
In this article




How we upgrade 10,000+ containers with zero downtime!
Managing Kubernetes version upgrades can be a formidable undertaking. API versions are graduated, new features are added and existing behaviors are deprecated. Version upgrades may also impact applications needed by the Kubernetes platform; affecting services like pod networking or DNS resolution. At LogicMonitor, we ensure our Kubernetes version upgrades are successful through a process designed to instill collaboration and due diligence in a repeatable fashion. Let’s jump into our Kubernetes upgrade best practices!
The Breakdown:
We run managed AWS EKS clusters in our environment. EKS clusters have a control plane managed by AWS and when a Kubernetes version upgrade is initiated, AWS upgrades the control plane components on our behalf. Our workload consists of a mixture of management and self-management node groups. During a Kubernetes version upgrade, AWS triggers an instance refresh on our managed node groups. To upgrade our self managed node groups, we trigger the instance refresh. To ensure nodes are cordoned off and gracefully drain of pods, we run a tool called the aws-node-termination-handler. As nodes running the prior version of Kubernetes are drained and terminated, new instances take their place, running the upgraded Kubernetes version. During this process thousands of containers are recreated across our global infrastructure. This recreation occurs at a rate which does not impact the uptime, accessibility or performance of any of our applications. We upgrade Kubernetes clusters with zero downtime or impact to our production workloads!
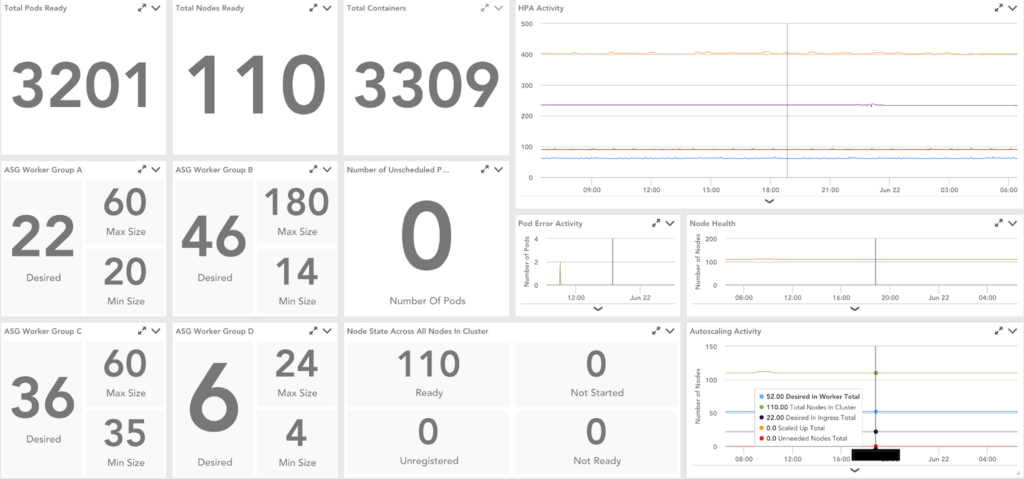
Datapoints we’ve found especially useful when monitoring Kubernetes version upgrading:
- Auto Scaling Group Metrics
- Desired Instance Count
- Max Size
- Min Size
- Total Nodes
- Cluster Autoscaler Metrics
- Number of Unscheduled Pods
- Number of Evicted Pods
- Number of Node in Unready State
- Number of Node Not Started
- Number of Node in Ready State
The Team
Our version upgrades are performed by a team of three engineers who play specific roles during the process described below. Ops(New), Ops(Lead) & Ops(Sr):
Operator (On-boarding) Ops(New)
This operator is new to the cycle of Kubernetes upgrades. As a new member of the team, their main goal is to familiarize themselves with the upgrade process as a whole; studying past upgrades, learning the process and supporting the current upgrade efforts. In this role, the operator will perform upgrades on both a production and non-production cluster under the guidance of the operator responsible for research and development Ops(Lead).
Core Duties
- Responsible for executing processes on development/pre-production cluster
- Responsible for executing processes on a production cluster
Operator (Lead) Ops(Lead)
This operator is the lead engineer during the upgrade cycle. They are responsible for researching changes, upgrading any critical components, determining a course of action for breaking changes, and scheduling all cluster upgrades. A considerable amount of time is dedicated to planning the proposed changes by this engineer. This operator also acts as a liaison between different stakeholders. This involves communicating important dates, interesting findings or feature deprecations. Ops(Lead) coordinates knowledge transfers sessions between the Ops(New) and Ops(Sr) as needed. In the previous cycle this operator participated as Ops(New) and has experience executing the upgrade process on both development and production clusters.
Core Duties
- This operator in the previous cycle was Ops(New), leveraging that experience, Ops(Lead) is expected to have an understanding of the execution tasks.
- Responsible for executing processes on development/pre-production clusters
- Responsible for executing processes on production clusters
- Responsible for core research of version upgrade changes
- Responsible for coordinating associated work between Ops(New) and Ops(Sr)
Operator (Senior): Ops(Sr)
This operator previously participated in the last two upgrade cycles. This engineer serves as a knowledge resource for both Ops(Lead) and Ops(On-boarding).
