
Cluster Alerts
Last updated – 17 March, 2026
Overview
Cluster alerts monitor and alert on datapoints across multiple resources in a resource group. They are designed to provide quick insight into the overall state of a collection of devices or cloud resources. For example, this can be useful when you have a pool of resources that are serving an application or performing a task; while you may not be too concerned with an issue that affects a single resource in the pool, you’ll likely want to know immediately if the pool of resources as a whole is at risk of not being able to serve its purpose. In a case like this, you could configure a cluster alert to trigger when five batch servers have CPU usage rates higher than 80%.
Cluster alerts trigger based on the presence of individual alerts for devices or instances belonging to the same group of resources. For example, using the scenario provided in the previous paragraph, five batch servers in the group would need to have 80% set as an alert threshold for CPU usage and would need to have exceeded that threshold in order for the cluster alert to trigger. Because cluster alerts rely on individual datapoint alerts, it’s important that you keep datapoint thresholds tuned, as discussed in Tuning Static Thresholds for Datapoints.
Note: Cluster alerts are a simple way to measure the overall health of a group of resources. For more sophisticated monitoring and alerting capabilities across groups of resources, consider LM Service Insight, a feature that groups instances across one or more monitored resources (e.g. devices) into logical “Services”. For more information, see About LM Service Insight.
Configuring Cluster Alerts
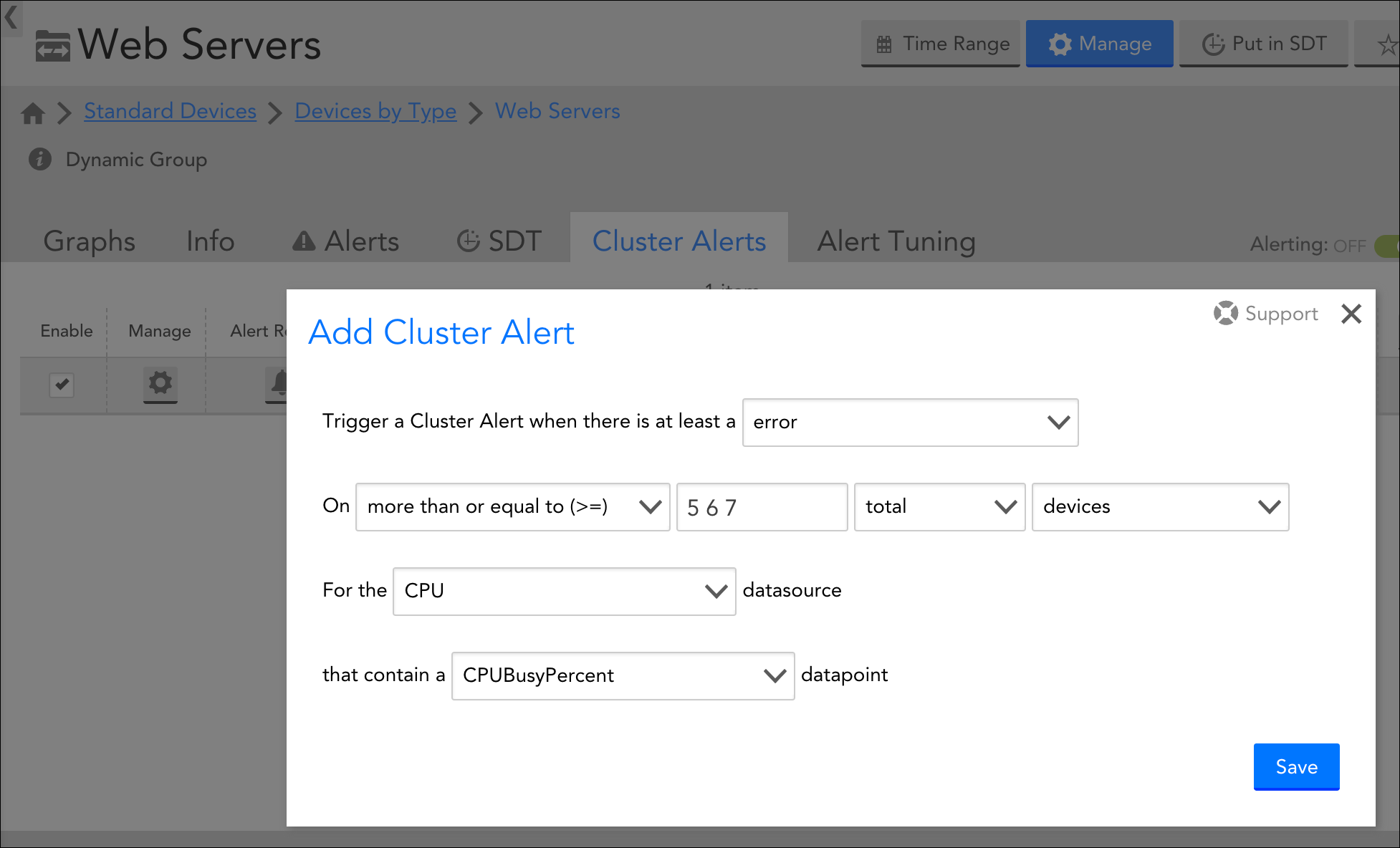
Cluster alerts are configured from the Resources page. From the Resources tree, select the resource group for which you are configuring the cluster alert and, from the group’s detail view, open the Cluster Alerts tab. Click the add icon (plus sign +) in the upper right corner to open the Add Cluster Alert dialog. As discussed next, there are several fields that must be configured.
