Modern software development is evolving rapidly, and while the latest innovations allow companies to grow through greater efficiency, there is a cost. Modern architectures are incredibly complex, which can make it challenging to diagnose and rectify performance issues.
Once these issues affect customer experience, the consequences can be costly.
So, what is the solution?
Observability — which provides a visible overview of the big picture. This is achieved through metrics, logs, and traces, with a core focus on distributed tracing.
Whether you are a DevOps engineer, software leader, CEO, or business leader, understanding the role that distributed tracing plays, and when to use it, can give you that competitive edge you seek.
Distributed tracing is an emerging DevOps practice that makes it easier to debug, develop, and deploy systems.
Distributed tracing involves the operating and monitoring of modern application environments. As data moves from one service to another, distributed tracing is the capacity to track and observe service requests. The goal here is to understand the flow of requests so that you can pinpoint weak spots in the system, such as failures or performance issues.
This flow of requests is through a microservices environment or distributed architecture, which we will touch on momentarily.
As discussed, traces go hand-in-hand with two other essential types of data— metrics and logs. Together, these three types of telemetry data provide you with a complete picture of your software environment and more importantly, how it is performing.
Primary use cases of distributed tracing involve operations, DevOps, and software engineers. The goal is to get answers quickly, focusing on distributed environments — mainly microservices or serverless architectures. These architectures yield many benefits but are also highly complex. This makes tracking and resolving issues challenging.
Think of an everyday eCommerce application. When a customer makes a purchase, a series of requests travel through distributed services and databases. From the storefront to the shopping cart, authentication to payment, shipping, and CRM, there’s a lot that could go wrong. If an issue occurs in any of these services, the customer experience will be poor, and will probably lead to a lost sale. Not to mention the loss of a recurring customer. This study found that following a negative experience, 95% of users will leave a website. Once they do, it’s tough to get them to come back.
Distributed tracing helps cut through the complexity, allowing you to troubleshoot issues and bottlenecks in distributed systems before the customer is affected. Used by operators to maintain observability in a highly distributed context, tracing can identify problems such as latency, analyzing the root cause and surrounding context — which is invaluable.
So, distributed tracing is the process of tracking and analyzing requests across all services, as they bounce around distributed systems as a whole. This allows you to:
Better understand the performance of each service.
Visualize and effectively resolve performance issues.
Measure the overall health of your system.
Prioritize areas that will lead to valuable improvements.
The History of Distributed Tracing
Monolithic service architectures were once the golden standard, but are now becoming increasingly rare.
Monolithic applications have evolved into microservices. When it comes to a traditional monolithic application, that contains a centralized codebase in a single service, diagnosing a failure can be as simple as following a single stack trace. To troubleshoot an error, you would simply look through your log messages or implement standard APM tools. However, this type of architecture makes scaling software development tedious and painstaking.
As technology evolved, distributed architectures, such as microservices, were developed to provide better communication between different platforms and more user-friendly systems. An increase in efficiency and productivity resulted.
Since a distributed architecture or microservices-based application can consist of tens, hundreds, or even thousands of services running across different hosts, a deeper, more complex level of telemetry is required to make sense of relationships — relationships you may not even be aware of.
The benefits of developing apps using microservices are vast. This approach involves smaller services that can be more easily deployed, scaled, and updated. This provides greater flexibility in terms of the technologies and frameworks you use for each component.
Although many real-world environments still use a combination of monolith apps alongside microservices-based apps, there has been a dramatic shift. As of 2018, research shows that 63% of traditional enterprises were using microservices architecture, experiencing:
Improved employee efficiency.
Improved end-user experience.
Cost savings on both infrastructure and development tools.
This research was based on the views of engineering managers, software architects, and other applications development experts across 51 countries and twelve industries.
Another 2020 report found that 92% of organizations are experiencing success with microservices. This means that if you are not leveraging the benefits of microservices, you risk being left behind.
Today, modern software solutions are typically implemented as large-scale, complex distributed systems. For example, using the microservice architectural style. These modern applications are often developed by different teams and may even use different language programs. As these applications evolved, companies realized they needed a way to view the entire request flow — not just individual microservices in isolation.
Based on the research above, lack of visibility into the end-to-end process, across multiple microservices and communication between teams are some of the top challenges that companies using microservices expect to face. The ultimate goal is to handle errors throughout the process reliably and consistently.
This is where distributed tracing came into play, becoming a best practice for optimal visibility and control. Distributed tracing tackles common issues, such as difficulty tracking and analyzing requests in a distributed environment. Debugging these issues is also fairly straightforward thanks to tracing — even when systems are highly distributed.
At first, this concept was painfully time-consuming. Being able to collect and visualize data was incredibly labor-intensive. The number of resources that were being spent on tracing was taking away from the development of new features and the overall growth of a company. The development of tools was needed to properly support distributed architectures, leading to a growing reliance on distributed tracing. This includes data tracing tools.