Core Duties
- This operator in the previous cycle was Ops(Lead), leveraging that experience, the Ops(Snr) serves as a mentor to the Ops(Lead) and Ops(On-boarding).
- Responsible for assisting with executing processes on production clusters.
The Process
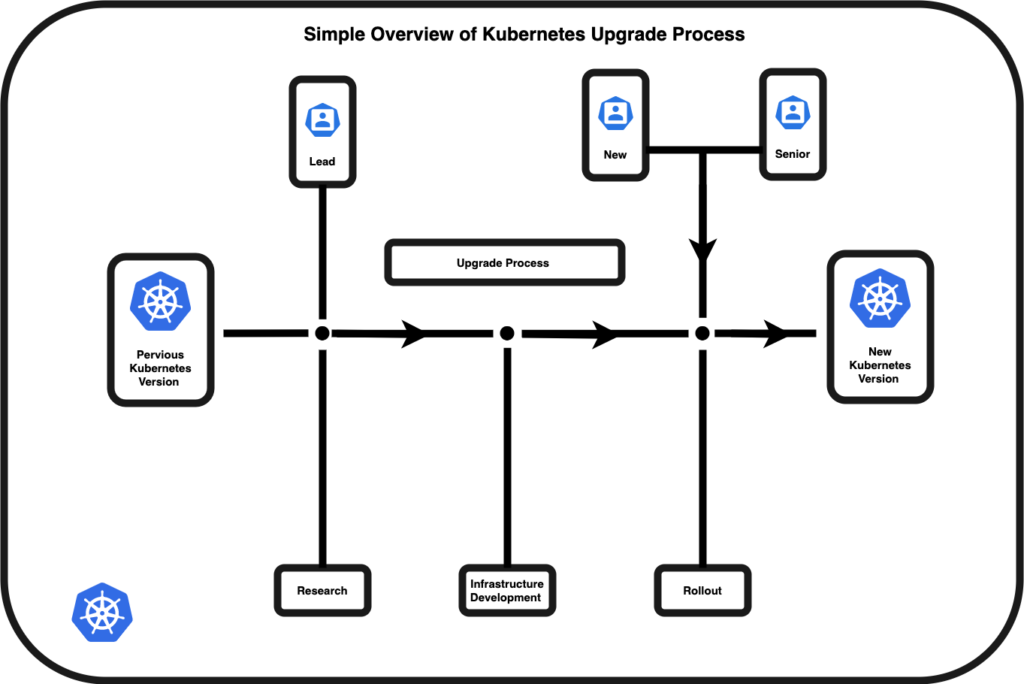
Research: The lead operator starts the cycle by investigating changes between the current version and the proposed version we would like to upgrade to. During this phase of work, the lead operator shares findings, road-blockers, and items of interest with the core team. To assist the lead operator several resources were gathered over the course of previous upgrade cycles to help determine what Kubernetes components have changed in the release we plan to run. The lead operator uses these resources to answer the following questions;
- Questions
- Were any APIs graduated/deprecated that we should be concerned about?
- Are there any features enabled by default that we should be concerned about or can leverage in our Kubernetes implementation?
- What components currently running in our cluster will be impacted by the Kubernetes version upgrade ?
- Resources
Critical Components: We deem several components in our clusters as critical to the operations of Kubernetes, each of these components has recommended versions to run on specific Kubernetes versions. Research is done to verify we can run the supported version.
We define these services as critical to our clusters viability
- DNS
- Pod Networking
- Cluster Ingress
- Cluster Autoscaling
Infrastructure Development and Rollout: Once the resource portion is concluded the lead operator generates a series of pull requests to alter the infrastructure which supports our Kubernetes clusters. These pull requests are approved per our internal guidelines.
Rollout:
- Communication: During each rollout, a communication thread is created to provide team members updates on the progress of each process executed during the upgrade. In the event that an issue occurs these communication threads can be used for further investigation.
- Pre-Production: The rollout begins to our pre-production clusters. This gives the lead operator an opportunity to vet the changes and determine a course of action if a component is found in an unhealthy state. The on-boarding engineer is expected to shadow the lead engineer during these pre-production rollouts and is expected to execute the rollout on a pre-production cluster under the supervision of the lead operator.
- Production: Our production clusters are updated over the course of two maintenance periods. Traditionally, changes of this nature are done during a scheduled maintenance window due to the potential impact to our customers if something were to occur. All operators participate in the rollout of our production clusters; monitoring, overseeing and communicating updates as the rollout progresses.Once all nodes are on the new Kubernetes version, each operator performs a series of health checks to ensure each cluster is in a fully functioning state.
In conclusion, our upgrade process consists of identifying changes to critical Kubernetes components, determining their impact to our environment and creating a course of action when breaking changes are identified. Once we’re ready to implement a version upgrade, we trigger an instance refresh to our various node groups, which causes nodes to be cordoned off and gracefully drained of pods prior to termination. The team responsible for managing the upgrade process consists of 3 different roles which are cycled through by each on-boarded engineer. Kubernetes is an important part of our infrastructure, and the process we’ve designed at LogicMonitor allows us to upgrade Kubernetes versions without impacting the uptime of our services.



Subscribe to our blog
Get articles like this delivered straight to your inbox