Individual Device/Instance Alert Level Required to Trigger Cluster Alert
From the Trigger a Cluster Alert when there is at least a field’s dropdown menu, select the minimum alert severity level that individual devices/instances must be in in order for them to contribute toward the overall number of devices/instances required to trigger the cluster alert.
Number of Devices/Instances that Must Meet Alert Level Required to Trigger Cluster Alert
In order to specify the number or percentage of devices or instances that must meet the alert severity level specified in the previous field, a total of four fields must be configured:
- Comparison operator. Select the comparison operator that will be applied to the total number or percentage (e.g. greater than the total provided).
- Threshold value. Enter the number or percentage of devices in the device group that must meet the alert severity level specified by the Trigger a Cluster Alert when there is at least a <warning | error | critical> field. Similar to datapoint thresholds, you can enter a number for each alert level, as shown next.
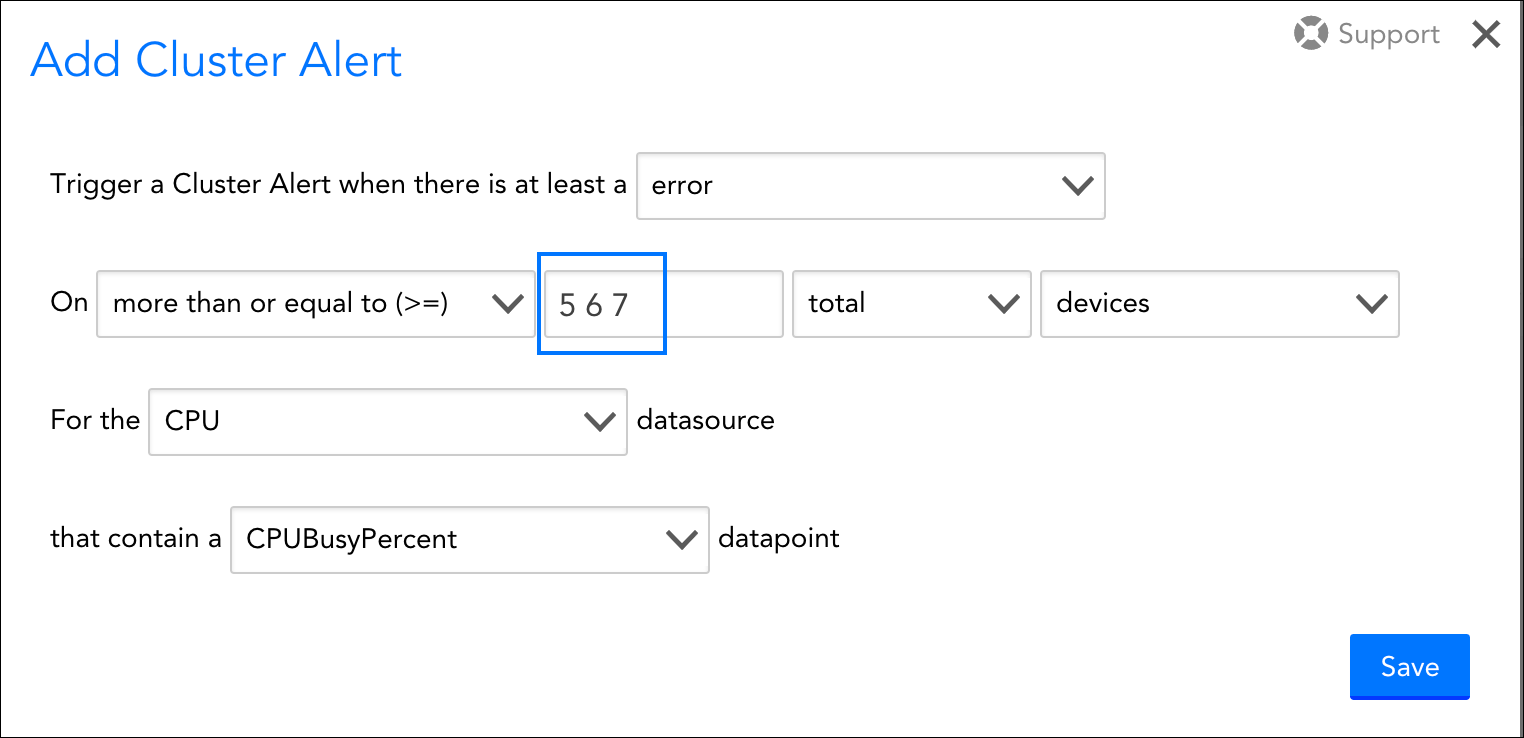
In the example depicted here, a cluster alert with a severity level of warning will be generated if 5 devices in the group have an active alert with a severity level of error for the CPUBusyPercent datapoint. A cluster alert with a severity level of error will be generated if 6 devices in the group have an active alert with a severity level of error. A cluster alert with a severity level of critical will be generated if 7 or more devices in the group have an active alert with a severity level of error. - Total count or percentage. From the dropdown menu, select “total” to indicate that the threshold is a static device or instance count; select “percent of” to indicate that the threshold is a percentage of the total number of devices or instances in the group.