Distributed tracing took the concept of tracing, which was used to provide the point of view of a single monolithic process, extending it to the point of view of all the processes involved in the journey of a single request.
Luckily, companies such as LogicMonitor began offering a fully automated approach. This made it possible for companies to implement solutions that enhance the productivity of tracing, analyzing, and visualizing available data. Being able to identify where issues occur in an application is a game-changer.
The Relationship Between OpenTelemetry and Distributed Tracing
In 2019, OpenTracing and OpenCensus merged into OpenTelemetry.
OpenTelemetry offers a single, open-source standard to capture and export logs, metrics, and traces from your infrastructure and cloud-native applications. Providing a specification in which all implementations should follow, including a common set of SDKs and APIs, OpenTelemetry can help with distributed tracing.
While distributed tracing has been around for over a decade, it was only recently that interoperability between distributed tracing systems became widely adopted. It is OpenTelemetry that created interoperability between OpenCensus and OpenTracing.
LogicMonitor’s Distributed Tracing is an OpenTelemetry-based integration that allows you to forward trace data from instrumented applications. This allows you to monitor end-to-end requests as they flow through distributed services. Learn more about installing an OpenTelemetry Collector.
How Does Distributed Tracing Work?
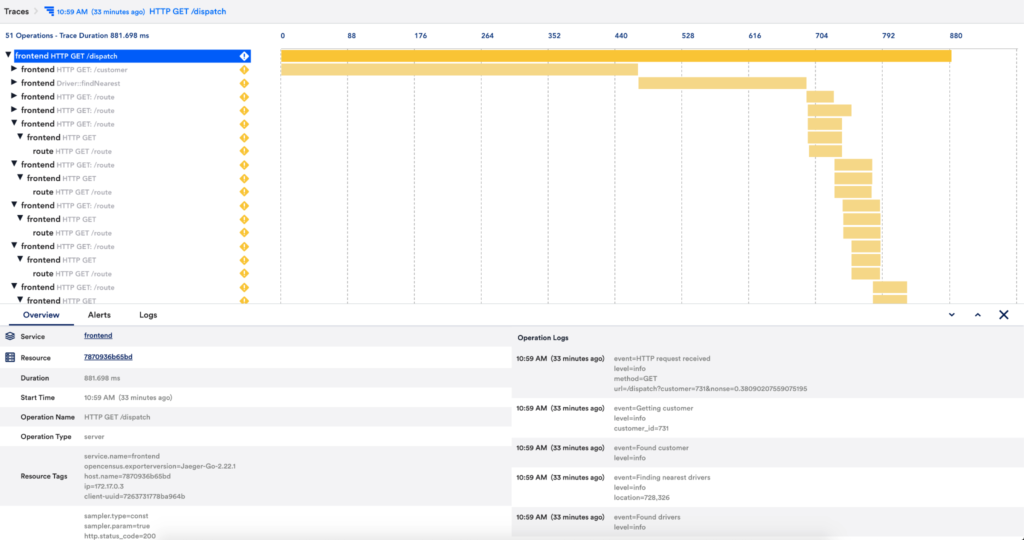
Think of distributed tracing as a tree-like structure. A root or “parent” span, branches off into “child” spans.
Once an end-user interacts with an application, tracing begins. When an initial request is sent, such as an HTTP, that request is given a unique trace ID. That trace will describe the entire journey of that single request. As the request moves through the system, operations or “spans” are tagged with that initial trace ID. It is also assigned a unique ID. There will also be an ID associated with the operation that originally generated the current request — also known as the “parent” span.
Each of the spans represents a single step within the request’s journey and is encoded with critical data, including everything from tags to query and detailed stack traces to logs and events that provide context. This means that as a trace moves through a distributed system, the platform will generate child spans for each additional operation needed along the way.
There is a multi-step process involved, which includes:
Instrumentation
Trace context
Metrics and metadata
Analysis and visualization
Based on this process, distributed tracing can offer real-time visibility into an end user’s experience.
In summary:
Once a trace is started, it is assigned a trace ID that follows the request wherever it goes.
A new span is created following each chunk of work in the request that contains the same trace ID, a new trace ID, and the parent span ID.
Once a parent span ID is created, a parent-child relationship is formed between spans. A child span will have one parent span, while a parent can have multiple child spans.
Spans are also time-stamped so that they can be placed in a timeline.
One span in a trace tree will not have a parent, which is referred to as the root span.
What Does Distributed Tracing Mean Within Observability?
As the use of microservices and cloud-based applications increases, the need for observability is more important than ever before. This is accomplished by recording the system data in various forms.
Above, we discussed metrics, logs, and traces. Together, these are often referred to as the pillars of observability. When understood, these strategies allow you to build and manage better systems.
Tracing is one critical component within this overall strategy, representing a series of distributed events through a distributed system. Traces are a representation of logs, providing visibility on the path a request travels, as well as the structure of a request.
