, consistency point activity
- Per volume space, inode and snapshot utilization
- Per volume read and write latency, IO operations per second and throughput
- Health checks for disk, fan and power supply failures; autosupport success
- LUN queue depth
and many more metrics.
Whether you are running in Cluster mode, 7-mode or ONTAP, storage monitoring should not fall on your best team members. Let LogicMonitor monitor, alert on, and display the information for them, so they can get down to solving problems or more strategic activities.