

Through the early December we’ll be rolling out a minor release (v.47). As you may have seen recently in the press, Netflow is out of Beta with this release as well. It will be free at least through the end of the year, check out our help documentation for more details!
Improved Services Configuration
As we prepare to add more testing locations, we decided we better give you the choice of which locations you care about. With this next release you’ll be able to select which testing locations you want to use.
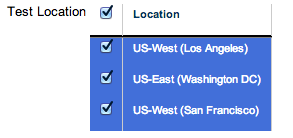
Overall alerting will be based on the total number of active locations. Once this is released, keep your eyes out for testing locations around the world.
Enhanced Windows Event Monitoring
We replaced the datapoint “wineventlog” with ##EVENTCODE##. The ##EVENTCODE## token will include the Windows Event ID as the datapoint, enabling you to filter and report by event type.
Other Improvements
- If you try to generate a report larger than what the typical email server can accommodate, we’ll send you an email letting you know why you haven’t received it.
- Manage alerting includes a column “Alerting for datapoint has been disabled at” to make it clear if alerts have been disabled at a parent host or group.
- Reports now say “Powered by LogicMonitor” instead of Managed by.
- Additional security around forgot password logic.
- We added ***Cleared*** to the subject line for custom alert delivery method cleared emails.
Bugs Fixed
- Users with full control of a group can add monitored windows services.
- Users with full control of a subgroup cannot see other host names for the parent group.
- Custom properties are now correctly added to hosts when using a netscan script.
- We now double check log file messages for a ‘new’ flag to ensure alerting accuracy
- Fixes around Services alert evaluation
- Event alerts with multiple matches could not be acknowledged by a phone call
- Collectors that switched proxies were not failing back in a timely manner, causing issues with collector restarts.
- NetApp tasks with a large number of instances were stuck in waiting status, so we optimized the data collection.