Tracing is the continuous monitoring of an application’s flow, tracking a single user’s journey through an app stack. Distributed request tracing has evolved from the method of observability, ensuring cloud applications are in good health. Distributed tracing involves the process of following a request by recording the data associated with the path of microservices architecture. This approach provides a well-structured format of data tracing that is leveraged across various industries, helping DevOps teams quickly understand the technical glitches that disrupt a system infrastructure.
Again, this relates to the use of tools such as OpenTelemetry.
Why Does Distributed Tracing Matter?
The development of new technologies and practices allows businesses to grow more rapidly than ever before. However, as variables such as microservices, containers, DevOps, serverless functions, and the cloud gain velocity, making it easier to move from code to production, this creates new challenges.
The more complex software is, the more potential points of failure there will be within an application stack, leading to an increased mean time to repair (MTTR) — which is the average time it takes from when an issue is reported until that issue is resolved. As complexity increases, there is also less time to innovate because more time and energy is spent on diagnosing issues.
Making distributed tracing part of your end-to-end observability strategy, software teams can operate much more effectively. In the process, teams can:
Better identify and repair issues to improve customer experience and business outcomes.
More effectively measure system health to continuously make positive changes to the customer experience.
Innovate to rise above competitors.
Why Seek Distributed Tracing Solutions?
Bringing coherence to distributed systems is the primary benefit of distributed tracing. However, this leads to a list of other benefits, directly affecting a company’s bottom line.
Increased productivity — Compared to monolithic applications, tracking and resolving issues associated with a microservice architecture can be time-consuming and expensive. Failure data also requires developers to decipher issues from messages that aren’t always clear. Distributed tracing reduces the diagnostic and debugging process through a more accurate, holistic view. This significantly boosts efficiency.
Implementation is flexible — Since distributed tools work across a variety of programming languages and applications, developers can implement these tools into practically any microservices system, viewing critical data through one tracing application.
Improved collaboration — A specialized team develops each process within a microservice environment. When there is an error, it’s challenging to determine where that error occurred and who is responsible. By eliminating data silos and the issues they create, cross-team collaboration improves, as does response time.
Reduces MTTR — If a customer reports a failure, distributed traces can be used to verify that it is a backend issue. Using the available traces, engineers can then quickly troubleshoot. Frontend performance issues could also be analyzed using a distributed tracing tool.
So, the reasons why you would seek distributed tracing solutions are clear — but how?
Even if there is only a handful of services, the amount of data can become overwhelming, and fast. Sifting through traces is much like finding a needle in a haystack. To properly observe, analyze, and understand every trace in real-time, you need a distributed tracing tool. This will highlight the most useful information in terms of where you should take action.
What Is Sampling?
Sampling comes into play based on the sheer volume of trace data that collects over time. As more microservices are deployed and the volume of requests increases, so does the complexity and cost of storing/transmitting that data. Instead of saving all the data, organizations can store samples of data for analysis.
There are two approaches to sampling distributed traces.
Head-Based Sampling
When processing large amounts of data, distributed tracing solutions often use head-based sampling. This involves randomly selecting a trace to sample before it has finished its path. This means that sampling begins when a single trace is initiated. That data will either be kept or discarded and is the preferred form of sampling based on its simplicity.
There are many advantages to head-based sampling, as it is fast and simple, has little-to-no effect on application performance, and is ideal for blended monolith and microservices environments. The disadvantage is that since data is selected randomly, valuable information may be lost because there is no related trace data or context.
Tail-Based Sampling
Based on the limitations of head-based sampling, tail-based sampling is best for high-volume distributed systems where every error must be observed. In this case, 100% of traces are analyzed, with sampling taking place after traces have fully completed their path. This allows you to pinpoint exactly where issues are, solving the whole needle in a haystack concern.
Tail-based sampling leads to more informed decisions, especially for latency measurements. Since a sampling decision is made at the end of the workflow, it is easier to visualize errors and performance issues. The downside to this option is that it can cost more to transmit and store large amounts of data and additional gateways and proxies will be required.
Key Terms to Know for Distributed Tracing
Here is a short glossary of distributed tracing terminology:
A request is how applications, microservices, and functions communicate with one another.
A span is the segments that make up a portion of a trace.
A root span is the first span in a trace, which is also known as the parent span.
A child span is what follows the root or parent span.
A trace is the performance data that flows through microservices.
Sampling involves storing samples of tracing data instead of saving them for analysis.
Head-based sampling involves the decision to collect and store trace data randomly while the root span is being processed.
Distributed tracing tells the story of what has happened in your systems, helping you quickly deal with unpredictable problems. As the future of technology and software becomes increasingly complex, the use of distributed tracing, as well as techniques like monitoring metrics and logging, will become increasingly essential. It’s time to rise to the challenge.