- Device or instance. From the dropdown menu, indicate whether the threshold count or percentage is calculated using the number of devices in alert or the number of instances.
DataSource and Datapoint
From the DataSource and Datapoint fields’ dropdown menus, choose the datapoint (and its owning DataSource) whose threshold will be evaluated to see if it meets the minimum alert severity level specified by the Trigger a Cluster Alert when there is at least a <warning | error | critical> field.
Managing Cluster Alerts
Once a cluster alert is configured and saved, it displays in a table on the Cluster Alerts tab. From this table, you can edit the cluster alert’s configurations (using the manage icon), as well as enable/disable individual datapoint alerts for the group’s members, and disable/enable the cluster alert itself.
Enabling Datapoint Alerts
LogicMonitor assumes that cluster alerts supersede individual datapoint alerts for the resources in the group (i.e. the overall health of a collection of resources is the meaningful metric and not the individual health of the resources). For this reason, individual datapoint alert notifications for the datapoint specified are, by default, turned off for the members of the group once you configure and save a cluster alert. These alerts will still display in the interface (i.e. on the Alerts page or Alerts tab), but alert notifications for the alert will not be routed.
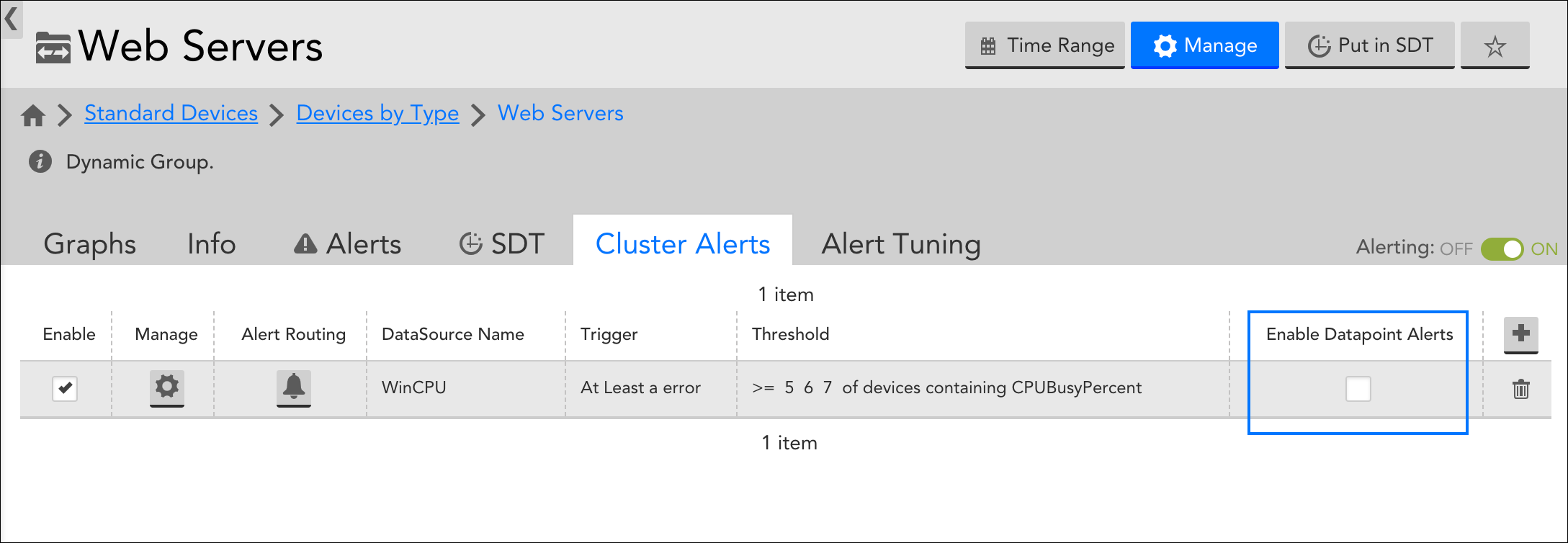
To re-enable individual datapoint alert notifications, check the Enable Datapoint Alerts option found in the Cluster Alerts table. When checked, individual datapoint alert notifications for group members will be routed along with the cluster alert notifications.
Disabling Cluster Alerts
Uncheck the Enable option to disable a cluster alert. When disabled, the cluster alert will no longer generate alerts.
Routing Cluster Alert Notifications
As with all alerts, cluster alerts will appear on the Alerts page, as well as on the Alerts tab (available from the Resources page). A device name of “cluster” will always be assigned to a cluster alert. This generic device name can be used when specifying alert routing, filter, or reporting criteria.
If you’d additionally like notifications to be generated and routed for cluster alerts, you’ll need to configure an alert rule. At a minimum, this alert rule’s criteria must match the group for which the cluster alert is configured. If you’d like the cluster alerts to be routed differently than other alerts for the group, deeper-level matching can be accomplished by setting the alert rule to match the “cluster” device. For more information on alert rules, see Alert Rules.
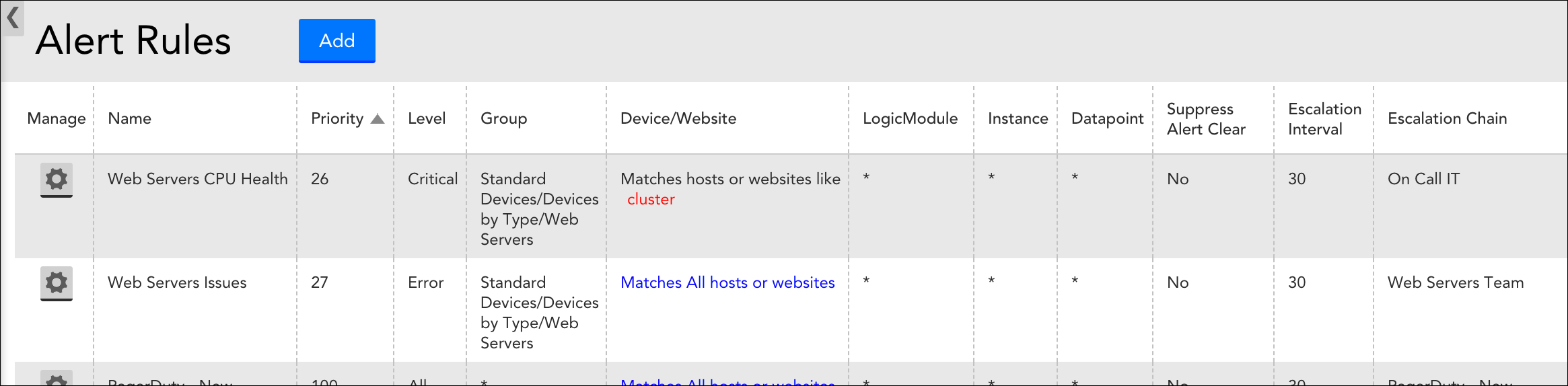
The first alert rule listed here will route alert notifications for all cluster alerts with a severity level of critical to the “On Call IT” escalation chain. The second alert will route alert notifications for any issues with a severity level of error that arise for the resource group (including cluster alerts with severity levels other than critical).
Note: To test alert notification routing for a cluster alert, click the alert routing icon found on the Cluster Alerts tab. The process for testing alert notification routing for a cluster alert is identical to testing alert notification routing for a particular datapoint/instance pair. See Testing Alert Delivery for more details.
